WhiFlash: Accelerating Speculative Decoding with Token-Level Cross-Paradigm Routing
Pith reviewed 2026-06-27 22:48 UTC · model grok-4.3
The pith
Token-level routing between autoregressive and diffusion drafting raises acceptance lengths and delivers up to 69.6 percent throughput gains over static speculative decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
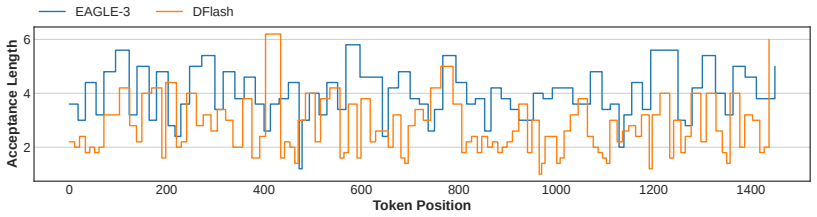
WhiFlash unifies autoregressive and diffusion-based parallel drafting under a single token-level controller. The controller selects the paradigm for each token with either an entropy-based or a learned neural policy that balances expected token gain against added latency. Lazy Catch-up and KV-only Prefill mechanisms reduce the cost of high-frequency switches to less than seven percent of per-round latency. Capitalising on the complementary strengths of the two paradigms produces higher acceptance lengths than either static EAGLE-3 or static DFlash, translating into category-specific throughput gains of up to 69.6 percent and 37.3 percent respectively.
What carries the argument
The token-level cross-paradigm routing controller that selects between autoregressive and diffusion drafting via an entropy or learned policy, backed by Lazy Catch-up and KV-only Prefill cache mechanisms.
If this is right
- Sequences whose drafting accuracy varies token to token obtain the largest acceptance-length improvements.
- The routing mechanism works with any pair of complementary drafting architectures without retraining the target model.
- High-frequency paradigm switches remain profitable once the cache optimisations are in place.
- Category-specific speedups arise automatically because the policy adapts to the local characteristics of reasoning versus structured-output segments.
Where Pith is reading between the lines
- The same per-token selection idea could be tested with additional drafting paradigms beyond the two examined here.
- Agentic workloads that mix reasoning and output generation may see the largest practical benefit because the controller can react inside a single response.
- Distilling the routing decision into the drafter itself might reduce overhead further in future implementations.
- The approach suggests that static paradigm choice is a general limitation worth revisiting in other acceleration techniques that rely on a single drafting style.
Load-bearing premise
A lightweight policy can pick the stronger drafting paradigm at each token while adding less than seven percent latency per round.
What would settle it
Measuring that the routing policy selects the lower-accuracy drafter on more than half the tokens across held-out sequences, or that measured switching overhead exceeds seven percent of per-round latency, would eliminate the claimed net gains.
Figures

read the original abstract
The autoregressive nature of large language models (LLMs) remains a significant bottleneck for inference, particularly in complex agentic workloads. While speculative decoding (SD) accelerates inference, current approaches rely on static drafting paradigms, utilising either autoregressive drafting models for reasoning or diffusion-based parallel drafting models for structured outputs. We empirically find that drafting accuracy fluctuates dramatically within a single sequence, leaving significant performance unrealised by static paradigms and coarse-grained routing. To address this volatility, we introduce WhiFlash, the first cross-paradigm SD method that unifies autoregressive and diffusion-based parallel drafting under a single token-level controller. WhiFlash adopts a fine-grained routing mechanism that employs either a lightweight entropy-based or a learned neural policy, both parametrised to provide a tunable balance between expected token gain and latency. To make high-frequency switching computationally viable, we introduce novel cache-management optimisations, Lazy Catch-up and KV-only Prefill, reducing switching overhead to below 7% of per-round latency. By capitalising on the complementary strengths of fundamentally distinct drafting architectures, WhiFlash achieves significantly higher acceptance lengths, yielding category-specific throughput gains of up to 69.6% over the state-of-the-art autoregressive EAGLE-3 and 37.3% over the diffusion-based DFlash.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WhiFlash, a speculative decoding framework that performs token-level routing between autoregressive drafters (e.g., EAGLE-3) and diffusion-based parallel drafters (e.g., DFlash) via lightweight entropy-based or learned neural policies. It proposes Lazy Catch-up and KV-only Prefill cache mechanisms to bound paradigm-switching overhead below 7% of per-round latency, claiming this yields higher acceptance lengths and category-specific throughput gains of up to 69.6% over EAGLE-3 and 37.3% over DFlash.
Significance. If the routing policy maintains high selection accuracy and the cache mechanisms indeed keep overhead low under realistic switching rates, the work would demonstrate a practical way to exploit complementary strengths of distinct drafting paradigms, potentially improving SD robustness across reasoning and structured-output workloads.
major comments (2)
- [Abstract] Abstract (final paragraph): The central claim that Lazy Catch-up and KV-only Prefill reduce switching overhead to below 7% of per-round latency is load-bearing for the reported net throughput gains, yet the abstract supplies no per-component latency breakdown, routing decision frequency statistics, or ablation isolating the routing controller from the base drafters.
- [Abstract] Abstract: The headline gains (69.6% over EAGLE-3, 37.3% over DFlash) are presented without reference to specific experimental tables/figures, model sizes, datasets, hardware, error bars, or statistical tests, making it impossible to verify robustness or rule out post-hoc selection effects.
minor comments (1)
- Clarify whether the entropy-based and neural policies are compared head-to-head in the same experimental setting and report their individual overheads.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the abstract can be improved by adding explicit references to supporting results and will revise it in the resubmitted version.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): The central claim that Lazy Catch-up and KV-only Prefill reduce switching overhead to below 7% of per-round latency is load-bearing for the reported net throughput gains, yet the abstract supplies no per-component latency breakdown, routing decision frequency statistics, or ablation isolating the routing controller from the base drafters.
Authors: We agree the abstract would benefit from directing readers to the supporting evidence. The full manuscript reports the per-component latency breakdown and routing frequency statistics in Section 4.3 and Figure 5, with ablations isolating the routing controller in Section 5.2. We will revise the abstract to cite these sections and figures. revision: yes
-
Referee: [Abstract] Abstract: The headline gains (69.6% over EAGLE-3, 37.3% over DFlash) are presented without reference to specific experimental tables/figures, model sizes, datasets, hardware, error bars, or statistical tests, making it impossible to verify robustness or rule out post-hoc selection effects.
Authors: We agree that explicit references would aid verifiability. The gains are supported by results in Table 2 and Figure 3, using the model sizes, datasets, and hardware described in Section 4.1, with error bars included in the reported figures. We will update the abstract to reference these tables and figures. revision: yes
Circularity Check
No significant circularity; empirical method with direct comparisons
full rationale
The paper presents an engineering contribution introducing token-level cross-paradigm routing for speculative decoding, along with cache optimizations (Lazy Catch-up, KV-only Prefill) and a lightweight policy (entropy-based or neural). Reported gains (e.g., 69.6% over EAGLE-3) rest on empirical throughput measurements against external baselines rather than any derivation chain, fitted parameters renamed as predictions, or self-referential definitions. No equations, uniqueness theorems, or load-bearing self-citations appear in the provided text that would reduce the central claims to inputs by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, Che Chang, Kai Chen, and 106 others. 2025. https://arxiv.org/abs/2508.10925 gpt-oss-120b & gpt-oss-20b Model Card . Prepri...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
AIME . 2025. AIME problems and solutions. https://artofproblemsolving.com/wiki/index.php/AIME Problems and Solutions
2025
-
[3]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. https://arxiv.org/abs/2108.07732 Program Synthesis with Large Language Models . Preprint, arXiv:2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Ruisheng Cao, Mouxiang Chen, Jiawei Chen, Zeyu Cui, Yunlong Feng, Binyuan Hui, Yuheng Jing, Kaixin Li, Mingze Li, Junyang Lin, Zeyao Ma, Kashun Shum, Xuwu Wang, Jinxi Wei, Jiaxi Yang, Jiajun Zhang, Lei Zhang, Zongmeng Zhang, Wenting Zhao, and Fan Zhou. 2026. https://arxiv.org/abs/2603.00729 Qwen3-Coder-Next Technical Report . Preprint, arXiv:2603.00729
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. 2023. https://arxiv.org/abs/2302.01318 Accelerating Large Language Model Decoding with Speculative Sampling . Preprint, arXiv:2302.01318
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Jian Chen, Yesheng Liang, and Zhijian Liu. 2026. https://arxiv.org/abs/2602.06036 DFlash: Block Diffusion for Flash Speculative Decoding . Preprint, arXiv:2602.06036
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, and 39 others. 2021. https://arxiv.org/abs/2107.03374 Evaluating Large Lang...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Ziyi Chen, Xiaocong Yang, Jiacheng Lin, Chenkai Sun, Kevin Chen-Chuan Chang, and Jie Huang. 2024. Cascade speculative drafting for even faster llm inference. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NeurIPS '24, Red Hook, NY, USA. Curran Associates Inc
2024
-
[9]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. https://arxiv.org/abs/2110.14168 Training Verifiers to Solve Math Word Problems . Preprint, arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.183 Enhancing chat language models by scaling high-quality instructional conversations . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3029--3051, Singapore...
-
[11]
Razvan-Gabriel Dumitru, Minglai Yang, Vikas Yadav, and Mihai Surdeanu. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1337 C opy S pec: Accelerating LLM s with speculative copy-and-paste . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 26301--26332, Suzhou, China. Association for Computational Linguistics
-
[12]
Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, and 48 others. 2025. https://arxiv.org/abs/2512.13961 Olmo 3 . Prepri...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [13]
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The Llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Dan Hendrycks and Kevin Gimpel. 2023. https://arxiv.org/abs/1606.08415 Gaussian Error Linear Units (GELUs) . Preprint, arXiv:1606.08415
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2025. https://openreview.net/forum?id=chfJJYC3iL LiveCodeBench : Holistic and contamination free evaluation of large language models for code . In The Thirteenth International Conference on Learning Representations
2025
-
[17]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. 2024. https://openreview.net/forum?id=VTF8yNQM66 SWE -bench: Can Language Models Resolve Real-world Github Issues? In The Twelfth International Conference on Learning Representations
2024
-
[18]
Jiin Kim, Byeongjun Shin, Jinha Chung, and Minsoo Rhu. 2026 a . The Cost of Dynamic Reasoning: Demystifying AI Agents and Test-Time Scaling from an AI Infrastructure Perspective . In IEEE International Symposium on High Performance Computer Architecture (HPCA)
2026
-
[19]
Taehyeon Kim, Hojung Jung, and Se-Young Yun. 2026 b . https://arxiv.org/abs/2604.05417 Multi-Drafter Speculative Decoding with Alignment Feedback . Preprint, arXiv:2604.05417
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. 2017. https://arxiv.org/abs/1412.6980 Adam: A Method for Stochastic Optimization . Preprint, arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. https://proceedings.mlr.press/v202/leviathan23a.html Fast Inference from Transformers via Speculative Decoding . In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 19274--19286. PMLR
2023
-
[22]
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. 2025. https://proceedings.neurips.cc/paper_files/paper/2025/file/c7b5a35ea98b62512a869c19ea7b03cb-Paper-Conference.pdf EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test . In Advances in Neural Information Processing Systems, volume 38, pages 136737--136756. Cur...
2025
-
[23]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2024. https://openreview.net/forum?id=v8L0pN6EOi Let's Verify Step by Step . In The Twelfth International Conference on Learning Representations
2024
-
[24]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, and 244 others. 2025. https://arxiv.org/abs/2512.02556 DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models . P...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Hongyi Liu, Jiaji Huang, Zhen Jia, Youngsuk Park, and Yu-Xiang Wang. 2026 a . https://openreview.net/forum?id=JMmljf895g Not-a-Bandit: Provably No-Regret Drafter Selection in Speculative Decoding for LLM s . In The Fourteenth International Conference on Learning Representations
2026
- [26]
-
[27]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, and 3 others. 2024. https://openreview.net/forum?id=zAdUB0aCTQ AgentBench : Evaluating LLM s as agents . In The Twelfth Internationa...
2024
-
[28]
Zhiyao Ma, In Gim, and Lin Zhong. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1581 Cacheback: Speculative decoding with nothing but cache . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 31079--31084, Suzhou, China. Association for Computational Linguistics
-
[29]
Arindam Mitra, Luciano Del Corro, Guoqing Zheng, Shweti Mahajan, Dany Rouhana, Andres Codas, Yadong Lu, Wei ge Chen, Olga Vrousgos, Corby Rosset, Fillipe Silva, Hamed Khanpour, Yash Lara, and Ahmed Awadallah. 2024. https://arxiv.org/abs/2407.03502 AgentInstruct : Toward generative teaching with agentic flows . Preprint, arXiv:2407.03502
-
[30]
Gabriele Oliaro, Zhihao Jia, Daniel Campos, and Aurick Qiao. 2025. https://proceedings.neurips.cc/paper_files/paper/2025/file/b7aea253ab34a773967f1e4cdea9e4fb-Paper-Conference.pdf SuffixDecoding: Extreme Speculative Decoding for Emerging AI Applications . In Advances in Neural Information Processing Systems, volume 38, pages 126326--126354. Curran Associates, Inc
2025
-
[31]
Guofeng Quan, Wenfeng Feng, Chuzhan Hao, Guochao Jiang, Yuewei Zhang, and Hao Henry Wang. 2025. https://doi.org/10.18653/v1/2025.findings-acl.320 RASD : Retrieval-augmented speculative decoding . In Findings of the Association for Computational Linguistics: ACL 2025, pages 6167--6177, Vienna, Austria. Association for Computational Linguistics
-
[32]
Liran Ringel and Yaniv Romano. 2026. https://arxiv.org/abs/2604.12989 Accelerating Speculative Decoding with Block Diffusion Draft Trees . Preprint, arXiv:2604.12989
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford Alpaca: An Instruction-following LLaMA model . https://github.com/tatsu-lab/stanford_alpaca
2023
-
[34]
Jikai Wang, Yi Su, Juntao Li, Qingrong Xia, Zi Ye, Xinyu Duan, Zhefeng Wang, and Min Zhang. 2025. https://doi.org/10.1162/tacl_a_00735 OPT -tree: Speculative decoding with adaptive draft tree structure . Transactions of the Association for Computational Linguistics, 13:188--199
-
[35]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, and 3 others. 2020. https://doi.org/10.18653/v1/2020.emnlp-demos.6 Transformers: Sta...
-
[36]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 Technical Report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik R Narasimhan. 2025. https://openreview.net/forum?id=roNSXZpUDN -bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains . In The Thirteenth International Conference on Learning Representations
2025
-
[38]
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. 2024. https://openreview.net/forum?id=Bl8u7ZRlbM WildChat : 1M ChatGPT interaction logs in the wild . In The Twelfth International Conference on Learning Representations
2024
-
[39]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM -as-a-judge with MT -bench and Chatbot Arena . In Proceedings of the 37th International Conference on Neural Information Processing Systems, NeurIPS '23, Red H...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.