FuzzPilot: Plateau-Triggered Recipe Validation for Structured Text Fuzzing
Pith reviewed 2026-06-29 20:36 UTC · model grok-4.3
The pith
FuzzPilot tests candidate mutation recipes in short isolated AFL++ campaigns only when coverage plateaus and promotes none of twenty model proposals on cJSON.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
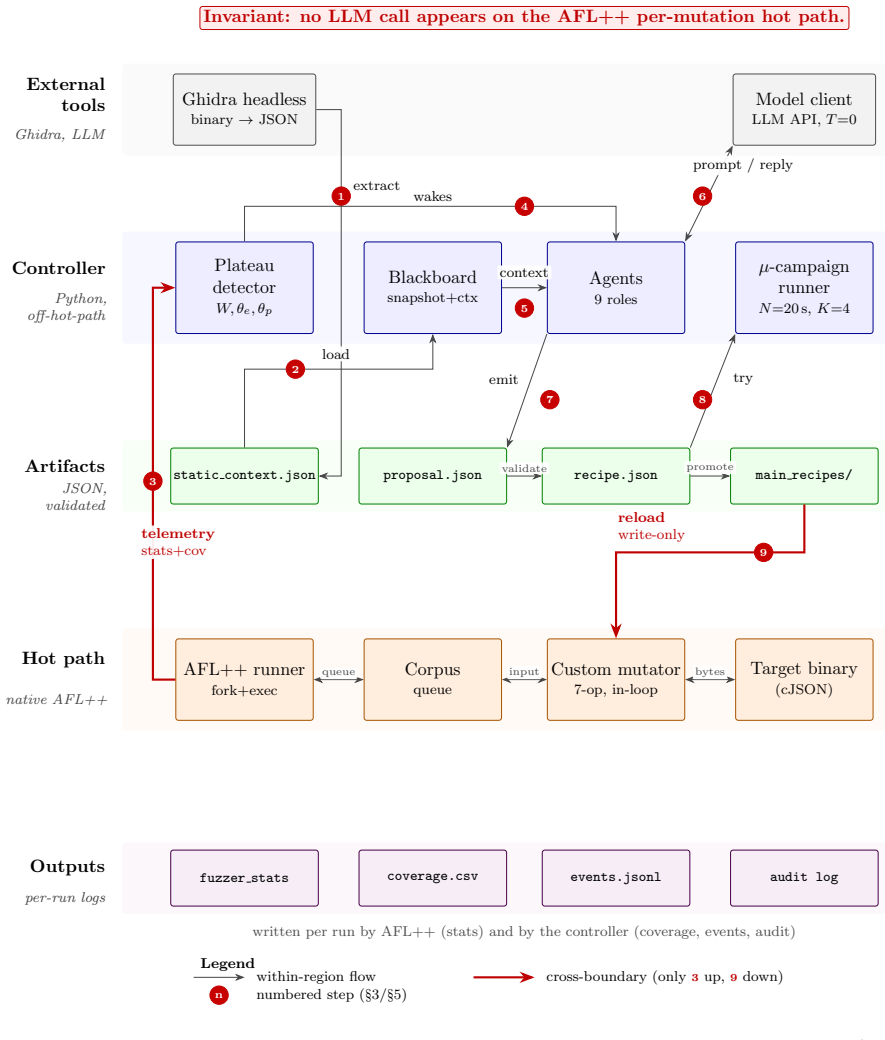
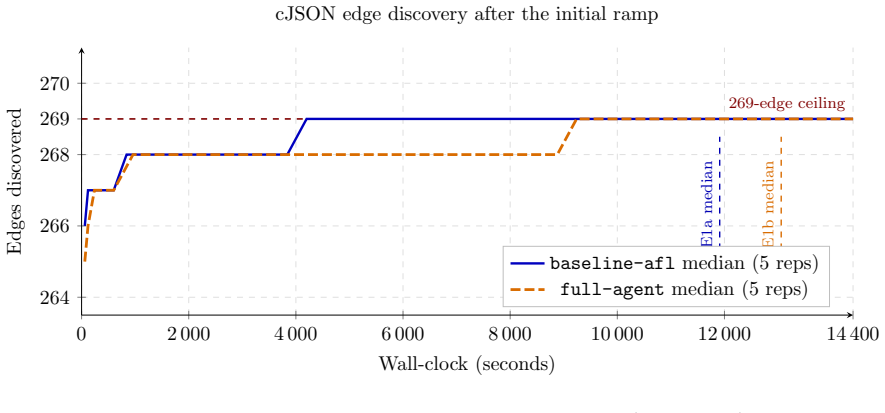
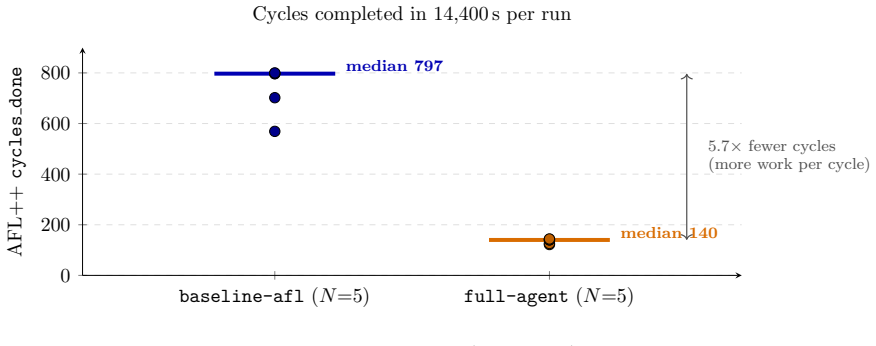
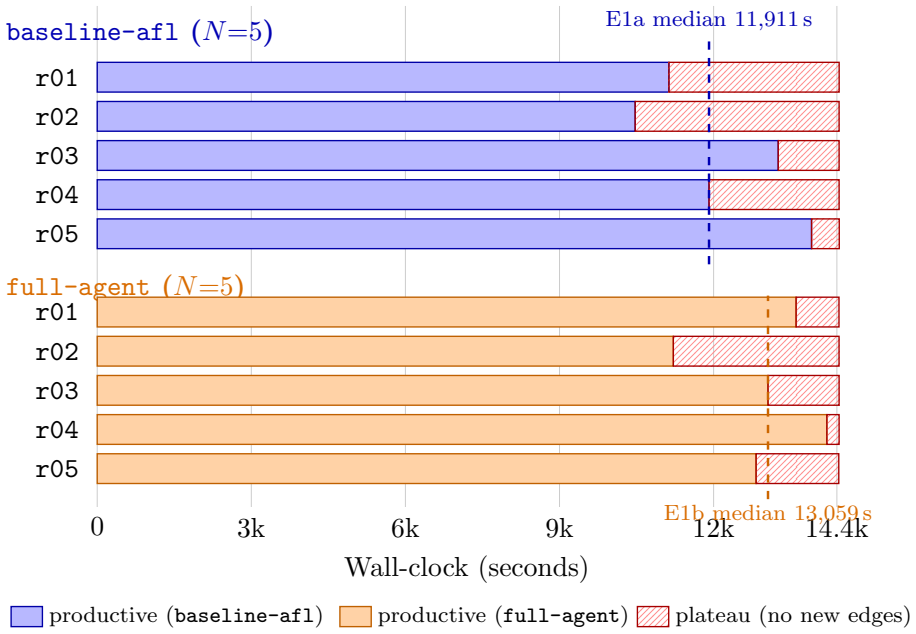
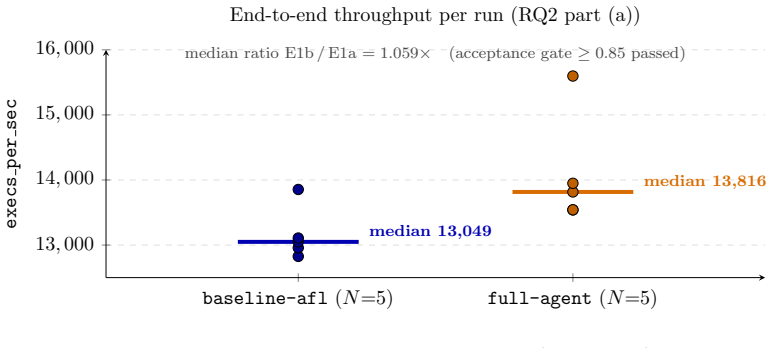
FuzzPilot snapshots the corpus upon plateau detection, prepares candidate recipes from local rules or a language-model agent supplied with Ghidra-derived constants, evaluates each recipe inside a short isolated AFL++ micro-campaign, and promotes only those yielding positive validation reward. In five 14,400-second repetitions against vanilla AFL++ on cJSON, the validation gate examined twenty model-proposed recipes and promoted none; the observed median plateau reduction from 2,532 s to 1,384 s is therefore attributed to the controller's snapshot and restart machinery rather than to the recipes themselves.
What carries the argument
The plateau-triggered validation gate that launches short isolated AFL++ micro-campaigns to compute reward for JSON-encoded candidate recipes before promotion.
If this is right
- Throughput stays comparable to vanilla AFL++ with median execs-per-second at roughly 1.06 times baseline.
- Median plateau duration shortens but the change is not statistically significant at N=5.
- No model-proposed recipes receive positive reward on the saturated cJSON target.
- The architecture separates expensive reasoning steps from the mutation hot path without throughput loss in the reported setting.
- The cJSON results serve as an auditable baseline for later tests on programs that have not reached coverage saturation.
Where Pith is reading between the lines
- Snapshot and restart machinery alone may be sufficient to produce the reported reduction in plateau length.
- Validation signals collected on saturated targets are unlikely to predict behavior on programs still capable of substantial coverage growth.
- Model proposals may require different reward definitions or richer target context before any recipe earns promotion.
Load-bearing premise
Short isolated micro-campaigns on a saturated target like cJSON can provide a reliable signal for whether recipe validation would improve coverage on non-saturated, more complex programs.
What would settle it
A run on a non-saturated target in which at least one model-proposed recipe receives positive reward, is promoted, and produces higher final edge coverage than a snapshot-restart-only control arm.
Figures

read the original abstract
FuzzPilot is a controller for AFL++ that moves expensive reasoning out of the mutation hot path. When coverage plateaus, it snapshots the corpus, prepares candidate mutation recipes, evaluates them in short isolated AFL++ micro-campaigns, and promotes only recipes with positive validation reward. Recipes are JSON data, not generated code: a native custom mutator consumes operator weights, byte ranges, corpus-selection rules, and dictionary tokens. Candidate recipes can come from local rules or from a language-model agent, with Ghidra-derived constants and decompiled context as target hints. This preprint reports a deliberately narrow cJSON evaluation. We compare vanilla AFL++ and the full FuzzPilot agent over five 14,400 s repetitions per arm. cJSON is saturated: baseline AFL++ reaches the exposed 269-edge ceiling at a median of about 2,500 s. The experiments therefore do not show that language-model proposals improve coverage or generalize beyond cJSON. Within this scope, FuzzPilot preserves throughput (median execs_per_sec about 1.06x baseline), shows a descriptively shorter median plateau (1,384 s versus 2,532 s), but the difference is not statistically significant at N=5 (Mann-Whitney p=0.42). The validation gate evaluated 20 model-proposed recipes and promoted none because all rewards were zero. The observed plateau reduction is more likely due to controller snapshot and restart machinery than to the model or recipe mutator. This version is best read as an auditable implementation report and baseline for ongoing non-saturated-target evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents FuzzPilot, an AFL++ controller that moves expensive reasoning (local rules or LLM-generated mutation recipes) out of the hot path by triggering only on coverage plateaus. It snapshots the corpus, evaluates candidate JSON recipes (operator weights, byte ranges, corpus rules, dictionary tokens) in short isolated micro-campaigns, and promotes only those with positive validation reward. On the saturated cJSON target (269-edge ceiling reached by baseline at median ~2,500 s), five 14,400 s repetitions per arm show preserved throughput (~1.06x execs/sec), a descriptively shorter median plateau (1,384 s vs 2,532 s), but no statistical significance (Mann-Whitney p=0.42 at N=5). The validation gate evaluated 20 model-proposed recipes and promoted none (all rewards zero); the paper attributes any plateau difference to snapshot/restart machinery rather than the model or mutator, and explicitly frames the work as a narrow-scope implementation report and baseline for future non-saturated targets.
Significance. The transparent reporting of a negative result, zero promotions, and explicit attribution to restart machinery (rather than overclaiming LLM benefits) provides a useful, auditable baseline for structured-text fuzzing research. The work credits the experimental design and statistical caveats directly, which strengthens its value as a reference point for subsequent evaluations on more complex programs.
minor comments (2)
- [Abstract] Abstract and evaluation section: the reward function used for the zero-promotion outcome is referenced but not defined in the provided abstract; a one-sentence inline definition or pointer to its equation would make the negative result fully self-contained without requiring the reader to consult the full methods.
- [Discussion] The manuscript notes the narrow cJSON scope and lack of generalization; a brief sentence in the discussion contrasting this saturated target with expected behavior on non-saturated programs would further clarify the intended scope of the baseline.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the recognition of our transparent reporting of negative results and zero promotions, and the recommendation to accept. The manuscript is intentionally scoped as an implementation report and baseline on a saturated target.
Circularity Check
No significant circularity identified
full rationale
The paper is an experimental implementation report comparing AFL++ variants on a saturated cJSON target. It contains no mathematical derivations, equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations. All claims rest on direct measurements (execs/sec, plateau times, reward values), statistical tests (Mann-Whitney), and explicit negative findings (zero promotions). The attribution of plateau reduction to snapshot/restart machinery follows directly from the zero-reward outcome and experimental design, without reduction to prior self-citations or ansatzes. This matches the default expectation of a self-contained empirical study against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Coverage plateau detection in AFL++ provides a meaningful trigger point for recipe validation
- domain assumption Short micro-campaigns yield a valid reward signal for recipe quality
Reference graph
Works this paper leans on
-
[1]
Malf: A multi-agent llm framework for intelligent fuzzing of industrial control protocols,
Anonymous. MALF: A multi-agent LLM framework for intelligent fuzzing of industrial control protocols.arXiv preprint arXiv:2510.02694, 2025
-
[2]
Anonymous. Semantic-aware fuzzing: An empirical framework for llm-guided, reasoning-driven input mutation.arXiv preprint arXiv:2509.19533, 2025
-
[3]
A practical guide for using statistical tests to assess randomized algorithms in software engineering
Andrea Arcuri and Lionel Briand. A practical guide for using statistical tests to assess randomized algorithms in software engineering. InProceedings of the 33rd International Conference on Software Engineering (ICSE ’11), pages 1–10, 2011
2011
-
[4]
NAUTILUS: Fishing for deep bugs with grammars
Cornelius Aschermann, Tommaso Frassetto, Thorsten Holz, Patrick Jauernig, Ahmad-Reza Sadeghi, and Daniel Teuchert. NAUTILUS: Fishing for deep bugs with grammars. InProceedings of the Network and Distributed System Security Symposium (NDSS ’19), 2019
2019
-
[5]
REDQUEEN: Fuzzing with input-to-state correspondence
Cornelius Aschermann, Sergej Schumilo, Tim Blazytko, Robert Gawlik, and Thorsten Holz. REDQUEEN: Fuzzing with input-to-state correspondence. InProceedings of the Network and Distributed System Security Symposium (NDSS ’19), 2019
2019
-
[6]
Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models
Yinlin Deng, Chunqiu Steven Xia, Haoran Peng, Chenyuan Yang, and Lingming Zhang. Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA ’23), pages 423–435, 2023
2023
-
[7]
Large language models are edge-case generators: Crafting unusual programs for fuzzing deep learning libraries
Yinlin Deng, Chunqiu Steven Xia, Chenyuan Yang, Shizhuo Dylan Zhang, Shujing Yang, and Lingming Zhang. Large language models are edge-case generators: Crafting unusual programs for fuzzing deep learning libraries. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering (ICSE ’24), 2024
2024
-
[8]
AFL++: Combining incremental steps of fuzzing research
Andrea Fioraldi, Dominik Maier, Heiko Eißfeldt, and Marc Heuse. AFL++: Combining incremental steps of fuzzing research. USENIX Workshop on Offensive Technologies (WOOT),
-
[9]
Software v4.21c used in this paper
-
[10]
Jie Hu, Qian Zhang, and Heng Yin. ChatFuzz: Augmenting greybox fuzzing with large language models.arXiv preprint arXiv:2308.11525, 2023
-
[11]
Evaluating fuzz testing
George Klees, Andrew Ruef, Benji Cooper, Shiyi Wei, and Michael Hicks. Evaluating fuzz testing. InProceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (CCS ’18), pages 2123–2138, 2018
2018
-
[12]
Circumventing fuzzing roadblocks with compiler transformations
laf intel. Circumventing fuzzing roadblocks with compiler transformations. https://lafintel. wordpress.com, 2016. Blog post, August 15, 2016. The laf-intel LLVM pass; integrated into AFL++ asAFL LLVM LAF *build flags. 39
2016
-
[13]
Shiyin Lin. Hybrid fuzzing with LLM-guided input mutation and semantic feedback.arXiv preprint arXiv:2511.03995, 2025
-
[14]
Dongge Liu, Jonathan Metzman, Oliver Chang, and Google OSS-Fuzz team. OSS-Fuzz-Gen: An open framework for LLM-driven fuzz target generation.arXiv preprint arXiv:2404.14924, 2024
- [15]
-
[16]
FuzzCoder: Byte-level fuzzing test via large language model.arXiv preprint arXiv:2409.01944, 2024
Liqun Liu et al. FuzzCoder: Byte-level fuzzing test via large language model.arXiv preprint arXiv:2409.01944, 2024
-
[17]
The Mutators reloaded: Fuzzing compilers with large language model generated mutators
Conghua Ou et al. The Mutators reloaded: Fuzzing compilers with large language model generated mutators. InProceedings of the 29th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’24), 2024
2024
-
[18]
Santosa, Alexandru R˘ azvan Caciulescu, and Abhik Roychoudhury
Van-Thuan Pham, Marcel B¨ ohme, Andrew E. Santosa, Alexandru R˘ azvan Caciulescu, and Abhik Roychoudhury. Smart greybox fuzzing. InIEEE Transactions on Software Engineering (TSE), 2021. Originally NDSS 2019 (AFLSmart); journal extension 2021
2021
-
[19]
Schuirmann
Donald J. Schuirmann. A comparison of the two one-sided tests procedure and the power approach for assessing the equivalence of average bioavailability.Journal of Pharmacokinetics and Biopharmaceutics, 15(6):657–680, 1987
1987
-
[20]
LLM upfront, no steady-state calls
Yuyan Sun et al. Sphinx: A language model guided generator for solver fuzzing. InProceed- ings of the International Conference on Automated Software Engineering (ASE ’24), 2024. Representative “LLM upfront, no steady-state calls” design for SMT-solver fuzzing
2024
-
[21]
Andr´ as Vargha and Harold D. Delaney. A critique and improvement of the CL common language effect size statistics of McGraw and Wong.Journal of Educational and Behavioral Statistics, 25(2):101–132, 2000
2000
-
[22]
LLAMAFUZZ: Large language model enhanced greybox fuzzing.arXiv preprint arXiv:2406.07714, 2024
Hongxiang Wang, Xiangwei Xu, Xiaofei Xie, et al. LLAMAFUZZ: Large language model enhanced greybox fuzzing.arXiv preprint arXiv:2406.07714, 2024. Latest revision March 2026
-
[23]
Superion: Grammar-aware greybox fuzzing
Junjie Wang, Bihuan Chen, Lei Wei, and Yang Liu. Superion: Grammar-aware greybox fuzzing. InProceedings of the 41st International Conference on Software Engineering (ICSE ’19), 2019
2019
-
[24]
Ohlsson, Bj¨ orn Regnell, and Anders Wessl´ en.Experimentation in Software Engineering
Claes Wohlin, Per Runeson, Martin H¨ ost, Magnus C. Ohlsson, Bj¨ orn Regnell, and Anders Wessl´ en.Experimentation in Software Engineering. Springer Berlin Heidelberg, 2012
2012
-
[25]
Fuzz4All: Universal fuzzing with large language models.arXiv preprint arXiv:2308.04748,
Chunqiu Steven Xia, Matteo Paltenghi, Jia Le Tian, Michael Pradel, and Lingming Zhang. Fuzz4All: Universal fuzzing with large language models.arXiv preprint arXiv:2308.04748,
-
[26]
Originally posted 2023; updated 2024
2023
-
[27]
WhiteFox: White-box compiler fuzzing empowered by large language models
Chenyuan Yang, Yinlin Deng, Runyu Lu, Jiayi Yao, Jiawei Liu, Reyhaneh Jabbarvand, and Lingming Zhang. WhiteFox: White-box compiler fuzzing empowered by large language models. InProceedings of the ACM on Programming Languages (OOPSLA ’24), 2024
2024
-
[28]
KernelGPT: Enhanced kernel fuzzing via large language models
Chenyuan Yang, Zhouruixing Zhao, and Lingming Zhang. KernelGPT: Enhanced kernel fuzzing via large language models. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’25), 2025. 40
2025
- [29]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.