Reproducibility in Machine Learning for Health
Pith reviewed 2026-05-25 11:01 UTC · model grok-4.3
The pith
Machine learning for health research shares data and code less often than other machine learning fields.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
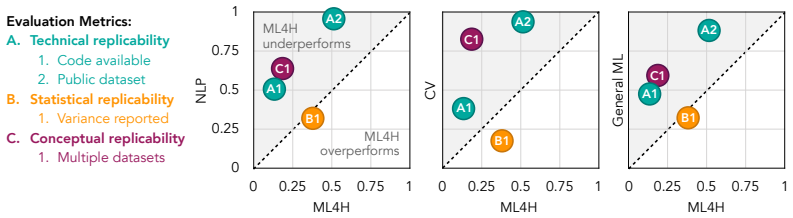
In a systematic evaluation of over 100 recently published ML4H research papers along several dimensions related to reproducibility, the field of ML4H compares poorly to more established machine learning fields, particularly concerning data and code accessibility. Drawing from success in other fields of science, recommendations are proposed to data providers, academic publishers, and the ML4H research community in order to promote reproducible research moving forward.
What carries the argument
Systematic evaluation of over 100 ML4H papers along reproducibility dimensions such as data accessibility and code accessibility.
If this is right
- Higher data and code accessibility would align ML4H reproducibility with levels seen in established machine learning fields.
- Data providers could increase dataset availability to support wider verification of results.
- Academic publishers could adopt policies that require sharing of data and code with publications.
- The ML4H community could implement practices proven effective in other areas of science.
Where Pith is reading between the lines
- Better accessibility practices could support more reliable use of ML models in clinical environments.
- Health data privacy concerns may contribute to the observed gap, suggesting value in exploring secure sharing methods.
- Repeating the evaluation at intervals could track whether the proposed changes produce measurable gains.
Load-bearing premise
The chosen papers form a representative sample of ML4H research and the selected dimensions adequately capture reproducibility.
What would settle it
A review of a different or expanded collection of ML4H papers that finds data and code accessibility rates equal to or higher than those in other machine learning fields.
Figures

read the original abstract
Machine learning algorithms designed to characterize, monitor, and intervene on human health (ML4H) are expected to perform safely and reliably when operating at scale, potentially outside strict human supervision. This requirement warrants a stricter attention to issues of reproducibility than other fields of machine learning. In this work, we conduct a systematic evaluation of over 100 recently published ML4H research papers along several dimensions related to reproducibility. We find that the field of ML4H compares poorly to more established machine learning fields, particularly concerning data and code accessibility. Finally, drawing from success in other fields of science, we propose recommendations to data providers, academic publishers, and the ML4H research community in order to promote reproducible research moving forward.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a systematic evaluation of reproducibility dimensions across over 100 recently published ML4H papers, concluding that ML4H performs worse than other machine learning fields particularly on data and code accessibility, and offers recommendations to data providers, publishers, and the research community.
Significance. If the evaluation is methodologically sound and the sample representative, the result would usefully document reproducibility shortfalls in a high-stakes application area and could help set community standards for data and code release.
major comments (1)
- [Abstract (and Methods section)] The abstract states that a systematic evaluation of over 100 papers was performed along reproducibility dimensions but supplies no information on paper selection criteria, search strategy, inclusion/exclusion rules, scoring rubric, inter-rater agreement, or statistical comparison methods. This information is load-bearing for the central claim that ML4H compares poorly to other fields.
Simulated Author's Rebuttal
We thank the referee for their review and the recommendation for major revision. We address the single major comment below and will revise the manuscript accordingly to improve methodological transparency.
read point-by-point responses
-
Referee: [Abstract (and Methods section)] The abstract states that a systematic evaluation of over 100 papers was performed along reproducibility dimensions but supplies no information on paper selection criteria, search strategy, inclusion/exclusion rules, scoring rubric, inter-rater agreement, or statistical comparison methods. This information is load-bearing for the central claim that ML4H compares poorly to other fields.
Authors: We agree that the abstract would be strengthened by including a concise description of the evaluation methodology. In the revised manuscript we will expand the abstract to briefly note the search strategy (recent publications in ML4H venues), inclusion criteria (papers applying ML to health data), the reproducibility dimensions scored, and the basis for field comparisons. The full Methods section already specifies the paper selection process, databases and keywords used, inclusion/exclusion rules, the detailed scoring rubric for each reproducibility dimension, inter-rater agreement procedures, and the statistical approach for comparisons to other ML fields; we will add explicit cross-references from the abstract and ensure any omitted quantitative details (e.g., exact agreement statistics) are stated clearly. These changes will make the load-bearing methodological information accessible without altering the manuscript's core findings. revision: yes
Circularity Check
No significant circularity: empirical survey with no derivations or fitted claims
full rationale
This paper performs a systematic review of >100 ML4H papers, comparing data/code accessibility to other ML fields and offering recommendations. It contains no equations, no fitted parameters, no predictions derived from inputs, and no self-citation chains used to justify uniqueness or ansatzes. The central claim rests on direct empirical counts from external papers rather than any internal reduction or self-referential construction. Per the hard rules, an empirical survey self-contained against external benchmarks receives score 0 with no steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reproducibility in ML4H can be assessed by checking data accessibility, code accessibility, and related factors across published papers
Reference graph
Works this paper leans on
-
[1]
1,500 scientists lift the lid on reproducibility
Monya Baker. 1,500 scientists lift the lid on reproducibility. Nature News, 533(7604):452, May 2016
work page 2016
-
[2]
Google Tries to Patent Healthcare Deep Learning, EHR Analytics, February 2019
Jennifer Bresnick. Google Tries to Patent Healthcare Deep Learning, EHR Analytics, February 2019
work page 2019
-
[3]
Relabeling internal and external validity for applied social scientists
Donald T Campbell. Relabeling internal and external validity for applied social scientists. New Directions for Program Evaluation, 1986(31):67–77, 1986
work page 1986
-
[4]
Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission
Rich Caruana, Yin Lou, Johannes Gehrke, Paul Koch, Marc Sturm, and Noemie Elhadad. Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1721–1730. ACM, 2015
work page 2015
-
[5]
Retraction rates are on the rise.EMBO reports, 9(1):2–2, January 2008
Murat Cokol, Fatih Ozbay, and Raul Rodriguez-Esteban. Retraction rates are on the rise.EMBO reports, 9(1):2–2, January 2008
work page 2008
-
[6]
Replicability is not Reproducibility : Nor is it Good Science
Chris Drummond. Replicability is not Reproducibility : Nor is it Good Science. Montreal, Canada, 2009
work page 2009
-
[7]
The fienberg problem: How to allow human interactive data analysis in the age of differential privacy
Cynthia Dwork and Jonathan Ullman. The fienberg problem: How to allow human interactive data analysis in the age of differential privacy. Journal of Privacy and Confidentiality, 8, 2018. 6
work page 2018
-
[8]
The Registration of Observational Studies—When Metaphors Go Bad
The Editors. The Registration of Observational Studies—When Metaphors Go Bad. Epidemiol- ogy, 21(5):607, September 2010
work page 2010
-
[9]
Digital Signals in Chronic Pain (DiSCover Project)
Evidation Health. Digital Signals in Chronic Pain (DiSCover Project). Clinical Trial NCT03421223, U.S. National Library of Medicine, February 2018
work page 2018
-
[10]
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumeé III, and Kate Crawford. Datasheets for Datasets. arXiv:1803.09010 [cs], March 2018. arXiv: 1803.09010
-
[11]
Mohammad M. Ghassemi, Benjamin E. Moody, Li-wei H. Lehman, Christopher Song, Qiao Li, Haoqi Sun, Roger G. Mark, M. Brandon Westover, and Gari D. Clifford. You Snooze, You Win: The PhysioNet/Computing in Cardiology Challenge 2018 | Request PDF. In Proceedings of the 2018 Computing in Cardiology, volume 45, page 1, December 2018
work page 2018
-
[12]
Ary L Goldberger, Luis AN Amaral, Leon Glass, Jeffrey M Hausdorff, Plamen Ch Ivanov, Roger G Mark, Joseph E Mietus, George B Moody, Chung-Kang Peng, and H Eugene Stanley. Physiobank, physiotoolkit, and physionet: components of a new research resource for complex physiologic signals. Circulation, 101(23):e215–e220, 2000
work page 2000
-
[13]
Gong, Tristan Naumann, Peter Szolovits, and John V
Jen J. Gong, Tristan Naumann, Peter Szolovits, and John V . Guttag. Predicting Clinical Outcomes Across Changing Electronic Health Record Systems. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’17, pages 1497–1505, New York, NY , USA, 2017. ACM. event-place: Halifax, NS, Canada
work page 2017
-
[14]
System and Method for Predicting and Summarizing Medical Events from Electronic Health Records
Google, Inc., Alexander Mossin, Alvin Rajkomar, Eyal Oren, James Wilson, James Wexler, Patrik Sundberg, Andrew Dai, Yingwei Cui, Gregory Corrado, Hector Yee, Jacob Marcus, Jeffrey Dean, Benjamin Irvine, Kai Chen, Kun Zhang, Michaela Hardt, Xiaomi Sun, Nissan Hajaj, Peter Liu, Quoc Le, Xiaobing Liu, and Yi Zhang. System and Method for Predicting and Summar...
-
[15]
State of the art: Reproducibility in artificial intelligence
Odd Eric Gundersen and Sigbjorn Kjensmo. State of the art: Reproducibility in artificial intelligence. Thirty-Second AAAI Conference on Artificial Intelligence, 2018
work page 2018
-
[16]
The tuh eeg corpus: A big data resource for automated eeg interpretation
A Harati, S Lopez, I Obeid, J Picone, MP Jacobson, and S Tobochnik. The tuh eeg corpus: A big data resource for automated eeg interpretation. In 2014 IEEE Signal Processing in Medicine and Biology Symposium (SPMB), pages 1–5. IEEE, 2014
work page 2014
-
[17]
Reproducible Survival Prediction with SEER Cancer Data
Stefan Hegselmann, Leonard Gruelich, Julian Varghese, and Martin Dugas. Reproducible Survival Prediction with SEER Cancer Data. In Machine Learning for Healthcare Conference, pages 49–66, November 2018
work page 2018
-
[18]
Deep Reinforcement Learning that Matters
Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. Deep Reinforcement Learning that Matters. arXiv:1709.06560 [cs, stat], September
work page internal anchor Pith review Pith/arXiv arXiv
- [19]
-
[20]
George Hripcsak, Jon D Duke, Nigam H Shah, Christian G Reich, V ojtech Huser, Martijn J Schuemie, Marc A Suchard, Rae Woong Park, Ian Chi Kei Wong, Peter R Rijnbeek, et al. Observational health data sciences and informatics (ohdsi): opportunities for observational researchers. Studies in health technology and informatics, 216:574, 2015
work page 2015
-
[21]
Reproducible, Reusable, and Robust Reinforcement Learning, December 2018
Joelle Pineau. Reproducible, Reusable, and Robust Reinforcement Learning, December 2018
work page 2018
-
[22]
Alistair E. W. Johnson, Tom J. Pollard, and Tristan Naumann. Generalizability of predictive models for intensive care unit patients. In arXiv:1812.02275 [cs, stat] , Montreal, Canada, December 2018. arXiv: 1812.02275
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[23]
Alistair E. W. Johnson, Tom J. Pollard, Lu Shen, Li-wei H. Lehman, Mengling Feng, Moham- mad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G. Mark. MIMIC-III, a freely accessible critical care database. Scientific Data, 3:160035, May 2016
work page 2016
-
[24]
Reproducibility in critical care: a mortality prediction case study
Alistair EW Johnson, Tom J Pollard, and Roger G Mark. Reproducibility in critical care: a mortality prediction case study. In Machine Learning for Healthcare Conference , pages 361–376, 2017
work page 2017
-
[25]
Mimic-iii, a freely accessible critical care database
Alistair EW Johnson, Tom J Pollard, Lu Shen, H Lehman Li-wei, Mengling Feng, Mohammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. Mimic-iii, a freely accessible critical care database. Scientific data, 3:160035, 2016. 7
work page 2016
-
[26]
Should protocols for observational research be registered? The Lancet , 375(9712):348, January 2010
The Lancet. Should protocols for observational research be registered? The Lancet , 375(9712):348, January 2010
work page 2010
-
[27]
Timothy L. Lash and Jan P. Vandenbroucke. Commentary: Should Preregistration of Epidemio- logic Study Protocols Become Compulsory? Reflections and a Counterproposal. Epidemiology, 23(2):184–188, 2012
work page 2012
-
[28]
Tesla fatal crash: ’autopilot’ mode sped up car before driver killed, report finds
Sam Levin. Tesla fatal crash: ’autopilot’ mode sped up car before driver killed, report finds. The Guardian, June 2018
work page 2018
-
[29]
Registration of observational studies
Elizabeth Loder, Trish Groves, and Domhnall MacAuley. Registration of observational studies. BMJ, 340:c950, February 2010
work page 2010
-
[30]
Are GANs Created Equal? A Large-Scale Study
Mario Lucic, Karol Kurach, Marcin Michalski, Sylvain Gelly, and Olivier Bousquet. Are GANs Created Equal? A Large-Scale Study. arXiv:1711.10337 [cs, stat], November 2017. arXiv: 1711.10337
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
On the State of the Art of Evaluation in Neural Language Models
Gábor Melis, Chris Dyer, and Phil Blunsom. On the State of the Art of Evaluation in Neural Language Models. arXiv:1707.05589 [cs], July 2017. arXiv: 1707.05589
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Roundup: 12 healthcare algorithms cleared by the FDA, November 2018
Dave Muoio. Roundup: 12 healthcare algorithms cleared by the FDA, November 2018
work page 2018
-
[33]
Overview of the biobank japan project: study design and profile
Akiko Nagai, Makoto Hirata, Yoichiro Kamatani, Kaori Muto, Koichi Matsuda, Yutaka Kiy- ohara, Toshiharu Ninomiya, Akiko Tamakoshi, Zentaro Yamagata, Taisei Mushiroda, et al. Overview of the biobank japan project: study design and profile. Journal of epidemiology, 27(Supplement_III):S2–S8, 2017
work page 2017
- [34]
-
[35]
Bret Nestor, Matthew B. A. McDermott, Geeticka Chauhan, Tristan Naumann, Michael C. Hughes, Anna Goldenberg, and Marzyeh Ghassemi. Rethinking clinical prediction: Why machine learning must consider year of care and feature aggregation. Montreal, Canada, November 2018. arXiv: 1811.12583
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Validation of a common data model for active safety surveillance research
J Marc Overhage, Patrick B Ryan, Christian G Reich, Abraham G Hartzema, and Paul E Stang. Validation of a common data model for active safety surveillance research. Journal of the American Medical Informatics Association : JAMIA, 19(1):54–60, 2012
work page 2012
-
[37]
Regulation of predictive analytics in medicine
Ravi B Parikh, Ziad Obermeyer, and Amol S Navathe. Regulation of predictive analytics in medicine. Science, 363(6429):810–812, 2019
work page 2019
-
[38]
External validity: From do-calculus to transportability across populations
Judea Pearl, Elias Bareinboim, et al. External validity: From do-calculus to transportability across populations. Statistical Science, 29(4):579–595, 2014
work page 2014
-
[39]
Hans E. Plesser. Reproducibility vs. Replicability: A Brief History of a Confused Terminology. Frontiers in Neuroinformatics, 11, January 2018
work page 2018
-
[40]
Tom J. Pollard, Alistair E. W. Johnson, Jesse D. Raffa, Leo A. Celi, Roger G. Mark, and Omar Badawi. The eICU Collaborative Research Database, a freely available multi-center database for critical care research. Scientific Data, 5:180178, September 2018
work page 2018
-
[41]
Dai, Nissan Hajaj, Michaela Hardt, Peter J
Alvin Rajkomar, Eyal Oren, Kai Chen, Andrew M. Dai, Nissan Hajaj, Michaela Hardt, Peter J. Liu, Xiaobing Liu, Jake Marcus, Mimi Sun, Patrik Sundberg, Hector Yee, Kun Zhang, Yi Zhang, Gerardo Flores, Gavin E. Duggan, Jamie Irvine, Quoc Le, Kurt Litsch, Alexander Mossin, Justin Tansuwan, De Wang, James Wexler, Jimbo Wilson, Dana Ludwig, Samuel L. V olchenbo...
work page 2018
-
[42]
Do CIFAR-10 Classifiers Generalize to CIFAR-10?
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do ImageNet Clas- sifiers Generalize to ImageNet? arXiv:1806.00451 [cs, stat], June 2018. arXiv: 1806.00451
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
Annotating longitudinal clinical narratives for de- identification: The 2014 i2b2/UTHealth corpus
Amber Stubbs and Özlem Uzuner. Annotating longitudinal clinical narratives for de- identification: The 2014 i2b2/UTHealth corpus. Journal of Biomedical Informatics , 58 Suppl:S20–29, December 2015
work page 2014
-
[44]
Cathie Sudlow, John Gallacher, Naomi Allen, Valerie Beral, Paul Burton, John Danesh, Paul Downey, Paul Elliott, Jane Green, Martin Landray, et al. Uk biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS medicine, 12(3):e1001779, 2015. 8
work page 2015
-
[45]
Nicole A. Vasilevsky, Matthew H. Brush, Holly Paddock, Laura Ponting, Shreejoy J. Tripathy, Gregory M. LaRocca, and Melissa A. Haendel. On the reproducibility of science: unique identification of research resources in the biomedical literature. PeerJ, 1:e148, September 2013
work page 2013
-
[46]
Split learning for health: Distributed deep learning without sharing raw patient data
Praneeth Vepakomma, Otkrist Gupta, Tristan Swedish, and Ramesh Raskar. Split learn- ing for health: Distributed deep learning without sharing raw patient data. arXiv preprint arXiv:1812.00564, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [47]
-
[48]
Jason Walonoski, Mark Kramer, Joseph Nichols, Andre Quina, Chris Moesel, Dylan Hall, Carlton Duffett, Kudakwashe Dube, Thomas Gallagher, and Scott McLachlan. Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic electronic health care record. Journal of the American Medical Informatics Association , 25(3)...
work page 2018
-
[49]
Rebecca J. Williams, Tony Tse, William R. Harlan, and Deborah A. Zarin. Registration of observational studies: Is it time? CMAJ : Canadian Medical Association Journal, 182(15):1638– 1642, October 2010
work page 2010
-
[50]
Improving Patient Care with Machine Learning At Beth Israel Deaconess Medical Center, March 2019
Matt Wood. Improving Patient Care with Machine Learning At Beth Israel Deaconess Medical Center, March 2019
work page 2019
-
[51]
Fair Regression for Health Care Spending
Anna Zink and Sherri Rose. Fair Regression for Health Care Spending. arXiv:1901.10566 [cs, stat], January 2019. arXiv: 1901.10566. Appendix: Statistical Review Procedures Selection Criteria Papers were selected at random, to ensure an unbiased sample, from various venues associated with different domains (though papers were tagged with their content-drive...
-
[52]
What datasets were used?
-
[53]
Are these datasets publicly available (modulo data use agreements)?
-
[54]
Do the authors report any notion of variance around their results or assess their comparisons to baselines in a statistically robust fashion (e.g., via hypothesis testing)? Potential Biases This selection and annotation procedure allowed us to analyze a large number of papers, but has several possible biases. In particular, our annotation questions were a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.