Space-CIM: Enabling Compute-In-Memory Accelerators for Thermally-Constrained Space Platforms
Pith reviewed 2026-06-27 23:36 UTC · model grok-4.3
The pith
Compute-in-memory accelerators achieve higher TOPS/W than GPUs when radiator cooling capacity limits space platforms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
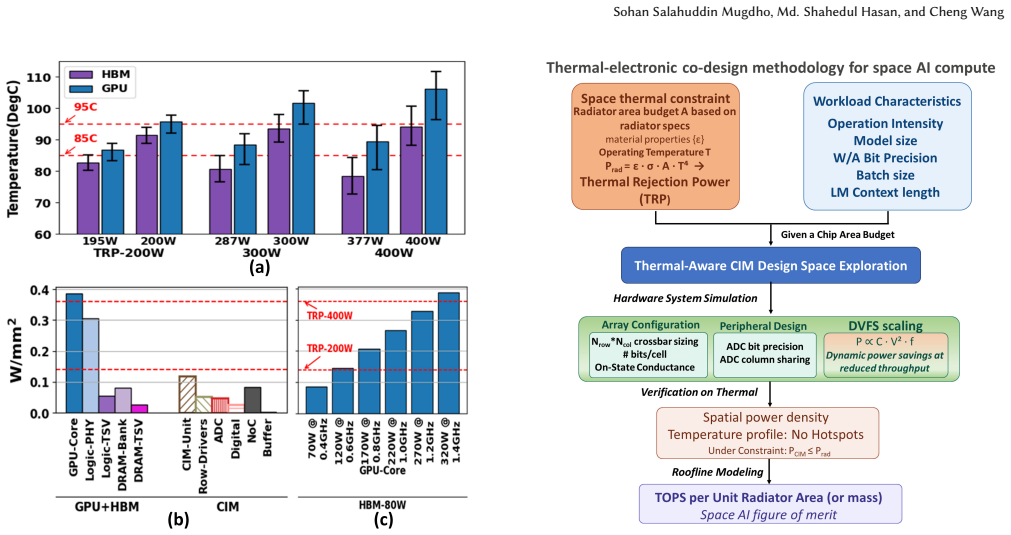
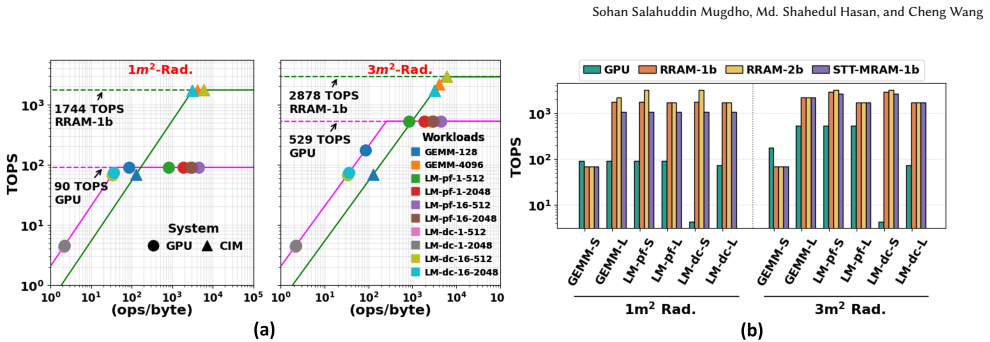
CIM accelerators exhibit a much more uniform heat distribution and consistently outperform GPUs in TOPS/W across a wide range of radiator budgets. Systematic evaluation across AI workloads demonstrates that CIM has a magnified advantage for deployment in space under realistic thermal constraints.
What carries the argument
The radiator-in-the-loop co-design methodology that directly links permitted system TOPS with practical radiator cooling capacity under vacuum conditions.
If this is right
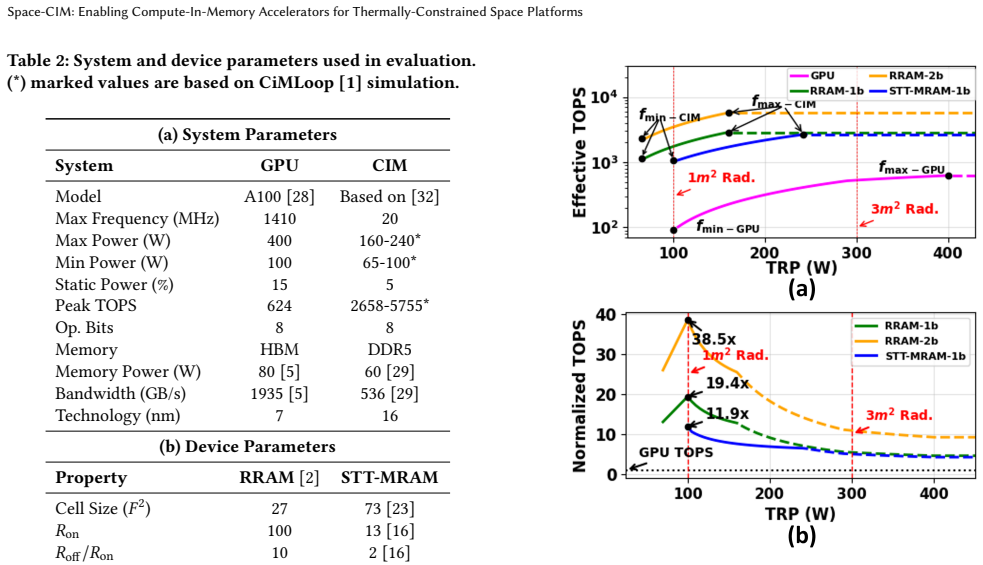
- CIM sustains higher effective throughput without thermal throttling for any fixed radiator area.
- The performance gap between CIM and GPU widens as available radiator capacity shrinks.
- CIM reduces the radiator area needed to reach a target compute rate compared with GPU designs.
- The advantage holds across multiple AI workloads when thermal constraints are enforced.
Where Pith is reading between the lines
- Orbital AI systems should favor CIM architectures if vacuum thermal behavior matches the modeled conditions.
- Combining the radiator sizing results with solar array mass and total platform volume would give a fuller picture of end-to-end efficiency.
- Hardware prototypes of both architectures could be compared in a thermal-vacuum chamber to test the simulation predictions directly.
Load-bearing premise
The thermal simulations accurately model heat flow for separately located GPU die and HBM versus integrated CIM under vacuum radiative cooling with no convection.
What would settle it
Measured heat maps and sustained TOPS from a GPU-HBM system versus an equivalent CIM accelerator tested in a vacuum chamber with controlled radiative cooling would confirm or refute the uniform distribution and performance advantage.
Figures

read the original abstract
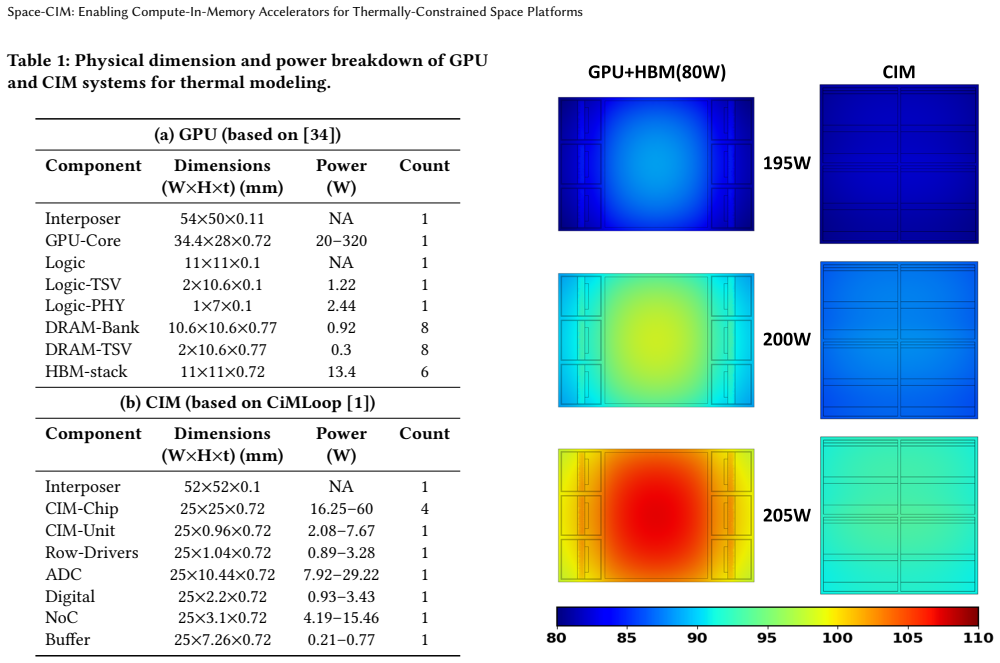
The rapid growth in compute demand from artificial intelligence (AI) has driven a massive surge in data center construction, precipitating an energy and sustainability crisis. Motivated by the abundant solar energy in outer space and the recent sharp reduction in space launch costs, orbital data centers are emerging as a potential pathway for the future scaling of AI compute infrastructure. While the cold background in vacuum seems appealing for cooling, computing systems operating in space without convection ultimately rely on radiative cooling, requiring large-area radiators. Such limitations in thermal management pose a significant challenge for deploying the standard liquid/air-cooled computers in space. In this work, we investigate the impact of the thermal constraints in space on both graphics processing units (GPUs) with high-bandwidth memory (HBM) and the emerging compute-in-memory (CIM) accelerators. We develop a radiator-in-the-loop co-design methodology that directly links the permitted system TOPS (terra-operations per second) with the practical radiator cooling capacity in space. Our thermal simulations reveal that the separately located GPU die and HBMs create severe thermal hotspots under limited radiator capacity, necessitating GPU thermal throttling. In contrast, CIM accelerators exhibit a much more uniform heat distribution and consistently outperform GPUs in TOPS/W across a wide range of radiator budgets. We systematically evaluated the performance of CIM and GPU across various AI workloads and demonstrated that CIM has a magnified advantage for deployment in space under realistic thermal constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a radiator-in-the-loop co-design methodology that couples permitted system TOPS to practical radiative cooling capacity for space platforms. Thermal simulations are used to show that discrete GPU die + HBM packages produce severe hotspots under limited radiator budgets, forcing thermal throttling, whereas CIM accelerators exhibit uniform heat distribution and deliver consistently higher TOPS/W across a range of radiator sizes; the advantage is reported to be magnified for AI workloads under realistic space thermal constraints.
Significance. If the underlying thermal model is accurate, the work supplies a concrete quantitative link between accelerator microarchitecture, power density, and radiator sizing that could inform accelerator selection for orbital AI infrastructure. The co-design framing itself is a useful contribution even if the numerical gap between CIM and GPU narrows after further model validation.
major comments (2)
- [Thermal simulation methodology (likely §4 or equivalent)] The central performance claims rest on the thermal simulation results that predict severe hotspots for separately packaged GPU+HBM versus uniform dissipation in CIM. The manuscript must supply the explicit model parameters (emissivities, view factors to the radiator, component locations and power maps) and any cross-validation against analytical radiative heat-transfer solutions or published vacuum-cooling data; without these, the reported TOPS/W gap cannot be assessed for systematic bias.
- [Abstract and §3 (co-design methodology)] The radiator-in-the-loop co-design claims to directly link permitted TOPS to cooling capacity, yet the abstract and visible text provide no governing equations, no error bars on the simulated temperatures or efficiencies, and no workload-specific power traces. These omissions make the quantitative superiority statements impossible to reproduce or bound.
minor comments (2)
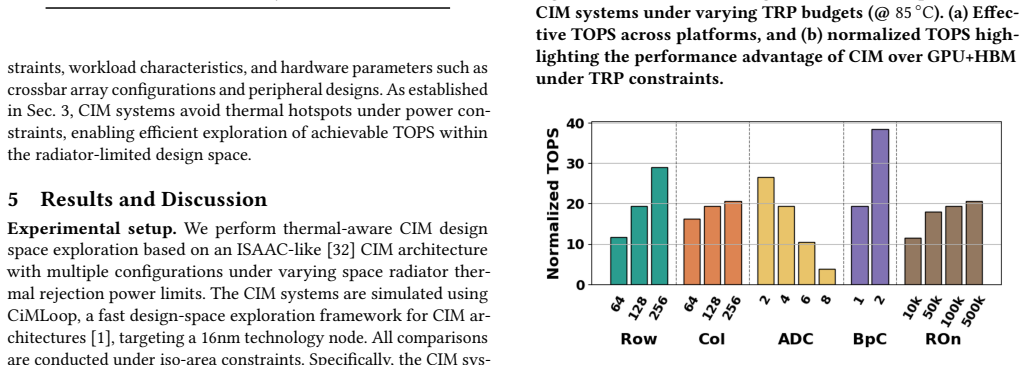
- [Figures 3–5] Figure captions and axis labels should explicitly state the radiator budget range (e.g., m² or W/K) and the exact AI workloads used for the TOPS/W comparison.
- [Throughout] Notation for TOPS/W should be defined once and used consistently; the distinction between peak and sustained efficiency under throttling should be clarified.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the reproducibility and clarity of our thermal co-design methodology. We address each major point below and have incorporated revisions to supply the requested details.
read point-by-point responses
-
Referee: The central performance claims rest on the thermal simulation results that predict severe hotspots for separately packaged GPU+HBM versus uniform dissipation in CIM. The manuscript must supply the explicit model parameters (emissivities, view factors to the radiator, component locations and power maps) and any cross-validation against analytical radiative heat-transfer solutions or published vacuum-cooling data; without these, the reported TOPS/W gap cannot be assessed for systematic bias.
Authors: We agree that explicit parameters are required to allow independent assessment of the thermal model. In the revised manuscript we have added a dedicated subsection (§4.2) that lists all emissivities, view factors, component locations, and power maps. We also include a direct comparison of the finite-element results against the analytical radiative heat-transfer equation for a simplified two-body system and reference published vacuum-chamber data for similar radiator configurations. These additions enable readers to evaluate potential systematic bias in the reported TOPS/W advantage. revision: yes
-
Referee: The radiator-in-the-loop co-design claims to directly link permitted TOPS to cooling capacity, yet the abstract and visible text provide no governing equations, no error bars on the simulated temperatures or efficiencies, and no workload-specific power traces. These omissions make the quantitative superiority statements impossible to reproduce or bound.
Authors: We accept that the governing equations, uncertainty quantification, and workload traces were insufficiently visible. Section 3 has been expanded to present the full set of radiator-in-the-loop equations, including the mapping from radiator area to allowable system power. We now report error bars derived from Monte-Carlo variation of emissivity and view-factor parameters, and we supply per-workload power traces for the evaluated AI models. These changes make the quantitative claims reproducible and bounded. revision: yes
Circularity Check
No circularity; claims rest on external thermal simulations and co-design methodology
full rationale
The abstract and provided context describe a radiator-in-the-loop co-design and thermal simulations comparing GPU+HBM hotspots versus CIM uniformity under vacuum radiative cooling. No equations, fitted parameters, self-citations, or ansatzes are shown that reduce any prediction to its own inputs by construction. The derivation chain is self-contained against the external simulation benchmarks rather than self-referential. This matches the reader's non-circularity assessment.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tanner Andrulis, Joel S. Emer, and Vivienne Sze. 2024. CiMLoop: A Flexible, Ac- curate, and Fast Compute-In-Memory Modeling Tool. In2024 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 10–23. doi:10.1109/ISPASS61541.2024.00012 Space-CIM: Enabling Compute-In-Memory Accelerators for Thermally-Constrained Space Platforms
-
[2]
Aayush Ankit, Izzat El Hajj, Sai Rahul Chalamalasetti, Geoffrey Ndu, Martin Foltin, R Stanley Williams, Paolo Faraboschi, Wen-mei W Hwu, John Paul Stra- chan, Kaushik Roy, et al. 2019. PUMA: A programmable ultra-efficient memristor- based accelerator for machine learning inference. InProceedings of the twenty- fourth international conference on architectu...
2019
-
[3]
Umberto Battista, Alberto Landini, Wojciech Golebiowski, Rafal Michalczyk, Adam Czerwinski, Krzysztof Duda, and Agata Sochaczewska. 2017. Design of Net Ejector for Space Debris Capturing. InProceedings of the 7th European Conference on Space Debris (SDC7). ESA Space Debris Office. https://conference. sdo.esoc.esa.int/proceedings/sdc7/paper/279
2017
-
[4]
Travis Beals, Maria Biggs, Jessica V Bloom, Thomas Fischbacher, Konstantin Gromov, Urs Köster, Rishiraj Pravahan, James Manyika, et al. 2025. Towards a future space-based, highly scalable AI infrastructure system design.arXiv preprint arXiv:2511.19468(2025)
Pith/arXiv arXiv 2025
-
[5]
Niladrish Chatterjee, Mike O’Connor, Donghyuk Lee, Daniel R Johnson, Stephen W Keckler, Minsoo Rhu, and William J Dally. 2017. Architecting an energy-efficient dram system for gpus. In2017 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 73–84
2017
-
[6]
Pranav Singh Chib and Pravendra Singh. 2024. Recent Advancements in End-to- End Autonomous Driving Using Deep Learning: A Survey.IEEE Transactions on Intelligent Vehicles9, 1 (2024), 103–118. doi:10.1109/TIV.2023.3318070
-
[7]
2015.COMSOL Multiphysics ® v5.1
COMSOL AB. 2015.COMSOL Multiphysics ® v5.1. COMSOL AB, Stockholm, Sweden. https://www.comsol.com
2015
-
[8]
Amir Gholami, Zhewei Yao, Sehoon Kim, Coleman Hooper, Michael W. Mahoney, and Kurt Keutzer. 2024. AI and Memory Wall.IEEE Micro44, 3 (2024), 33–39. doi:10.1109/MM.2024.3373763
-
[9]
David G. Gilmore. 2002.Spacecraft Thermal Control Handbook, Volume I: Funda- mental Technologies(2 ed.). The Aerospace Press, El Segundo, CA, USA
2002
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, et al . 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
Pith/arXiv arXiv 2024
-
[11]
Joao Guerreiro, Aleksandar Ilic, Nuno Roma, and Pedro Tomas. 2018. GPGPU power modeling for multi-domain voltage-frequency scaling. In2018 IEEE Inter- national Symposium on High Performance Computer Architecture (HPCA). IEEE, 789–800
2018
-
[12]
Phatak, Cheng Wang, and Supratik Guha
Wilfried Haensch, Anand Raghunathan, Kaushik Roy, Bhaswar Chakrabarti, Charudatta M. Phatak, Cheng Wang, and Supratik Guha. 2023. Compute in- Memory with Non-Volatile Elements for Neural Networks: A Review from a Co-Design Perspective.Advanced Materials35, 37 (2023), 2204944. doi:10.1002/ adma.202204944
2023
-
[13]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition. 770–778
2016
-
[14]
Jeremy Hsu. 2025. Data Centers in Space Aren’t as Wild as They Sound.Scien- tific American(9 Dec. 2025). https://www.scientificamerican.com/article/data- centers-in-space/ Online; accessed 2026-03-01
2025
-
[15]
Naoko Iwata, Sogo Nakanoya, Nobuyuki Nakamura, Noboru Takeda, and Fumiya Tsutsui. 2022. Thermal performance evaluation of space radiator for single-phase mechanically pumped fluid loop.Journal of Spacecraft and Rockets59, 1 (2022), 225–235
2022
-
[16]
Seungchul Jung, Hyungwoo Lee, Sungmeen Myung, Hyunsoo Kim, Seung Keun Yoon, Soon-Wan Kwon, Yongmin Ju, Minje Kim, Wooseok Yi, Shinhee Han, et al
-
[17]
A crossbar array of magnetoresistive memory devices for in-memory computing.Nature601, 7892 (2022), 211–216
2022
-
[18]
George Karfakis, Myriam Bouzidi, Yunhyeok Im, Alexander Graening, Suresh K. Sitaraman, and Puneet Gupta. 2025. Optimizing Thermal Performance in 2.5D Systems Using Embedded Isolators.IEEE Journal on Emerging and Selected Topics in Circuits and Systems15, 3 (2025), 458–468. doi:10.1109/JETCAS.2025.3595909
-
[19]
Andrej Karpathy. 2022. nanoGPT: The simplest, fastest repository for train- ing/finetuning medium-sized GPTs. https://github.com/karpathy/nanoGPT. Ac- cessed: 2026-03-18
2022
-
[20]
Riduan Khaddam-Aljameh, Milos Stanisavljevic, Jordi Fornt Mas, Geethan Karunaratne, Matthias Brändli, Feng Liu, Abhairaj Singh, Silvia M Müller, Urs Egger, Anastasios Petropoulos, et al. 2022. HERMES-core—A 1.59-TOPS/mm 2 PCM on 14-nm CMOS in-memory compute core using 300-ps/LSB linearized CCO-based ADCs.IEEE Journal of Solid-State Circuits57, 4 (2022), 1027–1038
2022
-
[21]
Dong Eun Kim, Aayush Ankit, Cheng Wang, and Kaushik Roy. 2023. SAMBA: Sparsity Aware In-Memory Computing Based Machine Learning Accelerator. IEEE Trans. Comput.72, 9 (2023), 2615–2627. doi:10.1109/TC.2023.3257513
-
[22]
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. 2015. Deep learning.nature 521, 7553 (2015), 436–444
2015
-
[23]
Jingwen Leng, Isaac Hetherington, Ahmed ElTantawy, Syed Gilani, Wilson WL Fung, and Tor M Aamodt. 2013. GPUWattch: enabling energy optimizations in GPGPUs. InProceedings of the 40th Annual International Symposium on Computer Architecture. 487–498. doi:10.1145/2485922.2485964
-
[24]
Ku-Feng Lin, Hiroki Noguchi, Yi-Chun Shih, Perng-Fei Yuh, Yuan-Jen Lee, Tung- Cheng Chang, Sheng-Po Huang, Yu-Fan Lin, Chun-Ying Lee, Yen-Hsiang Huang, et al. 2024. 15.9 A 16nm 16Mb embedded STT-MRAM with a 20ns write time, a 10 12 write endurance and integrated margin-expansion schemes. In2024 IEEE International Solid-State Circuits Conference (ISSCC), V...
2024
-
[25]
Yaoqi Liu, Yinhe Han, Hongxin Li, Shuhao Gu, Jibing Qiu, and Ting Li. 2025. Computing over Space: Status, Challenges, and Opportunities.Engineering54, 11 (2025), 20–25. doi:10.1016/j.eng.2025.06.005
-
[26]
Rui Lu and Dan Wang. 2025. A Thermal-aware Workload Scheduler for High- performance LLM Inference in Cooling-regulated Datacenters.ACM SIGENERGY Energy Informatics Review5, 2 (2025), 98–104
2025
-
[27]
2024.How data centers and the energy sector can sate AI’s hunger for power
McKinsey & Company. 2024.How data centers and the energy sector can sate AI’s hunger for power. Technical Report. McKinsey & Com- pany. https://www.mckinsey.com/industries/private-capital/our-insights/how- data-centers-and-the-energy-sector-can-sate-ais-hunger-for-power Data cen- ter load may make up between 30 and 40 percent of all net new demand added u...
2024
-
[28]
Mohd Halim Mohd Noor and Ayokunle Olalekan Ige. 2025. A survey on state-of- the-art deep learning applications and challenges.Engineering Applications of Artificial Intelligence159 (2025), 111225
2025
-
[29]
NVIDIA Corporation. 2020. NVIDIA A100 Tensor Core GPU Ar- chitecture. https://resources.nvidia.com/en-us-tensor-core/nvidia-ampere- architecture-whitepaper. Accessed: 2026-03-06
2020
-
[30]
Mike O’Connor, Niladrish Chatterjee, and Others. 2017. Fine-grained DRAM: Energy-efficient DRAM for extreme bandwidth systems. InProceedings of the 50th Annual IEEE/ACM MICRO. 41–54
2017
-
[31]
Anichur Rahman, Tanoy Debnath, Dipanjali Kundu, Md Saikat Islam Khan, Airin Afroj Aishi, Sadia Sazzad, Mohammad Sayduzzaman, and Shahab S Band
-
[32]
Machine learning and deep learning-based approach in smart healthcare: Recent advances, applications, challenges and opportunities.AIMS public health 11, 1 (2024), 58
2024
-
[33]
Bharath Ramakrishnan, Cam Turner, Husam Alissa, Dennis Trieu, Felipe Rivera, Luke Melton, Muralikrishna Rao, Sruti Chigullapalli, Tatek Getachew, Vladimir Prodanovic, et al. 2025. Understanding the impact of data center liquid cooling on energy and performance of machine learning and artificial intelligence workloads. Journal of Electronic Packaging147, 2...
2025
-
[34]
Stanley Williams, and Vivek Srikumar
Ali Shafiee, Anirban Nag, Naveen Muralimanohar, Rajeev Balasubramonian, John Paul Strachan, Miao Hu, R. Stanley Williams, and Vivek Srikumar. 2016. ISAAC: a convolutional neural network accelerator with in-situ analog arithmetic in crossbars. InProceedings of the 43rd International Symposium on Computer Architecture(Seoul, Republic of Korea)(ISCA ’16). IE...
2016
-
[35]
Pia Singh. 2025. Nvidia-backed Starcloud trains first AI model in space, orbital data centers. CNBC News Article. https://www.cnbc.com/2025/12/10/nvidia- backed-starcloud-trains-first-ai-model-in-space-orbital-data-centers.html Ac- cessed 2026-03-01
2025
-
[36]
Keeyoung Son, Joonsang Park, Seongguk Kim, Boogyo Sim, Keunwoo Kim, Seonguk Choi, Hyunsik Kim, and Joungho Kim. 2023. Thermal Analysis of High Bandwidth Memory (HBM)-GPU Module considering Power Consumption. In 2023 IEEE Electrical Design of Advanced Packaging and Systems (EDAPS). 1–3. doi:10.1109/EDAPS58880.2023.10468315
-
[37]
Zhenheng Tang, Yuxin Wang, Qiang Wang, and Xiaowen Chu. 2019. The impact of GPU DVFS on the energy and performance of deep learning: An empirical study. InProceedings of the Tenth ACM International Conference on Future Energy Systems. 315–325
2019
-
[38]
Weier Wan, Rajkumar Kubendran, Clemens Schaefer, Sukru Burc Eryilmaz, Wenqiang Zhang, Dabin Wu, Stephen Deiss, Priyanka Raina, He Qian, Bin Gao, et al. 2022. A compute-in-memory chip based on resistive random-access memory. Nature608, 7923 (2022), 504–512
2022
-
[39]
Dan Zhao, Siddharth Samsi, Joseph McDonald, Baolin Li, David Bestor, Michael Jones, Devesh Tiwari, and Vijay Gadepally. 2023. Sustainable supercomputing for AI: GPU power capping at HPC scale. InProceedings of the 2023 ACM symposium on cloud computing. 588–596
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.