DashAttention: Differentiable and Adaptive Sparse Hierarchical Attention
Pith reviewed 2026-05-20 10:45 UTC · model grok-4.3
The pith
DashAttention replaces fixed top-k with adaptive α-entmax to make hierarchical attention fully differentiable and non-dispersive for long contexts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DashAttention leverages the adaptively sparse α-entmax transformation to select a variable number of blocks according to the current query in the first stage. This in turn provides a prior for the second-stage softmax attention, keeping the entire hierarchy fully differentiable. Contrary to other hierarchical attention methods, DashAttention is non-dispersive, translating to better long-context modeling ability. Experiments with large language models show that DashAttention achieves comparable accuracy as full attention with 75% sparsity and a better Pareto frontier than NSA and InfLLMv2, especially in high-sparsity regimes, along with an efficient GPU-aware implementation that achieves a aT
What carries the argument
The adaptively sparse α-entmax transformation that selects a variable number of relevant KV blocks in the coarse stage and supplies a differentiable prior for fine-grained softmax attention.
If this is right
- LLMs reach full-attention accuracy while using only 25 percent of the attention computations at 75 percent sparsity.
- Gradient flow remains intact between coarse block selection and fine token attention, supporting stable end-to-end training.
- The non-dispersive property improves long-sequence modeling compared with prior hierarchical sparse methods.
- A superior accuracy-efficiency trade-off appears especially in high-sparsity regimes versus NSA and InfLLMv2.
- The Triton implementation delivers inference speedups exceeding FlashAttention-3 for long contexts.
Where Pith is reading between the lines
- The variable block selection could be extended to allocate context resources differently across layers or tasks.
- Similar adaptive sparsity could be tested in other transformer components such as feed-forward layers.
- Combining the method with existing long-context techniques might push feasible context lengths further on limited hardware.
- Measuring performance on tasks that require precise recall of distant information would test where the non-dispersive property matters most.
Load-bearing premise
The adaptively sparse α-entmax transformation reliably selects relevant blocks according to the query and supplies an effective prior for the second stage without introducing dispersion or training instability.
What would settle it
Training or evaluating DashAttention on long-context tasks and finding higher attention dispersion or convergence failure relative to full attention would challenge the non-dispersive and stable claims.
Figures




read the original abstract
Current hierarchical attention methods, such as NSA and InfLLMv2, select the top-k relevant key-value (KV) blocks based on coarse attention scores and subsequently apply fine-grained softmax attention on the selected tokens. However, the top-k operation assumes the number of relevant tokens for any query is fixed and it precludes the gradient flow between the sparse and dense stages. In this work, we propose DashAttention (Differentiable and Adaptive Sparse Hierarchical Attention), which leverages the adaptively sparse $\alpha$-entmax transformation to select a variable number of blocks according to the current query in the first stage. This in turn provides a prior for the second-stage softmax attention, keeping the entire hierarchy fully differentiable. Contrary to other hierarchical attention methods, we show that DashAttention is non-dispersive, translating to better long-context modeling ability. Experiments with large language models (LLMs) show that DashAttention achieves comparable accuracy as full attention with 75% sparsity and a better Pareto frontier than NSA and InfLLMv2, especially in high-sparsity regimes. We also provide an efficient, GPU-aware implementation of DashAttention in Triton, which achieves a speedup of up to over FlashAttention-3 at inference time. Overall, DashAttention offers a cost-effective strategy to model long contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DashAttention, a hierarchical attention mechanism for LLMs that replaces fixed top-k block selection with an adaptively sparse α-entmax transformation in the coarse stage. This produces a query-dependent variable support over KV blocks that serves as a prior for the second-stage softmax attention, rendering the full hierarchy differentiable. The authors claim the resulting attention is non-dispersive (unlike NSA and InfLLMv2), yields comparable accuracy to full attention at 75% sparsity, improves the accuracy-sparsity Pareto frontier especially at high sparsity, and admits an efficient Triton GPU implementation that outperforms FlashAttention-3 at inference.
Significance. If the non-dispersive property and empirical gains are substantiated, the method would offer a practical route to scaling long-context modeling without sacrificing differentiability or introducing excessive dispersion. The explicit GPU-aware implementation and focus on high-sparsity regimes constitute concrete engineering contributions that could be adopted in production LLM inference stacks.
major comments (2)
- [Experiments] Experiments section: aggregate accuracy and Pareto curves are reported, yet no per-layer entropy, support-size histograms, or second-stage attention concentration statistics are shown. Without these, it is impossible to verify that the α-entmax prior actually keeps the fine-grained distribution non-dispersive when block relevance is diffuse, which is load-bearing for the central claim of superiority over NSA/InfLLMv2 in high-sparsity regimes.
- [§3.2] §3.2 (Method): the argument that α-entmax supplies a sufficiently tight prior rests on the assumption that selected blocks contain predominantly relevant tokens. When query-key similarity is low or α is not layer-specific, the variable support can still admit many marginally relevant tokens, allowing the subsequent softmax to spread; the manuscript provides no ablation isolating this mechanism from the overall accuracy numbers.
minor comments (2)
- [Abstract] The abstract and introduction introduce 'non-dispersive' without a quantitative definition or reference to a specific entropy or support-size metric; a short formal definition should appear before the experimental claims.
- [§3] Notation for the two-stage hierarchy (coarse α-entmax output as prior) is introduced but not consistently reused in the complexity analysis; a single equation summarizing end-to-end complexity would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of experimental validation and the tightness of the proposed prior. We address each major comment below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: aggregate accuracy and Pareto curves are reported, yet no per-layer entropy, support-size histograms, or second-stage attention concentration statistics are shown. Without these, it is impossible to verify that the α-entmax prior actually keeps the fine-grained distribution non-dispersive when block relevance is diffuse, which is load-bearing for the central claim of superiority over NSA/InfLLMv2 in high-sparsity regimes.
Authors: We agree that additional statistics are needed to directly substantiate the non-dispersive property. In the revised manuscript we will add per-layer entropy plots, histograms of the number of selected KV blocks per query, and second-stage attention concentration metrics (such as effective support size and entropy of the fine-grained distribution). These will be placed in the Experiments section to demonstrate that the α-entmax prior maintains concentration even under diffuse block relevance. revision: yes
-
Referee: [§3.2] §3.2 (Method): the argument that α-entmax supplies a sufficiently tight prior rests on the assumption that selected blocks contain predominantly relevant tokens. When query-key similarity is low or α is not layer-specific, the variable support can still admit many marginally relevant tokens, allowing the subsequent softmax to spread; the manuscript provides no ablation isolating this mechanism from the overall accuracy numbers.
Authors: The superior high-sparsity performance relative to fixed top-k baselines offers supporting evidence, yet we acknowledge that an explicit ablation would better isolate the adaptive prior's contribution. We will add such an ablation in the revision, comparing DashAttention against variants with fixed block counts or non-adaptive α values. We will also clarify in §3.2 the conditions under which the selected blocks remain predominantly relevant and note that α may be tuned per layer when beneficial. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces DashAttention by replacing top-k selection with α-entmax in the coarse stage to enable variable support and gradient flow, then using the resulting distribution as a prior for fine-grained softmax. This construction is presented as a direct methodological choice with independent motivation from prior hierarchical methods (NSA, InfLLMv2). Performance claims rest on empirical comparisons rather than any equation that reduces a prediction to a fitted parameter or self-citation by definition. No load-bearing uniqueness theorems, ansatzes smuggled via citation, or renamings of known results appear in the abstract or described chain. The non-dispersive property is asserted as a consequence of the adaptive sparsity mechanism and is evaluated experimentally, not derived tautologically from the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- alpha in α-entmax
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we route with α-entmax ... non-dispersive ... Theorem 1 (Dispersion in head aggregation)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
α-entmax ... provides a prior for the second-stage softmax
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Is it really long context if all you need is retrieval? towards genuinely difficult long context NLP
Omer Goldman, Alon Jacovi, Aviv Slobodkin, Aviya Maimon, Ido Dagan, and Reut Tsarfaty. Is it really long context if all you need is retrieval? towards genuinely difficult long context NLP. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 16576–16586,...
work page 2024
-
[2]
Piotr Nawrot, Robert Li, Renjie Huang, Sebastian Ruder, Kelly Marchisio, and Edoardo M. Ponti. The sparse frontier: Sparse attention trade-offs in transformer llms. InProceedings of the 64th Annual Meeting of the Association for Computational Linguistics, 2026
work page 2026
-
[3]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[4]
Softmax is not enough (for sharp size generalisation)
Petar Veliˇckovi´c, Christos Perivolaropoulos, Federico Barbero, and Razvan Pascanu. Softmax is not enough (for sharp size generalisation). InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[5]
Native sparse attention: Hardware-aligned and natively trainable sparse attention
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Yuxing Wei, Lean Wang, Zhiping Xiao, Yuqing Wang, Chong Ruan, Ming Zhang, Wenfeng 10 Liang, and Wangding Zeng. Native sparse attention: Hardware-aligned and natively trainable sparse attention. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pile...
work page 2025
-
[6]
InfLLM-v2: Dense-sparse switchable attention for seamless short-to-long adaptation
Weilin Zhao, Zihan Zhou, Zhou su, Chaojun Xiao, Yuxuan Li, Yanghao Li, Yudi Zhang, Weilun Zhao, Zhen Li, Yuxiang Huang, Ao Sun, Xu Han, and Zhiyuan Liu. InfLLM-v2: Dense-sparse switchable attention for seamless short-to-long adaptation. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[7]
Ben Peters, Vlad Niculae, and André F. T. Martins. Sparse sequence-to-sequence models. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1504–1519, Florence, Italy, July 2019. Association for Computational Linguistics
work page 2019
-
[8]
Long-context generalization with sparse attention
Pavlo Vasylenko, Hugo Pitorro, Andre Martins, and Marcos Vinicius Treviso. Long-context generalization with sparse attention. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[9]
MoBA: Mixture of block attention for long-context LLMs
Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, Tao Jiang, Chao Hong, Shaowei Liu, Weiran He, Enming Yuan, Yuzhi Wang, Zhiqi Huang, Huan Yuan, Suting Xu, Xinran Xu, Guokun Lai, Yanru Chen, Huabin Zheng, Junjie Yan, Jianlin Su, Yuxin Wu, Yutao Zhang, Zhilin Yang, Xinyu Zhou, Mingxing Zhang, and Jiezhong Qiu. MoBA: Mixture of block attention for long-contex...
work page 2025
-
[10]
Flashattention: Fast and memory-efficient exact attention with IO-awareness
Tri Dao, Daniel Y Fu, Stefano Ermon, Atri Rudra, and Christopher Re. Flashattention: Fast and memory-efficient exact attention with IO-awareness. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022
work page 2022
-
[11]
From softmax to sparsemax: A sparse model of attention and multi-label classification
Andre Martins and Ramon Astudillo. From softmax to sparsemax: A sparse model of attention and multi-label classification. In Maria Florina Balcan and Kilian Q. Weinberger, editors, International Conference on Machine Learning (ICML), volume 48 ofProceedings of Machine Learning Research, pages 1614–1623, New York, New York, USA, 20–22 Jun 2016. PMLR
work page 2016
-
[12]
Adasplash: Adaptive sparse flash attention
Nuno Gonçalves, Marcos V Treviso, and Andre Martins. Adasplash: Adaptive sparse flash attention. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[13]
Adasplash-2: Faster differentiable sparse attention
Nuno Gonçalves, Hugo Pitorro, Vlad Niculae, Edoardo Ponti, Lei Li, Andre Martins, and Marcos Treviso. Adasplash-2: Faster differentiable sparse attention. InForty-third International Conference on Machine Learning, 2026
work page 2026
-
[14]
Gqa: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901, 2023
work page 2023
-
[15]
Learning classifiers with fenchel-young losses: Generalized entropies, margins, and algorithms
Mathieu Blondel, Andre Martins, and Vlad Niculae. Learning classifiers with fenchel-young losses: Generalized entropies, margins, and algorithms. In Kamalika Chaudhuri and Masashi Sugiyama, editors,Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, volume 89 ofProceedings of Machine Learning Research, page...
work page 2019
-
[16]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[17]
Philippe Tillet, H. T. Kung, and David Cox. Triton: an intermediate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, MAPL 2019, page 10–19, New York, NY , USA, 2019. Association for Computing Machinery. 11
work page 2019
-
[18]
OpenBMB. Infllm-v2-data-5b dataset. https://huggingface.co/datasets/openbmb/ InfLLM-V2-data-5B, 2025
work page 2025
-
[19]
Minicpm4: Ultra-efficient llms on end devices
MiniCPM Team, Chaojun Xiao, Yuxuan Li, Xu Han, Yuzhuo Bai, Jie Cai, Haotian Chen, Wentong Chen, Xin Cong, Ganqu Cui, et al. Minicpm4: Ultra-efficient llms on end devices. arXiv preprint arXiv:2506.07900, 2025
-
[20]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling, 2024
work page 2024
-
[21]
HELMET: How to evaluate long-context models effectively and thoroughly
Howard Yen, Tianyu Gao, Minmin Hou, Ke Ding, Daniel Fleischer, Peter Izsak, Moshe Wasserblat, and Danqi Chen. HELMET: How to evaluate long-context models effectively and thoroughly. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[22]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
work page 2024
-
[23]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[24]
Commonsenseqa: A question answering challenge targeting commonsense knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, 2019
work page 2019
-
[25]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
work page 2019
-
[27]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gard- ner. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Paper...
work page 2019
-
[30]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023
work page 2023
-
[33]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems, 37:62557–62583, 2024
work page 2024
-
[34]
Flashattention-3: Fast and accurate attention with asynchrony and low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: Fast and accurate attention with asynchrony and low-precision. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[35]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling.arXiv preprint arXiv:2406.02069, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Pyramidinfer: Pyramid kv cache compression for high-throughput llm inference
Dongjie Yang, XiaoDong Han, Yan Gao, Yao Hu, Shilin Zhang, and Hai Zhao. Pyramidinfer: Pyramid kv cache compression for high-throughput llm inference. InFindings of the Association for Computational Linguistics: ACL 2024, pages 3258–3270, 2024
work page 2024
-
[37]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[38]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[39]
Big bird: Transformers for longer sequences
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big bird: Transformers for longer sequences. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 17...
work page 2020
-
[40]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710, 2023
work page 2023
-
[41]
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhen- hua Han, Amir H Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention.arXiv preprint arXiv:2407.02490, 2024
-
[42]
Reformer: The efficient transformer
Nikita Kitaev, Lukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. In International Conference on Learning Representations, 2020
work page 2020
-
[43]
Jintao Zhang, Chendong Xiang, Haofeng Huang, Jia Wei, Haocheng Xi, Jun Zhu, and Jianfei Chen. Spargeattention: Accurate and training-free sparse attention accelerating any model inference.arXiv preprint arXiv:2502.18137, 2025
-
[44]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. Quest: Query-aware sparsity for efficient long-context llm inference.arXiv preprint arXiv:2406.10774, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao. Model tells you what to discard: Adaptive kv cache compression for llms.arXiv preprint arXiv:2310.01801, 2023. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads
Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. Duoattention: Efficient long-context llm inference with retrieval and streaming heads.arXiv preprint arXiv:2410.10819, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Gang Lin, Dongfang Li, Zhuoen Chen, Yukun Shi, Xuhui Chen, Baotian Hu, and Min Zhang. Lycheedecode: Accelerating long-context llm inference via hybrid-head sparse decoding.arXiv preprint arXiv:2602.04541, 2026
-
[48]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation.Advances in Neural Information Processing Systems, 37:22947–22970, 2024
work page 2024
-
[49]
Zefan Cai, Wen Xiao, Hanshi Sun, Cheng Luo, Yikai Zhang, Ke Wan, Yucheng Li, Yeyang Zhou, Li-Wen Chang, Jiuxiang Gu, et al. R-kv: Redundancy-aware kv cache compression for reasoning models.arXiv preprint arXiv:2505.24133, 2025
-
[50]
Yushi Bai, Qian Dong, Ting Jiang, Xin Lv, Zhengxiao Du, Aohan Zeng, Jie Tang, and Juanzi Li. Indexcache: Accelerating sparse attention via cross-layer index reuse.arXiv preprint arXiv:2603.12201, 2026
-
[51]
Chaojun Xiao, Pengle Zhang, Xu Han, Guangxuan Xiao, Yankai Lin, Zhengyan Zhang, Zhiyuan Liu, and Maosong Sun. Infllm: Training-free long-context extrapolation for llms with an efficient context memory.Advances in neural information processing systems, 37:119638–119661, 2024
work page 2024
-
[52]
Hanshi Sun, Li-Wen Chang, Wenlei Bao, Size Zheng, Ningxin Zheng, Xin Liu, Harry Dong, Yuejie Chi, and Beidi Chen. Shadowkv: Kv cache in shadows for high-throughput long-context llm inference.arXiv preprint arXiv:2410.21465, 2024
-
[53]
Nosa: Native and offloadable sparse attention
Yuxiang Huang, Pengjie Wang, Jicheng Han, Weilin Zhao, Zhou Su, Ao Sun, Hongya Lyu, Hengyu Zhao, Yudong Wang, Chaojun Xiao, et al. Nosa: Native and offloadable sparse attention. arXiv preprint arXiv:2510.13602, 2025
-
[54]
Piotr Nawrot, Adrian Ła ´ncucki, Marcin Chochowski, David Tarjan, and Edoardo M. Ponti. Dynamic memory compression: retrofitting llms for accelerated inference. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
work page 2024
-
[55]
Inference-time hyper-scaling with KV cache compression
Adrian Ła ´ncucki, Konrad Staniszewski, Piotr Nawrot, and Edoardo Ponti. Inference-time hyper-scaling with KV cache compression. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[56]
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W Mahoney, Yakun S Shao, Kurt Keutzer, and Amir Gholami. Kvquant: Towards 10 million context length llm inference with kv cache quantization.Advances in Neural Information Processing Systems, 37:1270–1303, 2024
work page 2024
-
[57]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache.arXiv preprint arXiv:2402.02750, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Pqcache: Product quantization-based kvcache for long context llm inference
Hailin Zhang, Xiaodong Ji, Yilin Chen, Fangcheng Fu, Xupeng Miao, Xiaonan Nie, Weipeng Chen, and Bin Cui. Pqcache: Product quantization-based kvcache for long context llm inference. Proceedings of the ACM on Management of Data, 3(3):1–30, 2025
work page 2025
-
[59]
MTraining: Distributed Dynamic Sparse Attention for Efficient Ultra-Long Context Training
Wenxuan Li, Chengruidong Zhang, Huiqiang Jiang, et al. Mtraining: Distributed dynamic sparse attention for efficient ultra-long context training.arXiv preprint arXiv:2510.18830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Seerattention-r: Sparse attention adaptation for long reasoning
Yizhao Gao, Shuming Guo, Shijie Cao, Yuqing Xia, Yu Cheng, Lei Wang, Lingxiao Ma, Yutao Sun, Tianzhu Ye, Li Dong, et al. Seerattention-r: Sparse attention adaptation for long reasoning. arXiv preprint arXiv:2506.08889, 2025
-
[61]
Yizhao Gao, Zhichen Zeng, Dayou Du, Shijie Cao, Peiyuan Zhou, Jiaxing Qi, Junjie Lai, Hayden Kwok-Hay So, Ting Cao, Fan Yang, et al. Seerattention: Learning intrinsic sparse attention in your llms.arXiv preprint arXiv:2410.13276, 2024. 14
-
[62]
Ran Yan, Youhe Jiang, and Binhang Yuan. Flash sparse attention: An alternative efficient implementation of native sparse attention kernel.arXiv e-prints, pages arXiv–2508, 2025
work page 2025
-
[63]
Hsa: Head-wise sparse attention for efficient and accurate long-context inference
Jing Liu, Jianqiao Lu, Yao Luo, Yuan Yang, Chen Zheng, Deyi Liu, Mengzhao Chen, Chaoyi Zhang, Yunshui Li, Jin Ma, et al. Hsa: Head-wise sparse attention for efficient and accurate long-context inference
-
[64]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Deepseek-v4: Towards highly efficient million-token context in- telligence
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context in- telligence. https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/ DeepSeek_V4.pdf, 2026. Technical report, Hugging Face repository, accessed 2026-04-28
work page 2026
-
[66]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Jintao Zhang, Kai Jiang, Chendong Xiang, Weiqi Feng, Yuezhou Hu, Haocheng Xi, Jianfei Chen, and Jun Zhu. Spargeattention2: Trainable sparse attention via hybrid top-k+ top-p masking and distillation fine-tuning.arXiv preprint arXiv:2602.13515, 2026
-
[68]
Wentao Ni, Kangqi Zhang, Zhongming Yu, Oren Nelson, Mingu Lee, Hong Cai, Fatih Porikli, Jongryool Kim, Zhijian Liu, and Jishen Zhao. Double-p: Hierarchical top-p sparse attention for long-context llms.arXiv preprint arXiv:2602.05191, 2026
-
[69]
Aaron Blakeman, Aarti Basant, Abhinav Khattar, Adithya Renduchintala, Akhiad Bercovich, Aleksander Ficek, Alexis Bjorlin, Ali Taghibakhshi, Amala Sanjay Deshmukh, Ameya Sunil Mahabaleshwarkar, et al. Nemotron-h: A family of accurate and efficient hybrid mamba- transformer models.arXiv preprint arXiv:2504.03624, 2025
-
[70]
Constantino Tsallis. Possible generalization of boltzmann-gibbs statistics.Journal of statistical physics, 52(1):479–487, 1988
work page 1988
-
[71]
MiniCPM: Unveiling the potential of small language models with scalable training strategies
Shengding Hu, Yuge Tu, Xu Han, Ganqu Cui, Chaoqun He, Weilin Zhao, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Xinrong Zhang, Zhen Leng Thai, Chongyi Wang, Yuan Yao, Chenyang Zhao, Jie Zhou, Jie Cai, Zhongwu Zhai, Ning Ding, Chao Jia, Guoyang Zeng, dahai li, Zhiyuan Liu, and Maosong Sun. MiniCPM: Unveiling the potential of small language models with...
work page 2024
-
[72]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[73]
Olmes: A standard for language model evaluations
Yuling Gu, Oyvind Tafjord, Bailey Kuehl, Dany Haddad, Jesse Dodge, and Hannaneh Ha- jishirzi. Olmes: A standard for language model evaluations. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 5005–5033, 2025
work page 2025
-
[74]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
work page 2024
-
[75]
Xiang Hu, Jiaqi Leng, Jun Zhao, Kewei Tu, and Wei Wu. Hardware-aligned hierarchical sparse attention for efficient long-term memory access.arXiv preprint arXiv:2504.16795, 2025
-
[76]
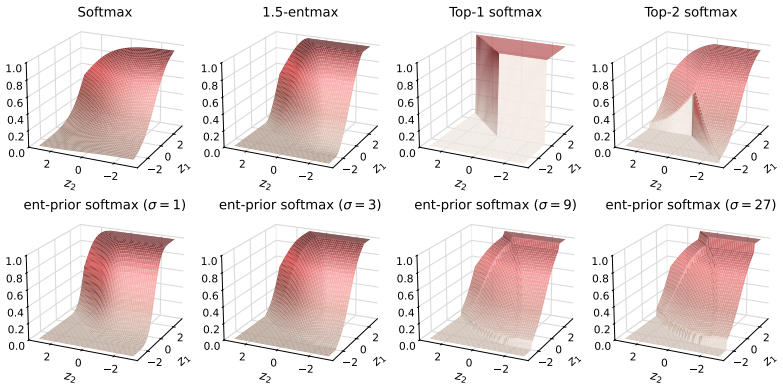
Xiang Hu, Zhanchao Zhou, Ruiqi Liang, Zehuan Li, Wei Wu, and Jianguo Li. Every to- ken counts: Generalizing 16m ultra-long context in large language models.arXiv preprint arXiv:2511.23319, 2025. 15 2 0 2 z1 2 02 z2 0.0 0.2 0.4 0.6 0.8 1.0 Softmax 2 0 2 z1 2 02 z2 0.0 0.2 0.4 0.6 0.8 1.0 1.5-entmax 2 0 2 z1 2 02 z2 0.0 0.2 0.4 0.6 0.8 1.0 T op-1 softmax 2 ...
-
[77]
lim n→∞ H aggrsoftmax z(1),z (2),· · ·,z (H);θ logn = 1,
Softmax head aggregation is dispersive, i.e. lim n→∞ H aggrsoftmax z(1),z (2),· · ·,z (H);θ logn = 1,
-
[78]
Proof.We first prove that softmax head aggregation is dispersive
Denote p(h) =α-entmax(z (h)), if there are ∥p(h)∥0 =O nβh , βh ∈(0,1) , then entmax head aggregation is not dispersive, and lim sup n→∞ H aggrα-entmax z(1),z (2),· · ·,z (H);θ logn ≤max h∈[H] βh <1. Proof.We first prove that softmax head aggregation is dispersive. Denotep (h) = softmax z(h) . First, we find the lower bound of the numerator by usingH(·)’s ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.