What Survives Into Context: A Diagnostic for Budget-Constrained Multi-Hop RAG and When Submodular Evidence Packing Improves It
Pith reviewed 2026-07-02 13:30 UTC · model grok-4.3
The pith
Answer-in-context predicts reader F1 better than document recall and a submodular packer raises accuracy when evidence must be densely packed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Answer-in-context is the central quantity because it directly records whether the gold answer span reaches the reader; it predicts answer F1 with correlations of 0.39-0.55 versus roughly 0.31 for recall, adds 0.17 to R-squared, and produces a 4.6 times EM gap even when all gold documents are retrieved. Casting reader-context construction as budgeted monotone submodular maximization and jointly optimizing relevance, coverage, representativeness, and diversity yields up to 5.1 F1 improvement over strong baselines at equal or lower token cost on HotpotQA with a 160-token budget and 3B reader. The advantage is confined to the joint presence of multi-hop complementary evidence, retrieval that sur
What carries the argument
answer-in-context diagnostic (gold answer as contiguous span in packed context) together with budgeted monotone submodular maximization for joint relevance-coverage-representativeness-diversity selection
If this is right
- Answer-in-context adds Delta R-squared of 0.17 over recall when predicting answer F1.
- A packing change that raises coverage but not answer-in-context produces no accuracy gain on 2WikiMultiHopQA.
- The submodular advantage is absorbed by 7B readers and reverses by 14B on the same tasks.
- The reported 4.6 times EM gap persists even among questions where all gold documents were retrieved.
Where Pith is reading between the lines
- The same diagnostic could be used to decide when to stop adding more retrieved documents rather than always packing to the budget limit.
- For tasks without multi-hop complementarity the submodular formulation may add unnecessary overhead compared with simple top-k selection.
- If answer-in-context can be estimated before packing, it could serve as a stopping criterion or reranking signal inside the retriever itself.
Load-bearing premise
The submodular packer improves results only when the reader is weak enough that evidence density, not model capacity, is the performance bottleneck.
What would settle it
On HotpotQA at 160 tokens with a 3B reader, the submodular packer showing no F1 gain over the focused heuristic, or answer-in-context failing to correlate more strongly with F1 than recall, would falsify the central claims.
Figures



read the original abstract
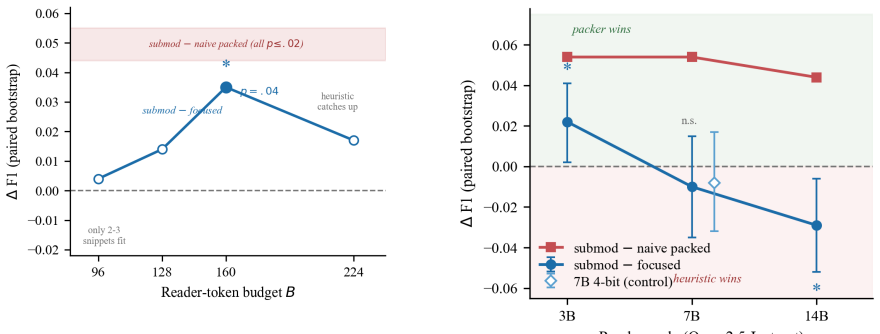
Retrieval-augmented generation (RAG) under a fixed reader-context budget forces a selection problem: of the evidence retrieved, only a fraction can be shown to the reader. We argue that document recall -- the standard retrieval metric -- is the wrong quantity to optimize in this regime, and we make two contributions. First, as a general contribution, we introduce answer-in-context, a diagnostic that measures whether a gold answer survives as a contiguous span in the packed reader context (not the retrieved set). It predicts answer F1 better than recall (r=0.39-0.55 vs. about 0.31), separates answer quality roughly five-fold (0.60 vs. 0.12 on HotpotQA), and carries information beyond retrieval: it adds Delta R squared=0.17 over recall and shows a 4.6x EM gap even among questions where all gold was retrieved. We also confirm it interventionally: on 2WikiMultiHopQA a packing change that raises coverage but not answer-in-context yields no accuracy gain. Second, as a conditional contribution, we cast reader-context construction as budgeted monotone submodular maximization and build a packer that jointly optimizes relevance, query coverage, representativeness, and diversity. On HotpotQA with a 160-token budget and a 3B reader it beats a strong focused heuristic, MMR, and naive packing -- by up to +5.1 F1 at equal-or-lower token cost, across three seeds. Crucially, we map the scope of this win honestly: it requires the conjunction of (i) multi-hop complementary structure, (ii) retrieval that surfaces the evidence, (iii) a binding but not extreme budget, and (iv) a reader weak enough that evidence density, not reading capacity, is the bottleneck. A quantization-controlled reader-scale ladder (3B to 7B to 14B) shows the edge over the heuristic is absorbed by 7B and significantly reverses by 14B, while the diagnostic explains every boundary with a single variable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in budget-constrained multi-hop RAG, document recall is the wrong optimization target; instead, answer-in-context (whether a gold answer appears as a contiguous span in the packed reader context) is a superior diagnostic. It reports stronger correlations with answer F1 (r=0.39-0.55 vs. ~0.31), a five-fold separation in answer quality (0.60 vs. 0.12 on HotpotQA), incremental R²=0.17 over recall, and a 4.6x EM gap even when all gold evidence is retrieved. It further claims that casting context packing as budgeted monotone submodular maximization yields a packer that improves F1 by up to +5.1 over focused heuristics, MMR, and naive packing on HotpotQA (160-token budget, 3B reader), with the win confined to the conjunction of multi-hop structure, sufficient retrieval, binding budget, and weak reader; a reader-scale ladder (3B/7B/14B) and interventional test on 2WikiMultiHopQA are provided to bound the result.
Significance. If the reported correlations, incremental R², and conditional F1 gains hold under full experimental disclosure, the work supplies a practical diagnostic that directly measures evidence survival in the reader context and a standard submodular technique for joint optimization of relevance, coverage, representativeness, and diversity. The explicit mapping of the win's scope (including the quantization-controlled reader ladder and the interventional check) strengthens falsifiability and clarifies when the packer is expected to help versus when larger readers absorb the edge.
major comments (2)
- [Abstract, §4] Abstract and §4 (experimental setup): the reported +5.1 F1 gain, R² deltas, and reader-scale ladder rest on specific data splits, retrieval pipelines, and tokenization details that are summarized at high level but not fully enumerated (e.g., exact train/dev/test partitions, retrieval top-k, span extraction rules). This prevents direct reproduction and verification of the 4.6x EM gap conditional on full gold retrieval.
- [§3.2] §3.2 (interventional test): the claim that raising coverage but not answer-in-context yields no accuracy gain on 2WikiMultiHopQA is load-bearing for the diagnostic's causal interpretation, yet the packing change, exact coverage numbers, and statistical test are described only qualitatively; a table or figure with before/after answer-in-context and EM would be required to confirm the boundary condition.
minor comments (2)
- [§2] Notation for answer-in-context should be introduced with an explicit equation or pseudocode in §2 to distinguish it cleanly from recall@K and from answer presence in the retrieved set.
- [Figure 3] Figure captions for the reader-scale ladder should state the exact token budget and number of seeds used so the absorption of the submodular edge at 7B is immediately interpretable.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We agree that additional experimental details and a quantitative presentation of the interventional test are needed to support reproducibility and strengthen the causal claims. We will revise accordingly.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (experimental setup): the reported +5.1 F1 gain, R² deltas, and reader-scale ladder rest on specific data splits, retrieval pipelines, and tokenization details that are summarized at high level but not fully enumerated (e.g., exact train/dev/test partitions, retrieval top-k, span extraction rules). This prevents direct reproduction and verification of the 4.6x EM gap conditional on full gold retrieval.
Authors: We agree the current high-level summary limits reproducibility. In revision we will add a dedicated appendix (or expanded §4) enumerating the exact train/dev/test partitions, retrieval top-k, span extraction rules for answer-in-context, tokenization details, and any other pipeline parameters. This will allow direct verification of all metrics including the conditional 4.6x EM gap. revision: yes
-
Referee: [§3.2] §3.2 (interventional test): the claim that raising coverage but not answer-in-context yields no accuracy gain on 2WikiMultiHopQA is load-bearing for the diagnostic's causal interpretation, yet the packing change, exact coverage numbers, and statistical test are described only qualitatively; a table or figure with before/after answer-in-context and EM would be required to confirm the boundary condition.
Authors: We accept that the interventional result must be presented quantitatively. We will insert a new table (or figure) in §3.2 reporting before/after coverage, answer-in-context, EM/F1, and the associated statistical test on 2WikiMultiHopQA. This will make the boundary condition explicit and allow readers to evaluate the causal claim directly. revision: yes
Circularity Check
No significant circularity detected
full rationale
The answer-in-context diagnostic is defined directly from span presence in the packed context and evaluated via explicit correlations, incremental R-squared, and interventional checks on held-out F1/EM; none of these reduce to fitted inputs by construction. Submodular maximization is invoked as a standard external budgeted monotone optimization technique with no self-citation chain or ansatz smuggling. The paper explicitly enumerates the conjunction of conditions required for the reported win rather than deriving them internally. No load-bearing step equates a prediction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[2]
Guu, Kelvin and Lee, Kenton and Tung, Zora and Pasupat, Panupong and Chang, Ming-Wei , booktitle =
-
[3]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Dense Passage Retrieval for Open-Domain Question Answering , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
2020
-
[4]
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , pages =
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering , author =. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , pages =
-
[5]
Journal of Machine Learning Research (JMLR) , volume =
Atlas: Few-shot Learning with Retrieval Augmented Language Models , author =. Journal of Machine Learning Research (JMLR) , volume =
-
[6]
Proceedings of the 39th International Conference on Machine Learning (ICML) , pages =
Improving Language Models by Retrieving from Trillions of Tokens , author =. Proceedings of the 39th International Conference on Machine Learning (ICML) , pages =
-
[7]
Transactions of the Association for Computational Linguistics (TACL) , volume =
In-Context Retrieval-Augmented Language Models , author =. Transactions of the Association for Computational Linguistics (TACL) , volume =
-
[8]
Shi, Weijia and Min, Sewon and Yasunaga, Michihiro and Seo, Minjoon and James, Rich and Lewis, Mike and Zettlemoyer, Luke and Yih, Wen-tau , booktitle =
-
[9]
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avirup and Hajishirzi, Hannaneh , booktitle =. Self-
-
[10]
Lin, Xi Victoria and Chen, Xilun and Chen, Moya and Shi, Weijia and Lomeli, Maria and James, Rich and Rodriguez, Pedro and Kahn, Jacob and Szilvasy, Gergely and Lewis, Mike and Zettlemoyer, Luke and Yih, Scott , booktitle =
-
[11]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retrieval-Augmented Generation for Large Language Models: A Survey , author =. arXiv preprint arXiv:2312.10997 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
, booktitle =
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. , booktitle =
-
[13]
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish , journal =
-
[14]
Constructing A Multi-hop
Ho, Xanh and Duong Nguyen, Anh-Khoa and Sugawara, Saku and Aizawa, Akiko , booktitle =. Constructing A Multi-hop
-
[15]
Transactions of the Association for Computational Linguistics (TACL) , volume =
Constructing Datasets for Multi-hop Reading Comprehension Across Documents , author =. Transactions of the Association for Computational Linguistics (TACL) , volume =
-
[16]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
-
[17]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =
Measuring and Narrowing the Compositionality Gap in Language Models , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =
2023
-
[18]
International Conference on Learning Representations (ICLR) , year =
Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval , author =. International Conference on Learning Representations (ICLR) , year =
-
[19]
Demonstrate-Search-Predict: Composing Retrieval and Language Models for Knowledge-Intensive
Khattab, Omar and Santhanam, Keshav and Li, Xiang Lisa and Hall, David and Liang, Percy and Potts, Christopher and Zaharia, Matei , journal =. Demonstrate-Search-Predict: Composing Retrieval and Language Models for Knowledge-Intensive
-
[20]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Active Retrieval Augmented Generation , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
2023
-
[21]
The Probabilistic Relevance Framework:
Robertson, Stephen and Zaragoza, Hugo , journal =. The Probabilistic Relevance Framework:
-
[22]
Sentence-
Reimers, Nils and Gurevych, Iryna , booktitle =. Sentence-
-
[23]
Passage Re-ranking with
Nogueira, Rodrigo and Cho, Kyunghyun , journal =. Passage Re-ranking with
-
[24]
Khattab, Omar and Zaharia, Matei , booktitle =
-
[25]
Xiao, Shitao and Liu, Zheng and Zhang, Peitian and Muennighoff, Niklas and Lian, Defu and Nie, Jian-Yun , booktitle =
-
[26]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , pages =
Muennighoff, Niklas and Tazi, Nouamane and Magne, Lo. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , pages =
-
[27]
Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track , year =
Thakur, Nandan and Reimers, Nils and R. Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track , year =
-
[28]
The Use of
Carbonell, Jaime and Goldstein, Jade , booktitle =. The Use of
-
[29]
Transactions of the Association for Computational Linguistics (TACL) , volume =
Lost in the Middle: How Language Models Use Long Contexts , author =. Transactions of the Association for Computational Linguistics (TACL) , volume =
-
[30]
Xu, Fangyuan and Shi, Weijia and Choi, Eunsol , booktitle =
-
[31]
Jiang, Huiqiang and Wu, Qianhui and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili , booktitle =
-
[32]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Compressing Context to Enhance Inference Efficiency of Large Language Models , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
2023
-
[33]
arXiv preprint arXiv:2311.08377 , year=
Learning to Filter Context for Retrieval-Augmented Generation , author =. arXiv preprint arXiv:2311.08377 , year =
-
[34]
International Conference on Learning Representations (ICLR) , year =
Making Retrieval-Augmented Language Models Robust to Irrelevant Context , author =. International Conference on Learning Representations (ICLR) , year =
-
[35]
Bai, Yushi and Lv, Xin and Zhang, Jiajie and Lyu, Hongchang and Tang, Jiankai and Huang, Zhidian and Du, Zhengxiao and Liu, Xiao and Zeng, Aohan and Hou, Lei and Dong, Yuxiao and Tang, Jie and Li, Juanzi , booktitle =
-
[36]
International Conference on Learning Representations (ICLR) , year =
Retrieval Meets Long Context Large Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[37]
Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (ACL-HLT) , pages =
A Class of Submodular Functions for Document Summarization , author =. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (ACL-HLT) , pages =
-
[38]
Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT) , pages =
Multi-document Summarization via Budgeted Maximization of Submodular Functions , author =. Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT) , pages =
2010
-
[39]
and Wolsey, Laurence A
Nemhauser, George L. and Wolsey, Laurence A. and Fisher, Marshall L. , journal =. An Analysis of Approximations for Maximizing Submodular Set Functions---
-
[40]
Tractability: Practical Approaches to Hard Problems , pages =
Submodular Function Maximization , author =. Tractability: Practical Approaches to Hard Problems , pages =
-
[41]
arXiv preprint arXiv:2202.00132 , year =
Submodularity In Machine Learning and Artificial Intelligence , author =. arXiv preprint arXiv:2202.00132 , year =
-
[42]
arXiv preprint arXiv:2412.15115 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Touvron, Hugo and Martin, Louis and Stone, Kevin and others , journal =
-
[44]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[45]
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , booktitle =
-
[46]
Dettmers, Tim and Lewis, Mike and Belkada, Younes and Zettlemoyer, Luke , booktitle =
-
[47]
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy , booktitle =
-
[48]
Es, Shahul and James, Jithin and Espinosa Anke, Luis and Schockaert, Steven , booktitle =
-
[49]
Saad-Falcon, Jon and Khattab, Omar and Potts, Christopher and Zaharia, Matei , booktitle =
-
[50]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Benchmarking Large Language Models in Retrieval-Augmented Generation , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[51]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , pages =
Petroni, Fabio and Piktus, Aleksandra and Fan, Angela and Lewis, Patrick and Yazdani, Majid and De Cao, Nicola and Thorne, James and Jernite, Yacine and Karpukhin, Vladimir and Maillard, Jean and Plachouras, Vassilis and Rockt. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , pages =
2021
-
[52]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
When Not to Trust Language Models: Investigating the Effectiveness of Parametric and Non-Parametric Memories , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
-
[53]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[54]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =
Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.