ManiSplat: Manipulation Trajectory Synthesis from Monocular Video via Decoupled 3D Gaussian Splatting
Pith reviewed 2026-06-27 13:54 UTC · model grok-4.3
The pith
ManiSplat reconstructs controllable 3D Gaussian scenes of robot manipulations from monocular videos by separating robot, objects, and background into independent subfields.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
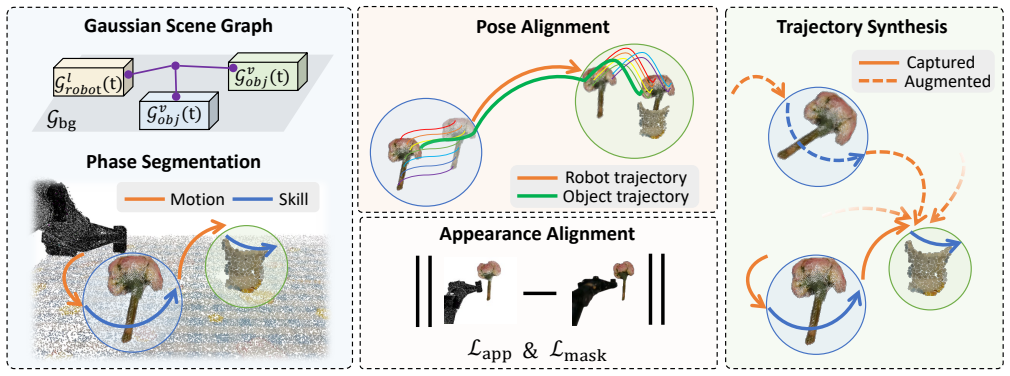
ManiSplat reconstructs controllable and decoupled Gaussian digital twins directly from monocular ego-view robotic videos. It uses a Graph-Structured Disentangled Representation that separates the robot, objects, and background into independently optimizable Gaussian subfields organized within a scene graph. A Task-Oriented Spatio-Temporal Alignment module exploits the alternation between Motion and Skill phases to build pseudo-ground-truth trajectories, and a joint photometric-geometric optimization produces scenes that are temporally coherent, physically consistent, and simulation-ready.
What carries the argument
Graph-Structured Disentangled Representation, which organizes the robot, manipulable objects, and background into a scene graph of independent Gaussian subfields that can be optimized separately while preserving relational structure.
If this is right
- Reconstructed scenes become directly usable in simulators for robotic policy learning and downstream manipulation tasks.
- The decoupled subfields allow independent control over robot motion, object movement, and background elements.
- Temporal coherence and physical consistency are achieved through the phase-based alignment and joint optimization.
- The approach operates from monocular ego-view videos without requiring additional supervision or multi-view capture.
Where Pith is reading between the lines
- The phase-based alignment logic might generalize to other video domains involving repeated action cycles, such as human-object interactions.
- If the scene graph structure scales, it could support reconstruction of multi-robot or multi-object scenes from single views.
- The simulation-ready output suggests a route to train control policies entirely from video-derived digital twins rather than real hardware trials.
- Extending the method to longer sequences would test whether the disentangled fields remain stable across multiple manipulation cycles.
Load-bearing premise
The method assumes that manipulation tasks naturally alternate between distinct Motion and Skill phases that can be used to generate accurate pseudo-ground-truth trajectories from monocular video without extra sensors.
What would settle it
If external motion-capture data shows that the synthesized trajectories deviate substantially from actual robot paths or if rendered contact regions fail to match the input video frames, the reconstruction claim would not hold.
Figures



read the original abstract
Reconstructing dynamic and interactive 3D scenes from real-world observations remains a fundamental challenge in computer vision and robotics. While recent advances in 3D Gaussian Splatting have enabled high-fidelity static reconstruction, extending it to interactive environments with articulated robots and manipulable objects remains difficult due to complex contact interactions and abrupt pose changes. To address these challenges, we introduce ManiSplat, a unified framework that reconstructs controllable and decoupled Gaussian digital twins directly from monocular ego-view robotic videos. Our method introduces a Graph-Structured Disentangled Representation that separates the robot, objects, and background into independently optimizable Gaussian subfields organized within a scene graph. To ensure stability, we propose a Task-Oriented Spatio-Temporal Alignment module that leverages the inherent logic of manipulation tasks-alternating between Motion and Skill phases-to construct accurate pseudo-ground-truth trajectories. Finally, a joint photometric-geometric optimization ensures the reconstructed scenes are temporally coherent, physically consistent, and simulation-ready. Extensive experiments demonstrate that our approach reconstructs interaction-driven dynamic scenes with high fidelity and controllability, effectively supporting downstream robotic tasks and policy learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ManiSplat, a framework for reconstructing controllable, decoupled 3D Gaussian digital twins of robots, objects, and backgrounds directly from monocular ego-view robotic manipulation videos. It proposes a Graph-Structured Disentangled Representation organized in a scene graph, a Task-Oriented Spatio-Temporal Alignment module that exploits alternation between Motion and Skill phases to synthesize pseudo-ground-truth trajectories, and a joint photometric-geometric optimization to enforce temporal coherence and physical consistency. The central claim is that the resulting reconstructions are high-fidelity, simulation-ready, and support downstream robotic tasks and policy learning.
Significance. If the central claims hold, the work would provide a practical route to building controllable dynamic scene models from single-view video without external sensors or multi-camera rigs, which is valuable for robotics simulation and imitation learning pipelines. The phase-based pseudo-GT construction and decoupled Gaussian subfields represent a targeted adaptation of 3DGS to contact-rich manipulation, potentially reducing data requirements compared to existing dynamic reconstruction methods.
major comments (2)
- [Task-Oriented Spatio-Temporal Alignment module] Task-Oriented Spatio-Temporal Alignment module: The pseudo-ground-truth trajectories are derived solely from detected alternation between Motion and Skill phases in monocular video, without reported external validation (e.g., trajectory RMSE against motion-capture ground truth) or ablation on phase-detection error. This step is load-bearing for the Graph-Structured Disentangled Representation and the physical-consistency claims of the joint optimization; inaccurate trajectories would propagate directly into the decoupled Gaussians.
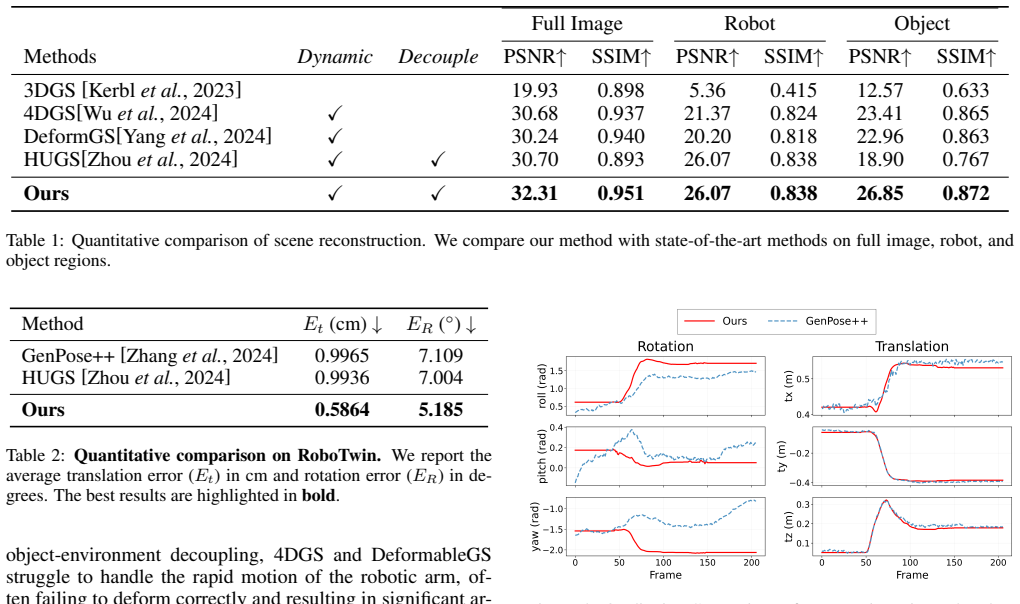
- [Abstract / Experiments section] Abstract and experimental claims: The manuscript asserts that 'extensive experiments demonstrate' high fidelity and controllability supporting policy learning, yet the provided text supplies no quantitative metrics, baseline comparisons, or ablation tables. Without these, it is impossible to assess whether the proposed modules actually deliver the claimed improvements over prior 3DGS dynamic extensions.
minor comments (2)
- [Abstract] The abstract is unusually dense and would benefit from a clearer separation of the three technical contributions.
- [Method] Notation for the scene-graph nodes and the decoupled Gaussian subfields should be introduced with explicit variable definitions early in the method section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on ManiSplat. We address the two major comments point by point below, focusing on the validation of the alignment module and the presentation of experimental results.
read point-by-point responses
-
Referee: [Task-Oriented Spatio-Temporal Alignment module] Task-Oriented Spatio-Temporal Alignment module: The pseudo-ground-truth trajectories are derived solely from detected alternation between Motion and Skill phases in monocular video, without reported external validation (e.g., trajectory RMSE against motion-capture ground truth) or ablation on phase-detection error. This step is load-bearing for the Graph-Structured Disentangled Representation and the physical-consistency claims of the joint optimization; inaccurate trajectories would propagate directly into the decoupled Gaussians.
Authors: We acknowledge that the pseudo-ground-truth trajectories rely on phase alternation detected from monocular video without external motion-capture validation. This design choice stems from the target setting of single-view robotic videos where mocap is unavailable. The phase logic follows the inherent structure of manipulation tasks. In revision we will add an ablation on phase-detection robustness and report qualitative trajectory consistency checks to address propagation concerns. revision: yes
-
Referee: [Abstract / Experiments section] Abstract and experimental claims: The manuscript asserts that 'extensive experiments demonstrate' high fidelity and controllability supporting policy learning, yet the provided text supplies no quantitative metrics, baseline comparisons, or ablation tables. Without these, it is impossible to assess whether the proposed modules actually deliver the claimed improvements over prior 3DGS dynamic extensions.
Authors: We agree that the submitted manuscript version does not contain the quantitative metrics, baseline comparisons, or ablation tables referenced in the abstract. This is a presentation gap. We will expand the Experiments section with the required tables, metrics (e.g., reconstruction fidelity and policy success rates), and comparisons in the revised manuscript. revision: yes
Circularity Check
No circularity in derivation chain; pseudo-GT construction described at high level without equations
full rationale
The abstract and available text describe a Task-Oriented Spatio-Temporal Alignment module that constructs pseudo-ground-truth trajectories by detecting Motion/Skill phase alternation in monocular video. No equations, fitting procedures, or self-citations are provided that would allow a reduction of any prediction to its inputs by construction. The central claims (decoupled Gaussians, joint optimization) are presented as independent of the phase logic, with no evidence that the trajectories depend on the same fitted parameters they supervise. This is the most common honest finding when no mathematical chain is visible.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[Barcellonaet al., 2024 ] Leonardo Barcellona, Andrii Zada- ianchuk, Davide Allegro, Samuele Papa, Stefano Ghidoni, and Efstratios Gavves. Dream to manipulate: Composi- tional world models empowering robot imitation learning with imagination.arXiv preprint arXiv:2412.14957,
-
[2]
Closing the sim-to-real loop: Adapting simulation randomization with real world expe- rience
[Chebotaret al., 2019 ] Yevgen Chebotar, Ankur Handa, Viktor Makoviychuk, Miles Macklin, Jan Issac, Nathan Ratliff, and Dieter Fox. Closing the sim-to-real loop: Adapting simulation randomization with real world expe- rience. In2019 International Conference on Robotics and Automation (ICRA), pages 8973–8979,
2019
-
[3]
[Chenet al., 2025 ] Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xi- anliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong do- main randomization for robust bimanual robotic manipu- lation.arXiv preprint arXiv:2506.18088,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
[Hanet al., 2025 ] Xiaoshen Han, Minghuan Liu, Yilun Chen, Junqiu Yu, Xiaoyang Lyu, Yang Tian, Bolun Wang, Weinan Zhang, and Jiangmiao Pang. Re3sim: Gener- ating high-fidelity simulation data via 3d-photorealistic real-to-sim for robotic manipulation.arXiv preprint arXiv:2502.08645,
-
[5]
Igfuse: Interactive 3d gaussian scene reconstruction via multi-scans fusion
[Huet al., 2026 ] Wenhao Hu, Zesheng Li, Haonan Zhou, Liu Liu, Xuexiang Wen, Zhizhong Su, Xi Li, and Gaoang Wang. Igfuse: Interactive 3d gaussian scene reconstruction via multi-scans fusion. InProceedings of the AAAI Con- ference on Artificial Intelligence, volume 40, pages 4932– 4940,
2026
-
[6]
Cotracker3: Simpler and better point track- ing by pseudo-labelling real videos
[Karaevet al., 2025 ] Nikita Karaev, Yuri Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker3: Simpler and better point track- ing by pseudo-labelling real videos. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6013–6022,
2025
-
[7]
3d gaus- sian splatting for real-time radiance field rendering.ACM Trans
[Kerblet al., 2023 ] Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaus- sian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
2023
-
[8]
Fully explicit dy- namic gaussian splatting.Advances in Neural Information Processing Systems, 37:5384–5409,
[Leeet al., 2024 ] Junoh Lee, ChangYeon Won, Hyunjun Jung, Inhwan Bae, and Hae-Gon Jeon. Fully explicit dy- namic gaussian splatting.Advances in Neural Information Processing Systems, 37:5384–5409,
2024
-
[9]
arXiv preprint arXiv:2411.11839 (2024) 1
[Liet al., 2024a ] Xinhai Li, Jialin Li, Ziheng Zhang, Rui Zhang, Fan Jia, Tiancai Wang, Haoqiang Fan, Kuo-Kun Tseng, and Ruiping Wang. Robogsim: A real2sim2real robotic gaussian splatting simulator.arXiv preprint arXiv:2411.11839,
-
[10]
[Liet al., 2025 ] Jiahui Li, Shengeng Tang, Jingxuan He, Gang Huang, Zhangye Wang, Yantao Pan, and Lechao Cheng. Splitgaussian: Reconstructing dynamic scenes via visual geometry decomposition.arXiv preprint arXiv:2508.04224,
-
[11]
Robo-gs: A physics consistent spatial-temporal model for robotic arm with hy- brid representation
[Louet al., 2025 ] Haozhe Lou, Yurong Liu, Yike Pan, Yi- ran Geng, Jianteng Chen, Wenlong Ma, Chenglong Li, Lin Wang, Hengzhen Feng, Lu Shi, et al. Robo-gs: A physics consistent spatial-temporal model for robotic arm with hy- brid representation. In2025 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 15379– 15386. IEEE,
2025
-
[12]
B ´eziergs: Dynamic urban scene reconstruction with b´ezier curve gaussian splatting
[Maet al., 2025 ] Zipei Ma, Junzhe Jiang, Yurui Chen, and Li Zhang. B ´eziergs: Dynamic urban scene reconstruction with b´ezier curve gaussian splatting. InICCV,
2025
-
[13]
Splatsim: Zero-shot sim2real transfer of rgb manipulation policies using gaussian splatting
[Qureshiet al., 2025 ] M Nomaan Qureshi, Sparsh Garg, Francisco Yandun, David Held, George Kantor, and Ab- hisesh Silwal. Splatsim: Zero-shot sim2real transfer of rgb manipulation policies using gaussian splatting. In2025 IEEE International Conference on Robotics and Automa- tion (ICRA), pages 6502–6509. IEEE,
2025
-
[14]
SAM 2: Segment Anything in Images and Videos
[Raviet al., 2024 ] Nikhila Ravi, Valentin Gabeur, Yuan- Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R ¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Freetimegs: Free gaussian prim- itives at anytime anywhere for dynamic scene reconstruc- tion
[Wanget al., 2025 ] Yifan Wang, Peishan Yang, Zhen Xu, Ji- aming Sun, Zhanhua Zhang, Yong Chen, Hujun Bao, Sida Peng, and Xiaowei Zhou. Freetimegs: Free gaussian prim- itives at anytime anywhere for dynamic scene reconstruc- tion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21750–21760,
2025
-
[16]
4d gaussian splatting for real-time dynamic scene rendering
[Wuet al., 2024 ] Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4d gaussian splatting for real-time dynamic scene rendering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20310–20320,
2024
-
[17]
Rl-gsbridge: 3d gaussian splatting based real2sim2real method for robotic manipulation learning
[Wuet al., 2025 ] Yuxuan Wu, Lei Pan, Wenhua Wu, Guang- ming Wang, Yanzi Miao, Fan Xu, and Hesheng Wang. Rl-gsbridge: 3d gaussian splatting based real2sim2real method for robotic manipulation learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 192–198. IEEE,
2025
-
[18]
[Xueet al., 2025 ] Zhengrong Xue, Shuying Deng, Zhenyang Chen, Yixuan Wang, Zhecheng Yuan, and Huazhe Xu. Demogen: Synthetic demonstration genera- tion for data-efficient visuomotor policy learning.arXiv preprint arXiv:2502.16932,
-
[19]
Deformable 3d gaussians for high-fidelity monocular dynamic scene re- construction
[Yanget al., 2024 ] Ziyi Yang, Xinyu Gao, Wen Zhou, Shao- hui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3d gaussians for high-fidelity monocular dynamic scene re- construction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20331– 20341,
2024
-
[20]
[Yanget al., 2025 ] Sizhe Yang, Wenye Yu, Jia Zeng, Jun Lv, Kerui Ren, Cewu Lu, Dahua Lin, and Jiangmiao Pang. Novel demonstration generation with gaussian splat- ting enables robust one-shot manipulation.arXiv preprint arXiv:2504.13175,
-
[21]
Omni6dpose: A benchmark and model for univer- sal 6d object pose estimation and tracking
[Zhanget al., 2024 ] Jiyao Zhang, Weiyao Huang, Bo Peng, Mingdong Wu, Fei Hu, Zijian Chen, Bo Zhao, and Hao Dong. Omni6dpose: A benchmark and model for univer- sal 6d object pose estimation and tracking. InEuropean Conference on Computer Vision, pages 199–216. Springer,
2024
-
[22]
Hugs: Holistic urban 3d scene understanding via gaussian splatting
[Zhouet al., 2024 ] Hongyu Zhou, Jiahao Shao, Lu Xu, Dongfeng Bai, Weichao Qiu, Bingbing Liu, Yue Wang, Andreas Geiger, and Yiyi Liao. Hugs: Holistic urban 3d scene understanding via gaussian splatting. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21336–21345,
2024
-
[23]
Motiongs: Exploring explicit motion guidance for deformable 3d gaussian splatting
[Zhuet al., 2024 ] Ruijie Zhu, Yanzhe Liang, Hanzhi Chang, Jiacheng Deng, Jiahao Lu, Wenfei Yang, Tianzhu Zhang, and Yongdong Zhang. Motiongs: Exploring explicit motion guidance for deformable 3d gaussian splatting. Advances in Neural Information Processing Systems, 37:101790–101817, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.