Semantic and Visual Evidence for Efficient Long-Video Reasoning: A Solution for the HD-EPIC VQA Challenge
Pith reviewed 2026-06-29 08:24 UTC · model grok-4.3
The pith
Long-video reasoning succeeds when MLLMs retrieve and combine semantic procedural evidence with object-centric visual evidence on demand.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
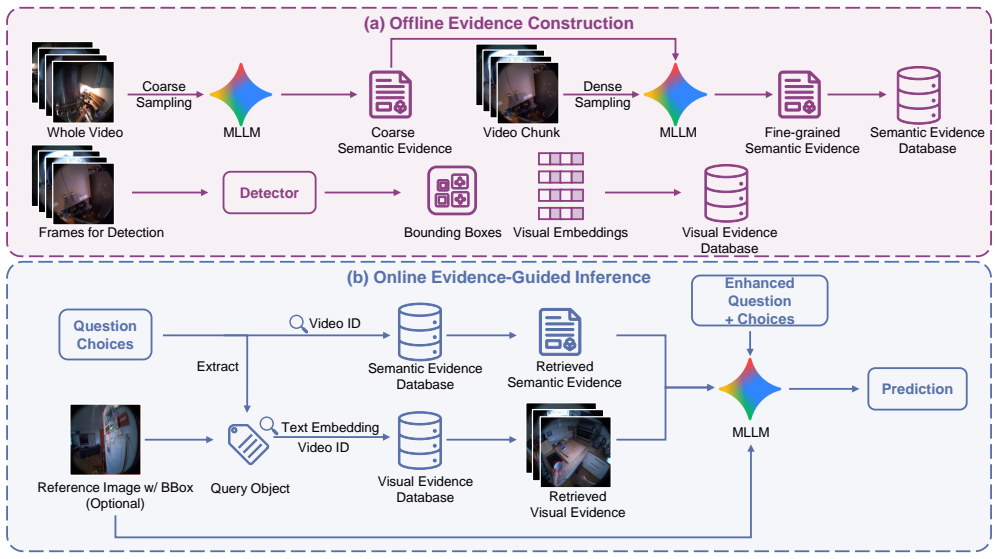
The authors establish that long-video reasoning in MLLMs can be reframed as query-conditioned retrieval and integration of two complementary evidence sources: semantic evidence that encodes global procedural structure through a coarse-to-fine pipeline, and object-centric visual evidence that preserves fine-grained grounding through bounding boxes and embeddings, yielding competitive performance across HD-EPIC-VQA task categories.
What carries the argument
Query-conditioned evidence retrieval and integration process that dynamically selects and merges semantic evidence (coarse-to-fine procedural structure) and visual evidence (bounding-box embeddings).
If this is right
- Explicit separation of semantic and visual evidence enables competitive results on diverse long egocentric VQA tasks.
- Dynamic, query-driven selection reduces the impact of context-length limits in current MLLMs.
- The same structuring and retrieval steps apply across multiple categories of the HD-EPIC challenge.
- Effective long-video understanding requires both global procedural structure and localized visual detail rather than raw video alone.
Where Pith is reading between the lines
- The same evidence-decoupling pattern could be tested on non-egocentric long videos if extraction pipelines are swapped for domain-appropriate ones.
- By keeping evidence sources explicit, the method may allow easier diagnosis of which part of a video answer fails.
- Efficiency gains may appear when the retrieval step replaces full-video encoding in resource-constrained settings.
Load-bearing premise
The coarse-to-fine semantic pipeline and bounding-box visual embeddings can be chosen and combined on the fly without losing essential grounding or introducing retrieval mistakes.
What would settle it
A direct comparison on HD-EPIC questions that hinge on precise object appearance or exact step order, where the dynamic retrieval version scores lower than an otherwise identical full-context baseline.
Figures

read the original abstract
Understanding long-form egocentric videos remains challenging for multimodal large language models (MLLMs) due to limited context length and insufficient grounding of fine-grained visual details. The recently proposed HD-EPIC benchmark highlights these limitations: even strong long-context models achieve relatively low performance across diverse video question answering tasks. In this paper, we propose a unified framework that decouples long-video reasoning into two complementary forms of evidence: semantic evidence and visual evidence. Semantic evidence captures global procedural structure through a coarse-to-fine extraction pipeline, while object-centric visual evidence preserves fine-grained grounding through bounding boxes and visual embeddings. During inference, we formulate reasoning as a query-conditioned evidence retrieval and integration process, dynamically selecting relevant information from both sources. Our approach achieves competitive performance in the HD-EPIC-VQA Challenge across multiple task categories. More broadly, our results demonstrate that explicitly structuring, retrieving, and integrating semantic and visual evidence is critical for effective long-video understanding with MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a unified framework for long-video egocentric VQA that decouples reasoning into semantic evidence (captured via a coarse-to-fine procedural extraction pipeline) and visual evidence (object-centric bounding boxes with visual embeddings). At inference, query-conditioned retrieval and integration dynamically select from both sources. The central claim is that this explicit structuring yields competitive performance on the HD-EPIC VQA Challenge across task categories, addressing MLLM limitations in context length and fine-grained grounding.
Significance. If the performance claims are substantiated, the work would provide a modular, evidence-structured alternative to end-to-end long-context MLLM processing for video QA. The separation of procedural semantic structure from object-centric visual details aligns with known challenges in egocentric video understanding and could inform retrieval-augmented architectures more broadly.
major comments (1)
- [Abstract] Abstract: the claim that the approach 'achieves competitive performance in the HD-EPIC-VQA Challenge across multiple task categories' is presented without any quantitative results, baseline comparisons, ablation studies, or error analysis. This absence makes the central empirical claim impossible to evaluate against the manuscript's own evidence.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback. We address the major comment below regarding the abstract. The full manuscript contains the empirical details in the experimental sections, but we agree the abstract can be improved for immediate evaluability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the approach 'achieves competitive performance in the HD-EPIC-VQA Challenge across multiple task categories' is presented without any quantitative results, baseline comparisons, ablation studies, or error analysis. This absence makes the central empirical claim impossible to evaluate against the manuscript's own evidence.
Authors: We thank the referee for highlighting this point. The manuscript's Experiments section (Section 4) and associated tables/figures provide the quantitative results across task categories on the HD-EPIC benchmark, direct comparisons to long-context MLLM baselines, ablation studies isolating the contributions of semantic procedural evidence and object-centric visual evidence retrieval, and error analysis. The abstract is written as a high-level summary of these findings. To make the central claim immediately evaluable from the abstract itself, we will revise the abstract to include key performance numbers, baseline comparisons, and a brief mention of the ablations. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a high-level methodological framework for decoupling semantic (coarse-to-fine procedural) and visual (object-centric bounding-box) evidence in long-video VQA, with query-conditioned retrieval and integration at inference. No equations, fitted parameters, or derivations are described in the provided text. The central claim is an empirical performance statement evaluated on the HD-EPIC benchmark rather than a mathematical reduction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatzes are smuggled, and no predictions reduce to inputs by construction. The derivation chain is self-contained as an engineering description without circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, and Lidong Bing. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video- llms.arXiv preprint arXiv:2406.07476, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Wedetect: Fast open- vocabulary object detection as retrieval.arXiv preprint arXiv:2512.12309, 2025
Shenghao Fu, Yukun Su, Fengyun Rao, Jing LYU, Xi- aohua Xie, and Wei-Shi Zheng. Wedetect: Fast open- vocabulary object detection as retrieval.arXiv preprint arXiv:2512.12309, 2025. 3
-
[3]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In CVPR, pages 18995–19012, 2022. 1
2022
-
[4]
Video-chatgpt: Towards detailed video understanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fa- had Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. InPro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024), 2024. 1
2024
-
[5]
Hd-epic: A highly-detailed egocentric video dataset
Toby Perrett, Ahmad Darkhalil, Saptarshi Sinha, Omar Emara, Sam Pollard, Kranti Parida, Kaiting Liu, Prajwal Gatti, Siddhant Bansal, Kevin Flanagan, Jacob Chalk, Zhi- fan Zhu, Rhodri Guerrier, Fahd Abdelazim, Bin Zhu, Da- vide Moltisanti, Michael Wray, Hazel Doughty, and Dima Damen. Hd-epic: A highly-detailed egocentric video dataset. InCVPR, 2025. 1, 2, 4
2025
-
[6]
Agentic very long video understanding, 2026
Aniket Rege, Arka Sadhu, Yuliang Li, Kejie Li, Ramya Kor- lakai Vinayak, Yuning Chai, Yong Jae Lee, and Hyo Jin Kim. Agentic very long video understanding, 2026. 1
2026
-
[7]
Egolife: Towards ego- centric life assistant
Jingkang Yang, Shuai Liu, Hongming Guo, Yuhao Dong, Xi- amengwei Zhang, Sicheng Zhang, Pengyun Wang, Zitang Zhou, Binzhu Xie, Ziyue Wang, et al. Egolife: Towards ego- centric life assistant. InCVPR, 2025. 1
2025
-
[8]
Optimiz- ing multimodal llms for egocentric video understanding: A solution for the hd-epic vqa challenge, 2026
Sicheng Yang, Yukai Huang, Shitong Sun, Weitong Cai, Jiankang Deng, Jifei Song, and Zhensong Zhang. Optimiz- ing multimodal llms for egocentric video understanding: A solution for the hd-epic vqa challenge, 2026. 4
2026
-
[9]
Video instruction tuning with synthetic data, 2024
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Zi- wei Liu, and Chunyuan Li. Video instruction tuning with synthetic data, 2024. 1
2024
-
[10]
Llava-video: Video instruction tuning with synthetic data, 2025
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Zi- wei Liu, and Chunyuan Li. Llava-video: Video instruction tuning with synthetic data, 2025. 4
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.