S2MAM: Semi-supervised Meta Additive Model for Robust Estimation and Variable Selection
Pith reviewed 2026-05-10 03:34 UTC · model grok-4.3
The pith
S2MAM uses bilevel optimization to automatically select informative variables and update similarity matrices in manifold-regularized semi-supervised learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
S2MAM formulates semi-supervised manifold regularization as a bilevel program in which the outer level identifies informative variables and refines the similarity matrix while the inner level produces additive-model predictions; the scheme is accompanied by proofs of algorithmic convergence and a statistical generalization bound.
What carries the argument
Bilevel optimization that couples an outer problem of variable selection and similarity-matrix update with an inner problem of additive-model fitting under manifold regularization.
If this is right
- Variable selection occurs automatically during training rather than as a separate preprocessing step.
- The learned model remains interpretable because it is additive and the active variables are explicitly identified.
- Generalization bounds hold under the stated manifold and optimization assumptions.
- Robustness is observed across multiple corruption types and intensities in the reported experiments.
Where Pith is reading between the lines
- The bilevel structure could be adapted to other regularizers that depend on a similarity graph.
- High-dimensional applications with many irrelevant features would be a natural test bed for the variable-selection component.
- If the manifold assumption is mildly violated the method may still outperform fixed-metric baselines provided the bilevel updates remain stable.
Load-bearing premise
The data distribution is supported on a Riemannian manifold and the bilevel updates to the similarity matrix do not introduce additional bias.
What would settle it
A controlled experiment on data whose support is not a manifold, or where bilevel updates demonstrably increase bias relative to a fixed similarity matrix, would refute the central claim.
Figures
read the original abstract
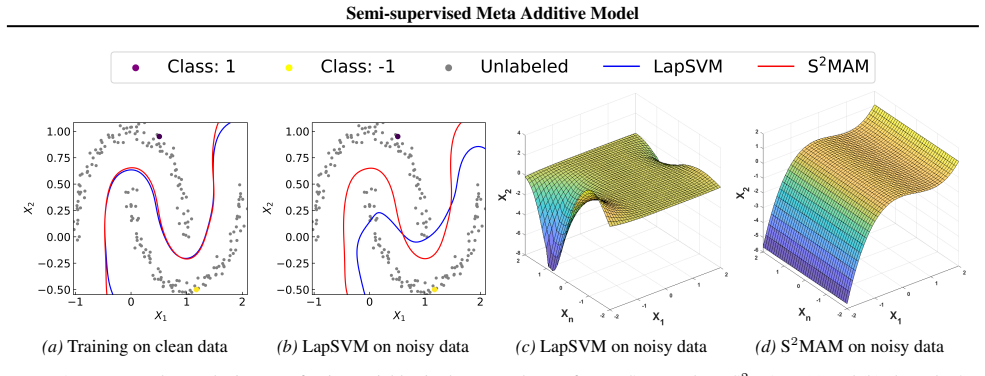
Semi-supervised learning with manifold regularization is a classical framework for jointly learning from both labeled and unlabeled data, where the key requirement is that the support of the unknown marginal distribution has the geometric structure of a Riemannian manifold. Typically, the Laplace-Beltrami operator-based manifold regularization can be approximated empirically by the Laplacian regularization associated with the entire training data and its corresponding graph Laplacian matrix. However, the graph Laplacian matrix depends heavily on the prespecified similarity metric and may lead to inappropriate penalties when dealing with redundant or noisy input variables. To address the above issues, this paper proposes a new Semi-Supervised Meta Additive Model (S$^2$MAM) based on a bilevel optimization scheme that automatically identifies informative variables, updates the similarity matrix, and simultaneously achieves interpretable predictions. Theoretical guarantees are provided for S$^2$MAM, including the computing convergence and the statistical generalization bound. Experimental assessments across 4 synthetic and 12 real-world datasets, with varying levels and categories of corruption, validate the robustness and interpretability of the proposed approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes S²MAM, a semi-supervised meta additive model that employs a bilevel optimization scheme to automatically identify informative variables, update the similarity matrix for manifold regularization, and produce interpretable predictions. It claims theoretical guarantees on computational convergence of the bilevel scheme and a statistical generalization bound, with experimental validation on 4 synthetic and 12 real-world datasets under varying corruption levels and types.
Significance. If the generalization bound can be rigorously established despite the data-dependent Laplacian induced by the outer loop, the work would meaningfully extend manifold-regularized semi-supervised learning by integrating variable selection and meta-optimization for robustness and interpretability. The experimental design across corrupted datasets provides useful evidence of practical performance, but the overall significance is limited by the need to verify that the adaptive regularizer does not invalidate the claimed bound.
major comments (2)
- [§4] §4 (Theoretical Guarantees), Theorem on statistical generalization bound: the bound is stated for the adaptive graph Laplacian produced by the bilevel update of the similarity matrix. Classical manifold regularization bounds rely on a fixed Laplacian whose spectral properties follow from the Riemannian manifold assumption on the marginal support. The proof must explicitly control the Lipschitz constant of the inner solution map with respect to the learned variables (or show that the adaptive Laplacian stays close to a fixed one in high probability); without this step the bound does not follow from existing results and the central theoretical claim is unsupported.
- [§3.2] §3.2 (Bilevel Optimization Formulation), convergence analysis: the computing convergence guarantee assumes the inner additive-model problem yields a sufficiently smooth and strongly convex solution map. Once variable selection and the meta-objective are introduced, strong convexity is no longer automatic. The manuscript must state the precise conditions (e.g., restricted strong convexity parameter, smoothness modulus) under which the outer-loop iteration converges and verify that they hold for the proposed S²MAM objective.
minor comments (2)
- [Table 1] Table 1 and §5.1: the reported performance metrics under different corruption categories would benefit from explicit standard deviations across the 10 random splits to allow assessment of statistical significance.
- [Notation] Notation section: the symbol for the updated similarity matrix is introduced in the bilevel formulation but reused without redefinition in the generalization proof; add a short notational table for clarity.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive and detailed comments. We address each major comment point by point below, clarifying our approach and outlining the revisions that will be made to strengthen the theoretical sections.
read point-by-point responses
-
Referee: [§4] §4 (Theoretical Guarantees), Theorem on statistical generalization bound: the bound is stated for the adaptive graph Laplacian produced by the bilevel update of the similarity matrix. Classical manifold regularization bounds rely on a fixed Laplacian whose spectral properties follow from the Riemannian manifold assumption on the marginal support. The proof must explicitly control the Lipschitz constant of the inner solution map with respect to the learned variables (or show that the adaptive Laplacian stays close to a fixed one in high probability); without this step the bound does not follow from existing results and the central theoretical claim is unsupported.
Authors: We appreciate this observation on the need for rigorous control in the proof. In the revised manuscript, we will augment the proof of the statistical generalization bound in Section 4 by explicitly deriving a bound on the Lipschitz constant of the inner solution map with respect to the learned variables. We will further show that, under standard assumptions on the variable selection process and the manifold structure, the adaptive Laplacian remains close to a fixed Laplacian (corresponding to the true marginal support) with high probability. This step will ensure the bound extends existing manifold regularization results to the data-dependent case. revision: yes
-
Referee: [§3.2] §3.2 (Bilevel Optimization Formulation), convergence analysis: the computing convergence guarantee assumes the inner additive-model problem yields a sufficiently smooth and strongly convex solution map. Once variable selection and the meta-objective are introduced, strong convexity is no longer automatic. The manuscript must state the precise conditions (e.g., restricted strong convexity parameter, smoothness modulus) under which the outer-loop iteration converges and verify that they hold for the proposed S²MAM objective.
Authors: We thank the referee for pointing out this requirement in the convergence analysis. In the revised version, we will explicitly state the precise conditions, including the restricted strong convexity parameter and smoothness modulus, under which the outer-loop iteration converges. We will also verify that these conditions hold for the S²MAM objective through appropriate choices of regularization parameters and structural assumptions on the additive model components, ensuring the bilevel scheme remains well-defined. revision: yes
Circularity Check
No circularity: derivation remains independent of its fitted outputs
full rationale
The paper introduces S2MAM as a bilevel optimization procedure that jointly performs variable selection, similarity-matrix adaptation, and additive-model fitting under a manifold-regularization objective. It states that convergence of the bilevel scheme and a statistical generalization bound are proved. No quoted equation or derivation step reduces the claimed bound or convergence result to a tautological re-expression of the learned similarity matrix or selected variables; the proofs are presented as following from the optimization structure and the Riemannian-manifold assumption on the marginal support. The adaptive Laplacian is an explicit part of the algorithm rather than a hidden re-use of the target quantity, and no self-citation is invoked as the sole justification for the uniqueness or validity of the bound. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The support of the unknown marginal distribution has the geometric structure of a Riemannian manifold.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.