A Komi-Yazva--Russian Parallel Corpus and Evaluation Protocol for Zero- and Few-Shot LLM Translation
Pith reviewed 2026-06-28 01:20 UTC · model grok-4.3
The pith
LLMs produce non-trivial Komi-Yazva to Russian translations, with retrieval-based few-shot prompting improving over zero-shot but showing limited further gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present the first Komi-Yazva--Russian parallel corpus together with an explicit evaluation protocol for studying LLM translation in an endangered, extremely low-resource setting. The dataset contains 457 aligned sentence pairs from 74 narrative texts and is accompanied by documented provenance, sentence-level alignment, and story identifiers that enable leakage-aware evaluation. We use this setup to compare modern large language models on Komi-Yazva-to-Russian translation under severe parallel-data scarcity in zero-shot and retrieval-based few-shot regimes. Across models, LLMs produce non-trivial translations, but performance varies strongly by model family and prompting regime. Retrieval
What carries the argument
The Komi-Yazva--Russian parallel corpus of 457 sentence pairs with story identifiers that supports story-level cross-validation and deterministic retrieval for leakage-aware zero- and few-shot evaluation.
If this is right
- Retrieval-based few-shot prompting produces higher-quality translations than zero-shot prompting for Komi-Yazva to Russian.
- Gains from additional retrieved examples plateau after a small context size.
- Evaluative rankings of models change depending on the choice of reference-based versus judge-based metrics and on failure-handling rules.
- The corpus and protocol together constitute a reproducible testbed for translation systems in other endangered-language settings.
Where Pith is reading between the lines
- The same story-level protocol could be replicated for other Uralic or similarly documented endangered languages to enable comparable LLM benchmarks.
- The observed sensitivity to metric choice and failure handling points to a need for standardized failure taxonomies in low-resource machine translation evaluation.
- The corpus allows direct testing of whether newer model families or alternative retrieval strategies close the performance gap beyond the small-context regime reported here.
Load-bearing premise
The 457 sentence pairs from 74 texts with their documented provenance and story identifiers are sufficient to support leakage-aware evaluation without material alignment errors or unrepresentative sampling that would invalidate comparisons across prompting regimes.
What would settle it
A demonstration that many sentence pairs contain alignment errors or that story identifiers do not prevent leakage during cross-validation would invalidate the reported differences between zero-shot and few-shot regimes.
Figures

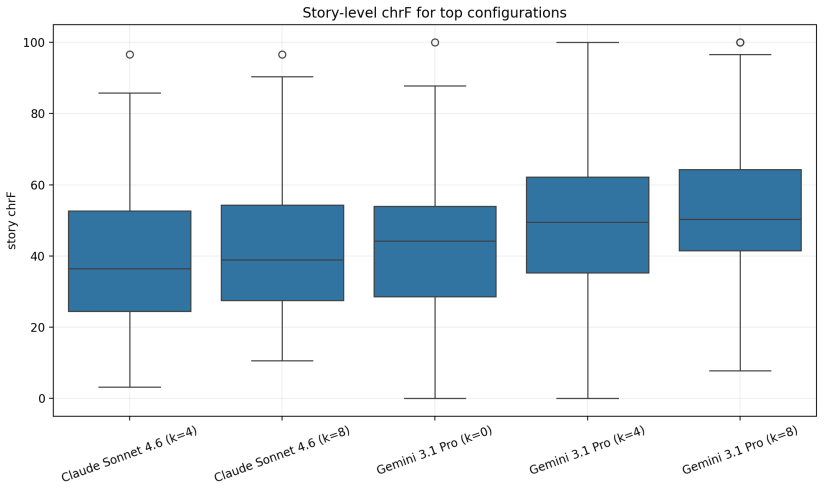
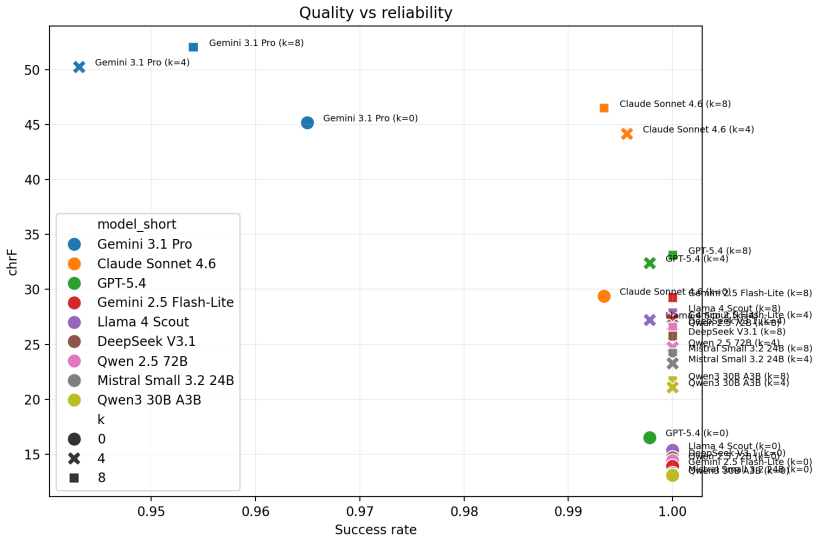
read the original abstract
We present the first Komi-Yazva--Russian parallel corpus together with an explicit evaluation protocol for studying LLM translation in an endangered, extremely low-resource setting. The dataset contains 457 aligned sentence pairs from 74 narrative texts and is accompanied by documented provenance, sentence-level alignment, and story identifiers that enable leakage-aware evaluation. We use this setup to compare modern large language models on Komi-Yazva-to-Russian translation under severe parallel-data scarcity in zero-shot and retrieval-based few-shot regimes. The protocol includes story-level cross-validation, deterministic retrieval for few-shot prompting, strict validation of generated outputs, complementary reference-based and judge-based metrics, and story-level uncertainty estimates. Across models, LLMs produce non-trivial translations, but performance varies strongly by model family and prompting regime. Retrieval-based few-shot prompting consistently improves over zero-shot prompting, while gains beyond a small retrieved context remain limited. The results show that evaluative conclusions in this setting depend materially on metric choice and failure handling, so the paper frames the corpus as both a dataset contribution and a reproducible evaluation testbed for endangered-language machine translation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the first Komi-Yazva--Russian parallel corpus, consisting of 457 aligned sentence pairs drawn from 74 narrative texts with documented provenance and story identifiers. It defines a leakage-aware evaluation protocol using story-level cross-validation and deterministic retrieval, then applies this protocol to compare LLMs on Komi-Yazva-to-Russian translation in zero-shot and retrieval-based few-shot regimes. The central empirical observations are that LLMs produce non-trivial translations whose performance varies strongly by model family and prompting regime, that few-shot retrieval improves over zero-shot with limited further gains beyond small contexts, and that evaluative conclusions depend materially on metric choice and failure handling.
Significance. If the alignment quality and sampling assumptions hold, the work supplies a reproducible testbed and new resource for extremely low-resource endangered-language MT. The explicit leakage-aware design, complementary reference- and judge-based metrics, and story-level uncertainty estimates are concrete strengths that address common pitfalls in few-shot LLM evaluation. The framing as both dataset and protocol contribution, together with the observation that metric choice affects conclusions, provides a useful methodological reference point for future low-resource translation studies.
major comments (2)
- [Dataset construction and evaluation protocol] The evaluation protocol (described in the abstract and §4) rests on accurate sentence alignments and representative sampling from the 74 narratives, yet no quantitative alignment-error rate, inter-annotator agreement, or diversity statistics are reported. Without these, it is impossible to rule out that observed differences between zero-shot and few-shot regimes are artifacts of alignment noise or story-specific leakage rather than genuine prompting effects.
- [Results and discussion] The claim that 'evaluative conclusions depend materially on metric choice and failure handling' is load-bearing for the paper's framing as a testbed, but the manuscript supplies no error analysis or breakdown of failure modes (e.g., by story or by model) that would allow readers to assess how sensitive the reported trends are to specific metric implementations.
minor comments (1)
- [Evaluation protocol] The abstract states that the protocol includes 'strict validation of generated outputs' but does not define the exact validation criteria; a short explicit list in the protocol section would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of dataset quality and analysis depth. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: The evaluation protocol (described in the abstract and §4) rests on accurate sentence alignments and representative sampling from the 74 narratives, yet no quantitative alignment-error rate, inter-annotator agreement, or diversity statistics are reported. Without these, it is impossible to rule out that observed differences between zero-shot and few-shot regimes are artifacts of alignment noise or story-specific leakage rather than genuine prompting effects.
Authors: We agree that explicit quantitative measures of alignment quality and sampling diversity would strengthen confidence in the protocol. The alignments were performed manually with documented provenance from the source narratives; however, we did not compute formal inter-annotator agreement or alignment-error rates in the original submission. In the revised manuscript we will add a dedicated subsection on corpus construction that reports (i) the alignment procedure, (ii) any available spot-check error estimates, and (iii) basic diversity statistics (sentence-length distribution, narrative-topic coverage, and story-size histogram). These additions will allow readers to assess potential noise or leakage more directly. revision: yes
-
Referee: The claim that 'evaluative conclusions depend materially on metric choice and failure handling' is load-bearing for the paper's framing as a testbed, but the manuscript supplies no error analysis or breakdown of failure modes (e.g., by story or by model) that would allow readers to assess how sensitive the reported trends are to specific metric implementations.
Authors: We accept that the current manuscript lacks a systematic error analysis to substantiate the metric-sensitivity claim. In the revision we will insert a new subsection (likely in §5 or an appendix) that provides (i) qualitative examples of common failure modes, (ii) quantitative breakdowns of error types by model and by story, and (iii) a sensitivity table showing how key trends change under alternative failure-handling rules. This will make the methodological point more concrete and reproducible. revision: yes
Circularity Check
Empirical corpus creation and model evaluation shows no circularity
full rationale
The paper constructs a new parallel corpus of 457 sentence pairs from 74 texts and applies it to direct empirical comparisons of LLM translation performance under zero-shot and few-shot regimes. No derivations, equations, fitted parameters, or predictions are present; claims rest on measured outputs from external models using documented alignments and story-level splits. No self-citations are load-bearing for any result, and the evaluation protocol is self-contained against the collected data without reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Machine Translation into Low-resource Language Varieties , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) , month = aug, year =. doi:10.18653/v1/2021.acl-short.16 , pages =
-
[9]
Findings of the Association for Computational Linguistics: ACL 2023 , month = jul, year =
In-Context Examples Selection for Machine Translation , author =. Findings of the Association for Computational Linguistics: ACL 2023 , month = jul, year =. doi:10.18653/v1/2023.findings-acl.156 , pages =
-
[10]
Findings of the Association for Computational Linguistics: EMNLP 2023 , month = dec, year =
Steering Large Language Models for Machine Translation with Finetuning and In-Context Learning , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , month = dec, year =. doi:10.18653/v1/2023.findings-emnlp.606 , pages =
-
[11]
Translating into an Unwritten Low-Resource Language Pair with
Elsner, Micha and Needle, Jordan , editor =. Translating into an Unwritten Low-Resource Language Pair with. Proceedings of the 20th SIGMORPHON workshop on Computational Research in Phonetics, Phonology, and Morphology , month = jul, year =. doi:10.18653/v1/2023.sigmorphon-1.2 , pages =
-
[12]
Machine Translation with Large Language Models: Prompting, Few-shot Learning, and Fine-tuning with
Zhang, Biao and Haddow, Barry and Birch, Alexandra , editor =. Machine Translation with Large Language Models: Prompting, Few-shot Learning, and Fine-tuning with. Proceedings of the Eighth Conference on Machine Translation , month = dec, year =. doi:10.18653/v1/2023.wmt-1.43 , pages =
-
[13]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , month = may, year =
Neural machine translation in low-resource language pairs using synthetic pivoting , author =. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , month = may, year =
2024
-
[14]
Understanding In-Context Machine Translation for Low-Resource Languages: A Case Study on
Pei, Renhao and Liu, Yihong and Lin, Peiqin and Yvon, Fran. Understanding In-Context Machine Translation for Low-Resource Languages: A Case Study on. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = jul, year =. doi:10.18653/v1/2025.acl-long.429 , pages =
-
[15]
Findings of the Association for Computational Linguistics: NAACL 2025 , month = apr, year =
In-Context Example Selection via Similarity Search Improves Low-Resource Machine Translation , author =. Findings of the Association for Computational Linguistics: NAACL 2025 , month = apr, year =. doi:10.18653/v1/2025.findings-naacl.68 , pages =
-
[16]
Findings of the Association for Computational Linguistics: EMNLP 2025 , month = nov, year =
Compositional Translation from Large Language Models for Language Pairs with one Low-Resource Language , author =. Findings of the Association for Computational Linguistics: EMNLP 2025 , month = nov, year =. doi:10.18653/v1/2025.findings-emnlp.1216 , pages =
-
[17]
How Good Are
Hendy, Amr and Abdelrehim, Mohamed and Sharaf, Ahmed and Raunak, Vikas and Gabr, Mohamed and Matsushita, Hideki and Kim, Young Jin and Afify, Mohamed and Awadalla, Hany , journal =. How Good Are. 2023 , doi =
2023
-
[18]
arXiv preprint arXiv:2302.07856 , year =
Dictionary-based Phrase-level Prompting of Large Language Models for Machine Translation , author =. arXiv preprint arXiv:2302.07856 , year =. doi:10.48550/arXiv.2302.07856 , url =
-
[19]
No Language Left Behind: Scaling Human-Centered Machine Translation
No Language Left Behind: Scaling Human-Centered Machine Translation , author =. arXiv preprint arXiv:2207.04672 , year =. doi:10.48550/arXiv.2207.04672 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2207.04672
-
[20]
arXiv preprint arXiv:2412.20584 , year =
Towards Neural No-Resource Language Translation: A Comparative Evaluation of Approaches , author =. arXiv preprint arXiv:2412.20584 , year =. doi:10.48550/arXiv.2412.20584 , url =
-
[21]
Low-Resource Machine Translation through Retrieval-Augmented
Merx, Raphael and Mahmudi, Aso and Langford, Katrina and Ara. Low-Resource Machine Translation through Retrieval-Augmented. arXiv preprint arXiv:2404.04809 , year =. doi:10.48550/arXiv.2404.04809 , url =
-
[22]
arXiv preprint arXiv:2407.13343 , year =
Learning-From-Mistakes Prompting for Indigenous Language Translation , author =. arXiv preprint arXiv:2407.13343 , year =. doi:10.48550/arXiv.2407.13343 , url =
-
[23]
arXiv preprint arXiv:2402.19167 , year =
Teaching Large Language Models an Unseen Language on the Fly , author =. arXiv preprint arXiv:2402.19167 , year =. doi:10.48550/arXiv.2402.19167 , url =
-
[24]
Compensating for Data with Reasoning: Low-Resource Machine Translation with
Frontull, Samuel and Str. Compensating for Data with Reasoning: Low-Resource Machine Translation with. arXiv preprint arXiv:2505.22293 , year =. doi:10.48550/arXiv.2505.22293 , url =
-
[25]
Prompt, Translate, Fine-Tune, Re-Initialize, or Instruction-Tune? Adapting
Toukmaji, Christopher and Flanigan, Jeffrey , journal =. Prompt, Translate, Fine-Tune, Re-Initialize, or Instruction-Tune? Adapting. 2025 , doi =
2025
-
[26]
and Allu, Niyathi and Garg, Rohin and Fartale, Harshwardhan and Chan, Dun Li , booktitle =
Ramasethu, A. and Allu, Niyathi and Garg, Rohin and Fartale, Harshwardhan and Chan, Dun Li , booktitle =. Can Linguistically Related Languages Guide. 2026 , doi =
2026
-
[27]
On the questions in developing computational infrastructure for
Rueter, Jack and Partanen, Niko and Ponomareva, Lilia , booktitle =. On the questions in developing computational infrastructure for. 2020 , doi =
2020
-
[28]
Gerstenberger, Ciprian and Partanen, Niko and Rie. Instant annotations in. Proceedings of the 2nd Workshop on the Use of Computational Methods in the Study of Endangered Languages , year =. doi:10.18653/v1/W17-0109 , url =
-
[29]
Partanen, Niko and Blokland, Rogier and Lim, Kyungtae and Poibeau, Thierry and Rie. The First. Proceedings of the Second Workshop on Universal Dependencies (UDW 2018) , year =. doi:10.18653/v1/W18-6015 , url =
-
[30]
Towards a Speech Recognizer for
Hjortnaes, Nils and Partanen, Niko and Rie. Towards a Speech Recognizer for. Proceedings of the Sixth International Workshop on Computational Linguistics of Uralic Languages , year =. doi:10.18653/v1/2020.iwclul-1.5 , url =
-
[31]
Tereshchenko, Yehor and H. Evaluating Open. arXiv preprint arXiv:2512.16287 , year =. doi:10.48550/arXiv.2512.16287 , url =
-
[32]
Lytkin, V. I. , title =. 1961 , publisher =
1961
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.