EgoPriMo: Egocentric Motion Generation for Interactive Humanoid Control
Pith reviewed 2026-06-27 18:35 UTC · model grok-4.3
The pith
A single checkpoint reconstructs, generates, and forecasts full-body SMPL motions from egocentric video and text for humanoid control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
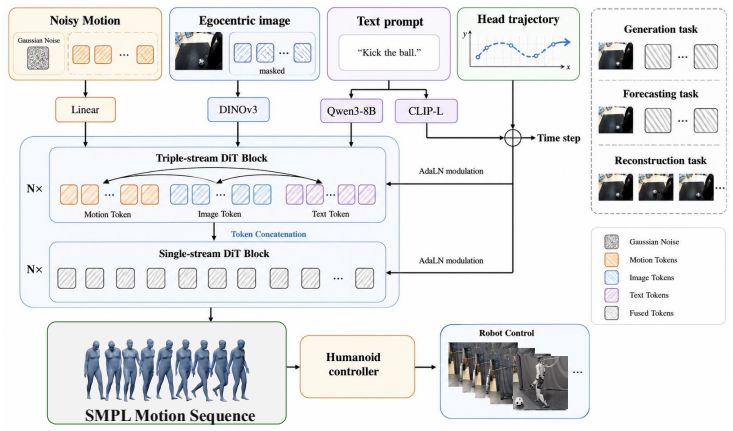
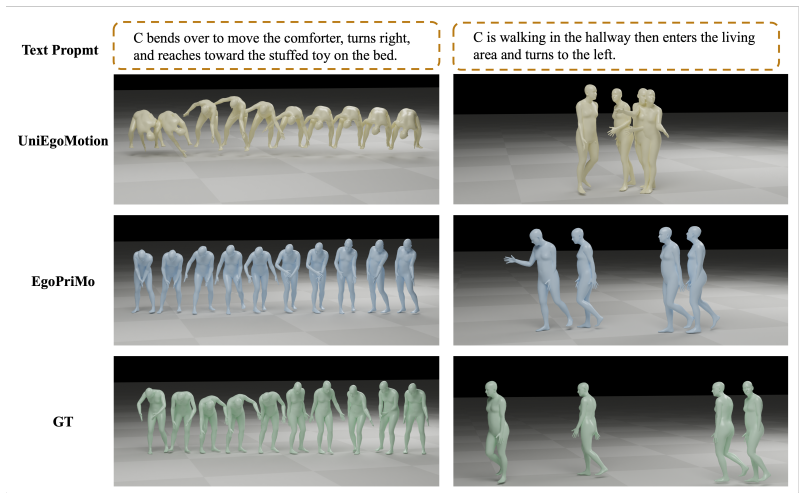
EgoPriMo is a unified framework that learns motion priors from egocentric human demonstrations. Given egocentric observations and a text prompt, it reconstructs, generates, and forecasts SMPL-based full-body motion. At its core is a Triple-stream DiT that jointly models body dynamics, egocentric visual context, and text, with task-conditioning masks routing different tasks and missing-modality data through the same checkpoint. Experiments on Nymeria and EgoExo4D show one checkpoint improves egocentric motion generation over UniEgoMotion while supporting reconstruction and forecasting, and the generated SMPL motions execute on a Unitree humanoid controller.
What carries the argument
Triple-stream DiT jointly modeling body dynamics, egocentric visual context, and text, with task-conditioning masks that route tasks and missing data through one checkpoint.
If this is right
- One checkpoint improves egocentric motion generation over UniEgoMotion on the tested datasets.
- The same checkpoint supports reconstruction and forecasting tasks without retraining.
- Generated SMPL motions transfer to execution on a physical Unitree humanoid controller.
- Language serves as a high-level rather than exhaustive control signal for motion.
Where Pith is reading between the lines
- The approach could allow robots to switch between motion tasks on the fly in response to changing user text prompts without reloading models.
- Retargeting the SMPL outputs to different robot morphologies might extend the prior beyond the Unitree platform tested.
- Adding more input modalities such as depth or audio could be tested by extending the existing mask mechanism rather than redesigning the architecture.
Load-bearing premise
Task-conditioning masks can route different tasks and missing-modality data through the same model checkpoint without significant degradation in performance for each individual task.
What would settle it
Train separate specialized models for reconstruction, generation, and forecasting on Nymeria and EgoExo4D, then compare each to the single EgoPriMo checkpoint; if any specialized model outperforms the unified one by a clear margin on its target task, the unified-checkpoint claim is falsified.
Figures


read the original abstract
Humanoid robots require whole-body motions that adapt to scene context, task requirements, and user intent. Motion tracking reproduces specified trajectories, and humanoid vision-language-action systems provide semantic interfaces, but neither offers a scalable and interactive prior for broad full-body behavior. We introduce EgoPriMo (Egocentric Motion Prior for Humanoid Robots), a unified framework that learns such priors from egocentric human demonstrations. Given egocentric observations and a text prompt, EgoPriMo reconstructs, generates, and forecasts SMPL-based full-body motion. Language is used as a high-level control signal rather than a complete motion specification. At the core of EgoPriMo is a Triple-stream DiT that jointly models body dynamics, egocentric visual context, and text; task-conditioning masks route different tasks and missing-modality data through the same checkpoint. Experiments on Nymeria and EgoExo4D show that one checkpoint improves egocentric motion generation over UniEgoMotion while supporting reconstruction and forecasting; the generated SMPL motions can also be executed by a Unitree humanoid controller. These results indicate a practical path from scalable egocentric observations to generalizable and interactive humanoid motion priors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EgoPriMo, a unified framework for learning egocentric motion priors from human demonstrations. It uses a Triple-stream DiT jointly modeling body dynamics, egocentric visuals, and text, with task-conditioning masks to route reconstruction, generation, forecasting, and missing-modality inputs through a single checkpoint. Experiments on Nymeria and EgoExo4D claim that this checkpoint outperforms UniEgoMotion on generation while supporting the other tasks, with generated SMPL motions executable on a Unitree humanoid controller.
Significance. If the multi-task masking mechanism holds without degradation, the work would provide a scalable, interactive prior for humanoid whole-body control from egocentric data, moving beyond separate tracking or VLA systems. The use of public datasets (Nymeria, EgoExo4D) and hardware transfer to Unitree are concrete strengths that support reproducibility and practical relevance.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: The central claim that 'one checkpoint improves egocentric motion generation over UniEgoMotion while supporting reconstruction and forecasting' rests on task-conditioning masks enabling joint training without measurable interference. No per-task quantitative breakdown, no ablation removing the masks, and no comparison of the unified model versus separately trained task-specific models on identical data splits are reported; this leaves the 'one checkpoint' advantage unsubstantiated.
- [Method] Method section (Triple-stream DiT description): The task-conditioning masks are presented as routing different tasks and missing modalities, but the manuscript provides no analysis of how mask design affects information flow across streams or any quantitative measure of specialization loss when multiple tasks share parameters.
- [Hardware transfer] Hardware transfer paragraph: The claim that generated SMPL motions 'can also be executed by a Unitree humanoid controller' is load-bearing for the interactive humanoid application, yet no mapping details, success rates, or comparison to baseline controllers are supplied to confirm executability beyond qualitative assertion.
minor comments (2)
- [Method] Notation for the three streams (body, visual, text) should be defined explicitly with consistent symbols when first introduced.
- [Experiments] Dataset splits and exact metrics (e.g., MPJPE, FID) used for the UniEgoMotion comparison should be stated clearly in the Experiments section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, clarifying the current evidence and committing to revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The central claim that 'one checkpoint improves egocentric motion generation over UniEgoMotion while supporting reconstruction and forecasting' rests on task-conditioning masks enabling joint training without measurable interference. No per-task quantitative breakdown, no ablation removing the masks, and no comparison of the unified model versus separately trained task-specific models on identical data splits are reported; this leaves the 'one checkpoint' advantage unsubstantiated.
Authors: We acknowledge that the manuscript does not include per-task quantitative breakdowns, ablations removing the task-conditioning masks, or direct comparisons against separately trained task-specific models on the same data splits. The reported results demonstrate that the unified checkpoint outperforms UniEgoMotion on generation while supporting the other tasks, but these additional analyses would more rigorously substantiate the lack of interference. We will add the requested per-task metrics, mask ablations, and task-specific model comparisons in the revised manuscript. revision: yes
-
Referee: [Method] Method section (Triple-stream DiT description): The task-conditioning masks are presented as routing different tasks and missing modalities, but the manuscript provides no analysis of how mask design affects information flow across streams or any quantitative measure of specialization loss when multiple tasks share parameters.
Authors: The manuscript presents the task-conditioning masks primarily through their empirical utility in enabling multi-task and missing-modality operation within the Triple-stream DiT. No explicit analysis of information flow or specialization loss is provided. We will expand the method section with additional discussion of mask design effects and any available quantitative measures of task specialization in the revision. revision: yes
-
Referee: [Hardware transfer] Hardware transfer paragraph: The claim that generated SMPL motions 'can also be executed by a Unitree humanoid controller' is load-bearing for the interactive humanoid application, yet no mapping details, success rates, or comparison to baseline controllers are supplied to confirm executability beyond qualitative assertion.
Authors: The hardware transfer is included as a qualitative demonstration that SMPL motions from EgoPriMo are executable on the Unitree platform. We agree that mapping details, success rates, and baseline controller comparisons are needed to strengthen the claim. We will incorporate these quantitative elements and implementation specifics in the revised version. revision: yes
Circularity Check
No significant circularity; claims rest on empirical evaluation
full rationale
The paper introduces a Triple-stream DiT model with task-conditioning masks and asserts performance via experiments on public datasets Nymeria and EgoExo4D, including comparison to UniEgoMotion and execution on a Unitree controller. No derivation chain, equations, or first-principles results are presented that reduce to inputs by construction. No self-citations, fitted parameters renamed as predictions, or self-definitional steps appear in the abstract or described structure. The multi-task routing via masks is a modeling choice whose effectiveness is claimed through external benchmarks rather than tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- model parameters
axioms (1)
- domain assumption SMPL model accurately represents human body motions for transfer to humanoid robots
invented entities (1)
-
Triple-stream DiT
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Z. Fu, Q. Zhao, Q. Wu, G. Wetzstein, and C. Finn. Humanplus: Humanoid shadowing and imitation from humans.arXiv preprint arXiv:2406.10454, 2024
arXiv 2024
-
[2]
T. He, Z. Luo, X. He, W. Xiao, C. Zhang, W. Zhang, K. Kitani, C. Liu, and G. Shi. Om- nih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning. InConference on Robot Learning, 2024. arXiv:2406.08858
arXiv 2024
- [3]
-
[4]
T. He, W. Xiao, T. Lin, Z. Luo, Z. Xu, Z. Jiang, J. Kautz, C. Liu, G. Shi, X. Wang, L. Fan, and Y . Zhu. Hover: Versatile neural whole-body controller for humanoid robots.arXiv preprint arXiv:2410.21229, 2024
arXiv 2024
-
[5]
T. He, J. Gao, W. Xiao, Y . Zhang, Z. Wang, J. Wang, Z. Luo, G. He, N. Sobanbab, C. Pan, Z. Yi, G. Qu, K. Kitani, J. Hodgins, L. Fan, Y . Zhu, C. Liu, and G. Shi. Asap: Aligning simulation and real-world physics for learning agile humanoid whole-body skills. InRobotics: Science and Systems, 2025. arXiv:2502.01143
arXiv 2025
-
[6]
S. Yin, Y . Ze, H.-X. Yu, C. K. Liu, and J. Wu. Visualmimic: Visual humanoid loco- manipulation via motion tracking and generation.arXiv preprint arXiv:2509.20322, 2025
arXiv 2025
-
[7]
Z. Luo, Y . Yuan, T. Wang, C. Li, S. Chen, F. Casta ˜neda, Z.-A. Cao, J. Li, D. Minor, Q. Ben, X. Da, R. Ding, C. Hogg, L. Song, E. Lim, E. Jeong, T. He, H. Xue, W. Xiao, Z. Wang, S. Yuen, J. Kautz, Y . Chang, U. Iqbal, L. Fan, and Y . Zhu. Sonic: Supersizing motion tracking for natural humanoid whole-body control.arXiv preprint arXiv:2511.07820, 2025. 9
Pith/arXiv arXiv 2025
-
[8]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[9]
R. Yang, Q. Yu, Y . Wu, R. Yan, B. Li, A.-C. Cheng, X. Zou, Y . Fang, X. Cheng, R.-Z. Qiu, H. Yin, S. Liu, S. Han, Y . Lu, and X. Wang. Egovla: Learning vision-language-action models from egocentric human videos.arXiv preprint arXiv:2507.12440, 2025
Pith/arXiv arXiv 2025
-
[10]
J. Yu, Y . Shentu, D. Wu, P. Abbeel, K. Goldberg, and P. Wu. Egomi: Learning active vi- sion and whole-body manipulation from egocentric human demonstrations.arXiv preprint arXiv:2511.00153, 2025
arXiv 2025
-
[11]
Grauman, A
K. Grauman, A. Westbury, L. Torresani, K. M. Kitani, J. Malik, T. Afouras, K. Ashutosh, V . Baiyya, S. Bansal, B. Boote, et al. Ego-exo4d: Understanding skilled human activity from first- and third-person perspectives.International Journal of Computer Vision, 2024
2024
-
[12]
L. Ma, Y . Ye, F. Hong, V . Guzov, Y . Jiang, R. Postyeni, L. Pesqueira, A. Gamino, V . Baiyya, H. J. Kim, K. Bailey, D. Soriano Fosas, C. K. Liu, Z. Liu, J. Engel, R. De Nardi, and R. New- combe. Nymeria: A massive collection of multimodal egocentric daily motion in the wild. European Conference on Computer Vision, 2024. arXiv:2406.09905
arXiv 2024
-
[13]
J. Li, C. K. Liu, and J. Wu. Ego-body pose estimation via ego-head pose estimation.arXiv preprint arXiv:2212.04636, 2023
arXiv 2023
- [14]
-
[15]
K. K. Somasundaram, J. Dong, H. Tang, J. Straub, M. Yan, M. Goesele, J. J. Engel, R. De Nardi, and R. A. Newcombe. Project aria: A new tool for egocentric multi-modal ai research.arXiv preprint arXiv:2308.13561, 2023
Pith/arXiv arXiv 2023
-
[16]
Zhang, Q
S. Zhang, Q. Ma, Y . Zhang, Z. Qian, T. Kwon, M. Pollefeys, F. Bogo, and S. Tang. Egobody: Human body shape and motion of interacting people from head-mounted devices. InEuropean Conference on Computer Vision, 2022
2022
-
[17]
C. Guo, S. Zou, X. Zuo, S. Wang, W. Ji, X. Li, and L. Cheng. Generating diverse and natu- ral 3d human motions from text. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[18]
Petrovich, M
M. Petrovich, M. J. Black, and G. Varol. TEMOS: Generating diverse human motions from textual descriptions. InEuropean Conference on Computer Vision, 2022
2022
-
[19]
Tevet, S
G. Tevet, S. Raab, B. Gordon, Y . Shafir, D. Cohen-Or, and A. H. Bermano. Human motion diffusion model. InInternational Conference on Learning Representations, 2023
2023
- [20]
-
[21]
Zhang, Y
J. Zhang, Y . Zhang, X. Cun, Y . Zhang, H. Zhao, H. Lu, X. Shen, and Y . Shan. Generating hu- man motion from textual descriptions with discrete representations. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[22]
X. Chen, B. Jiang, W. Liu, Z. Huang, B. Fu, T. Chen, and G. Yu. Executing your commands via motion diffusion in latent space. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[23]
Petrovich, M
M. Petrovich, M. J. Black, and G. Varol. Tmr: Text-to-motion retrieval using contrastive 3d human motion synthesis. InIEEE/CVF International Conference on Computer Vision, 2023. 10
2023
- [24]
- [25]
-
[26]
L. X. Shi, Z. Hu, T. Z. Zhao, A. Sharma, K. Pertsch, J. Luo, S. Levine, and C. Finn. Yell at your robot: Improving on-the-fly from language corrections.arXiv preprint arXiv:2403.12910, 2024
arXiv 2024
-
[27]
Z. Yang, M. Jun, J. Tien, S. Russell, A. Dragan, and E. Bıyık. Trajectory improvement and reward learning from comparative language feedback. InConference on Robot Learning, 2024. arXiv:2410.06401
arXiv 2024
- [28]
-
[29]
Loper, N
M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black. SMPL: A skinned multi- person linear model.ACM Transactions on Graphics, 34(6):248:1–248:16, 2015
2015
-
[30]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023
2023
-
[31]
J. Su, Y . Lu, S. Pan, A. Murtadha, B. Wen, and Y . Liu. Roformer: Enhanced transformer with rotary position embedding.arXiv preprint arXiv:2104.09864, 2021. 11
Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.