SimWorlds: A Multi-Agent System for Dynamic 3D Scene Creation
Pith reviewed 2026-07-03 13:56 UTC · model grok-4.3
The pith
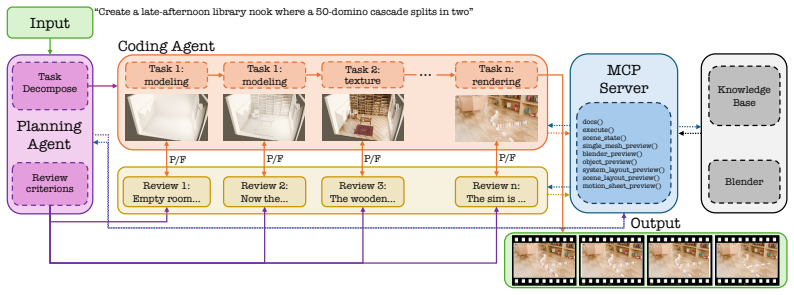
SimWorlds produces dynamic editable 4D scenes from text via a multi-agent planner-coder-reviewer workflow in Blender.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SimWorlds is a multi-agent framework that produces dynamic, editable 4D scenes from text, with Blender-specific procedural knowledge, a planner-coder-reviewer workflow driving a fixed ordered sequence of construction stages, a layered scene protocol enforced by a deterministic verifier, and a runtime-state inspection tool suite that catches mechanism failures the rendered image cannot reveal.
What carries the argument
Planner-coder-reviewer workflow that drives a fixed ordered sequence of construction stages, combined with a layered scene protocol and runtime-state inspection tools.
If this is right
- Generated scenes serve directly as editable training data for video generation models.
- Physical consistency can be verified without relying solely on rendered video frames.
- The same workflow structure extends to other procedural modeling environments beyond Blender.
- Benchmarks like 4DBuildBench become necessary to separate visual appearance from motion correctness.
Where Pith is reading between the lines
- Integration with reinforcement-learning environments could supply infinite varied physics trajectories for policy training.
- The deterministic verifier layer could be reused as a general filter for any LLM-generated simulation code.
- Extending the construction stages to include sound or material fracture would require only additions to the protocol without changing the agent roles.
Load-bearing premise
The planner-coder-reviewer workflow, deterministic verifier, and runtime inspection tools can reliably coordinate spatial layout, multiple physics solvers, temporal sequencing, camera, and lighting into physically consistent dynamic scenes.
What would settle it
A generated scene that passes all verifier checks and runtime inspections yet shows objects intersecting, incorrect particle trajectories, or timing mismatches when simulated forward from the initial state.
Figures

read the original abstract
LLM agents are increasingly used to translate natural language into 3D scenes in a procedural way, but existing systems focus on static output. Dynamic 4D scenes from text alone, in which liquids flow, particles emit, rigid bodies cascade, and articulated mechanisms move, remain largely unexplored despite their value as editable content and as physics-grounded training data for video generation and embodied AI. Two challenges set the dynamic case apart from static text-to-scene work: an agent must jointly coordinate spatial layout, multiple physics solvers, temporal sequencing, camera, and lighting in a single coherent scene, and verifying motion correctness from rendered video is fundamentally harder than judging a single image. We present SimWorlds: a multi-agent framework that produces dynamic, editable 4D scenes from text, with Blender-specific procedural knowledge, a planner-coder-reviewer workflow driving a fixed ordered sequence of construction stages, a layered scene protocol enforced by a deterministic verifier, and a runtime-state inspection tool suite that catches mechanism failures the rendered image cannot reveal. We also introduce 4DBuildBench, a benchmark for assessing both visual fidelity and physical consistency of the procedural dynamic 3D scenes generated from text prompts. Experiments show that SimWorlds outperforms prior dynamic Blender generation baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SimWorlds, a multi-agent LLM framework that generates dynamic, editable 4D scenes in Blender from text prompts. It incorporates Blender-specific procedural knowledge, a planner-coder-reviewer workflow that follows a fixed ordered sequence of construction stages, a layered scene protocol with a deterministic verifier, and a suite of runtime-state inspection tools to detect failures not visible in rendered video. The work also presents the 4DBuildBench benchmark for evaluating visual fidelity and physical consistency, and reports that SimWorlds outperforms prior dynamic Blender generation baselines.
Significance. If the coordination mechanisms prove reliable, the framework would advance text-to-dynamic-scene generation by addressing the joint challenges of spatial layout, multiple physics solvers, temporal sequencing, camera, and lighting. The introduction of 4DBuildBench as an independent benchmark and the runtime-state inspection tools represent concrete contributions that could support reproducible evaluation and physics-grounded data generation for video models and embodied AI.
major comments (2)
- [Abstract, §3] Abstract and §3 (planner-coder-reviewer workflow): the fixed ordered sequence of construction stages provides no described mechanism for revising an early stage (e.g., initial rigid-body placement) once a later stage reveals an inconsistency with fluid or particle dynamics. This directly bears on the central claim that the system reliably coordinates multiple physics solvers and temporal sequencing, as the verifier can only accept or reject the current stage output.
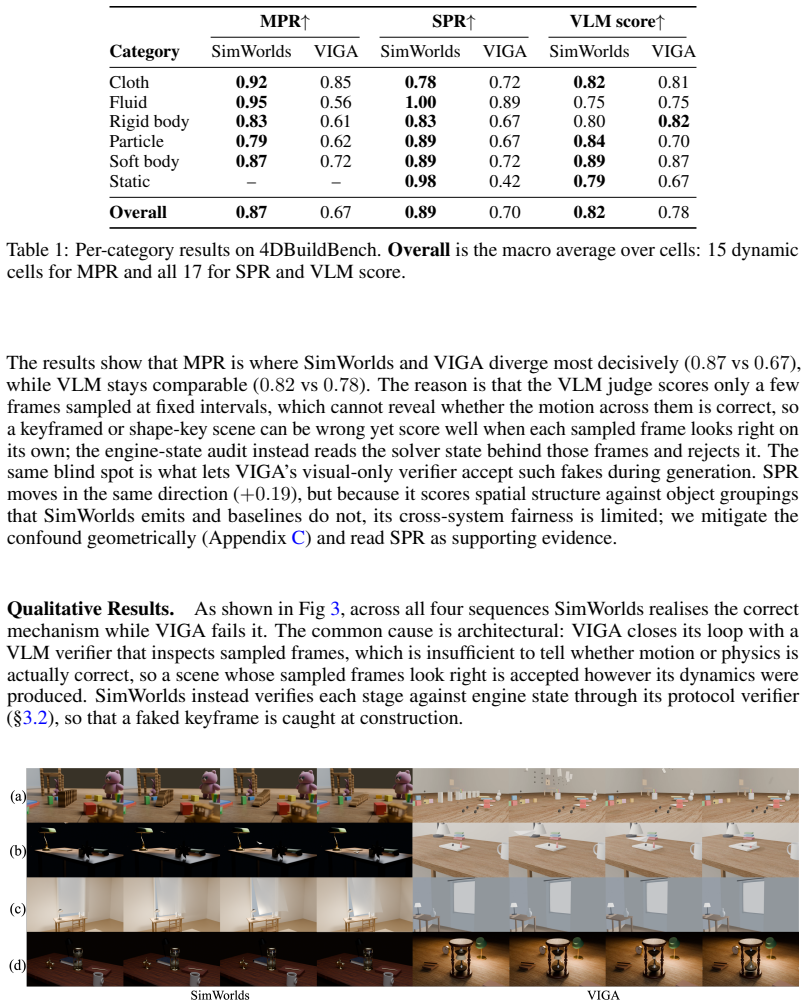
- [§4, 4DBuildBench] §4 (experiments) and 4DBuildBench description: the abstract asserts outperformance on the new benchmark, yet the provided text supplies no quantitative results, error bars, or per-category breakdown of visual fidelity versus physical consistency scores; without these, the claim that the runtime-state tools solve the motion-verification challenge cannot be assessed.
minor comments (2)
- [§3] Notation for the layered scene protocol is introduced without a compact tabular summary of layer dependencies; a small table would improve clarity.
- [Abstract, §4] The benchmark prompt set size and diversity statistics are not stated explicitly in the abstract or early sections.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the workflow design and the presentation of experimental results. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (planner-coder-reviewer workflow): the fixed ordered sequence of construction stages provides no described mechanism for revising an early stage (e.g., initial rigid-body placement) once a later stage reveals an inconsistency with fluid or particle dynamics. This directly bears on the central claim that the system reliably coordinates multiple physics solvers and temporal sequencing, as the verifier can only accept or reject the current stage output.
Authors: The workflow intentionally uses a fixed ordered sequence of stages to enforce systematic construction, with the layered scene protocol and deterministic verifier ensuring consistency checks at each step. The runtime-state inspection tools are designed to surface issues not visible in video renders. We agree, however, that the current description lacks an explicit mechanism for revising decisions from early stages (such as rigid-body placement) when later stages expose inconsistencies with fluid or particle dynamics. In the revision we will add a dedicated paragraph clarifying this design limitation, its impact on the coordination claim, and how the inspection tools partially mitigate propagation of errors; we will also outline a possible extension for limited cross-stage refinement. revision: partial
-
Referee: [§4, 4DBuildBench] §4 (experiments) and 4DBuildBench description: the abstract asserts outperformance on the new benchmark, yet the provided text supplies no quantitative results, error bars, or per-category breakdown of visual fidelity versus physical consistency scores; without these, the claim that the runtime-state tools solve the motion-verification challenge cannot be assessed.
Authors: Section 4 presents quantitative comparisons on 4DBuildBench, but we acknowledge that error bars, per-category breakdowns separating visual fidelity from physical consistency, and explicit linkage to the runtime-state tools are not sufficiently prominent. In the revised manuscript we will add a summary table with these details, include error bars on all reported metrics, and provide a per-category analysis to directly support the abstract claim and demonstrate the contribution of the inspection tools. revision: yes
Circularity Check
No circularity detected in system description or benchmark
full rationale
The paper presents an engineering system (multi-agent planner-coder-reviewer workflow, layered protocol, deterministic verifier, runtime inspection tools) built on external Blender, plus an independently introduced benchmark 4DBuildBench. No equations, fitted parameters, self-definitional claims, or load-bearing self-citations appear in the provided text; performance is asserted via comparison to external baselines rather than internal tautologies. The fixed-sequence design noted by the skeptic is a potential limitation but does not constitute circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DreamFusion: Text-to-3d using 2d diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. DreamFusion: Text-to-3d using 2d diffusion. InICLR, 2023. 2, 3
2023
-
[2]
LRM: Large reconstruction model for single image to 3d
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. LRM: Large reconstruction model for single image to 3d. InICLR, 2024. 3
2024
-
[3]
LGM: Large multi-view Gaussian model for high-resolution 3d content creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. LGM: Large multi-view Gaussian model for high-resolution 3d content creation. InECCV, 2024. 2, 3
2024
-
[4]
Ross, Cordelia Schmid, and Alireza Fathi
Ziniu Hu, Ahmet Iscen, Aashi Jain, Thomas Kipf, Yisong Yue, David A. Ross, Cordelia Schmid, and Alireza Fathi. SceneCraft: An LLM agent for synthesizing 3d scene as Blender code. arXiv:2403.01248, 2024. 2, 3, 6, 7
-
[5]
arXiv preprint arXiv:2310.12945 , year=
Chunyi Sun et al. 3D-GPT: Procedural 3d modeling with large language models. arXiv:2310.12945, 2023. 3
-
[6]
LL3M: Large language 3D modelers.arXiv:2508.08228, 2025
Sining Lu, Guan Chen, Nam Anh Dinh, Itai Lang, Ari Holtzman, and Rana Hanocka. LL3M: Large language 3D modelers.arXiv:2508.08228, 2025. 3, 6, 7
-
[7]
Holodeck: Language guided generation of 3d embodied AI environments
Yue Yang, Fan-Yun Sun, Luca Weihs, Eli VanderBilt, Alvaro Herrasti, Winson Han, Jiajun Wu, Nick Haber, Ranjay Krishna, Lingjie Liu, Chris Callison-Burch, Mark Yatskar, Aniruddha Kembhavi, and Christopher Clark. Holodeck: Language guided generation of 3d embodied AI environments. InCVPR, 2024. 7
2024
-
[8]
Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
Shaofeng Yin, Jiaxin Ge, Zora Zhiruo Wang, Chenyang Wang, Xiuyu Li, Michael J. Black, Trevor Darrell, Angjoo Kanazawa, and Haiwen Feng. VIGA: Vision-as-inverse-graphics agent via interleaved multimodal reasoning.arXiv:2601.11109, 2026. 2, 3, 6, 7, 8, 9, 15, 20
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
BlenderAlchemy: Editing 3d graphics with vision-language models.arXiv:2404.17672, 2024
Ian Huang, Guandao Yang, and Leonidas Guibas. BlenderAlchemy: Editing 3d graphics with vision-language models.arXiv:2404.17672, 2024. 3
-
[10]
Infinite photorealistic worlds using procedural generation
Alexander Raistrick et al. Infinite photorealistic worlds using procedural generation. InCVPR,
-
[11]
ProcTHOR: Large-scale embodied AI using procedural generation
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Kiana Ehsani, Jordi Salvador, Winson Han, Eric Kolve, Aniruddha Kembhavi, and Roozbeh Mottaghi. ProcTHOR: Large-scale embodied AI using procedural generation. InNeurIPS, 2022. 3
2022
-
[12]
AirSim360: A panoramic simulation platform within drone view
Xian Ge, Yuling Pan, Yuhang Zhang, Xiang Li, Weijun Zhang, Dizhe Zhang, Zhaoliang Wan, Xin Lin, Xiangkai Zhang, Juntao Liang, Jason Li, Wenjie Jiang, Bo Du, Ming-Hsuan Yang, and Lu Qi. AirSim360: A panoramic simulation platform within drone view. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[13]
Depth any panoramas: A foundation model for panoramic depth estimation
Xin Lin, Meixi Song, Dizhe Zhang, Wenxuan Lu, Haodong Li, Bo Du, Ming-Hsuan Yang, Truong Nguyen, and Lu Qi. Depth any panoramas: A foundation model for panoramic depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. 3
2026
-
[14]
ATISS: Autoregressive transformers for indoor scene synthesis
Despoina Paschalidou et al. ATISS: Autoregressive transformers for indoor scene synthesis. In NeurIPS, 2021. 3
2021
-
[15]
Chuan Fang et al. Ctrl-Room: Controllable text-to-3d room meshes generation with layout constraints.arXiv:2310.03602, 2023
-
[16]
LayoutGPT: Compositional visual planning and generation with large language models
Weixi Feng, Wanrong Zhu, Tsu-Jui Fu, Varun Jampani, Arjun Akula, Xuehai He, Sugato Basu, Xin Eric Wang, and William Yang Wang. LayoutGPT: Compositional visual planning and generation with large language models. InNeurIPS, 2023
2023
-
[17]
InstructScene: Instruction-driven 3d indoor scene synthesis with semantic graph prior
Chenguo Lin et al. InstructScene: Instruction-driven 3d indoor scene synthesis with semantic graph prior. InICLR, 2024
2024
-
[18]
SceneTeller: Language-to-3d scene generation
Ba¸ sak Melis Öcal et al. SceneTeller: Language-to-3d scene generation. InECCV, 2024. 10
2024
-
[19]
DiffuScene: Denoising diffusion models for generative indoor scene synthesis
Jiapeng Tang et al. DiffuScene: Denoising diffusion models for generative indoor scene synthesis. InCVPR, 2024. 3
2024
-
[20]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InCVPR, 2023. 3
2023
-
[21]
Objaverse-XL: A universe of 10M+ 3d objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, et al. Objaverse-XL: A universe of 10M+ 3d objects. InNeurIPS, 2023. 3
2023
-
[22]
BlenderGym: Bench- marking foundational model systems for graphics editing
Yunqi Gu, Ian Huang, Jihyeon Je, Guandao Yang, and Leonidas Guibas. BlenderGym: Bench- marking foundational model systems for graphics editing. InCVPR, 2025. Highlight. 3, 7
2025
-
[23]
Magic3D: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3D: High-resolution text-to-3d content creation. InCVPR, 2023. 3
2023
-
[24]
Fantasia3D: Disentangling geometry and appearance for high-quality text-to-3d content creation
Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. Fantasia3D: Disentangling geometry and appearance for high-quality text-to-3d content creation. InICCV, 2023
2023
-
[25]
Pro- lificDreamer: High-fidelity and diverse text-to-3d generation with variational score distillation
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Pro- lificDreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. InNeurIPS, 2023. 3
2023
-
[26]
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, and Ying Shan. In- stantMesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruc- tion models.arXiv:2404.07191, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
3d Gaussian Splatting for real-time radiance field rendering
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d Gaussian Splatting for real-time radiance field rendering. InSIGGRAPH, 2023
2023
-
[28]
DreamGaussian: Generative Gaussian Splatting for efficient 3d content creation
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. DreamGaussian: Generative Gaussian Splatting for efficient 3d content creation. InICLR, 2024
2024
-
[29]
GaussianDreamer: Fast generation from text to 3d Gaussians by bridging 2d and 3d diffusion models
Taoran Yi, Jiemin Fang, Junjie Wang, Guanjun Wu, Lingxi Xie, Xiaopeng Zhang, Wenyu Liu, Qi Tian, and Xinggang Wang. GaussianDreamer: Fast generation from text to 3d Gaussians by bridging 2d and 3d diffusion models. InCVPR, 2024
2024
-
[30]
Text-to-3d using Gaussian Splatting
Zilong Chen, Feng Wang, Yikai Wang, and Huaping Liu. Text-to-3d using Gaussian Splatting. InCVPR, 2024
2024
-
[31]
GraphDreamer: Compositional 3d scene synthesis from scene graphs
Gege Gao et al. GraphDreamer: Compositional 3d scene synthesis from scene graphs. InCVPR,
-
[32]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InICCV, 2023. 3
2023
-
[33]
MVDream: Multi-view diffusion for 3d generation
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. MVDream: Multi-view diffusion for 3d generation. InICLR, 2024
2024
-
[34]
Wonder3D: Single image to 3d using cross-domain diffusion
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, et al. Wonder3D: Single image to 3d using cross-domain diffusion. InCVPR, 2024. 3
2024
-
[35]
Set-the-scene: Global-local training for generating controllable NeRF scenes
Dana Cohen-Bar et al. Set-the-scene: Global-local training for generating controllable NeRF scenes. InICCV, 2023. 3
2023
-
[36]
SceneWiz3D: Towards text-guided 3d scene composition
Qihang Zhang et al. SceneWiz3D: Towards text-guided 3d scene composition. InCVPR, 2024
2024
-
[37]
Text2Room: Extracting textured 3d meshes from 2d text-to-image models
Lukas Höllein et al. Text2Room: Extracting textured 3d meshes from 2d text-to-image models. InICCV, 2023
2023
-
[38]
SceneScape: Text-driven consistent scene generation
Rafail Fridman et al. SceneScape: Text-driven consistent scene generation. InNeurIPS, 2023. 11
2023
-
[39]
GALA3D: Towards text-to-3d complex scene generation via layout-guided generative Gaussian Splatting
Xiaoyu Zhou et al. GALA3D: Towards text-to-3d complex scene generation via layout-guided generative Gaussian Splatting. InICML, 2024
2024
-
[40]
Director3D: Real-world camera trajectory and 3d scene generation from text
Xinyang Li et al. Director3D: Real-world camera trajectory and 3d scene generation from text. InNeurIPS, 2024. 3
2024
-
[41]
Text-to-4d dynamic scene generation
Uriel Singer, Shelly Sheynin, Adam Polyak, Oron Ashual, Iurii Makarov, Filippos Kokkinos, Naman Goyal, Andrea Vedaldi, Devi Parikh, Justin Johnson, and Yaniv Taigman. Text-to-4d dynamic scene generation. InICML, 2023. 3
2023
-
[42]
4D-fy: Text-to-4d generation using hybrid score distillation sampling
Sherwin Bahmani et al. 4D-fy: Text-to-4d generation using hybrid score distillation sampling. InCVPR, 2024
2024
-
[43]
Dreamgaussian4d: Generative 4d gaussian splatting,
Jiawei Ren et al. DreamGaussian4D: Generative 4d Gaussian Splatting.arXiv:2312.17142, 2024
-
[44]
Comp4D: LLM-guided compositional 4d scene generation.arXiv:2403.16993, 2024
Dejia Xu et al. Comp4D: LLM-guided compositional 4d scene generation.arXiv:2403.16993, 2024
-
[45]
L4GM: Large 4d Gaussian reconstruction model
Jiawei Ren et al. L4GM: Large 4d Gaussian reconstruction model. InNeurIPS, 2024
2024
-
[46]
TC4D: Trajectory-conditioned text-to-4d generation
Sherwin Bahmani et al. TC4D: Trajectory-conditioned text-to-4d generation. InECCV, 2024
2024
-
[47]
Diffusion4D: Fast spatial-temporal consistent 4d generation via video diffusion models
Hanwen Liang et al. Diffusion4D: Fast spatial-temporal consistent 4d generation via video diffusion models. InECCV, 2024
2024
-
[48]
Yiming Xie et al. SV4D: Dynamic 3d content generation with multi-frame and multi-view consistency.arXiv:2407.17470, 2024
-
[49]
Xiaoyuan Wang, Yizhou Zhao, Botao Ye, Xiaojun Shan, Weijie Lyu, Lu Qi, Kelvin C. K. Chan, Yinxiao Li, and Ming-Hsuan Yang. HoliGS: Holistic gaussian splatting for embodied view synthesis. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. 3
2025
-
[50]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022. 3
2022
-
[51]
Video diffusion models
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. InNeurIPS, 2022
2022
-
[52]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
Make-a-video: Text-to-video generation without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data. InICLR, 2023
2023
-
[54]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, et al. Video generation models as world simulators
-
[55]
OpenAI Technical Report
-
[56]
OmniRoam: World wandering via long-horizon panoramic video generation
Yuheng Liu, Xin Lin, Xinke Li, Baihan Yang, Chen Wang, Kalyan Sunkavalli, Yannick Hold- Geoffroy, Hao Tan, Kai Zhang, Xiaohui Xie, Zifan Shi, and Yiwei Hu. OmniRoam: World wandering via long-horizon panoramic video generation. InACM SIGGRAPH, 2026
2026
-
[57]
PanoWorld: Towards Spatial Supersensing in 360$^\circ$ Panorama World
Changpeng Wang, Xin Lin, Junhan Liu, Yuheng Liu, Zhen Wang, Donglian Qi, Yunfeng Yan, and Xi Chen. PanoWorld: Towards spatial supersensing in 360◦ panorama world.arXiv preprint arXiv:2605.13169, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
PhysDreamer: Physics-based interaction with 3d objects via video generation.arXiv:2404.13026, 2024
Tianyuan Zhang et al. PhysDreamer: Physics-based interaction with 3d objects via video generation.arXiv:2404.13026, 2024. 3
-
[59]
PhysGaussian: Physics-integrated 3d Gaussians for generative dynamics
Tianyi Xie et al. PhysGaussian: Physics-integrated 3d Gaussians for generative dynamics. In CVPR, 2024. 3 12
2024
-
[60]
Jeni, Min Xu, and Yizhou Zhao
Chunjiang Liu, Xiaoyuan Wang, Qingran Lin, Albert Xiao, Haoyu Chen, Shizheng Wen, Hao Zhang, Lu Qi, Ming-Hsuan Yang, László A. Jeni, Min Xu, and Yizhou Zhao. MOSIV: Multi-object system identification from videos. InInternational Conference on Learning Representations (ICLR), 2026. 3
2026
-
[61]
MASIV: Toward material-agnostic system identification from videos
Yizhou Zhao, Haoyu Chen, Chunjiang Liu, Zhenyang Li, Charles Herrmann, Junhwa Hur, Yinxiao Li, Ming-Hsuan Yang, Bhiksha Raj, and Min Xu. MASIV: Toward material-agnostic system identification from videos. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 3
2025
-
[62]
Kubric: A scalable dataset generator
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J Fleet, Dan Gnanapragasam, Florian Golemo, Charles Herrmann, et al. Kubric: A scalable dataset generator. InCVPR, 2022. 3
2022
-
[63]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InICLR, 2023. 3
2023
-
[64]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InNeurIPS, 2023. 3
2023
-
[65]
Self-refine: Iterative refinement with self-feedback
Aman Madaan et al. Self-refine: Iterative refinement with self-feedback. InNeurIPS, 2023. 3
2023
-
[66]
Large language models cannot self-correct reasoning yet
Jie Huang et al. Large language models cannot self-correct reasoning yet. InICLR, 2024. 3
2024
-
[67]
V oyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. InNeurIPS, 2023. 3
2023
-
[68]
Toolformer: Language models can teach themselves to use tools
Timo Schick et al. Toolformer: Language models can teach themselves to use tools. InNeurIPS,
-
[69]
CRITIC: Large language models can self-correct with tool-interactive critiquing
Zhibin Gou et al. CRITIC: Large language models can self-correct with tool-interactive critiquing. InICLR, 2024. 3
2024
-
[70]
Executable code actions elicit better LLM agents
Xingyao Wang et al. Executable code actions elicit better LLM agents. InICML, 2024. 3
2024
-
[71]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu et al. AutoGen: Enabling next-gen LLM applications via multi-agent conversation. arXiv:2308.08155, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[72]
MetaGPT: Meta programming for a multi-agent collaborative framework
Sirui Hong et al. MetaGPT: Meta programming for a multi-agent collaborative framework. In ICLR, 2024. 3
2024
-
[73]
ChatDev: Communicative agents for software development
Chen Qian et al. ChatDev: Communicative agents for software development. InACL, 2024. 3
2024
-
[74]
Effective context engineering for AI agents, 2025
Anthropic. Effective context engineering for AI agents, 2025. URLhttps://www.anthropic. com/engineering/effective-context-engineering-for-ai-agents. 3
2025
-
[75]
A Survey of Context Engineering for Large Language Models
Lingrui Mei, Jiayu Yao, et al. A survey of context engineering for large language models. arXiv:2507.13334, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Writing tools for agents, 2025
Anthropic. Writing tools for agents, 2025. URL https://www.anthropic.com/ engineering/writing-tools-for-agents. 3
2025
-
[77]
LLM powered autonomous agents, 2023
Lilian Weng. LLM powered autonomous agents, 2023. URL https://lilianweng.github. io/posts/2023-06-23-agent/. lilianweng.github.io. 3
2023
-
[78]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph C O’Brien, Carrie J Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InUIST,
-
[79]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and chatbot arena. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2023. 7 13
2023
-
[80]
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, and Noah A. Smith. TIFA: Accurate and interpretable text-to-image faithfulness evaluation with question answering. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.