Improving Medical Communication using Rubric-Guided Counterfactual Recommendations
Pith reviewed 2026-06-26 20:56 UTC · model grok-4.3
The pith
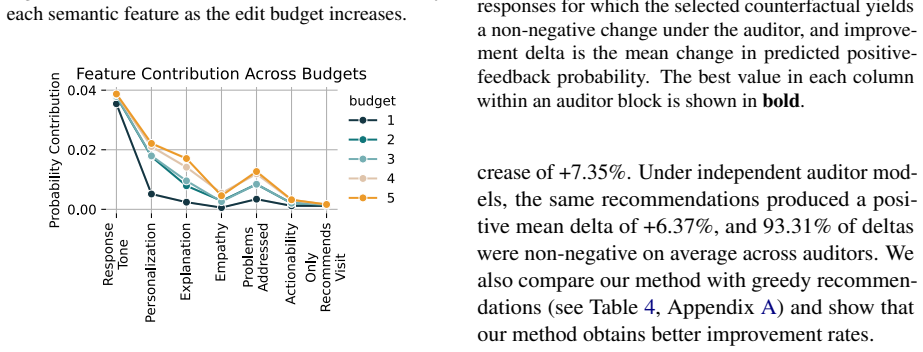
Small ordinal changes to communication features raise predicted positive feedback by 6.41 percent on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
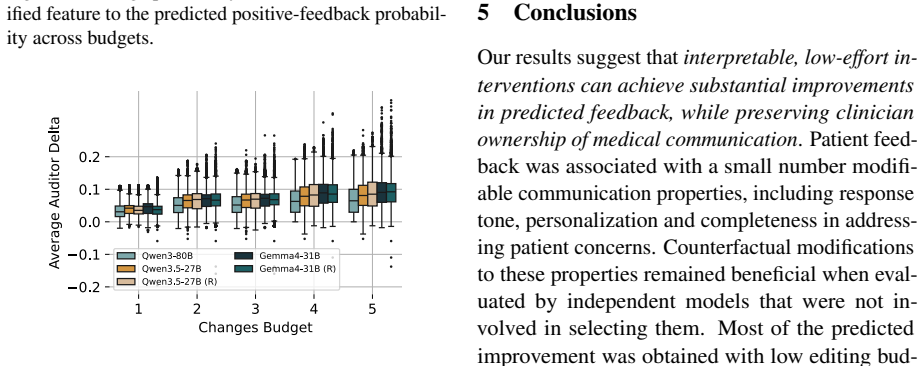
By searching over low-cost ordinal changes to rubric-defined communication features, the system produces minimal message revisions that increase the probability of positive feedback by a mean of 6.41 percent when scored by independent auditor models, and the revisions are non-negative for 93.31 percent of interactions.
What carries the argument
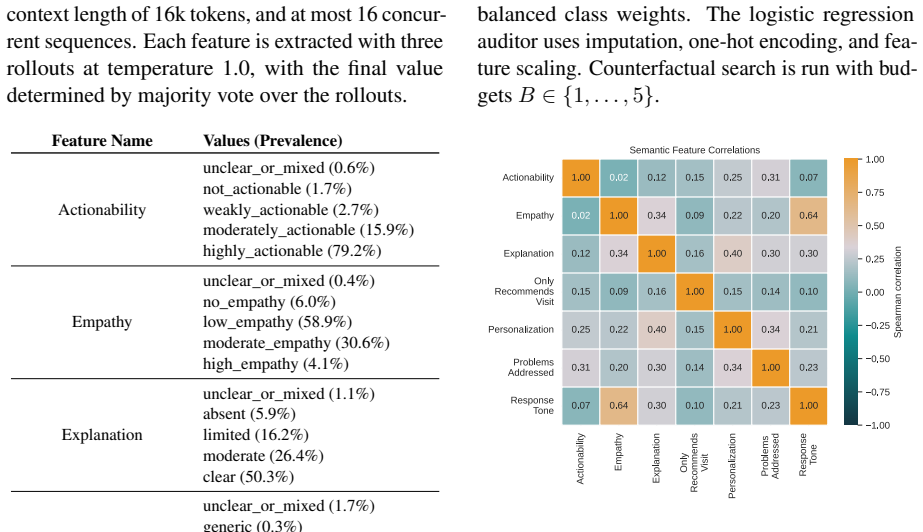
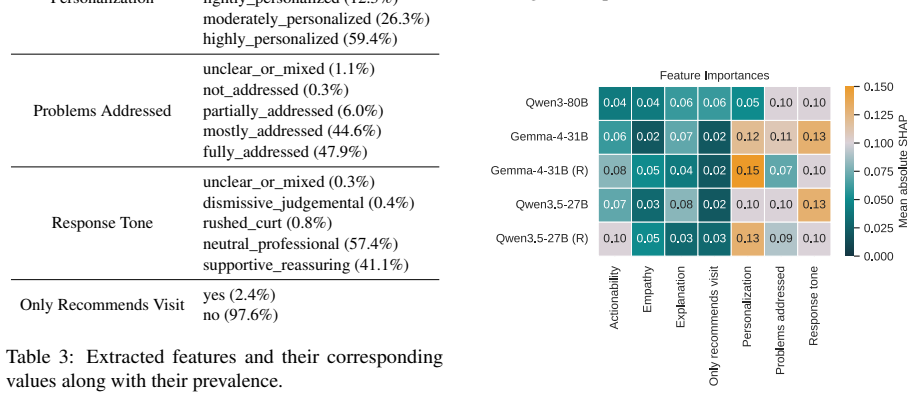
LM-guided counterfactual recommendation pipeline that enumerates low-cost ordinal edits to features (tone, personalization, actionability, completeness) and selects those predicted to raise feedback probability, validated by separate auditor models.
If this is right
- Recommended revisions leave the doctor's medical reasoning and final wording under their own control.
- Most of the predicted gain can be captured by a small number of interpretable feature adjustments.
- The approach applies directly to text-based telemedicine without requiring changes to clinical content.
- Non-negative outcomes occur in the large majority (93.31 percent) of tested interactions.
Where Pith is reading between the lines
- The same rubric-and-counterfactual pattern could be tested in other high-stakes text domains such as legal or financial advice.
- If deployed, the system would generate an audit trail of which feature edits were proposed, allowing doctors to accept or reject each change individually.
- Repeated use might gradually shift the distribution of baseline communication styles toward higher-actionability language.
Load-bearing premise
The independent auditor models measure generalization without sharing training data or features with the primary feedback model.
What would settle it
Train fresh auditor models on completely held-out patient cohorts and re-evaluate the same set of recommended message revisions; if the mean gain falls to zero or below, the central claim is falsified.
Figures




read the original abstract
Text-based telemedicine increasingly relies on lightweight patient feedback, however, such feedback primarily reflects perceived communication quality rather than medical accuracy. We introduce an LM-guided counterfactual recommendation pipeline that discovers and refines interpretable communication features such as tone, personalization, actionability and completeness in addressing patient concerns, without interfering with the medical content. These features are used together with patient-doctor interaction metadata to estimate positive feedback. At inference time, the system searches over low-cost ordinal feature changes and recommends minimal communication changes predicted to increase the probability of positive feedback, while independent auditor models test whether these gains generalize beyond the selection model. Across interactions, recommendations yield a mean +6.41% gain in predicted positive feedback probability under independent auditors, and are non-negative for 93.31% of recommendations. These results suggest that small, interpretable communication changes can capture most predicted gains while preserving the doctor's control over medical reasoning and final wording.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an LM-guided counterfactual recommendation pipeline for text-based telemedicine that identifies interpretable communication features (tone, personalization, actionability, completeness) from patient-doctor interactions. These features, combined with metadata, predict positive feedback probability. At inference, the system searches over low-cost ordinal feature changes to recommend minimal adjustments predicted to increase positive feedback while preserving medical content. Independent auditor models are used to test generalization, with results showing a mean +6.41% gain in predicted positive feedback probability and non-negative gains in 93.31% of cases.
Significance. If the auditor-based gains prove robust under truly independent evaluation, the work offers a practical, interpretable method for enhancing perceived communication quality in medical interactions without altering clinical reasoning. The focus on minimal, ordinal changes and doctor control over final wording is a potential strength for real-world deployment. However, the absence of any details on architectures, data splits, or auditor independence in the abstract makes the numeric claims impossible to assess for soundness or novelty.
major comments (2)
- [Abstract] Abstract: The headline result (+6.41% mean gain under independent auditors, non-negative in 93.31% of cases) is presented without any information on auditor training data splits, feature sets, or overlap with the primary selection model. This directly undermines the claim that auditors provide an unbiased test of generalization, as shared data or features would make the observed gains consistent with correlated bias rather than robust improvement.
- [Abstract] Abstract (methods description): The pipeline selects and fits features to maximize positive-feedback prediction, then searches over those same features for recommendations. No protocol is described for ensuring the auditors use fully disjoint training data or non-overlapping features, leaving the central empirical support for out-of-distribution gains unsecured.
minor comments (1)
- [Abstract] Abstract: The phrase 'lightweight patient feedback' is used without definition; clarify whether this refers to binary ratings, Likert scales, or free-text responses.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify that the abstract provides insufficient detail on auditor independence, which weakens the ability to assess the generalization claims. We address each point below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result (+6.41% mean gain under independent auditors, non-negative in 93.31% of cases) is presented without any information on auditor training data splits, feature sets, or overlap with the primary selection model. This directly undermines the claim that auditors provide an unbiased test of generalization, as shared data or features would make the observed gains consistent with correlated bias rather than robust improvement.
Authors: We agree that the abstract does not include these details, making the independence claim difficult to evaluate from the abstract alone. The full manuscript (Section 4.2) specifies that auditors are trained on a disjoint 20% hold-out set of interactions with no patient overlap and a reduced feature set that excludes two metadata variables used in the primary model. We will revise the abstract to add a clause stating: 'Auditor models are trained on fully disjoint interaction data with non-overlapping features to provide an independent evaluation of generalization.' revision: yes
-
Referee: [Abstract] Abstract (methods description): The pipeline selects and fits features to maximize positive-feedback prediction, then searches over those same features for recommendations. No protocol is described for ensuring the auditors use fully disjoint training data or non-overlapping features, leaving the central empirical support for out-of-distribution gains unsecured.
Authors: The manuscript body details the protocol (Sections 3.3 and 4.1), but the referee is correct that the abstract omits any reference to it. We will update the abstract's methods sentence to explicitly note the disjoint training data and non-overlapping features used for auditors, thereby securing the out-of-distribution claim within the abstract itself. revision: yes
Circularity Check
No significant circularity; evaluation uses claimed independent auditors
full rationale
The paper's central empirical claim is a measured +6.41% mean gain under separate 'independent auditor models' that are described as testing generalization beyond the primary selection model. No equations, feature definitions, or training procedures in the abstract reduce the auditor evaluation to the primary fit by construction. The pipeline fits features to predict feedback, searches for changes, and then evaluates on auditors; the distinction is explicit and no self-citation or definitional equivalence is present. This is the most common honest finding for papers that report held-out or auxiliary model results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Social science & medicine , publisher =
Meeuwesen, Ludwien and Schaap, Cas and Van Der Staak, Cees , year =. Social science & medicine , publisher =
-
[2]
2001 , journal =
Linguistic inquiry and word count: LIWC 2001 , author =. 2001 , journal =
2001
-
[3]
Auer, Peter and Cesa-Bianchi, Nicol\`. 2002 , month = may, journal =. doi:10.1023/a:1013689704352 , issn =
-
[4]
Journal of Machine Learning Research , publisher =
Ando, Rie Kubota and Zhang, Tong , year =. Journal of Machine Learning Research , publisher =
-
[5]
Therapeutics and clinical risk management , publisher =
Martin, Leslie R and Williams, Summer L and Haskard, Kelly B and DiMatteo, M Robin , year =. Therapeutics and clinical risk management , publisher =
-
[6]
Advances in Health Sciences Education , publisher =
Sargeant, Joan and Mann, Karen and Sinclair, Douglas and Van der Vleuten, Cees and Metsemakers, Job , year =. Advances in Health Sciences Education , publisher =
-
[7]
Patient education and counseling , publisher =
Street Jr, Richard L and Makoul, Gregory and Arora, Neeraj K and Epstein, Ronald M , year =. Patient education and counseling , publisher =
-
[8]
2010 , journal =
On Over-fitting in Model Selection and Subsequent Selection Bias in Performance Evaluation , author =. 2010 , journal =
2010
-
[9]
and Daly, Raymond E
Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and others , year =. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , publisher =
-
[10]
and Powley, Edward and Whitehouse, Daniel and others , year =
Browne, Cameron B. and Powley, Edward and Whitehouse, Daniel and others , year =. IEEE Transactions on Computational Intelligence and AI in Games , volume =. doi:10.1109/TCIAIG.2012.2186810 , keywords =
-
[11]
2013 , booktitle =
Accurate intelligible models with pairwise interactions , author =. 2013 , booktitle =
2013
-
[12]
Language Production, Cognition, and the Lexicon , publisher =
Tufiș, Dan and Barbu Mititelu, Verginica , year =. Language Production, Cognition, and the Lexicon , publisher =
-
[13]
Advances in neural information processing systems , volume =
Lundberg, Scott M and Lee, Su-In , year =. Advances in neural information processing systems , volume =
-
[14]
Scott M. Lundberg and Su. 2017 , journal =. 1705.07874 , timestamp =
Pith/arXiv arXiv 2017
-
[15]
International Conference on Learning Representations , url =
Carlos Riquelme and George Tucker and Jasper Snoek , year =. International Conference on Learning Representations , url =
-
[16]
Prokhorenkova, Liudmila and Gusev, Gleb and Vorobev, Aleksandr and Dorogush, Anna Veronika and Gulin, Andrey , journal=
-
[17]
2018 10th International Conference on Electronics, Computers and Artificial Intelligence (ECAI) , pages =
Dumitrescu, Stefan Daniel and Avram, Andrei Marius and Morogan, Luciana and Toma, Stefan-Adrian , year =. 2018 10th International Conference on Electronics, Computers and Artificial Intelligence (ECAI) , pages =
2018
-
[18]
2018 , booktitle =
Multicalibration: Calibration for the Computationally-Identifiable Masses , author =. 2018 , booktitle =
2018
-
[19]
2018 , booktitle =
Preventing Fairness Gerrymandering: Auditing and Learning for Subgroup Fairness , author =. 2018 , booktitle =
2018
-
[20]
and Barto, Andrew G
Sutton, Richard S. and Barto, Andrew G. , year =
-
[21]
URL https://doi.org/ 10.1145/3292500.3330701
Akiba, Takuya and Sano, Shotaro and Yanase, Toshihiko and others , year =. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , location =. doi:10.1145/3292500.3330701 , isbn =
-
[22]
2019 , booktitle =
Multiaccuracy: Black-Box Post-Processing for Fairness in Classification , author =. 2019 , booktitle =
2019
-
[23]
The World Wide Web Conference , pages =
Tigunova, Anna and Yates, Andrew and Mirza, Paramita and others , year =. The World Wide Web Conference , pages =
-
[24]
International Conference on Learning Representations , url =
Ari Holtzman and Jan Buys and Li Du and Maxwell Forbes and Yejin Choi , year =. International Conference on Learning Representations , url =
-
[25]
2020 , journal =
Learning from positive and unlabeled data: A survey , author =. 2020 , journal =
2020
-
[26]
Molnar, Christoph , year =
-
[27]
2021 , journal =
A causal lens for controllable text generation , author =. 2021 , journal =
2021
-
[28]
2021 , booktitle =
Towards Robust and Reliable Algorithmic Recourse , author =. 2021 , booktitle =
2021
-
[29]
Knowledge-Based Systems , volume =
Xin He and Kaiyong Zhao and Xiaowen Chu , year =. Knowledge-Based Systems , volume =. doi:https://doi.org/10.1016/j.knosys.2020.106622 , issn =
-
[30]
2022 , journal =
Dud. 2022 , journal =
2022
-
[31]
2022 , booktitle =
Robust Counterfactual Explanations for Tree-Based Ensembles , author =. 2022 , booktitle =
2022
-
[32]
Khattab, Omar and Santhanam, Keshav and Li, Xiang Lisa and others , year =
-
[33]
Advances in neural information processing systems , volume =
Kojima, Takeshi and Gu, Shixiang Shane and Reid, Machel and others , year =. Advances in neural information processing systems , volume =
-
[34]
Zhou, Yongchao and Muresanu, Andrei Ioan and Han, Ziwen and others , year =
-
[35]
ACM SIGKDD Explorations Newsletter , publisher =
Zytek, Alexandra and Arnaldo, Ignacio and Liu, Dongyu and others , year =. ACM SIGKDD Explorations Newsletter , publisher =
-
[36]
2023 , journal =
Knowledge Engineering Using Large Language Models , author =. 2023 , journal =
2023
-
[37]
Brandon T. Willard and R\'. 2023 , url =. 2307.09702 , archiveprefix =
Pith/arXiv arXiv 2023
-
[38]
European conference on information retrieval , pages =
Bucur, Ana-Maria and Cosma, Adrian and Rosso, Paolo and others , year =. European conference on information retrieval , pages =
-
[39]
2023 , booktitle =
DISCO: Distilling counterfactuals with large language models , author =. 2023 , booktitle =
2023
-
[40]
2023 , journal =
Gilardi, Fabrizio and Alizadeh, Meysam and Kubli, Ma. 2023 , journal =
2023
-
[41]
Scientific reports , publisher =
Hohenstein, Jess and Kizilcec, Rene F and DiFranzo, Dominic and Aghajari, Zhila and Mieczkowski, Hannah and Levy, Karen and Naaman, Mor and Hancock, Jeffrey and Jung, Malte F , year =. Scientific reports , publisher =
-
[42]
Cureus , publisher =
Li, Yunxiang and Li, Zihan and Zhang, Kai and Dan, Ruilong and Jiang, Steve and others , year =. Cureus , publisher =
-
[43]
Findings of the Association for Computational Linguistics: EMNLP 2023 , publisher =
Lin, Zi and Wang, Zihan and Tong, Yongqi and Wang, Yangkun and Guo, Yuxin and Wang, Yujia and Shang, Jingbo , year =. Findings of the Association for Computational Linguistics: EMNLP 2023 , publisher =. doi:10.18653/v1/2023.findings-emnlp.311 , url =
-
[44]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , year =
- [45]
-
[46]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =
Pryzant, Reid and Iter, Dan and Li, Jerry and Lee, Yin and Zhu, Chenguang and Zeng, Michael , year =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , publisher =. doi:10.18653/v1/2023.emnlp-main.494 , url =
-
[47]
Reiss, Michael V , year =
-
[48]
Medical Humanities , publisher =
Stergiopoulos, Erene and Martimianakis, Maria Athina Tina , year =. Medical Humanities , publisher =
-
[49]
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and others , year =
-
[50]
Yang, Chengrun and Wang, Xuezhi and Lu, Yifeng and others , year =
-
[51]
Zhou, Hongjian and Liu, Fenglin and Gu, Boyang and Zou, Xinyu and Huang, Jinfa and Wu, Jinge and Li, Yiru and Chen, Sam S and Zhou, Peilin and Liu, Junling and others , year =
-
[52]
Zhu, Yiming and Zhang, Peixian and Haq, Ehsan-Ul and others , year =
-
[53]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages =
Aguda, Toyin D and Siddagangappa, Suchetha and Kochkina, Elena and others , year =. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages =
2024
-
[54]
Bolton, Elliot and Venigalla, Abhinav and Yasunaga, Michihiro and others , year =
-
[55]
European Conference on Advances in Databases and Information Systems , pages =
Brinkmann, Alexander and Baumann, Nick and Bizer, Christian , year =. European Conference on Advances in Databases and Information Systems , pages =
-
[56]
Chern, Steffi and Chern, Ethan and Neubig, Graham and others , year =
-
[57]
Journal of Medical Internet Research , publisher =
Geng, Shuang and He, Yuqin and Duan, Liezhen and Yang, Chen and Wu, Xusheng and Liang, Gemin and Niu, Ben , year =. Journal of Medical Internet Research , publisher =
-
[58]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and others , year =
-
[59]
Hassan, Abdelrahaman A and Hanafy, Radwa J and Fouda, Mohammed E , year =
-
[60]
He, Xingwei and Lin, Zhenghao and Gong, Yeyun and others , year =
-
[61]
Jiang, Junqi and Leofante, Francesco and Rago, Antonio and Toni, Francesca , title =. 2024 , isbn =. doi:10.24963/ijcai.2024/894 , booktitle =
-
[62]
Khattab, Omar and Singhvi, Arnav and Maheshwari, Paridhi and others , year =
-
[63]
Li, Mingchen and Huang, Jiatan and Yeung, Jeremy and others , year =
-
[64]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , publisher =
Nigatu, Hellina Hailu and Tonja, Atnafu Lambebo and Rosman, Benjamin and Solorio, Thamar and Choudhury, Monojit , year =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , publisher =. doi:10.18653/v1/2024.emnlp-main.983 , url =
-
[65]
Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs
Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs , author =. 2024 , month = nov, booktitle =. doi:10.18653/v1/2024.emnlp-main.525 , url =
-
[66]
Nature Medicine , publisher =
Reis, Moritz and Reis, Florian and Kunde, Wilfried , year =. Nature Medicine , publisher =
-
[67]
Ren, Zhiyao and Zhan, Yibing and Yu, Baosheng and Ding, Liang and Tao, Dacheng , year =
-
[68]
Shekar, Shruthi and Pataranutaporn, Pat and Sarabu, Chethan and Cecchi, Guillermo A and Maes, Pattie , year =
-
[69]
Sinha, Apurva and Gujral, Ekta , year =
-
[70]
2024 , booktitle =
Fine-tuning and prompt optimization: Two great steps that work better together , author =. 2024 , booktitle =
2024
-
[71]
2024 , journal =
Counterfactual explanations and algorithmic recourses for machine learning: A review , author =. 2024 , journal =
2024
-
[72]
2024 , journal =
Self-preference bias in LLM-as-a-Judge , author =. 2024 , journal =
2024
-
[73]
An LLM feature-based framework for dialogue constructiveness assessment
Zhou, Lexin and Farag, Youmna and Vlachos, Andreas , year =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , publisher =. doi:10.18653/v1/2024.emnlp-main.308 , url =
-
[74]
Computational Linguistics , publisher =
Ziems, Caleb and Held, William and Shaikh, Omar and others , year =. Computational Linguistics , publisher =
-
[75]
2025 , journal =
Balek, Vojt. 2025 , journal =
2025
-
[76]
2025 , journal =
Bean, Andrew and Payne, Rebecca Elizabeth and Parsons, Guy and Kirk, Hannah Rose and Ciro, Juan and Mosquera-G. 2025 , journal =
2025
-
[77]
Belcak, Peter and Heinrich, Greg and Diao, Shizhe and others , year =
-
[78]
How Many Instructions Can
Daniel Jaroslawicz and Brendan Whiting and Parth Shah and Karime Maamari , year =. How Many Instructions Can. NeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling , url =
2025
-
[79]
Journal of Business Research , volume =
Dennis Herhausen and Stephan Ludwig and Ehsan Abedin and others , year =. Journal of Business Research , volume =. doi:https://doi.org/10.1016/j.jbusres.2025.115491 , issn =
-
[80]
Position: Scaling
Elliot Meyerson and Xin Qiu , year =. Position: Scaling. Forty-second International Conference on Machine Learning Position Paper Track , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.