MASK: Multi-Agent Semantic K-Scheduling for Risk-Sensitive 6G Robotics
Pith reviewed 2026-06-27 16:16 UTC · model grok-4.3
The pith
MASK lets robot swarms match full-communication performance even when only a small fraction of agents transmit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MASK uses Arbiter-Assisted Semantic Information Gating to schedule only the top-K agents by their locally computed semantic importance scores, aggregates the selected observations into a compact latent state via a self-supervised global encoder, and applies a distributional policy to mitigate tail risks despite the resulting data sparsity, thereby matching the performance of communication-unconstrained baselines even when channel access is restricted to a small fraction of the swarm size.
What carries the argument
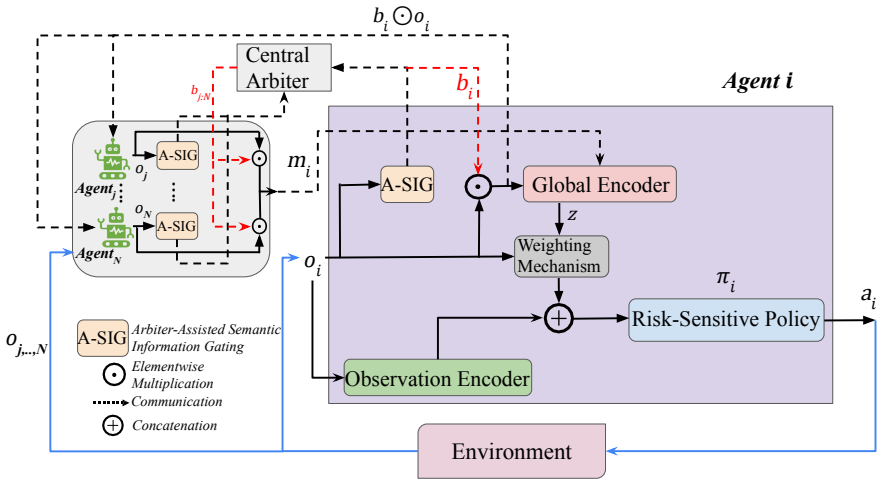
Arbiter-Assisted Semantic Information Gating (A-SIG), which enforces hard bandwidth constraints by selecting and transmitting only the top-K agents according to locally computed semantic importance scores.
If this is right
- Performance matches communication-unconstrained baselines when only a small fraction of the swarm transmits.
- The framework maintains coordination under packet erasures.
- Semantic prioritization enables risk-sensitive control in strictly bandwidth-limited 6G robotic systems.
- A self-supervised global encoder can still support policy learning despite severe data sparsity induced by K-scheduling.
Where Pith is reading between the lines
- If the semantic scores remain reliable across tasks, the same gating logic could reduce required bandwidth in other multi-agent sensing settings.
- The resilience to erasures suggests the method may tolerate additional channel impairments common in real wireless deployments.
- Distributional policies paired with selective observation may offer a general route to risk control when communication budgets vary over time.
Load-bearing premise
Locally computed semantic importance scores must reliably identify which individual observations are most useful for the swarm's global coordination, and the encoder must still produce a usable latent state from the sparse selected data.
What would settle it
An experiment in which K equals 10 percent of swarm size and the tail-risk metric of the distributional policy falls more than a few percent below the unconstrained baseline across multiple benchmarks would falsify the central claim.
Figures
read the original abstract
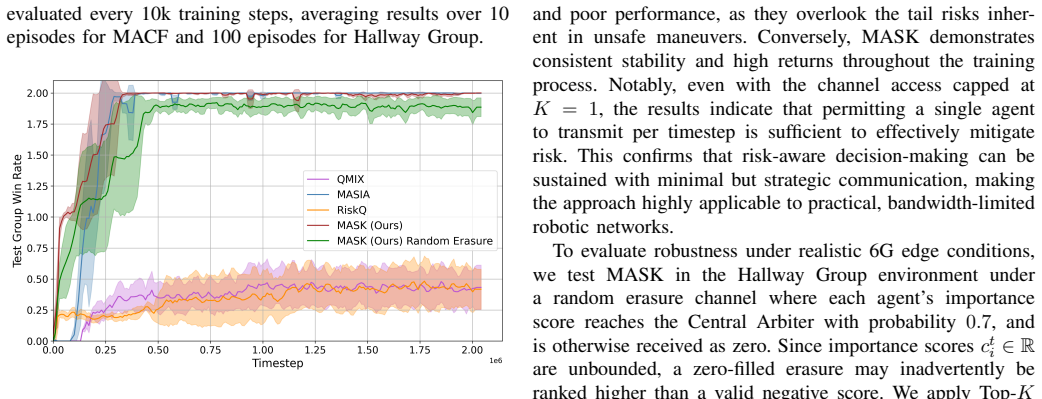
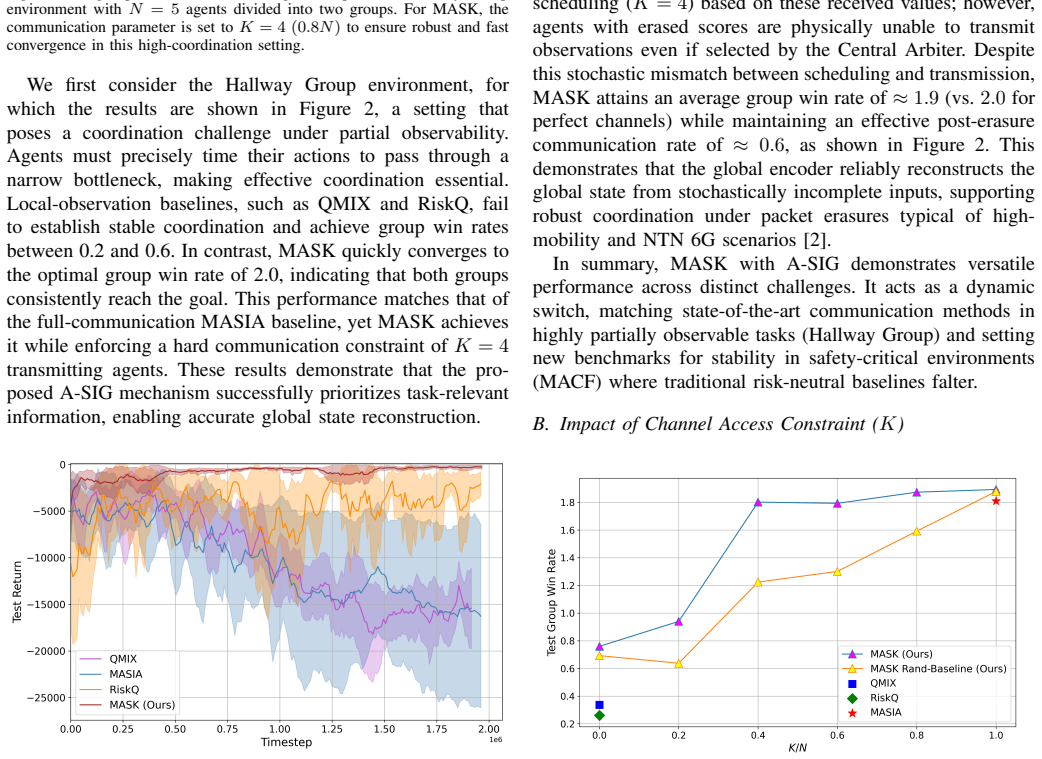
Realizing the vision of 6G connected robotics requires reconciling high-performance collaborative control with the rigid spectral limitations of physical wireless channels. In realistic collaborative sensing scenarios, spectral resources are quantized into finite physical resource blocks or orthogonal subcarriers, rendering simultaneous transmission by all agents infeasible. To address this, we propose Multi-Agent Semantic K-Scheduling (MASK), a control architecture designed to sustain robust, risk-aware coordination under strict instantaneous bandwidth caps. We introduce Arbiter-Assisted Semantic Information Gating (A-SIG), a lightweight coordination mechanism that enforces hard access constraints by scheduling only the top-K agents based on locally computed semantic importance scores. By aggregating these prioritized observations into a compact latent state, a self-supervised global encoder enables a distributional policy to mitigate tail risks despite data sparsity. We evaluate MASK across diverse benchmarks, demonstrating that it matches the performance of communication-unconstrained baselines even when channel access is restricted to a small fraction of the swarm size. Furthermore, the framework exhibits inherent resilience to packet erasures, validating semantic scheduling as a critical enabler for resource-constrained 6G systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Multi-Agent Semantic K-Scheduling (MASK) for risk-sensitive collaborative robotics under 6G bandwidth constraints. It introduces Arbiter-Assisted Semantic Information Gating (A-SIG) to select only the top-K agents for transmission based on locally computed semantic importance scores; these are aggregated by a self-supervised global encoder into a compact latent state that feeds a distributional policy for tail-risk mitigation. The central claims are that MASK matches the performance of communication-unconstrained baselines even when channel access is limited to a small fraction of the swarm and that the framework is inherently resilient to packet erasures.
Significance. If the empirical claims are substantiated, the work could contribute to semantic communication and scheduling techniques for resource-constrained multi-agent robotic systems. The combination of local semantic gating with distributional RL for risk sensitivity targets a relevant problem in 6G-enabled robotics. However, the manuscript supplies no experimental details, metrics, baselines, or analysis to support the headline performance claims, so the potential significance cannot be evaluated from the provided text.
major comments (3)
- [Abstract] Abstract: the claim that MASK 'matches the performance of communication-unconstrained baselines even when channel access is restricted to a small fraction of the swarm size' is asserted without any experimental setup, metrics, baselines, tables, or figures in the manuscript, leaving the central empirical result without visible support.
- [Abstract] Abstract: no derivation, loss function, or correlation analysis is supplied to establish that locally computed semantic importance scores reliably identify observations with high marginal value for the global latent state or tail-risk policy; the K-scheduling mechanism therefore rests on an untested assumption that local scores proxy inter-agent coordination value.
- The manuscript contains no evaluation section, ablation studies, or sensitivity analysis on the choice of K relative to swarm size, making it impossible to assess whether the reported resilience to erasures or performance parity holds under the stated constraints.
Simulated Author's Rebuttal
We thank the referee for identifying the absence of empirical support and methodological justification in the current manuscript. We agree that the abstract's performance claims and the A-SIG mechanism require visible experimental validation and analysis, which are missing from the provided text. We will revise the paper by adding a complete evaluation section, derivations, and supporting analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that MASK 'matches the performance of communication-unconstrained baselines even when channel access is restricted to a small fraction of the swarm size' is asserted without any experimental setup, metrics, baselines, tables, or figures in the manuscript, leaving the central empirical result without visible support.
Authors: We agree that the abstract asserts performance parity without any supporting experimental details in the manuscript. The full paper was intended to contain an evaluation section with benchmarks, metrics, baselines, tables, and figures, but these elements are absent from the current version. We will add them in revision to substantiate the claim. revision: yes
-
Referee: [Abstract] Abstract: no derivation, loss function, or correlation analysis is supplied to establish that locally computed semantic importance scores reliably identify observations with high marginal value for the global latent state or tail-risk policy; the K-scheduling mechanism therefore rests on an untested assumption that local scores proxy inter-agent coordination value.
Authors: The referee correctly notes the lack of any derivation, loss function, or analysis linking local semantic scores to global coordination value. The manuscript provides no such justification. We will include a dedicated subsection deriving the scoring mechanism and providing supporting analysis or correlation evidence in the revision. revision: yes
-
Referee: [—] The manuscript contains no evaluation section, ablation studies, or sensitivity analysis on the choice of K relative to swarm size, making it impossible to assess whether the reported resilience to erasures or performance parity holds under the stated constraints.
Authors: We concur that the manuscript lacks any evaluation section, ablations, or sensitivity analysis on K. This omission prevents assessment of the claims regarding erasure resilience and performance under bandwidth limits. We will add a full experimental section including these elements. revision: yes
Circularity Check
No derivation chain or equations present; performance claims rest on absent evaluation details with no self-referential reduction.
full rationale
The provided abstract and context indicate that the manuscript contains no equations, derivations, or first-principles results. The central claims concern empirical performance matching under K-scheduling constraints, but these are asserted via evaluation whose details are absent. Without any load-bearing mathematical steps, fitted parameters renamed as predictions, or self-citation chains that reduce the result to its inputs by construction, no circularity of the enumerated kinds can be identified. The architecture (A-SIG, semantic scores, global encoder) is presented as a proposal whose validity is external to any internal definitional loop.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Arbiter-Assisted Semantic Information Gating (A-SIG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey and critique of multiagent deep reinforcement learning,
P. Hernandez-Leal, B. Kartal, and M. E. Taylor, “A survey and critique of multiagent deep reinforcement learning,”Autonomous Agents and Multi- Agent Systems, vol. 33, no. 6, p. 750–797, Oct. 2019
2019
-
[2]
Cooperative multi-agent deep reinforce- ment learning for computation offloading in digital twin satellite edge networks,
Z. Ji, S. Wu, and C. Jiang, “Cooperative multi-agent deep reinforce- ment learning for computation offloading in digital twin satellite edge networks,”IEEE Journal on Selected Areas in Communications, vol. 41, no. 11, pp. 3414–3429, 2023
2023
-
[3]
Dynamic routing for integrated satellite-terrestrial networks: A constrained multi-agent reinforcement learning approach,
Y . Lyu, H. Hu, R. Fan, Z. Liu, J. An, and S. Mao, “Dynamic routing for integrated satellite-terrestrial networks: A constrained multi-agent reinforcement learning approach,”IEEE Journal on Selected Areas in Communications, vol. 42, no. 5, pp. 1204–1218, 2024
2024
-
[4]
Deep decentralized multi-task multi-agent reinforcement learning under partial observability,
S. Omidshafiei, J. Pazis, C. Amato, J. P. How, and J. Vian, “Deep decentralized multi-task multi-agent reinforcement learning under partial observability,” 2017. [Online]. Available: https://arxiv.org/abs/ 1703.06182
Pith/arXiv arXiv 2017
-
[5]
Learning multiagent communication with backpropagation,
S. Sukhbaatar, A. Szlam, and R. Fergus, “Learning multiagent communication with backpropagation,” 2016. [Online]. Available: https://arxiv.org/abs/1605.07736
Pith/arXiv arXiv 2016
-
[6]
Tarmac: Targeted multi-agent communication,
A. Das, T. Gervet, J. Romoff, D. Batra, D. Parikh, M. Rabbat, and J. Pineau, “Tarmac: Targeted multi-agent communication,” 2020. [Online]. Available: https://arxiv.org/abs/1810.11187
arXiv 2020
-
[7]
Efficient multi-agent communication via self-supervised information aggregation,
C. Guan, F. Chen, L. Yuan, C. Wang, H. Yin, Z. Zhang, and Y . Yu, “Efficient multi-agent communication via self-supervised information aggregation,” inProceedings of the 36th International Conference on Neural Information Processing Systems, ser. NIPS ’22. Red Hook, NY , USA: Curran Associates Inc., 2022
2022
-
[8]
A distributional per- spective on reinforcement learning,
M. G. Bellemare, W. Dabney, and R. Munos, “A distributional per- spective on reinforcement learning,” inProceedings of the 34th Inter- national Conference on Machine Learning - Volume 70, ser. ICML’17. JMLR.org, 2017, p. 449–458
2017
-
[9]
Distribu- tional reinforcement learning with quantile regression,
W. Dabney, M. Rowland, M. G. Bellemare, and R. Munos, “Distribu- tional reinforcement learning with quantile regression,” inProceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, ser...
2018
-
[10]
Riskq: risk-sensitive multi-agent reinforcement learning value factor- ization,
S. Shen, C. Ma, C. Li, W. Liu, Y . Fu, S. Mei, X. Liu, and C. Wang, “Riskq: risk-sensitive multi-agent reinforcement learning value factor- ization,” inProceedings of the 37th International Conference on Neural Information Processing Systems, ser. NIPS ’23. Red Hook, NY , USA: Curran Associates Inc., 2023
2023
-
[11]
Conditional value-at-risk for general loss distributions,
R. Rockafellar and S. Uryasev, “Conditional value-at-risk for general loss distributions,”Journal of Banking & Finance, vol. 26, no. 7, pp. 1443–1471, 2002
2002
-
[12]
Beyond transmitting bits: Context, semantics, and task-oriented communications,
D. G ¨und¨uz, Z. Qin, I. E. Aguerri, H. S. Dhillon, Z. Yang, A. Yener, K. K. Wong, and C.-B. Chae, “Beyond transmitting bits: Context, semantics, and task-oriented communications,”IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 5–41, 2023
2023
-
[13]
Semantic communications in networked systems: A data significance perspective,
E. Uysal, O. Kaya, A. Ephremides, J. Gross, M. Codreanu, P. Popovski, M. Assaad, G. Liva, A. Munari, B. Soret, T. Soleymani, and K. H. Johansson, “Semantic communications in networked systems: A data significance perspective,”IEEE Network, vol. 36, no. 4, pp. 233–240, 2022
2022
-
[14]
Learning to communicate with deep multi-agent reinforcement learning,
J. N. Foerster, Y . M. Assael, N. de Freitas, and S. Whiteson, “Learning to communicate with deep multi-agent reinforcement learning,” in Proceedings of the 30th International Conference on Neural Information Processing Systems, ser. NIPS’16. Red Hook, NY , USA: Curran Associates Inc., 2016, p. 2145–2153
2016
-
[15]
Learning attentional communication for multi-agent cooperation,
J. Jiang and Z. Lu, “Learning attentional communication for multi-agent cooperation,” inProceedings of the 32nd International Conference on Neural Information Processing Systems, ser. NIPS’18. Red Hook, NY , USA: Curran Associates Inc., 2018, p. 7265–7275
2018
-
[16]
M. Wojtala, B. Stefa ´nczyk, D. Bogucki, Łukasz Lepak, J. Strykowski, and P. Wawrzy ´nski, “Mactas: Self-attention-based module for inter- agent communication in multi-agent reinforcement learning,” 2025. [Online]. Available: https://arxiv.org/abs/2508.13661
arXiv 2025
-
[17]
Learning when to communicate at scale in multiagent cooperative and competitive tasks,
A. Singh, T. Jain, and S. Sukhbaatar, “Learning when to communicate at scale in multiagent cooperative and competitive tasks,” 2018. [Online]. Available: https://arxiv.org/abs/1812.09755
Pith/arXiv arXiv 2018
-
[18]
Learning nearly decomposable value functions via communication minimization,
T. Wang, J. Wang, C. Zheng, and C. Zhang, “Learning nearly decomposable value functions via communication minimization,” 2020. [Online]. Available: https://arxiv.org/abs/1910.05366
arXiv 2020
-
[19]
Effective communi- cations: A joint learning and communication framework for multi-agent reinforcement learning over noisy channels,
T.-Y . Tung, S. Kobus, J. P. Roig, and D. G ¨und¨uz, “Effective communi- cations: A joint learning and communication framework for multi-agent reinforcement learning over noisy channels,”IEEE Journal on Selected Areas in Communications, vol. 39, no. 8, pp. 2590–2603, 2021
2021
-
[20]
Goal-oriented semantic communication in bandwidth-constrained marl,
Y . Su, Y . Du, and Y . Deng, “Goal-oriented semantic communication in bandwidth-constrained marl,” in2025 IEEE International Conference on Communications Workshops (ICC Workshops), 2025, pp. 1274–1279
2025
-
[21]
Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning,
T. Rashid, M. Samvelyan, C. S. de Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning,” 2018. [Online]. Available: https://arxiv.org/abs/1803.11485
Pith/arXiv arXiv 2018
-
[22]
Distortion risk measures. coherence and stochastic dominance,
J. Wirch and M. Hardy, “Distortion risk measures. coherence and stochastic dominance,”Insurance Mathematics and Economics, vol. 32, pp. 168–168, 02 2003
2003
-
[23]
Estimating or propagating gradients through stochastic neurons for conditional computation,
Y . Bengio, N. L ´eonard, and A. Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,”
-
[24]
Available: https://arxiv.org/abs/1308.3432
[Online]. Available: https://arxiv.org/abs/1308.3432
-
[25]
Implicit quantile networks for distributional reinforcement learning,
W. Dabney, G. Ostrovski, D. Silver, and R. Munos, “Implicit quantile networks for distributional reinforcement learning,” inProceedings of the 35th International Conference on Machine Learning, ser. Proceed- ings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. PMLR, 10–15 Jul 2018, pp. 1096–1105
2018
-
[26]
Risk-averse offline reinforcement learning,
N. A. Urp ´ı, S. Curi, and A. Krause, “Risk-averse offline reinforcement learning,” 2021. [Online]. Available: https://arxiv.org/abs/2102.05371
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.