Concept Unlearning via Cross-Attention Activation Projection for Diffusion Models
Pith reviewed 2026-06-29 22:41 UTC · model grok-4.3
The pith
Representing concepts via cross-attention activations during denoising enables closed-form unlearning that resists paraphrased prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
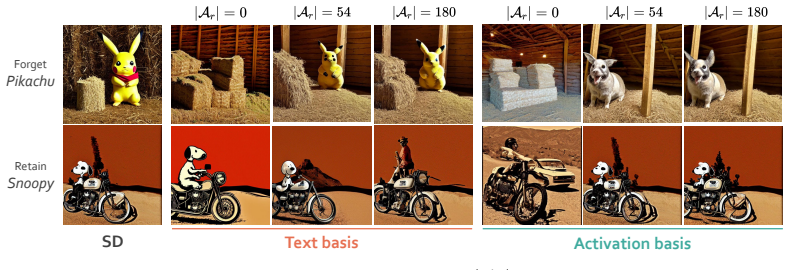
PURE builds forget and retain bases from per-layer cross-attention activations captured along a short denoising trajectory and applies a single linear projector to the cross-attention key and value weights, yielding the best overall forget-retain trade-off among evaluated methods by significantly reducing target leakage under paraphrased and adversarial prompts.
What carries the argument
The single linear projector applied to cross-attention key and value weights, with bases derived from per-layer activations along a short denoising trajectory rather than text-encoder embeddings.
If this is right
- The edit generalizes to prompts that paraphrase or avoid naming the target concept.
- Retain concepts stay close in performance to the unedited model across the tested categories.
- The method adds no inference-time cost because it is a one-time closed-form weight change.
- The approach covers artistic style, intellectual property, celebrity, and NSFW targets in one framework.
Where Pith is reading between the lines
- Activation-space editing may apply to other attention-based generative models beyond diffusion.
- Collecting activations at more points along the trajectory could further improve robustness.
- The same projection idea might help identify and edit unintended concepts discovered after training.
Load-bearing premise
The target concept is more reliably represented by cross-attention activations captured along a short denoising trajectory than by the text encoder's response to a few short anchor prompts and their paraphrases.
What would settle it
An experiment showing that paraphrased or adversarial prompts still produce the target concept at rates comparable to text-encoder-based methods on the same benchmark would falsify the claimed advantage.
Figures







read the original abstract
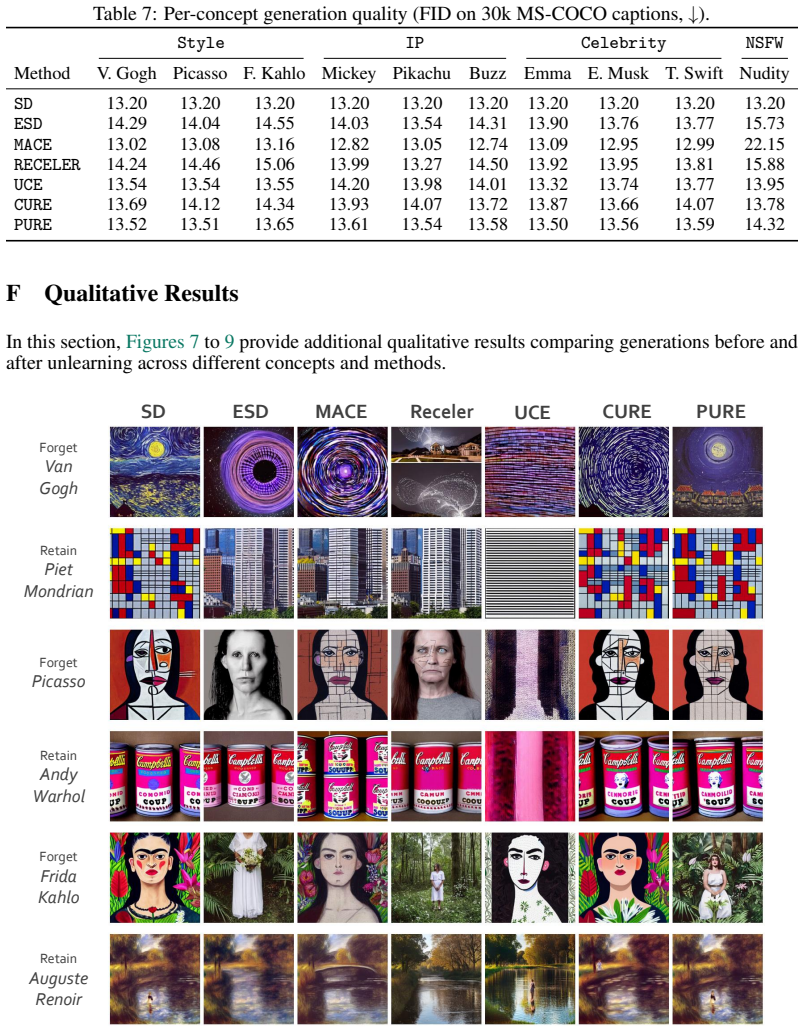
Concept unlearning aims to erase a target concept from a pretrained text-to-image diffusion model without retraining. Closed-form methods are attractive in this setting because they apply a single deterministic edit to the cross-attention weights and add no inference-time cost. Existing closed-form methods, however, represent the target concept through the text encoder's response to a few short anchor prompts that name it, and paraphrased prompts that evoke the concept without naming it consistently bypass the edit. We argue that the target should instead be represented in the cross-attention activation space. Text embeddings describe the user's prompt, while cross-attention activations describe what the model is about to render, and the latter generalize to paraphrase the anchor templates do not cover. Building on this observation, we propose PURE (Projection in U-Net Rendering for Erasure), a closed-form method that builds the forget and retain bases from per-layer cross-attention activations captured along a short denoising trajectory and applies a single linear projector to the cross-attention key and value weights. On a recent holistic concept-unlearning benchmark covering ten concepts across artistic style, intellectual property, celebrity, and NSFW categories, PURE significantly reduces target leakage under paraphrased and adversarial prompts while preserving retain concepts close to the unedited model, yielding the best overall forget-retain trade-off among evaluated methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PURE, a closed-form method for erasing target concepts from pretrained text-to-image diffusion models. It constructs forget and retain bases from per-layer cross-attention activations captured along a short denoising trajectory (rather than text-encoder embeddings from anchor prompts), then applies a single linear projector to the cross-attention K/V weights. On a holistic benchmark with ten concepts spanning artistic style, IP, celebrity, and NSFW categories, the method is claimed to reduce target leakage under paraphrased and adversarial prompts while preserving retain concepts near the unedited baseline, yielding the best overall forget-retain trade-off among compared approaches.
Significance. If the central empirical claim holds after addressing sampling and reporting gaps, the work supplies a practical, inference-free edit that improves paraphrase robustness over prior closed-form unlearning techniques. The shift from text-embedding to activation-space representation is a clear conceptual contribution for safety-oriented editing of generative models, and the multi-category benchmark evaluation provides a useful stress test of generalization.
major comments (3)
- [§3] §3 (Method, trajectory description): the central claim that activations along a short denoising trajectory suffice to span a paraphrase-robust forget basis is load-bearing, yet the manuscript provides no analysis, ablation, or justification of trajectory length, timestep selection, or coverage of the activation distribution; this directly engages the sampling concern that residual leakage may remain when concept signatures appear outside the sampled slice.
- [Experiments / Results] Experiments / Results section (benchmark reporting): the abstract and results claim statistically significant improvements and best overall trade-off, but supply no quantitative details on statistical significance testing, exact baseline re-implementations, variance across runs, or ablation of the activation-capture procedure itself; without these, the strength of the forget-retain superiority cannot be assessed.
- [§4] §4 (Evaluation protocol): the paper does not report whether the short trajectory was held fixed across all ten concepts or tuned per concept; if the latter, the method is no longer parameter-free in the sense advertised and the cross-concept comparison is weakened.
minor comments (2)
- [Method] Notation: the precise definition of the per-layer activation matrix (e.g., concatenation over heads or timesteps) is not stated explicitly enough to allow immediate reproduction from the equations alone.
- [Figure 2] Figure clarity: the activation-projection diagram would benefit from an explicit indication of which timesteps are sampled and how the forget/retain bases are formed from them.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each of the major comments below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [§3] §3 (Method, trajectory description): the central claim that activations along a short denoising trajectory suffice to span a paraphrase-robust forget basis is load-bearing, yet the manuscript provides no analysis, ablation, or justification of trajectory length, timestep selection, or coverage of the activation distribution; this directly engages the sampling concern that residual leakage may remain when concept signatures appear outside the sampled slice.
Authors: We agree that the manuscript would benefit from additional analysis on the trajectory. The choice of a short denoising trajectory (typically 5 timesteps) is motivated by the observation that cross-attention activations in early denoising steps capture the core concept rendering, as later steps focus on details. However, to address the concern, we will include an ablation study varying the trajectory length and timestep selection in the revised version, demonstrating that performance stabilizes beyond a certain short length. This will also include discussion on coverage of the activation distribution. revision: yes
-
Referee: Experiments / Results section (benchmark reporting): the abstract and results claim statistically significant improvements and best overall trade-off, but supply no quantitative details on statistical significance testing, exact baseline re-implementations, variance across runs, or ablation of the activation-capture procedure itself; without these, the strength of the forget-retain superiority cannot be assessed.
Authors: We acknowledge that the current manuscript lacks detailed statistical reporting. In the revision, we will add: (1) results of statistical significance tests (e.g., paired t-tests) comparing PURE to baselines, (2) exact details on how baselines were re-implemented, (3) variance (standard deviation) across 3-5 independent runs, and (4) an ablation on the activation-capture procedure (e.g., number of steps, layers). These additions will allow better assessment of the superiority claim. revision: yes
-
Referee: [§4] §4 (Evaluation protocol): the paper does not report whether the short trajectory was held fixed across all ten concepts or tuned per concept; if the latter, the method is no longer parameter-free in the sense advertised and the cross-concept comparison is weakened.
Authors: The short trajectory parameters (timesteps and length) were held fixed across all ten concepts to ensure the method remains parameter-free and comparisons are fair. We will explicitly report this fixed setting in the revised §4, along with the specific values used (e.g., timesteps 0-4 or similar), to clarify the evaluation protocol. revision: yes
Circularity Check
No circularity: direct linear projection from observed activations
full rationale
The paper presents PURE as a closed-form linear projector computed directly from per-layer cross-attention activations collected along a short denoising trajectory. No equation reduces the forget/retain bases or the resulting performance to a quantity fitted inside the same experiment, nor does any load-bearing step rely on self-citation chains or imported uniqueness theorems. The derivation is self-contained against external benchmarks, consistent with the reader's assessment of score 2.0 (minor at most).
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-attention activations captured along a short denoising trajectory represent the target concept more robustly than text-encoder outputs to anchor prompts.
Reference graph
Works this paper leans on
-
[1]
Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models
Yiting Qu, Xinyue Shen, Xinlei He, Michael Backes, Savvas Zannettou, and Yang Zhang. Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, pages 3403–3417,
2023
-
[2]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text- conditional image generation with CLIP latents.arXiv preprint arXiv:2204.06125,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Patrick Schramowski, Christopher Tauchmann, and Kristian Kersting. Can machines help us answer- ing question 16 in datasheets, and in turn reflecting on inappropriate content? InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 1350–1361,
2022
-
[4]
{c}”, “painting by {c}
From these categories, we select ten forget concepts for evaluation: Van Gogh, Picasso, and Frida Kahlo from Style; Mickey Mouse, Pikachu, and Buzz Lightyear from IP; Emma Watson, Elon Musk, and Taylor Swift fromCelebrity; and Nudity fromNSFW. Table 3: Concepts included in each HUB category. Category Concepts Style Andy Warhol, Auguste Renoir, Claude Mone...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.