Workflow Closure Is Not Scientific Closure in Auto-Research Systems
Pith reviewed 2026-06-29 20:12 UTC · model grok-4.3
The pith
Auto-research systems can close internal workflows without achieving scientific closure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
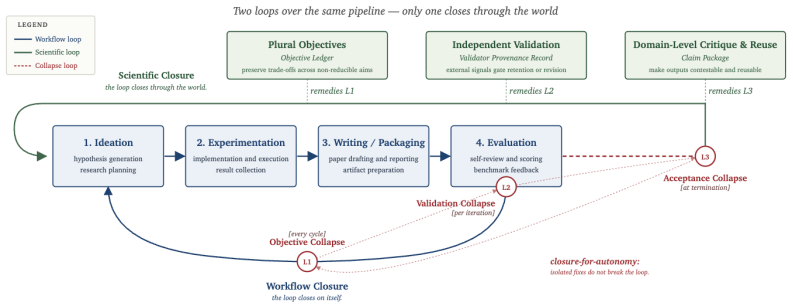
Workflow closure is not scientific closure in auto-research systems. Current systems exhibit objective collapse, validation collapse, and acceptance collapse. These are correctable design choices rather than inherent limits of autonomy, and trustworthy systems should target autonomous execution under non-autonomous epistemic control.
What carries the argument
The three collapses—objective, validation, and acceptance—that separate workflow closure from scientific closure.
If this is right
- Remedies in objective signal, validation mechanisms, and output pathways can correct the collapses.
- Systems should aim for autonomous execution under non-autonomous epistemic control rather than full self-sufficiency.
- The distinction reframes design goals away from maximizing internal closure alone.
Where Pith is reading between the lines
- Interfaces allowing external epistemic oversight may become central to practical auto-research tools.
- The collapse pattern could appear in autonomous agents outside research domains.
- Testing specific remedies empirically would provide direct evidence for the proposed distinction.
Load-bearing premise
The survey of more than 100 papers and structured audit of 21 representative systems accurately captures a recurring and structurally connected failure pattern across the emerging field.
What would settle it
An auto-research system that produces outputs achieving independent scientific acceptance, reuse, and integration without external epistemic control would falsify the necessity of non-autonomous control.
Figures
read the original abstract
This paper argues that workflow closure is not scientific closure in auto-research systems. Current systems can increasingly complete research-like loops internally, moving from idea generation to experiment execution, writing, and self-evaluation. That achievement is real, but it does not by itself give the resulting outputs scientific standing. We argue that trustworthy auto-research should not aim for autonomous self-sufficiency, but should aim for autonomous execution under non-autonomous epistemic control. Based on a survey of more than 100 recent papers and repositories in this rapidly emerging area, together with a structured audit of 21 representative systems, we diagnose a recurring and structurally connected failure pattern: objective collapse, in which single-proxy targets replace multi-objective scientific aims; validation collapse, in which internal self-evaluation replaces independent validation; and acceptance collapse, in which benchmark scores or publication-shaped artifacts replace mechanisms for domain-level critique, reuse, and integration. These collapses are not inherent limits of autonomy but correctable design choices. Accordingly, we outline potential remedies across objective signal, validation, and output pathway to spark community discussion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that workflow closure (internal completion of research-like loops from idea to self-evaluation) in auto-research systems does not equate to scientific closure. Drawing on a survey of more than 100 papers and a structured audit of 21 representative systems, it diagnoses three recurring, structurally linked failure modes—objective collapse (single-proxy targets replacing multi-objective aims), validation collapse (internal self-evaluation replacing independent validation), and acceptance collapse (benchmark scores replacing domain critique and reuse)—and argues these are correctable design choices rather than inherent limits of autonomy. The authors recommend targeting autonomous execution under non-autonomous epistemic control and sketch remedies across objective signal, validation, and output pathways.
Significance. If the collapse pattern is substantiated, the work would usefully reorient the auto-research literature away from full self-sufficiency toward hybrid designs that preserve external epistemic oversight. The explicit framing of collapses as design choices rather than inevitabilities, together with the call for community discussion on remedies, could help shape evaluation criteria and system architectures in this emerging area.
major comments (2)
- [Abstract] Abstract and the survey/audit description: the central claim that objective, validation, and acceptance collapses form a 'recurring and structurally connected failure pattern' across the field rests entirely on the survey of >100 papers and the structured audit of 21 systems, yet no sampling frame, inclusion/exclusion criteria, operational definitions of each collapse type, coding rubric, or inter-auditor agreement metrics are supplied. Without these, the empirical foundation cannot be evaluated and the normative recommendation inherits the same uncertainty.
- [Remedies] Remedies section: the proposed remedies (objective signal, validation, output pathway) are presented at a conceptual level without mapping back to concrete failures observed in the 21 audited systems or providing even schematic implementation details, so it is unclear whether the suggested fixes would actually address the diagnosed collapses.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify clear opportunities to strengthen the empirical transparency and practical grounding of the manuscript. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and the survey/audit description: the central claim that objective, validation, and acceptance collapses form a 'recurring and structurally connected failure pattern' across the field rests entirely on the survey of >100 papers and the structured audit of 21 systems, yet no sampling frame, inclusion/exclusion criteria, operational definitions of each collapse type, coding rubric, or inter-auditor agreement metrics are supplied. Without these, the empirical foundation cannot be evaluated and the normative recommendation inherits the same uncertainty.
Authors: We agree that the absence of explicit methodological details limits evaluability of the survey and audit. The original submission prioritized concise presentation of the collapse pattern and its implications over a full methods appendix. In revision we will add a new subsection (and, if space permits, an appendix) that specifies: (1) the sampling frame and inclusion/exclusion criteria used to select the >100 papers and the 21 audited systems; (2) operational definitions and coding rubric for each collapse type; and (3) any steps taken to ensure consistency across auditors. These additions will allow readers to assess the strength of the empirical claims directly. revision: yes
-
Referee: [Remedies] Remedies section: the proposed remedies (objective signal, validation, output pathway) are presented at a conceptual level without mapping back to concrete failures observed in the 21 audited systems or providing even schematic implementation details, so it is unclear whether the suggested fixes would actually address the diagnosed collapses.
Authors: The remedies were deliberately kept at a conceptual level to stimulate community discussion rather than to prescribe ready-to-implement solutions. We nevertheless accept that explicit linkage to the audited systems would increase persuasiveness. In the revised manuscript we will insert a mapping table (or subsection) that connects each proposed remedy to one or more concrete failure instances drawn from the 21 systems and will supply schematic implementation outlines (e.g., example objective functions, validation protocols, or output metadata schemas) where the underlying data permit. This will make the connection between diagnosis and remedy explicit without overclaiming prescriptive detail. revision: yes
Circularity Check
No circularity; derivation rests on external survey and audit
full rationale
The paper's central argument—that objective, validation, and acceptance collapses form a recurring pattern and are correctable design choices—rests on a survey of more than 100 external papers plus a structured audit of 21 systems. No equations, self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The normative recommendation for autonomous execution under non-autonomous epistemic control follows directly from the diagnosed external patterns without reducing to any input by construction. This is the most common honest finding for survey-based position papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scientific standing requires independent validation mechanisms rather than internal self-evaluation.
Reference graph
Works this paper leans on
-
[1]
du-nlp-lab/MLR-Copilot, Aug. 2025
2025
-
[2]
aiming-lab/AutoResearchClaw, Apr. 2026
2026
-
[3]
davebcn87/pi-autoresearch, Apr. 2026
2026
-
[4]
drivelineresearch/autoresearch-claude-code, Apr. 2026
2026
-
[5]
eimenhmdt/autoresearcher, Apr. 2026
2026
-
[6]
Entrpi/autoresearch-everywhere, Apr. 2026
2026
-
[7]
gepa-ai/gepa, Apr. 2026
2026
-
[8]
greyhaven-ai/autocontext, Apr. 2026
2026
-
[9]
HKUDS/AI-Researcher, Apr. 2026
2026
-
[10]
HKUDS/ClawTeam, Apr. 2026
2026
-
[11]
hyperspaceai/agi, Apr. 2026
2026
-
[12]
james-s-tayler/lazy-developer, Apr. 2026
2026
-
[13]
JinheonBaek/ResearchAgent, Mar. 2026
2026
-
[14]
jmilinovich/goal-md, Apr. 2026
2026
-
[15]
leo-lilinxiao/codex-autoresearch, Apr. 2026
2026
-
[16]
LitLLM/LitLLM, Apr. 2026
2026
-
[17]
MASWorks/ML-Agent, Mar. 2026
2026
-
[18]
MaximeRobeyns/self_improving_coding_agent, Apr. 2026
2026
-
[19]
metauto-ai/HGM, Apr. 2026
2026
-
[20]
MrTsepa/autoevolve, Mar. 2026
2026
-
[21]
mutable-state-inc/autoresearch-at-home, Apr. 2026
2026
-
[22]
openags/OpenAGS, Apr. 2026
2026
-
[23]
OpenRaiser/NanoResearch, Apr. 2026
2026
-
[24]
Orchestra-Research/AI-Research-SKILLs, Apr. 2026
2026
-
[25]
peterskoett/self-improving-agent, Apr. 2026
2026
-
[26]
PouriaRouzrokh/LatteReview, Apr. 2026
2026
-
[27]
SakanaAI/AI-Scientist, Apr. 2026
2026
-
[28]
SakanaAI/AI-Scientist-v2, Apr. 2026
2026
-
[29]
SamuelSchmidgall/AgentLaboratory, Apr. 2026
2026
-
[30]
ShengranHu/ADAS, Apr. 2026
2026
-
[31]
Sibyl-Research-Team/AutoResearch-SibylSystem, Apr. 2026
2026
-
[32]
supratikpm/gemini-autoresearch, Apr. 2026
2026
-
[33]
uditgoenka/autoresearch, Apr. 2026
2026
-
[34]
wanshuiyin/Auto-claude-code-research-in-sleep, Apr. 2026. 21
2026
-
[35]
WecoAI/aideml, Apr. 2026
2026
-
[36]
Why AI cannot do good science without humans.Nature, 653(8115):650–650, May 2026
2026
-
[37]
zkarimi22/autoresearch-anything, Apr. 2026
2026
-
[38]
Alexander, B
S. Alexander, B. Bradley, L. Gouskos, and C. Niu. Autonomous Discovery of Particle Physics Theories from Experimental Data, Mar. 2026
2026
-
[39]
S. Alzubi, N. Provenzano, J. Bingham, W. Chen, and T. Vu. Evoskill: Automated skill discovery for multi-agent systems.arXiv preprint arXiv:2603.02766, 2026
Pith/arXiv arXiv 2026
-
[40]
Aygün, A
E. Aygün, A. Belyaeva, G. Comanici, M. Coram, H. Cui, J. Garrison, R. Johnston, A. Kast, C. Y . McLean, P. Norgaard, Z. Shamsi, D. Smalling, J. Thompson, S. Venugopalan, B. P. Williams, C. He, S. Martinson, M. Plomecka, L. Wei, Y . Zhou, Q.-Z. Zhu, M. Abraham, E. Brand, A. Bulanova, J. A. Cardille, C. Co, S. Ellsworth, G. Joseph, M. Kane, R. Krueger, J. K...
2026
-
[41]
D. A. Boiko, R. MacKnight, B. Kline, and G. Gomes. Autonomous chemical research with large language models.Nature, 624:570–578, 2023
2023
-
[42]
Y . Chen, C. Liu, Z. Chen, T. Liu, B. Han, and K. Zhang. CausalEvolve: Towards Open-Ended Discovery with Causal Scratchpad, Mar. 2026
2026
-
[43]
M. Cobelli and S. Sanvito. Agentic design of compositional descriptors via autoresearch for materials science applications.arXiv preprint arXiv:2605.14671, 2026
Pith/arXiv arXiv 2026
-
[44]
L. Fan, P. Dai, Z. Deng, H. Wang, X. Gong, Y . Zheng, and Y . Ou. Evolving Medical Imaging Agents via Experience-driven Self-skill Discovery, Mar. 2026. arXiv:2603.05860 [cs]
arXiv 2026
-
[45]
Ferreira, L
F. Ferreira, L. Wobbe, A. Krishnakumar, F. Hutter, and A. Zela. Can LLMs Beat Classical Hyperparameter Optimization Algorithms? A Study on autoresearch, Mar. 2026
2026
-
[46]
A. E. Ghareeb, B. Chang, L. Mitchener, A. Yiu, C. J. Szostkiewicz, D. Shved, G. J. Gyimesi, J. M. Laurent, S. M. Wright, M. T. Razzak, A. D. White, S. C. Finnemann, M. M. Hinks, and S. G. Rodriques. A multi-agent system for automating scientific discovery.Nature, May 2026
2026
-
[47]
Gottweis, W.-H
J. Gottweis, W.-H. Weng, A. Daryin, T. Tu, P. Sirkovic, A. Myaskovsky, G. Glowaty, F. Weis- senberger, A. Orlandi, D. Popovici, A. Palepu, K. Rong, R. Tanno, K. Saab, F. Zhang, J. Blum, A. Carroll, K. Kulkarni, N. Tomašev, D. Zverinski, I. Rendulic, E. Vedadi, F. Hasler, L. Ri- manic, M. Boia, I. Budiselic, B. Feinstein, M. Bellaiche, T. Sheffer, J. Freyb...
2026
-
[48]
T. Han, Y . Zhang, W. Song, C. Fang, Z. Chen, Y . Sun, and L. Hu. Swe-skills-bench: Do agent skills actually help in real-world software engineering?arXiv preprint arXiv:2603.15401, 2026
arXiv 2026
-
[49]
C. He, X. Zhou, D. Wang, H. Xu, W. Liu, and C. Miao. The AutoResearch Moment: From Experimenter to Research Director, Mar. 2026
2026
-
[50]
M. He, F. Jiang, J. Jiao, M. Li, K. Li, Y . Liao, B. Liu, T. Liu, F. Qi, Z. Shang, W. Song, Y . Sun, X. Wang, H. Wang, D. Xiong, C. Yuan, B. Zhang, Z. Zhang, and X. Zhu. Dr.Sai: An agentic AI for real-world physics analysis at BESIII, Apr. 2026. arXiv:2604.22541 [hep-ex] version: 1
Pith/arXiv arXiv 2026
- [51]
-
[52]
V . Ilin. Semi-Autonomous Formalization of the Vlasov-Maxwell-Landau Equilibrium, Mar. 2026
2026
-
[53]
B. Jia, S. Kamboj, S. Katipomu, S. H. Han, N. Sengupta, and A. Jackson. Nomad: Autonomous Exploration and Discovery, Mar. 2026
2026
- [54]
-
[55]
Karpathy
A. Karpathy. karpathy/autoresearch, Apr. 2026
2026
-
[56]
Karwowski, O
J. Karwowski, O. Hayman, X. Bai, K. Kiendlhofer, C. Griffin, and J. M. V . Skalse. Good- hart’s law in reinforcement learning. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[57]
Khandelwal and S
N. Khandelwal and S. S. Gupta. Agent-Driven Autonomous Reinforcement Learning Research: Iterative Policy Improvement for Quadruped Locomotion, Mar. 2026
2026
-
[58]
L. Kong, X. Sun, W. Chow, L. Li, K. Q. Lin, X. B. Zhang, S. Wang, R. Li, Q. Wu, W. Gao, Y . Wang, S. Xie, J. Liu, L. Qu, S. Li, L. X. Ng, B. R. Cottereau, Z. Liu, T.-S. Chua, and W. T. Ooi. AI for Auto-Research: Roadmap & user guide. May 2026
2026
- [59]
-
[60]
C.-Y . Lee, H. Liang, R. Kim, A. McDannald, C. A. R. Ocampo, A. G. Kusne, and I. Takeuchi. Real-time multi-instrument autonomous discovery of novel phase-change memory materials. May 2026
2026
-
[61]
F. Li, P. Tagkopoulos, and I. Tagkopoulos. Skillflow: Scalable and efficient agent skill retrieval system.arXiv e-prints, pages arXiv–2504, 2025
2025
-
[62]
H. Li, C. Mu, J. Chen, S. Ren, Z. Cui, Y . Zhang, L. Bai, and S. Hu. Organizing, orchestrating, and benchmarking agent skills at ecosystem scale.arXiv preprint arXiv:2603.02176, 2026
arXiv 2026
-
[63]
X. Li. Auto Researching, not hyperparameter tuning: Convergence Analysis of 10,000 Experiments, Mar. 2026
2026
-
[64]
X. Li. When single-agent with skills replace multi-agent systems and when they fail.arXiv preprint arXiv:2601.04748, 2026
arXiv 2026
-
[65]
X. Li, W. Chen, Y . Liu, S. Zheng, X. Chen, Y . He, Y . Li, B. You, H. Shen, J. Sun, et al. Skillsbench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670, 2026
Pith/arXiv arXiv 2026
-
[66]
Y . Li, C. Shao, X. Liu, R. Zhao, P. Liu, H. Su, Z. Chen, Q. Yang, A. Xu, Y . Fang, et al. Autosota: An end-to-end automated research system for state-of-the-art ai model discovery. arXiv preprint arXiv:2604.05550, 2026
Pith/arXiv arXiv 2026
- [67]
-
[68]
C. Liu, T. Li, M. Huang, X. Wei, P. Liu, Y . Shen, Y . Mao, and T. Cui. Protrlsearch: A multi- round multimodal protein search agent with large language models trained via reinforcement learning.arXiv preprint arXiv:2603.01464, 2026
arXiv 2026
-
[69]
F. Liu, J. Han, T. Lyu, W. Zhang, Z.-R. Yang, L. Dai, C. Liu, and H. Liu. Foundation models for scientific discovery: From paradigm enhancement to paradigm transition.Advances in Neural Information Processing Systems, 2025
2025
-
[70]
F. Liu, J. Xu, X. Cui, X. Wang, Z. Guo, J. Wang, S. M. Mousavi, X. Gu, H. Chen, B. Fei, L. Fang, F. Ling, Z. Li, and L. Bai. TRACE: A Multi-Agent System for Autonomous Physical Reasoning for Seismology, Mar. 2026. 23
2026
-
[71]
J. Liu, Z. Ling, S. Qiu, Y . Liu, S. Han, P. Xia, H. Tu, Z. Zheng, C. Xie, C. Fleming, et al. Omni-simplemem: Autoresearch-guided discovery of lifelong multimodal agent memory. arXiv e-prints, pages arXiv–2604, 2026
2026
-
[72]
J. Liu, S. Qiu, M. Li, B. Li, H. Ji, S. Han, X. Ye, P. Xia, Z. Dong, C. Zhang, L. Zhang, G. Chen, H. Tu, X. Yang, L. Feng, X. Zhao, H. Chen, J. Zhou, X. Wang, W. Zhang, H. Zhu, Y . Li, J. Mei, H. Fei, J. Zhang, L. Li, L. Zhang, Y . Zhou, S. Wang, C. Xiong, J. Zou, Z. Zheng, C. Xie, M. Ding, and H. Yao. AutoResearchClaw: Self-reinforcing autonomous researc...
2026
-
[73]
J. Liu, J. Shen, S. Song, T. Li, X. Liu, R. Li, Z. Huang, J. Lin, J. Ning, C. Ji, S. Luo, W. Li, C. Ma, M. Hu, J. Xiong, J. Ye, B. Fu, N. Xu, Y . Chen, L. Jin, H. Chen, and J. He. MedProbeBench: Systematic Benchmarking at Deep Evidence Integration for Expert-level Medical Guideline, Apr. 2026. arXiv:2604.18418 [cs] version: 1
Pith/arXiv arXiv 2026
-
[74]
J. Liu, X. Ye, P. Xia, Z. Zheng, C. Xie, M. Ding, and H. Yao. Evolvemem: Self-evolving memory architecture via autoresearch for llm agents.arXiv preprint arXiv:2605.13941, 2026
Pith/arXiv arXiv 2026
-
[75]
C. Lu, C. Lu, R. T. Lange, Y . Yamada, S. Hu, J. Foerster, D. Ha, and J. Clune. Towards end-to-end automation of AI research.Nature, 651(8107):914–919, Mar. 2026
2026
-
[76]
D. Manheim and S. Garrabrant. Categorizing variants of goodhart’s law.arXiv preprint arXiv:1803.04585, 2018
Pith/arXiv arXiv 2018
-
[77]
Messeri and M
L. Messeri and M. J. Crockett. Artificial intelligence and illusions of understanding in scientific research.Nature, 627:49–58, 2024
2024
-
[78]
J. Ni, Y . Liu, X. Liu, Y . Sun, M. Zhou, P. Cheng, D. Wang, X. Jiang, and G. Jiang. Trace2skill: Distill trajectory-local lessons into transferable agent skills.arXiv preprint arXiv:2603.25158, 2026
Pith/arXiv arXiv 2026
-
[79]
Novikov, M
A. Novikov, M. Balog, M. P. Kumar, et al. AlphaEvolve: A coding agent for scientific and algorithmic discovery, 2025
2025
-
[80]
Introducing deep research, 2025
OpenAI. Introducing deep research, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.