Semantic Quorum Assurance: Collective Certification for Non-Deterministic AI Infrastructure
Pith reviewed 2026-06-27 20:14 UTC · model grok-4.3
The pith
Semantic Quorum Assurance routes infrastructure proposals to diverse sandboxed validators and admits them only under a risk-adaptive quorum, cutting unsafe approvals from 18.5% to 0.3%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
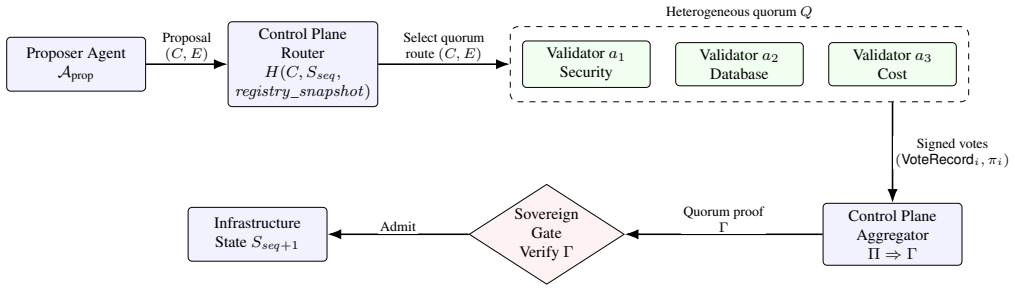
Semantic Quorum Assurance represents proposals as declarative execution contracts bound to cryptographic evidence chains and routes them to a diverse panel of read-only sandboxed validator agents. Their judgments are aggregated under a risk-adaptive quorum predicate that enforces model and archetype diversity, adjusts weights by calibrated assurance scores, and respects archetype-specific vetoes. Admitted proposals execute only through a sovereign execution gate. On 500 infrastructure-inspired mutation scenarios, with results on held-out safe and unsafe trials, the method reduces unsafe approval from 18.5% for single-agent validation to 0.3% while adding median validation latency of 1.45--4.
What carries the argument
The risk-adaptive quorum predicate, which aggregates judgments from diverse validators while enforcing diversity, weighting by assurance scores, and applying archetype vetoes.
If this is right
- Proposals execute only after passing the quorum through the sovereign execution gate.
- Validation adds between 1.45 and 4.12 seconds of median latency depending on the risk bucket.
- Results hold on held-out safe and unsafe trials drawn from 500 infrastructure mutation scenarios.
- The predicate explicitly respects archetype-specific vetoes and calibrated assurance scores.
Where Pith is reading between the lines
- The same quorum structure could be tested on other classes of agent-proposed actions beyond cloud infrastructure.
- Maintaining long-term diversity and calibration of the validator panel would require ongoing monitoring not detailed in the current experiments.
- If correlation of failures proves higher than modeled, hybrid human-in-the-loop gates might still be needed for high-risk buckets.
Load-bearing premise
The failures across different validator models and archetypes are not too strongly correlated.
What would settle it
A controlled deployment in which validator error patterns turn out to be highly correlated, so that the unsafe approval rate stays near the single-agent baseline of 18.5%.
Figures

read the original abstract
As large language model (LLM) agents are integrated into autonomous cloud operations, distributed systems face a semantic reliability problem: proposer agents can generate production mutations, such as modifying IAM policies, opening firewall security groups, or executing data exports, that are syntactically valid and statically authorized but operationally unsafe. Classical distributed consensus protocols replicate deterministic state transitions but do not evaluate the safety of the proposed intent. To address this gap, we introduce Semantic Quorum Assurance (SQA), a control-plane primitive for governing non-deterministic agentic infrastructure. SQA represents proposals as declarative execution contracts bound to cryptographic evidence chains and routes them to a diverse panel of read-only, sandboxed validator agents. SQA aggregates their judgments under a risk-adaptive quorum predicate that enforces model and archetype diversity, adjusts weights based on calibrated assurance scores, and respects archetype-specific vetoes. Admitted proposals execute only through a sovereign execution gate. We instantiate SQA in a cloud-native control plane and formalize a correlated cognitive failure model for non-deterministic validators. On 500 infrastructure-inspired mutation scenarios, with safety results reported on held-out safe/unsafe trials excluding ambiguous scenarios, SQA reduces unsafe approval from 18.5% for single-agent validation to 0.3% while adding median validation latency of 1.45--4.12 seconds across the studied risk buckets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Semantic Quorum Assurance (SQA) as a control-plane primitive for non-deterministic LLM agents operating on cloud infrastructure. Proposals are represented as declarative execution contracts routed to a diverse panel of read-only sandboxed validator agents; judgments are aggregated by a risk-adaptive quorum predicate that enforces model/archetype diversity, applies calibrated weights, and respects archetype-specific vetoes. The paper formalizes a correlated cognitive failure model and reports an empirical result on 500 infrastructure-inspired mutation scenarios (held-out safe/unsafe trials, excluding ambiguous cases): unsafe approvals fall from 18.5% under single-agent validation to 0.3% under SQA, with median added validation latency of 1.45–4.12 s across risk buckets.
Significance. If the reported reduction is robust and the low-correlation premise among validators can be substantiated, SQA would supply a practical mechanism for semantic safety that classical deterministic consensus protocols lack. The modest latency overhead and the explicit modeling of correlated failures are positive features that could support further work on AI-governed infrastructure.
major comments (2)
- [Abstract] Abstract: the central empirical claim (unsafe approvals reduced from 18.5% to 0.3%) supplies no description of scenario generation, labeling protocol, how 'infrastructure-inspired' mutations were created or partitioned, the exact definition of held-out safe/unsafe trials, the exclusion rules applied to ambiguous scenarios, or the statistical procedure that produced the 0.3% figure. These omissions render the headline performance result unverifiable.
- [Abstract] Abstract: the manuscript invokes a 'correlated cognitive failure model' and states that SQA 'enforces model and archetype diversity' and 'adjusts weights based on calibrated assurance scores,' yet no equations, parameters, pairwise correlation measurements, or ablation removing the diversity mechanism are provided. Because the claimed reduction to 0.3% holds only when validator failures are not strongly correlated, the absence of any quantification or sensitivity analysis on this assumption is load-bearing for the central claim.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the abstract. Both points correctly identify that key methodological and modeling details are omitted from the abstract, which limits verifiability of the central claims. We will revise the abstract and, where appropriate, the body to supply the requested information while preserving conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (unsafe approvals reduced from 18.5% to 0.3%) supplies no description of scenario generation, labeling protocol, how 'infrastructure-inspired' mutations were created or partitioned, the exact definition of held-out safe/unsafe trials, the exclusion rules applied to ambiguous scenarios, or the statistical procedure that produced the 0.3% figure. These omissions render the headline performance result unverifiable.
Authors: We agree that the abstract, as currently written, does not supply these details. In the revised manuscript we will add a concise clause to the abstract describing the scenario-generation method, labeling protocol, held-out partitioning, ambiguous-case exclusion rules, and the statistical procedure used to obtain the 0.3 % figure. revision: yes
-
Referee: [Abstract] Abstract: the manuscript invokes a 'correlated cognitive failure model' and states that SQA 'enforces model and archetype diversity' and 'adjusts weights based on calibrated assurance scores,' yet no equations, parameters, pairwise correlation measurements, or ablation removing the diversity mechanism are provided. Because the claimed reduction to 0.3% holds only when validator failures are not strongly correlated, the absence of any quantification or sensitivity analysis on this assumption is load-bearing for the central claim.
Authors: We concur that the abstract contains no equations, parameters, correlation measurements, or ablation results for the correlated cognitive failure model. The revised version will incorporate the principal equations and a brief sensitivity analysis (including an ablation that removes the diversity mechanism) either directly in the abstract or via an explicit pointer to the newly expanded methods subsection. revision: yes
Circularity Check
No circularity: empirical result on held-out trials is independent of inputs
full rationale
The paper reports an empirical outcome (unsafe approvals drop from 18.5% to 0.3% on held-out trials from 500 scenarios) measured after applying the SQA quorum predicate. No equations, fitted parameters, or self-citations are shown that would make this number equivalent to the model inputs or the diversity assumptions by construction. The correlated cognitive failure model is formalized as part of the system description, but the reported safety numbers are presented as direct experimental measurements rather than derived predictions, satisfying the criteria for a self-contained empirical claim.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Sovereign Assurance Boundary: Certificate-Bound Admission for Agentic Infrastructure
SAB introduces a certificate-bound runtime admission system that converts agent proposals into typed contracts bound to evidence digests and policy versions, emitting signed certificates verified by an execution broke...
Reference graph
Works this paper leans on
-
[1]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022
Pith/arXiv arXiv 2022
-
[2]
Toolformer: Language models can teach themselves to use tools.arXiv preprint arXiv:2302.04761, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Can- cedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.arXiv preprint arXiv:2302.04761, 2023
Pith/arXiv arXiv 2023
-
[3]
The part-time parliament.ACM Trans- actions on Computer Systems (TOCS), 16(2):133–169, 1998
Leslie Lamport. The part-time parliament.ACM Trans- actions on Computer Systems (TOCS), 16(2):133–169, 1998
1998
-
[4]
In search of an understandable consensus algorithm
Diego Ongaro and John Ousterhout. In search of an understandable consensus algorithm. InProceedings of the USENIX Annual Technical Conference (ATC), pages 305–320, 2014
2014
-
[5]
Practical byzantine fault tolerance
Miguel Castro and Barbara Liskov. Practical byzantine fault tolerance. InProceedings of the Symposium on Operating Systems Design and Implementation (OSDI), pages 173–186, 1999
1999
-
[6]
Schneider
Fred B. Schneider. Implementing fault-tolerant services using the state machine replication approach: A tutorial. ACM Computing Surveys (CSUR), 22(4):299–319, 1990
1990
-
[7]
Aggregate and verifiable multisignatures from bilinear maps
Dan Boneh, Craig Gentry, Ben Lynn, and Hovav Shacham. Aggregate and verifiable multisignatures from bilinear maps. InProceedings of the International Cryptology Conference (ASIACRYPT), pages 416–432, 2003
2003
-
[8]
gVisor documentation
gVisor Project. gVisor documentation. https:// gvisor.dev/docs/, 2026. Accessed 2026-06-05
2026
-
[9]
The byzantine generals problem.ACM Transactions on Programming Languages and Systems (TOPLAS), 4(3):382–401, 1982
Leslie Lamport, Robert Shostak, and Marshall Pease. The byzantine generals problem.ACM Transactions on Programming Languages and Systems (TOPLAS), 4(3):382–401, 1982
1982
-
[10]
Byzantine quorum systems.Distributed Computing, 11(4):203–213, 1998
Dahlia Malkhi and Michael Reiter. Byzantine quorum systems.Distributed Computing, 11(4):203–213, 1998
1998
-
[11]
Knight and Nancy G
John C. Knight and Nancy G. Leveson. An experimental evaluation of the assumption of independence in multi- version programming.IEEE Transactions on Software Engineering, SE-12(1):96–109, 1986
1986
-
[12]
Using simplicity to control complexity.IEEE Software, 18(4):20–28, 2001
Lui Sha. Using simplicity to control complexity.IEEE Software, 18(4):20–28, 2001
2001
-
[13]
Shield synthesis: Runtime enforcement for reactive systems
Roderick Bloem, Bettina Könighofer, Robert Könighofer, and Chao Wang. Shield synthesis: Runtime enforcement for reactive systems. InPro- ceedings of the International Conference on Tools and Algorithms for the Construction and Analysis of Systems (TACAS), pages 533–548, 2015
2015
-
[14]
Safe reinforcement learning via shielding
Mohammed Alshiekh, Roderick Bloem, Rüdiger Ehlers, Bettina Könighofer, Scott Niekum, and Ufuk Topcu. Safe reinforcement learning via shielding. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 2669–2678, 2018
2018
-
[15]
Smolka, and Scott D
Dzung Phan, Radu Grosu, Nils Jansen, Nicola Paoletti, Scott A. Smolka, and Scott D. Stoller. Neural simplex architecture. InNASA Formal Methods Symposium, pages 97–114, 2020
2020
-
[16]
Security assurance cases: Motivation and research agenda.System Safety Society, 2001
John Rushby. Security assurance cases: Motivation and research agenda.System Safety Society, 2001
2001
-
[17]
Policy language
Open Policy Agent. Policy language. Open Policy Agent documentation, 2026. Accessed 2026-06-05
2026
-
[18]
OPA for kubernetes admission con- trol
Open Policy Agent. OPA for kubernetes admission con- trol. Open Policy Agent documentation, 2026. Accessed 2026-06-05. 20
2026
-
[19]
Dynamic admission control
Kubernetes. Dynamic admission control. Kubernetes documentation, 2026. Accessed 2026-06-05
2026
-
[20]
Aws identity and access management (iam) user guide
AWS. Aws identity and access management (iam) user guide. InAmazon Web Services Technical Documenta- tion, 2024
2024
-
[21]
Service control policies in AWS organizations
Amazon Web Services. Service control policies in AWS organizations. AWS documentation, 2026. Accessed 2026-06-05
2026
-
[22]
Zero trust architecture
Scott Rose, Oliver Borchert, Stu Mitchell, and Sean Con- nelly. Zero trust architecture. Technical Report Special Publication 800-207, National Institute of Standards and Technology (NIST), 2020
2020
-
[23]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuo- han Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and chatbot arena. InAdvances in Neural Information Processing Systems, 2023
2023
-
[24]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations, 2023
2023
-
[25]
Encouraging divergent thinking in LLMs via multi-agent debate.arXiv preprint arXiv:2305.19118, 2023
Tian Liang, Zhiheng Xi, Sara Xu, Yiwen Wang, Taipeng Li, Wensen Zhou, Yifan Lu, Xiaoxian Wu, Dong Shen, Lu Chen, et al. Encouraging divergent thinking in LLMs via multi-agent debate.arXiv preprint arXiv:2305.19118, 2023
Pith/arXiv arXiv 2023
-
[26]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate.arXiv preprint arXiv:2305.14325, 2023
Pith/arXiv arXiv 2023
-
[27]
Survey of hallucination in natural language processing.ACM Computing Surveys (CSUR), 55(12):1–38, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language processing.ACM Computing Surveys (CSUR), 55(12):1–38, 2023
2023
-
[28]
Weinberger
Chuan Guo, Geoff Pleiss, Sunjana Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. InProceedings of the International Conference on Ma- chine Learning (ICML), pages 1321–1330, 2017
2017
-
[29]
Selective classifi- cation for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classifi- cation for deep neural networks. InAdvances in Neu- ral Information Processing Systems, pages 4885–4894, 2017
2017
-
[30]
Selectivenet: A deep neural network with an integrated reject option
Yonatan Geifman and Ran El-Yaniv. Selectivenet: A deep neural network with an integrated reject option. InProceedings of the International Conference on Ma- chine Learning, pages 2151–2159, 2019
2019
-
[31]
Ignore previous prompt: Attack techniques for language models.arXiv preprint arXiv:2211.09527, 2022
Fäbio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models.arXiv preprint arXiv:2211.09527, 2022
Pith/arXiv arXiv 2022
-
[32]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injec- tion.arXiv preprint arXiv:2302.12173, 2023
Pith/arXiv arXiv 2023
-
[33]
Jingwei Yi, Yueqi Xie, Bin Zhu, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu. Bench- marking and defending against indirect prompt injec- tion attacks on large language models.arXiv preprint arXiv:2312.14197, 2023
arXiv 2023
-
[34]
OW ASP top 10 for large language model applications
OW ASP Foundation. OW ASP top 10 for large language model applications. OWASP project page, 2025. Ac- cessed 2026-06-05
2025
-
[35]
Hakan Inan, Kartikeya Upasani, Jian Zhang, Rashi Rungta, Riza Aktas, Felipe Cruz, Jason Ramapuram, Stephen Hicks, Onur Dilek, Igor Molybog, et al. Llama Guard: LLM-based input-output safeguard for human- AI conversations.arXiv preprint arXiv:2312.06674, 2023
Pith/arXiv arXiv 2023
-
[36]
Traian Rebedea, Sandeep Subramanian, Vlas Kukanov, Amit Sharma, Shrimai Prabhumoye, Senthil Purush- walkam, Gokul Swamy, Vaibhav Singh, and Christopher Parisien. NeMo Guardrails: A toolkit for controlling the outputs of large language model applications.arXiv preprint arXiv:2310.10501, 2023. 21
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.