MetaForge: A Self-Evolving Multimodal Agent that Retrieves, Adapts, and Forges Tools On Demand
Pith reviewed 2026-06-28 12:09 UTC · model grok-4.3
The pith
MetaForge lets multimodal agents decide when to forge new tools and recycle them via a closed RL-optimized loop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
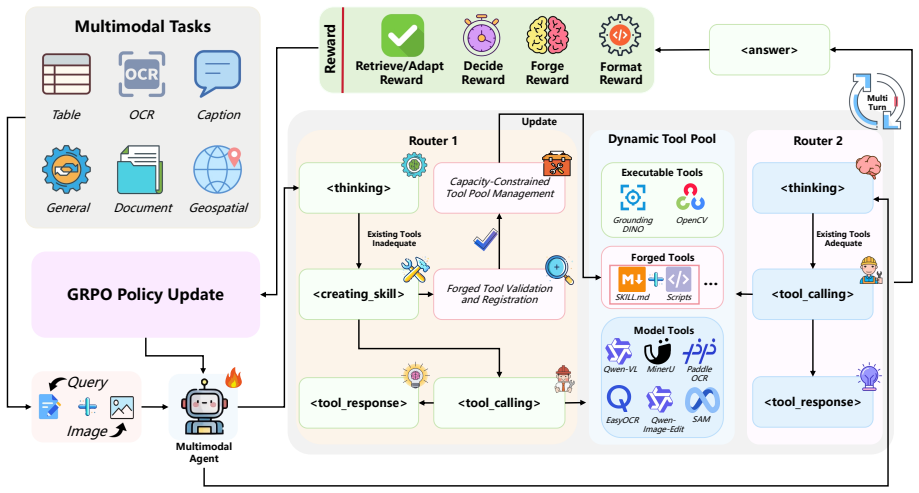
MetaForge factorizes agentic behavior into four coupled stages—Decide, Retrieve, Adapt, and Forge—forming a closed judge-retrieve-adapt-forge-recycle loop. A unified orchestration policy enables the agent to choose among answering directly, reusing existing tools, or forging new ones. Joint reinforcement learning optimizes invocation necessity, retrieval accuracy, execution effectiveness, and forged-skill reusability with an explicit invocation-cost penalty, allowing on-demand self-evolution of the tool library.
What carries the argument
The closed judge-retrieve-adapt-forge-recycle loop with unified orchestration policy and joint RL optimization plus cost penalty.
If this is right
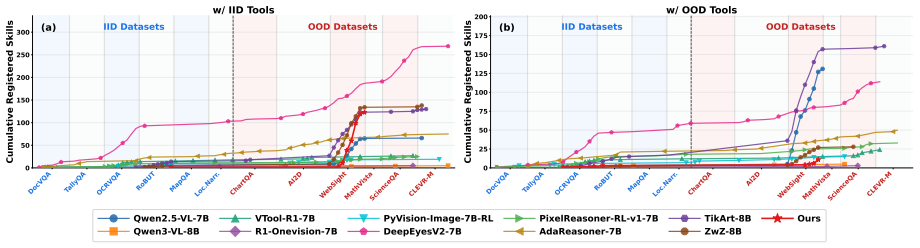
- Agents generalize to unseen scenarios by forging and recycling new skills instead of relying on fixed inventories.
- The decide stage plus cost penalty reduces redundant invocations and associated noise-induced errors.
- Forged skills are added to the library and become available for future reuse, improving long-term efficiency.
- End-to-end RL training aligns all four stages so that the agent selects the lowest-cost effective action at each step.
Where Pith is reading between the lines
- The same decide-forge-recycle pattern could be applied to non-multimodal agents or to environments where tool needs shift over long horizons.
- Dynamic tool creation might reduce the engineering burden of maintaining large hand-curated tool libraries in deployed systems.
- If the RL loop remains stable, the framework could support continual learning agents that accumulate capabilities without explicit retraining.
- Error accumulation in the forge step would be detectable by tracking whether newly forged tools are reused or discarded in subsequent episodes.
Load-bearing premise
The joint RL optimization of invocation necessity, retrieval accuracy, execution effectiveness, and forged-skill reusability with an explicit cost penalty will produce stable, generalizable behavior without the forged tools being overly task-specific or the loop introducing compounding errors.
What would settle it
Running MetaForge on a fresh benchmark suite where it fails to exceed static-tool baselines in accuracy or where forged tools increase error rates would falsify the effectiveness of the self-evolution loop.
Figures



read the original abstract
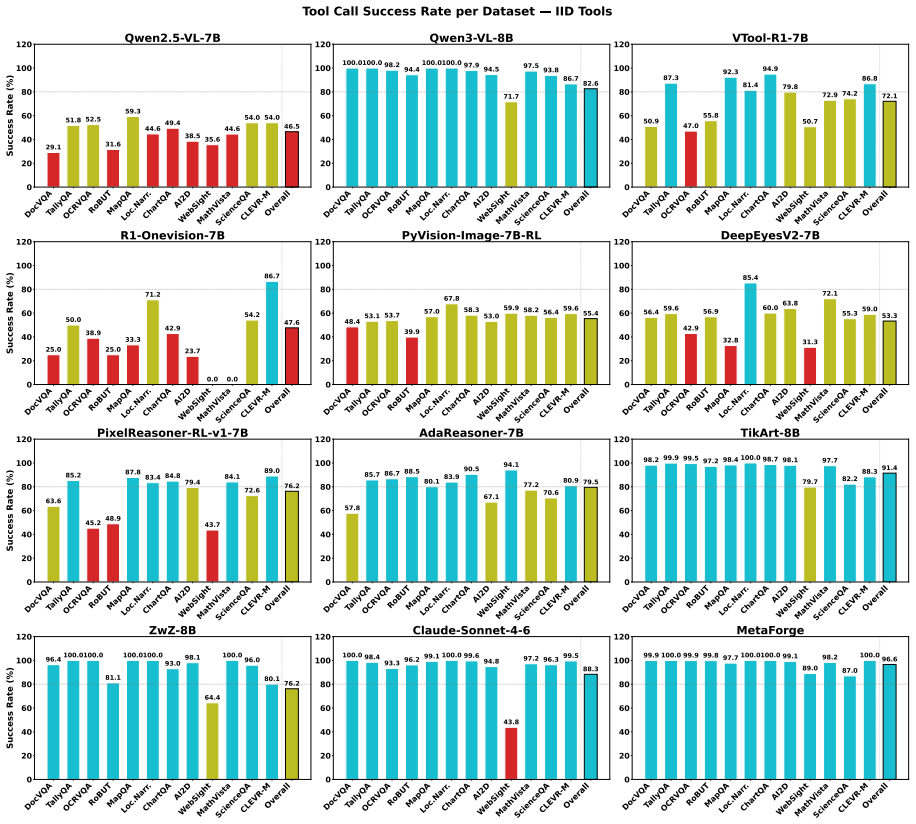
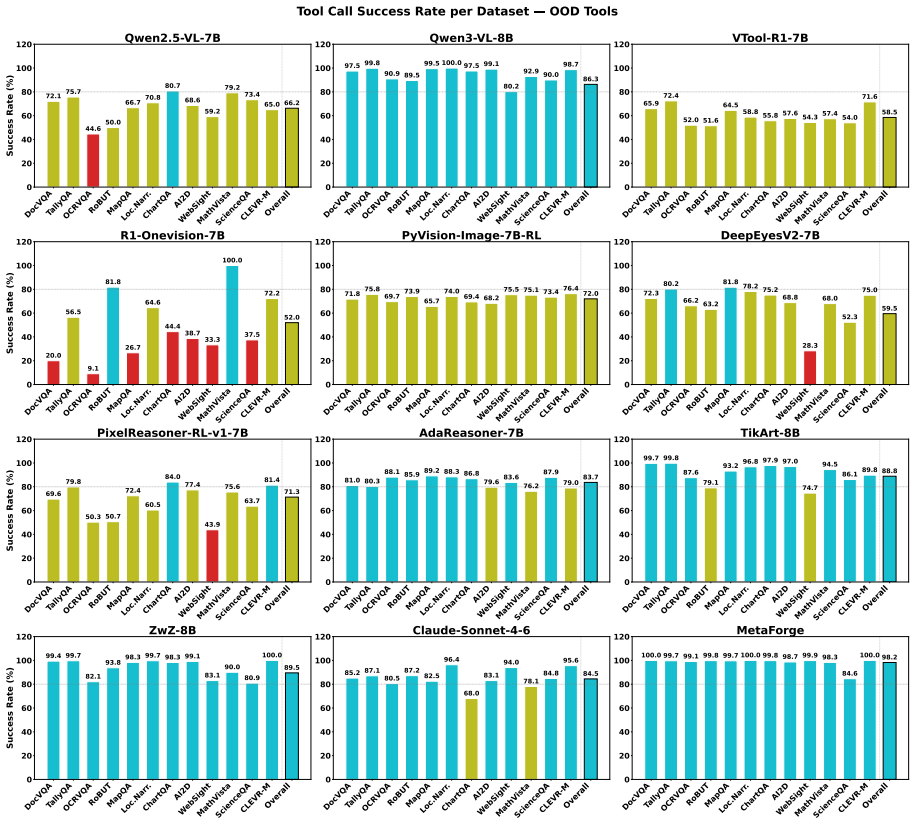
Multimodal agents have achieved notable progress on complex reasoning tasks through tool use, yet remain limited by two issues: statically predefined tool inventories fail to generalize to unseen scenarios, and indiscriminate tool invocation incurs redundant cost and noise-induced errors. We propose MetaForge, a multimodal agent framework that learns when to invoke tools and how to evolve its toolset on demand. MetaForge factorizes agentic behavior into four coupled stages: Decide (judging whether tool use is warranted), Retrieve (selecting suitable tools), Adapt (grounding tool parameters in task context), and Forge (synthesizing new skills online and recycling them into the tool library for reuse), forming a closed judge-retrieve-adapt-forge-recycle loop. A unified orchestration policy enables the agent to choose among answering directly, reusing existing tools, or forging new ones. We jointly optimize invocation necessity, retrieval accuracy, execution effectiveness, and forged-skill reusability via reinforcement learning, with an explicit invocation-cost penalty discouraging redundant calls. Across 12 benchmarks, MetaForge consistently surpasses 16 baselines in accuracy, efficiency, and generalization, validating a paradigm shift from static tool inventories to on-demand self-evolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MetaForge, a multimodal agent that factorizes behavior into a closed judge-retrieve-adapt-forge-recycle loop, uses a unified orchestration policy to decide among direct answering, tool reuse, or forging new skills, and jointly optimizes the four factors plus an explicit cost penalty via reinforcement learning. It reports consistent outperformance over 16 baselines on 12 benchmarks in accuracy, efficiency, and generalization.
Significance. If the empirical results are robust and the RL loop produces reusable rather than brittle tools, the work would meaningfully advance multimodal agents by replacing static tool inventories with on-demand self-evolution. The explicit cost penalty and four-stage factorization are conceptually clean contributions.
major comments (2)
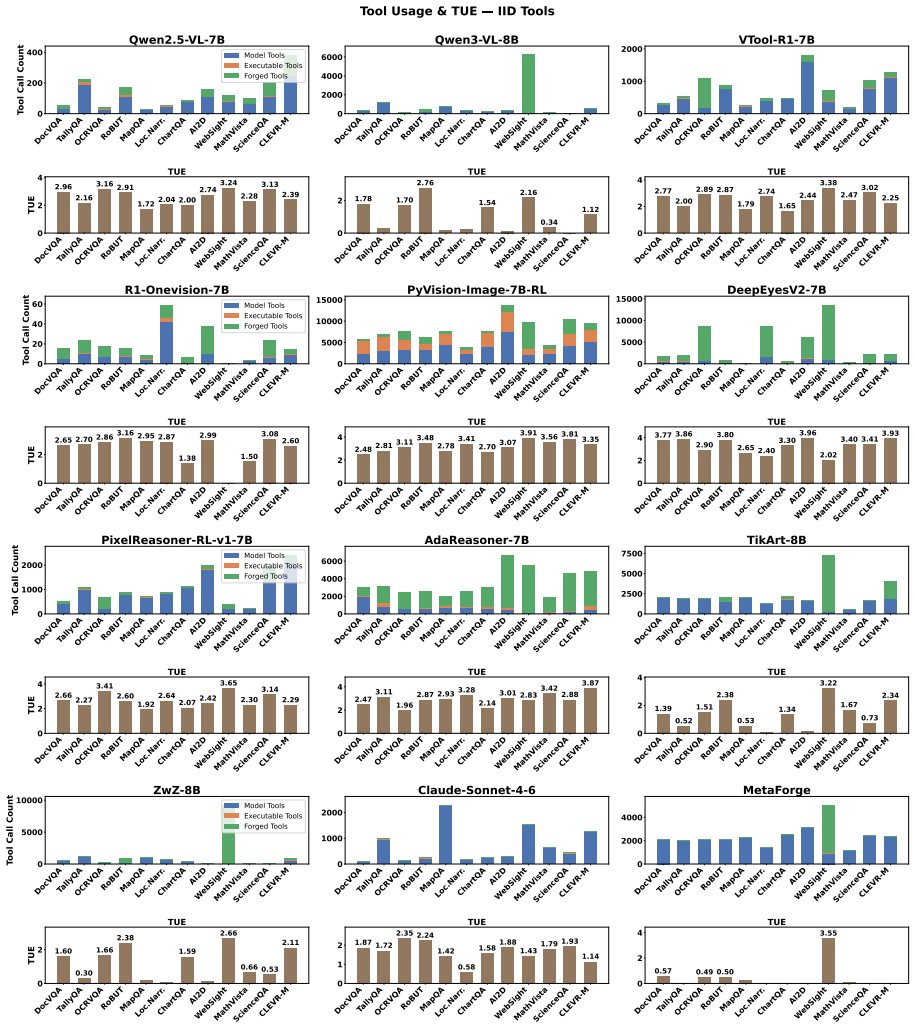
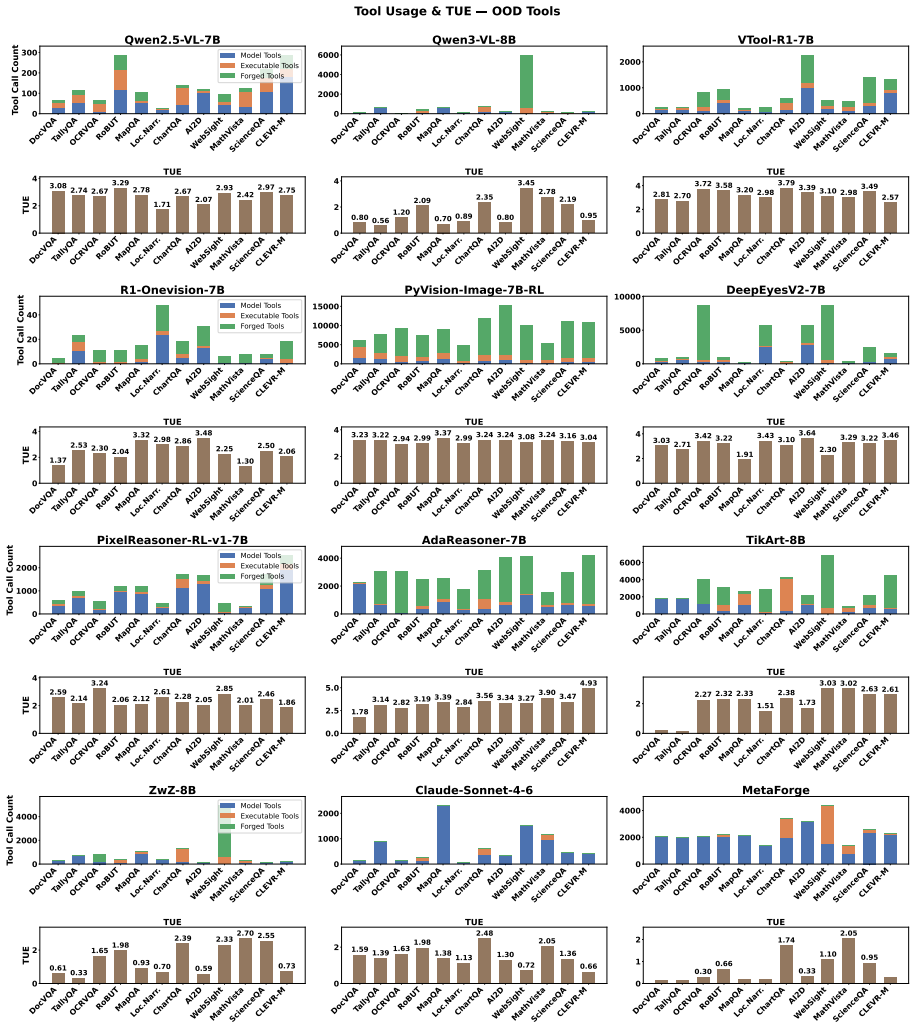
- [Experiments] The central empirical claim (surpassing 16 baselines on 12 benchmarks) rests on the joint RL objective producing stable, generalizable behavior. No convergence analysis, ablation on the cost-penalty term, or quantitative measurement of forged-tool reuse rates versus novelty appears in the experimental section, leaving the risk of compounding errors or task-specific overfitting unaddressed.
- [Method] The abstract states that the unified policy optimizes invocation necessity, retrieval accuracy, execution effectiveness, and forged-skill reusability, yet the manuscript supplies no equations or pseudocode showing how these four terms are combined into a single reward or how the closed loop is prevented from error accumulation across iterations.
minor comments (2)
- [Tables and Figures] Figure captions and table headers should explicitly list the 12 benchmarks and 16 baselines so readers can assess coverage without cross-referencing the text.
- [Evaluation Protocol] Clarify whether the forged tools are evaluated for reusability on held-out tasks or only on the training distribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the empirical and methodological sections.
read point-by-point responses
-
Referee: [Experiments] The central empirical claim (surpassing 16 baselines on 12 benchmarks) rests on the joint RL objective producing stable, generalizable behavior. No convergence analysis, ablation on the cost-penalty term, or quantitative measurement of forged-tool reuse rates versus novelty appears in the experimental section, leaving the risk of compounding errors or task-specific overfitting unaddressed.
Authors: We agree that these analyses are absent and would strengthen the claims. The revised manuscript will include RL convergence curves, an ablation removing the cost-penalty term, and quantitative reuse-versus-novelty statistics for forged tools across all 12 benchmarks to address concerns about stability and overfitting. revision: yes
-
Referee: [Method] The abstract states that the unified policy optimizes invocation necessity, retrieval accuracy, execution effectiveness, and forged-skill reusability, yet the manuscript supplies no equations or pseudocode showing how these four terms are combined into a single reward or how the closed loop is prevented from error accumulation across iterations.
Authors: The referee correctly notes the absence of explicit equations and pseudocode. We will add a subsection to the Method section containing the reward function that linearly combines the four terms with the cost penalty, plus pseudocode for the full judge-retrieve-adapt-forge-recycle loop and safeguards such as forged-tool validation to limit error accumulation. revision: yes
Circularity Check
No circularity: empirical framework evaluated on external benchmarks
full rationale
The paper presents a methodological framework (four-stage loop with unified RL policy and cost penalty) whose performance claims rest on direct comparisons against 16 external baselines across 12 benchmarks. No equations, self-definitional reductions, fitted-input predictions, or load-bearing self-citations are visible in the provided text that would make any result equivalent to its inputs by construction. The RL optimization and empirical superiority are standard experimental claims, not derivations that collapse into the design itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tallyqa: Answering complex counting ques- tions. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 8076–8084. Anthropic. 2026. Introducing claude sonnet 4.6. https://www.anthropic.com/news/ claude-sonnet-4-6. Accessed: 2026-02-17. Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
A diagram is worth a dozen images. InEuro- pean conference on computer vision, pages 235–251. Springer. Aniruddha Kembhavi, Minjoon Seo, Dustin Schwenk, Jonghyun Choi, Ali Farhadi, and Hannaneh Ha- jishirzi. 2017. Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension. InProceedings of the IEEE Confer- ence o...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
Springer. Cheng Qian, Chi Han, Yi Fung, Yujia Qin, Zhiyuan Liu, and Heng Ji. 2023. Creator: Tool creation for disentangling abstract and concrete reasoning of large language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 6922–6939. Jiahao Qiu, Xuan Qi, Tongcheng Zhang, Xinzhe Juan, Ji- acheng Guo, Yifu Lu, Yimin Wan...
-
[4]
Identify the accuracy of the most accurate algorithm (highest bar)
-
[5]
Identify the accuracy of the least accurate algorithm (lowest bar)
-
[6]
wheat" with an accuracy of approximately 90. - The lowest bar corresponds to
Calculate the difference between these two values. From the chart: - The highest bar corresponds to "wheat" with an accuracy of approximately 90. - The lowest bar corresponds to "ditch" with an accuracy of approximately 10. The difference is 90 - 10 = 80. I will use the UniChart tool to confirm the exact values from the chart. </thinking> <tool_call>{"nam...
-
[7]
name": "run_skill
Run ‘describe_scene.py‘ with image_index to generate a concise scene description. ### Call Contract - run_skill.args.image_index is required for image input. ### When to call - Use this skill to summarize visual scenes, events, or settings in an image without extracting text, ,→classifying genre, or parsing structured data. ## Image Input Contract - This ...
-
[8]
Run ‘detect_brown_metallic.py‘ to extract object count from image
-
[9]
name": "run_skill
Run ‘update_count.py‘ to increment and store the total count. ### Call Contract - run_skill.args.image_index is required only for image-reading scripts. ### When to call - Use this skill when tracking brown metallic objects specifically -- not gray, not non-metallic, not ,→large objects -- and need persistent count management across multiple images. ## Im...
-
[10]
Run ‘detect_objects.py‘ to count objects in a new image
-
[11]
Run ‘update_count.py‘ to merge new count with historical state
-
[12]
name": "run_skill
Run ‘report_status.py‘ to generate a human-readable summary. ### Call Contract - ‘run_skill.args.image_index‘ is required only for ‘detect_objects.py‘. 34 - All scripts must print key results to stdout for downstream consumption. ### When to call - Use this skill when monitoring environmental changes involving small gray metallic objects across ,→sequenti...
-
[13]
Run ‘describe_layout.py‘ to extract visual elements and their arrangement
-
[14]
name": "run_skill
Run ‘summarize_description.py‘ to generate final natural language summary. ### Call Contract - run_skill.args.image_index is required only for image-reading scripts. ### When to call - Use this skill when you need a quick, non-interpretive visual summary of an image’s composition -- ,→distinct from genre, text, or table extraction skills by focusing purel...
2022
-
[15]
Run ‘analyze-layout.py‘ to extract visual region boundaries and semantic roles (header/main/footer)
-
[16]
name": "run_skill
Run ‘build-semantic-html.py‘ to generate final semantic HTML using the layout mapping. ### Call Contract - ‘image_index‘ is required for ‘analyze-layout.py‘ to select the correct screenshot. - Scripts must print key results (e.g., region coordinates, HTML string) to stdout for downstream ,→consumption. ### When to call - Use this skill when you need to ma...
2022
-
[17]
screenshot-semantic-html-stream
Run ‘generate_html_from_screenshot.py‘ with image_index to produce full semantic HTML directly to ,→stdout. ### Call Contract - run_skill.args.image_index is required as this script reads image input. - Output is printed directly to stdout; no intermediate files are created. ### When to call - Use this skill when you need immediate, complete semantic HTML...
2023
-
[18]
Do NOT include script content or source fields
Do NOT generate any code in this stage. Do NOT include script content or source fields
-
[19]
The skill name must not match or be confusingly ,→similar to any existing skill
Compare against existing skills before proposing. The skill name must not match or be confusingly ,→similar to any existing skill. Do NOT propose a skill whose purpose substantially overlaps ,→with an existing one
-
[20]
Design params to be explicit and CLI-friendly
Scripts are executed via CLI as --key value pairs. Design params to be explicit and CLI-friendly
-
[21]
Use Python standard library first
-
[22]
On fatal errors, print to stderr and exit ,→non-zero
On success, scripts should print key results to stdout. On fatal errors, print to stderr and exit ,→non-zero
-
[23]
Stage 2: Script Generation Prompt [System] You are a skill designer
Every script path must end with .py or .sh. Stage 2: Script Generation Prompt [System] You are a skill designer. Generate exactly one script for the specified target path. [User] Skill name: {skill_name} Skill description: {skill_description} Target script path: {target_path} All script specs (from Stage 1): {full_specs_json} Current target script spec: {...
-
[24]
Use argparse to parse CLI arguments
Scripts are launched as external commands. Use argparse to parse CLI arguments
-
[25]
image_index is consumed by the runtime for image selection and is NOT forwarded to the script
-
[26]
If the script needs image input, read from SKILL_IMAGE_PATH (local file path) or ,→SKILL_IMAGE_DATA_URL (base64 data URL) environment variables
-
[27]
Output contract:
Put executable code under ‘if __name__ == ’__main__’:‘ and ensure ‘python <script> --help‘ succeeds ,→. Output contract:
-
[28]
Output must reflect the actual input content -- do NOT produce ,→generic or static placeholder text
On success, print results to stdout. Output must reflect the actual input content -- do NOT produce ,→generic or static placeholder text
-
[29]
path": "<target_path>
On fatal errors, print to stderr and exit non-zero. Do not print error text to stdout. Return JSON: {"path": "<target_path>", "content": "<script_content>"} 49 D The Use of Large Language Models In this paper, we utilized LLMs for language polish- ing to enhance clarity, and we manually reviewed all modifications. 50
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.