A Retrospective Recount of Computer Architecture Research with a Data-Driven Study of Over Four Decades of ISCA Publications
Pith reviewed 2026-05-25 18:23 UTC · model grok-4.3
The pith
An NLP pipeline applied to all ISCA papers from 1973 to 2018 extracts computation patterns and research trends that the authors judge worth sharing despite acknowledged limits in document understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a practical NLP pipeline for document understanding, when run on the complete set of ISCA papers from 1973 to 2018, yields identifiable computation patterns and research trends that remain interesting enough to report even while the underlying natural language processing technology is still limited.
What carries the argument
The NLP-based AI pipeline developed in the DISCvR project, used here to process and extract trends from the full historical corpus of ISCA publications.
If this is right
- Computer architecture researchers gain a quantitative baseline for how topics such as parallelism, memory systems, and power have risen or fallen across four decades.
- Conference organizers obtain a repeatable method for reviewing past programs and identifying underrepresented areas.
- The same pipeline can be reapplied to later ISCA volumes or to related venues to track ongoing evolution.
- Limitations identified in the current analysis point to specific improvements needed in handling technical terminology and citation context.
Where Pith is reading between the lines
- The approach could be extended to papers from other architecture or systems conferences to test whether the same trends appear outside ISCA.
- If the pipeline improves, it might eventually support automated generation of research roadmaps by comparing extracted patterns against emerging hardware capabilities.
- The work implicitly suggests that community-maintained labeled datasets of architecture papers would help future NLP efforts succeed where the current prototype falls short.
Load-bearing premise
The pipeline can pull reliable patterns and trends out of the unstructured text of technical papers even though the authors themselves note that current natural language understanding remains imperfect.
What would settle it
Expert reviewers or independent re-analysis of the same ISCA corpus finds that the reported trends do not align with documented historical shifts in the field or that the extracted patterns are too noisy to be actionable.
Figures














read the original abstract
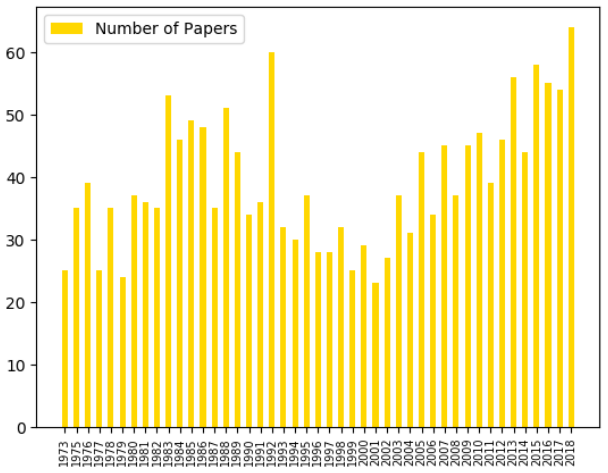
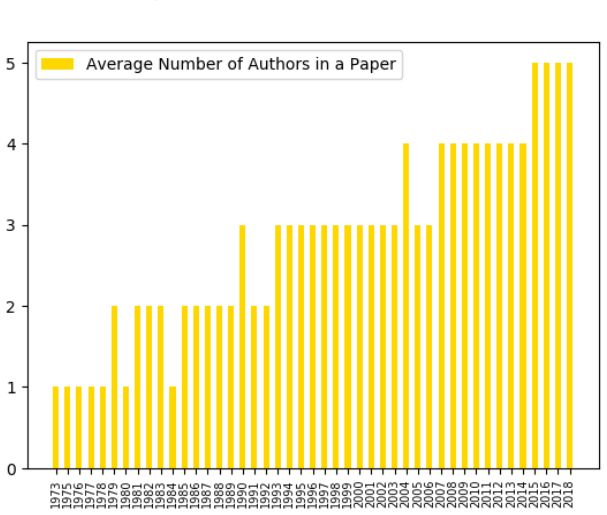
This study began with a research project, called DISCvR, conducted at the IBM-ILLINOIS Center for Cognitive Computing Systems Reseach. The goal of DISCvR was to build a practical NLP based AI pipeline for document understanding which will help us better understand the computation patterns and requirements of modern computing systems. While building such a prototype, an early use case came to us thanks to the 2017 IEEE/ACM International Symposium on Microarchitecture (MICRO-50) Program Co-chairs, Drs. Hillery Hunter and Jaime Moreno. They asked us if we can perform some data-driven analysis of the past 50 years of MICRO papers and show some interesting historical perspectives on MICRO's 50 years of publication. We learned two important lessons from that experience: (1) building an AI solution to truly understand unstructured data is hard in spite of the many claimed successes in natural language understanding; and (2) providing a data-driven perspective on computer architecture research is a very interesting and fun project. Recently we decided to conduct a more thorough study based on all past papers of International Symposium on Computer Architecture (ISCA) from 1973 to 2018, which resulted this article. We recognize that we have just scratched the surface of natural language understanding of unstructured data, and there are many more aspects that we can improve. But even with our current study, we felt there were enough interesting findings that may be worthwhile to share with the community. Hence we decided to write this article to summarize our findings so far based only on ISCA publications. Our hope is to generate further interests from the community in this topic, and we welcome collaboration from the community to deepen our understanding both of the computer architecture research and of the challenges of NLP-based AI solutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes an exploratory observational study applying an NLP pipeline (developed in the DISCvR project) to ISCA papers from 1973–2018. Motivated by an earlier MICRO-50 analysis, it aims to surface computation patterns and research trends, acknowledges inherent difficulties in technical-document understanding, and positions the work as a preliminary effort intended to stimulate community interest rather than a fully validated analysis.
Significance. If the reported trends prove reproducible and the pipeline’s error characteristics are characterized, the study could serve as a useful seed for data-driven meta-research in computer architecture. Its modest framing and explicit recognition of NLP limitations are appropriate for an initial effort.
major comments (2)
- [Abstract] Abstract: the central claim that the analysis produced 'enough interesting findings' to share with the community is not supported by any concrete examples, quantitative trends, or error analysis of the NLP pipeline; without these the reader cannot evaluate whether the findings are reliable or novel.
- [Abstract] The manuscript supplies no validation metrics, inter-annotator agreement, or manual spot-checks for the extraction of computation patterns; this absence is load-bearing because the weakest assumption identified is precisely the reliability of the NLP pipeline on unstructured technical text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our exploratory study. We agree that the abstract requires concrete support for its claims and that the reliability of the NLP pipeline needs better characterization. We will revise the manuscript accordingly while preserving its positioning as a preliminary effort.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the analysis produced 'enough interesting findings' to share with the community is not supported by any concrete examples, quantitative trends, or error analysis of the NLP pipeline; without these the reader cannot evaluate whether the findings are reliable or novel.
Authors: We agree that the abstract should include concrete examples to substantiate the claim. In the revision we will add specific quantitative trends identified in the ISCA corpus (such as shifts in dominant computation patterns across decades) and reference the pipeline error characteristics already analyzed in the body of the paper. This will enable readers to assess reliability and novelty directly from the abstract. revision: yes
-
Referee: [Abstract] The manuscript supplies no validation metrics, inter-annotator agreement, or manual spot-checks for the extraction of computation patterns; this absence is load-bearing because the weakest assumption identified is precisely the reliability of the NLP pipeline on unstructured technical text.
Authors: We acknowledge the absence of explicit validation metrics in the current version. The work is framed as preliminary and we already note the inherent difficulties of NLP on technical documents. For the revision we will add manual spot-check results on a sample of extracted patterns together with basic agreement statistics. A full inter-annotator study remains outside the scope of this initial effort but will be listed as future work. revision: partial
Circularity Check
No significant circularity
full rationale
The paper is an exploratory observational study applying NLP to extract trends from external ISCA publication data spanning 1973-2018. No equations, derivations, fitted parameters, or predictions appear in the provided text or abstract. The central claim is explicitly modest (interesting findings worth sharing despite NLP limitations), with no load-bearing steps that reduce to self-defined inputs, self-citations, or ansatzes. The work is self-contained against external benchmarks as a retrospective recount without internal reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Arnab Sinha, Zhihong Shen, Yang Song, Hao Ma, Darrin Eide, Bo-June (Paul) Hsu, and Kuansan Wang. 2015. An Overview of Microsoft Academic Service (MA) and Applications. In Proceedings of the 24th International Con- ference on World Wide Web (WWW ’15 Companion). ACM, New York, NY, USA, 243-246. DOI=http://dx.doi.org/10.1145/2740908.2742839
-
[2]
David R. Ditzel and David A. Patterson. 1980. Retrospective on high-level language computer architecture. In Proceedings of the 7th annual symposium on Computer Architecture (ISCA ’80). ACM, New York, NY, USA, 97-104. DOI: http://dx.doi.org/10.1145/800053.801914 23
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.