Response-free item difficulty modelling for multiple-choice items with fine-tuned transformers: Component-wise representation and multi-task learning
Pith reviewed 2026-05-19 20:18 UTC · model grok-4.3
The pith
Fine-tuned transformers predict multiple-choice item difficulty directly from wording, with multi-task learning aiding small-sample cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
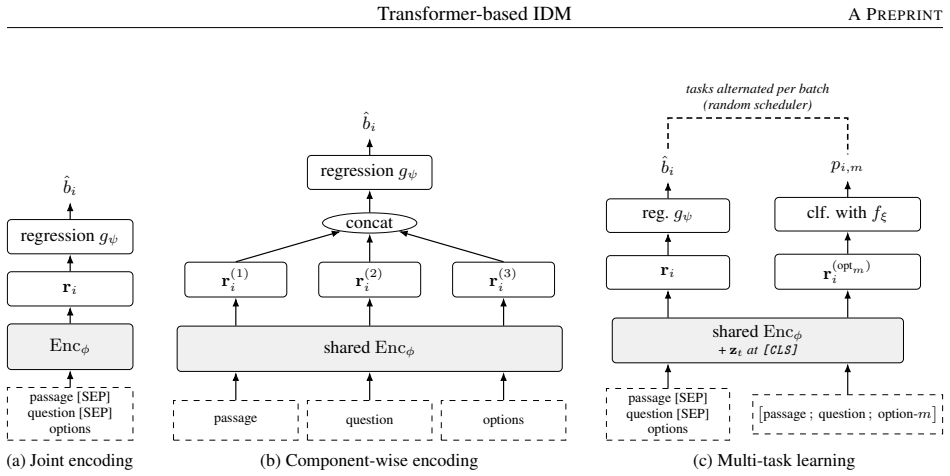
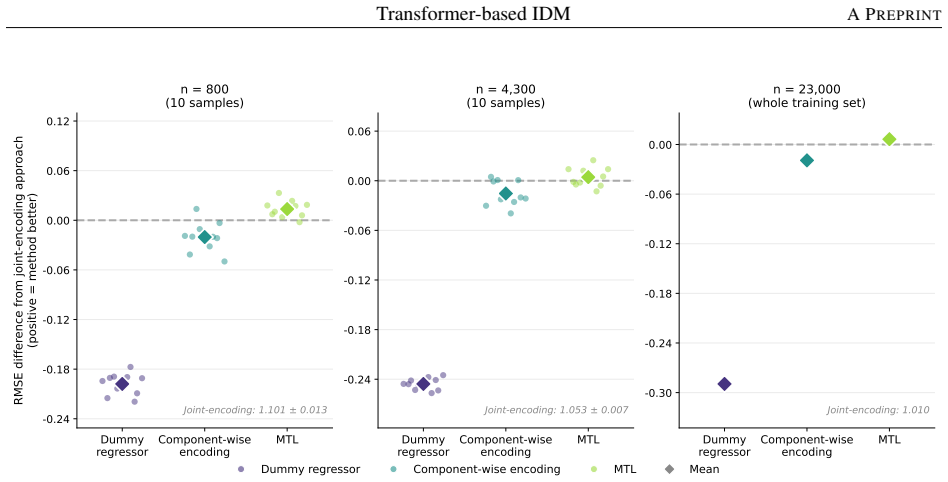
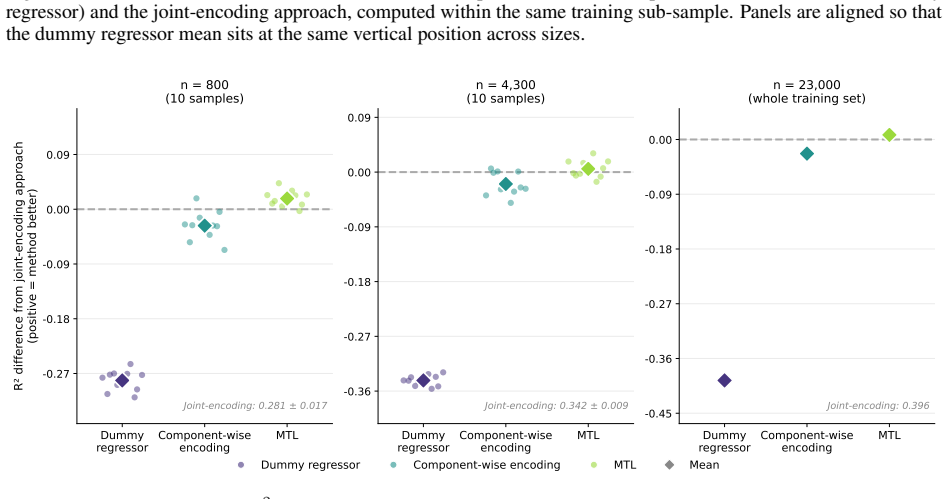
Joint encoding of item wording via fine-tuned transformers provides a workable end-to-end alternative to manual feature-engineering pipelines for response-free difficulty modeling; component-wise encoding confers no detectable advantage, while adding an auxiliary multiple-choice question-answering objective produces significant paired improvements in the smallest-sample regime and recovers a substantial share of the wording-derivable signal at training-set sizes typical of applied measurement.
What carries the argument
A shared transformer encoder fine-tuned jointly on item wording for difficulty regression, optionally augmented by an auxiliary multiple-choice question-answering task that regularizes the representation.
If this is right
- Joint transformer encoding removes the need for manual feature extraction and preprocessing steps that can discard information.
- Self-attention within a single encoder already captures cross-component signals, rendering separate component-wise encoding redundant.
- Multi-task regularization with an auxiliary QA objective improves difficulty estimates particularly when response data for training is limited.
- The approach supplies a flexible interface that can incorporate further psychometrically motivated auxiliary tasks.
Where Pith is reading between the lines
- If wording alone carries most of the difficulty signal, test developers could screen or rank new items before any piloting occurs, cutting development time.
- The same multi-task setup might extend to predicting other item properties such as discrimination or guessing parameters when those are also partly wording-driven.
- Performance gains from auxiliary tasks suggest that difficulty modeling could benefit from borrowing representations learned on large general QA corpora even when local response data remains small.
Load-bearing premise
Item difficulty is determined enough by surface and inferential features in the wording itself, without needing specific details about the student population or testing context.
What would settle it
Observe that the model's difficulty predictions on a held-out set of items deviate substantially from empirical difficulties measured in a new student population whose background or prior knowledge differs markedly from the training data.
Figures

read the original abstract
Response-free item difficulty modelling promises to reduce reliance on response-based calibration but is intrinsically difficult on reading-comprehension multiple-choice items, where difficulty depends on inferential demands across wording components. Whereas most existing approaches extract item-text features and pass them to a separate statistical or machine-learning model, we fine-tune transformer encoders end-to-end on the item wording, eliminating the manual feature engineering and preprocessing that discards information. Moreover, two extensions to this joint-encoding approach are proposed: a component-wise variant that encodes wording components separately through a shared encoder, and a multi-task variant that retains joint encoding and adds an auxiliary multiple-choice question answering objective on the shared encoder. Each method is evaluated under a Monte Carlo subsampling design at three training-set sizes on a held-out test set. We find that joint encoding is a viable end-to-end alternative to feature-engineering pipelines; while the component-wise variant shows no detectable benefit, consistent with self-attention already harvesting the cross-component signal, the multi-task variant delivers significant paired improvements in the smallest-sample regime. Transformer fine-tuning, especially if regularised by a suitable auxiliary task, recovers a substantial share of the wording-derivable signal at training-set sizes typical of applied measurement. The framework provides a customisable interface for psychometrically motivated extensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents methods for response-free modeling of item difficulty in multiple-choice reading comprehension items using fine-tuned transformer encoders on item wording. It introduces a component-wise representation where wording components are encoded separately and a multi-task learning approach that adds an auxiliary multiple-choice question answering task. These are compared to a joint encoding baseline using a Monte Carlo subsampling design with held-out test sets at three different training set sizes. The key finding is that the multi-task variant provides significant paired improvements in the smallest sample regime, while the component-wise variant does not, suggesting that self-attention already captures cross-component information. The authors conclude that this approach recovers a substantial share of the wording-derivable difficulty signal.
Significance. Should the results prove robust, the work is significant as it offers an end-to-end deep learning alternative to manual feature extraction for difficulty prediction, which can be valuable in educational assessment where collecting response data is expensive. The demonstration of multi-task benefits at small training sizes is particularly useful for practical applications. The use of Monte Carlo subsampling and held-out evaluation provides a reasonable basis for the performance claims.
major comments (2)
- [§4.2] §4.2 (Results): The reported 'significant paired improvements' for the multi-task variant at the smallest training-set size are presented without error bars, standard deviations across Monte Carlo subsamples, or details on the paired statistical test and multiple-comparison correction; this directly affects the strength of the central claim regarding the multi-task benefit in the low-data regime.
- [§6] §6 (Discussion): The interpretation that the model recovers a 'substantial share of the wording-derivable signal' treats within-pool held-out performance as direct evidence, but the evaluation does not test or discuss transfer across student populations or test contexts; this assumption is load-bearing for the broader promise of response-free modelling since difficulty is known to interact with population-specific factors.
minor comments (2)
- [Abstract] The abstract could explicitly state the three training-set sizes used in the subsampling design to improve readability.
- [§3.1] Notation for the shared encoder in the component-wise variant would benefit from an accompanying diagram or explicit equation for the aggregation step.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on our manuscript. We address each major comment point by point below, indicating where revisions will be incorporated.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Results): The reported 'significant paired improvements' for the multi-task variant at the smallest training-set size are presented without error bars, standard deviations across Monte Carlo subsamples, or details on the paired statistical test and multiple-comparison correction; this directly affects the strength of the central claim regarding the multi-task benefit in the low-data regime.
Authors: We agree that reporting variability measures and full details of the statistical analysis would strengthen the presentation of the central results. In the revised manuscript we will add standard deviations across the Monte Carlo subsamples to the relevant tables, include error bars on the performance plots, and expand the description of the paired statistical test (including the exact test used and any multiple-comparison correction) in Section 4.2. These additions will allow readers to evaluate the robustness of the reported improvements directly. revision: yes
-
Referee: [§6] §6 (Discussion): The interpretation that the model recovers a 'substantial share of the wording-derivable signal' treats within-pool held-out performance as direct evidence, but the evaluation does not test or discuss transfer across student populations or test contexts; this assumption is load-bearing for the broader promise of response-free modelling since difficulty is known to interact with population-specific factors.
Authors: We acknowledge that our evaluation is limited to within-pool held-out performance on a single dataset and does not examine transfer across student populations or testing contexts. In the revised Discussion we will explicitly state this scope limitation, note that item difficulty is known to interact with population-specific factors, and qualify the claim of recovering a 'substantial share of the wording-derivable signal' to the setting studied. We will also add a forward-looking statement identifying cross-context transfer as an important direction for future work. Because the current study does not include data from multiple populations, we cannot perform such transfer experiments in this revision. revision: partial
Circularity Check
No significant circularity; results are empirical performance on held-out data
full rationale
The paper evaluates transformer fine-tuning, component-wise encoding, and multi-task learning for response-free difficulty prediction using Monte Carlo subsampling on held-out test sets at varying training sizes. All reported improvements are measured as paired differences in prediction accuracy on items excluded from training, with no equations or claims that reduce a derived quantity to a fitted parameter by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the core results; the framework is presented as an empirical alternative to feature-engineering pipelines rather than a deductive derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- training set size
axioms (1)
- domain assumption Item difficulty depends on inferential demands across wording components
Reference graph
Works this paper leans on
-
[1]
AlKhuzaey, Samah and Grasso, Floriana and Payne, Terry R. and Tamma, Valentina , date =. Text-based question difficulty prediction:. doi:10.1007/s40593-023-00362-1 , url =
-
[2]
Belov, Dmitry and Lüdtke, Oliver and Ulitzsch, Esther , date =. A. OSF , doi =
- [3]
- [5]
-
[6]
Caruana, Rich , date =. Multitask. doi:10.1023/A:1007379606734 , url =
-
[7]
Comanici, Gheorghe and Bieber, Eric and Schaekermann, Mike and Pasupat, Ice and Sachdeva, Noveen and Dhillon, Inderjit and Blistein, Marcel and Ram, Ori and Zhang, Dan and Rosen, Evan and Marris, Luke and Petulla, Sam and Gaffney, Colin and Aharoni, Asaf and Lintz, Nathan and Pais, Tiago Cardal and Jacobsson, Henrik and Szpektor, Idan and Jiang, Nan-Jiang...
-
[8]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , date =. arXiv , doi =
-
[9]
Freedle, Roy and Kostin, Irene , date =. The prediction of. doi:10.1177/026553229301000203 , url =
-
[10]
Gombert, Sebastian and Menzel, Lukas and Di Mitri, Daniele and Drachsler, Hendrik , editor =. Predicting. Proceedings of the 19th
-
[11]
and Perelman, Adam and Ramesh, Aditya and Clark, Aidan and Ostrow, A
OpenAI and Hurst, Aaron and Lerer, Adam and Goucher, Adam P. and Perelman, Adam and Ramesh, Aditya and Clark, Aidan and Ostrow, A. J. and Welihinda, Akila and Hayes, Alan and Radford, Alec and Mądry, Aleksander and Baker-Whitcomb, Alex and Beutel, Alex and Borzunov, Alex and Carney, Alex and Chow, Alex and Kirillov, Alex and Nichol, Alex and Paino, Alex a...
- [12]
-
[13]
Predicting the difficulty of multiple choice questions in a high-stakes medical exam , booktitle =
Ha, Le An and Yaneva, Victoria and Baldwin, Peter and Mee, Janet , editor =. Predicting the difficulty of multiple choice questions in a high-stakes medical exam , booktitle =. doi:10.18653/v1/W19-4402 , url =
- [14]
-
[15]
Jawahar, Ganesh and Sagot, Benoît and Seddah, Djamé , editor =. What. Proceedings of the 57th. doi:10.18653/v1/P19-1356 , url =
-
[16]
Lai, Guokun and Xie, Qizhe and Liu, Hanxiao and Yang, Yiming and Hovy, Eduard , date =. arXiv , doi =
-
[18]
Fine-tuning language models to predict item difficulty from wording , author =
-
[19]
doi:10.48550/arXiv.2303.08774 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774
- [20]
-
[21]
Rodrigo, Alvaro and Moreno-Álvarez, Sergio and Peñas, Anselmo , editor =. Proceedings of the 19th
-
[23]
LaFlair, Geoffrey and Hagiwara, Masato , date =
Settles, Burr and T. LaFlair, Geoffrey and Hagiwara, Masato , date =. Machine. doi:10.1162/tacl_a_00310 , url =
-
[24]
Sharpnack, James and Hao, Kevin and Mulcaire, Phoebe and Bicknell, Klinton and LaFlair, Geoff and Yancey, Kevin and family=Davier, given=Alina A., prefix=von, useprefix=true , date =. Proceedings of
-
[26]
Štěpánek, Lubomír and Dlouhá, Jana and Martinková, Patrícia , date =. Item. doi:10.3390/math11194104 , url =
- [28]
-
[30]
Natural language processing with transformers: building language applications with
Tunstall, Lewis and family=Werra, given=Leandro, prefix=von, useprefix=false and Wolf, Thomas , date =. Natural language processing with transformers: building language applications with
-
[31]
International Conference on Learning Representations (ICLR) , eprint =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations (ICLR) , eprint =
-
[35]
doi:10.1038/s42256-020-00257-z , url =
Shortcut learning in deep neural networks , author =. doi:10.1038/s42256-020-00257-z , url =
-
[36]
Applied Psychological Measurement , volume =
Component Latent Trait Models for Paragraph Comprehension Tests , author =. Applied Psychological Measurement , volume =. 1987 , doi =
work page 1987
-
[37]
Applied Psychological Measurement , volume =
Item Difficulty Modeling of Paragraph Comprehension Items , author =. Applied Psychological Measurement , volume =. 2006 , doi =
work page 2006
-
[38]
Behavior Research Methods , volume =
Where's the Difficulty in Standardized Reading Tests: The Passage or the Question? , author =. Behavior Research Methods , volume =. 2008 , doi =
work page 2008
-
[39]
Xue, Kang and Yaneva, Victoria and Runyon, Christopher and Baldwin, Peter , editor =. Predicting the. Proceedings of the. doi:10.18653/v1/2020.bea-1.20 , url =
-
[40]
and Runge, Andrew and LaFlair, Geoffrey and Mulcaire, Phoebe , editor =
Yancey, Kevin P. and Runge, Andrew and LaFlair, Geoffrey and Mulcaire, Phoebe , editor =. Proceedings of the 19th
-
[41]
Yaneva, Victoria and North, Kai and Baldwin, Peter and Ha, Le An and Rezayi, Saed and Zhou, Yiyun and Ray Choudhury, Sagnik and Harik, Polina and Clauser, Brian , editor =. Findings from the. Proceedings of the 19th
-
[42]
Zhou, Ya and Tao, Can , date =. Multi-task. 2020. doi:10.1109/CISCE50729.2020.00048 , url =
-
[43]
Zou, Jiajie and Zhang, Yuran and Jin, Peiqing and Luo, Cheng and Pan, Xunyi and Ding, Nai , date =. arXiv , url =
-
[44]
and Lüdtke, Oliver and Ulitzsch, Esther , date =
Belov, Dmitry I. and Lüdtke, Oliver and Ulitzsch, Esther , date =. A supervised learning approach to estimating. doi:10.1111/bmsp.12396 , url =
-
[45]
Ulitzsch, Esther and Belov, Dmitry and Lüdtke, Oliver and Robitzsch, Alexander , date =. Using. doi:10.1111/jedm.12426 , url =
-
[46]
Proceedings of The Eleventh Asian Conference on Machine Learning , pages =
A New Multi-choice Reading Comprehension Dataset for Curriculum Learning , author =. Proceedings of The Eleventh Asian Conference on Machine Learning , pages =. 2019 , editor =
work page 2019
-
[47]
Rogers, Anna and Kovaleva, Olga and Rumshisky, Anna , journal =. A Primer in. 2020 , doi =
work page 2020
-
[48]
An Overview of Multi-Task Learning in Deep Neural Networks , author =. arXiv , year =
-
[49]
Explanatory Item Response Models: A Generalized Linear and Nonlinear Approach , editor =
-
[50]
Generating Items during Testing: Psychometric Issues and Models , author =. Psychometrika , volume =. 1999 , doi =
work page 1999
-
[51]
Item Response Theory for Psychologists , author =
-
[52]
Probabilistic Models for Some Intelligence and Attainment Tests , author =
-
[53]
The Linear Logistic Test Model as an Instrument in Educational Research , author =. Acta Psychologica , volume =. 1973 , doi =
work page 1973
-
[54]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =
Jump-Starting Item Parameters for Adaptive Language Tests , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =. 2021 , publisher =
work page 2021
-
[55]
and Runge, Andrew and LaFlair, Geoffrey and Mulcaire, Phoebe , booktitle =
Yancey, Kevin P. and Runge, Andrew and LaFlair, Geoffrey and Mulcaire, Phoebe , booktitle =. 2024 , publisher =
work page 2024
-
[56]
Item characteristics and test-taker disengagement in
-
[57]
Triplet loss , booktitle =
-
[58]
Alberts, René V. J. , date =. Equating. doi:10.1080/09695940120089143 , url =
-
[59]
Charles and Wall, Dianne , date =
Alderson, J. Charles and Wall, Dianne , date =. Does. doi:10.1093/applin/14.2.115 , url =
-
[60]
A similarity-based theory of controlling
Alsubait, Tahani and Parsia, Bijan and Sattler, Ulrike , date =. A similarity-based theory of controlling. 2013. doi:10.1109/ICeLeTE.2013.6644389 , url =
-
[61]
A taxonomy for learning, teaching, and assessing: a revision of
-
[62]
doi:10.1037/0003-066X.57.12.1060 , abstract =
Ethical. doi:10.1037/0003-066X.57.12.1060 , abstract =
-
[63]
doi:10.1002/ets2.12042 , url =
Estimating item difficulty with comparative judgments , author =. doi:10.1002/ets2.12042 , url =
-
[64]
Attali, Yigal and Runge, Andrew and LaFlair, Geoffrey T. and Yancey, Kevin and Goodwin, Sarah and Park, Yena and family=Davier, given=Alina A., prefix=von, useprefix=true , date =. The interactive reading task:. doi:10.3389/frai.2022.903077 , url =
-
[65]
Bartels, Meike and Rietveld, Marjolein J. H. and Baal, G. Caroline M. Van and Boomsma, Dorret I. , date =. Heritability of. doi:10.1375/twin.5.6.544 , url =
-
[66]
Robustness of equating high-stakes tests , author =
-
[67]
Use of different sources of information in maintaining standards: examples from the
Beguin, Anton , date =. Use of different sources of information in maintaining standards: examples from the. Psychometrics in. doi:10.3990/3.9789036533744.ch3 , url =
-
[68]
New developments in categorial data analysis for the social and behavioral sciences , author =
The. New developments in categorial data analysis for the social and behavioral sciences , author =
-
[69]
Belcak, Peter and Heinrich, Greg and Diao, Shizhe and Fu, Yonggan and Dong, Xin and Muralidharan, Saurav and Lin, Yingyan Celine and Molchanov, Pavlo , date =. Small. doi:10.48550/arXiv.2506.02153 , url =. 2506.02153 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.02153
-
[70]
Belov, Dmitry and Lüdtke, Oliver and Ulitzsch, Esther , date =. A. doi:10.31234/osf.io/w3cyq_v1 , url =
-
[71]
doi:10.1145/3375462.3375517 , url =
Benedetto, Luca and Cappelli, Andrea and Turrin, Roberto and Cremonesi, Paolo , date =. doi:10.1145/3375462.3375517 , url =
-
[72]
Benedetto, Luca and Aradelli, Giovanni and Cremonesi, Paolo and Cappelli, Andrea and Giussani, Andrea and Turrin, Roberto , editor =. On the application of. Proceedings of the 16th
-
[73]
Benedetto, Luca , date =. A quantitative study of. doi:10.48550/arXiv.2305.10236 , url =. 2305.10236 , eprinttype =
-
[74]
Benedetto, Luca and Cremonesi, Paolo and Caines, Andrew and Buttery, Paula and Cappelli, Andrea and Giussani, Andrea and Turrin, Roberto , date =. A. doi:10.1145/3556538 , url =
-
[75]
The impact of standardized test feedback in math:
Beuchert, Louise and Eriksen, Tine Louise Mundbjerg and Krægpøth, Morten Visby , date =. The impact of standardized test feedback in math:. doi:10.1016/j.econedurev.2020.102017 , url =
-
[76]
Taxonomy of educational objectives:
Bloom, Benjamin S and Engelhart, Max D and Furst, Edward J and Hill, Walker H and Krathwohl, David R , date =. Taxonomy of educational objectives:
-
[77]
doi:10.1007/BF02291411 , abstract =
Estimating item parameters and latent ability when responses are scored in two or more nominal categories , author =. doi:10.1007/BF02291411 , abstract =
-
[78]
Darrell and Aitkin, Murray , date =
Bock, R. Darrell and Aitkin, Murray , date =. Marginal maximum likelihood estimation of item parameters:. doi:10.1007/BF02293801 , abstract =
-
[79]
Brown, Gavin T. L. and O’Leary, Timothy M. and Hattie, John A. C. , date =. Effective reporting for formative assessment:. Score
-
[80]
Brown, Gavin T. L. and O'Leary, Timothy M. and Hattie, John A. C. , date =. Effective reporting for formative assessment:. Score
-
[81]
Interaktivní nástroj pro podporu vyhodnocování dat ze standardizovaných testů , booktitle =
Martinková, Patrícia and Potužníková, Eva and Netík, Jan , editor =. Interaktivní nástroj pro podporu vyhodnocování dat ze standardizovaných testů , booktitle =
-
[82]
Cígler, Hynek , date =. Psychometrik Hynek Cígler: Státní maturita nenaplňuje standardy pedagogického testování , shorttitle =
-
[83]
Hoe komt een examenopgave tot stand? , author =
-
[84]
Organisatie & governance , url =
-
[85]
Toelichting op de normering , author =
-
[86]
Comanici, Gheorghe and Bieber, Eric and Schaekermann, Mike and Pasupat, Ice and Sachdeva, Noveen and Dhillon, Inderjit and Blistein, Marcel and Ram, Ori and Zhang, Dan and Rosen, Evan and Marris, Luke and Petulla, Sam and Gaffney, Colin and Aharoni, Asaf and Lintz, Nathan and Pais, Tiago Cardal and Jacobsson, Henrik and Szpektor, Idan and Jiang, Nan-Jiang...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.06261
-
[87]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , date =. doi:10.48550/arXiv.1810.04805 , url =. 1810.04805 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1810.04805
-
[88]
Predikce obtížnosti položek pomocí modulu EduTest Text Analysis , author =
-
[89]
Docentenparticipatie , author =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.