Towards Cybersecurity SuperIntelligence (CSI): What's the best harness for cybersecurity?
Pith reviewed 2026-06-29 11:57 UTC · model grok-4.3
The pith
A blackboard that lets different AI scaffolds share findings solves more cybersecurity challenges than any one scaffold alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
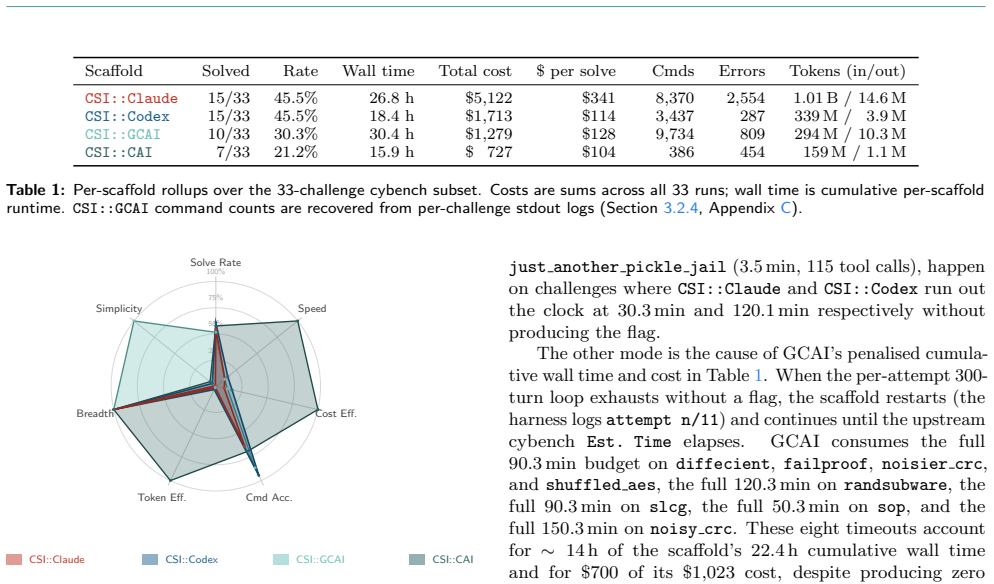
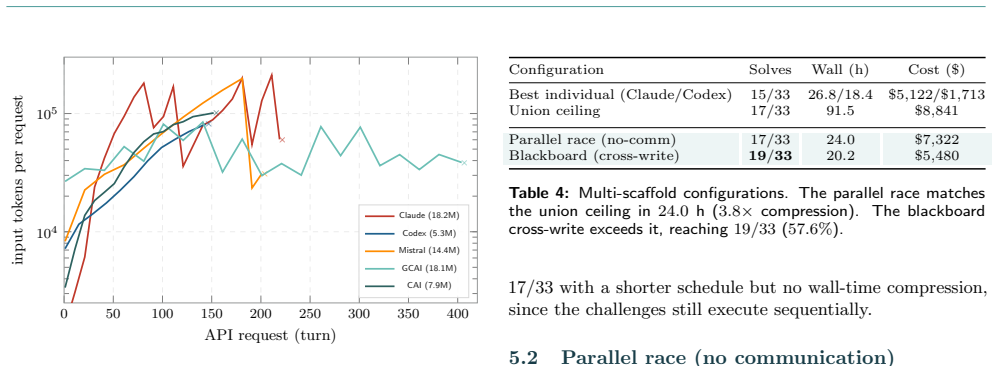
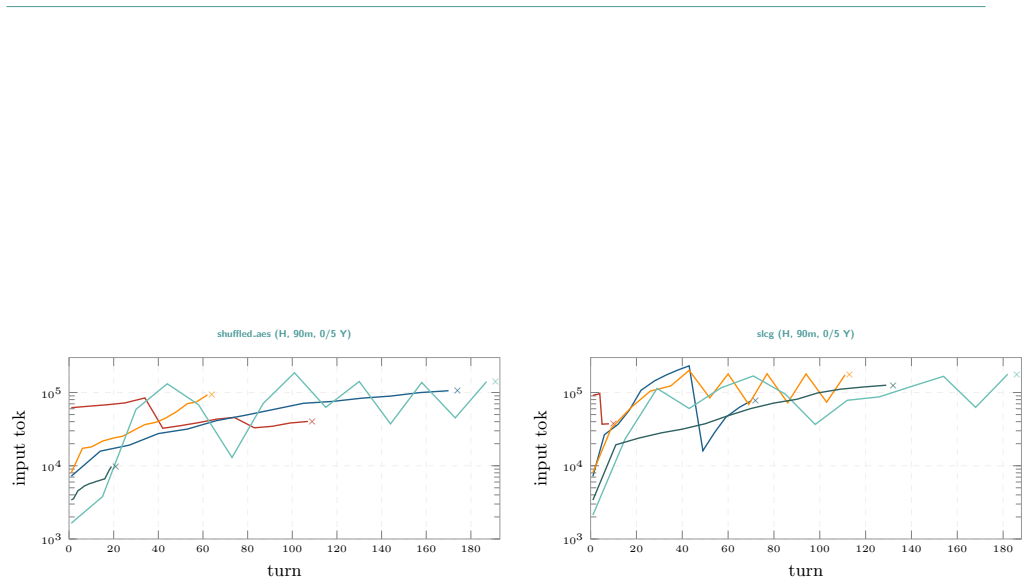
No single scaffold is the best harness; the combination of structurally heterogeneous scaffolds inside a blackboard-based multi-agent architecture produces the highest coverage, solving 19 of 33 cybench challenges versus 15 of 33 for the strongest individual scaffold at 25 percent less time and comparable cost.
What carries the argument
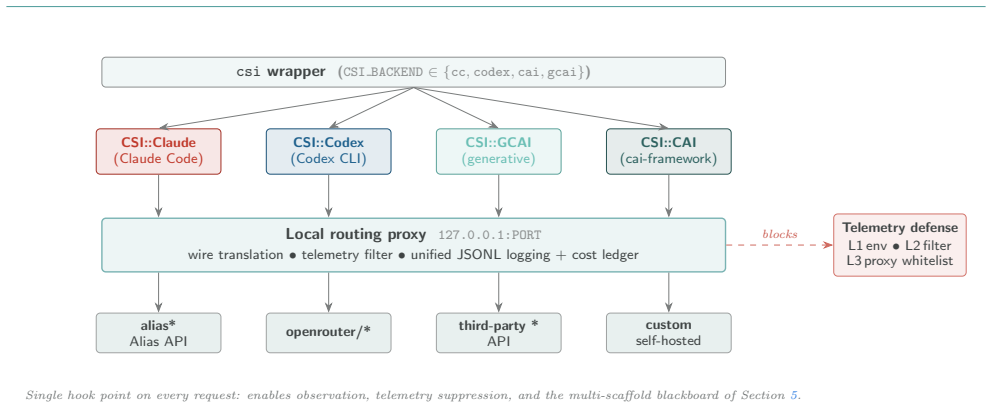
CSI's blackboard-based multi-agent architecture, in which scaffold-specialised agents run in parallel and exchange intermediate findings via a shared substrate.
If this is right
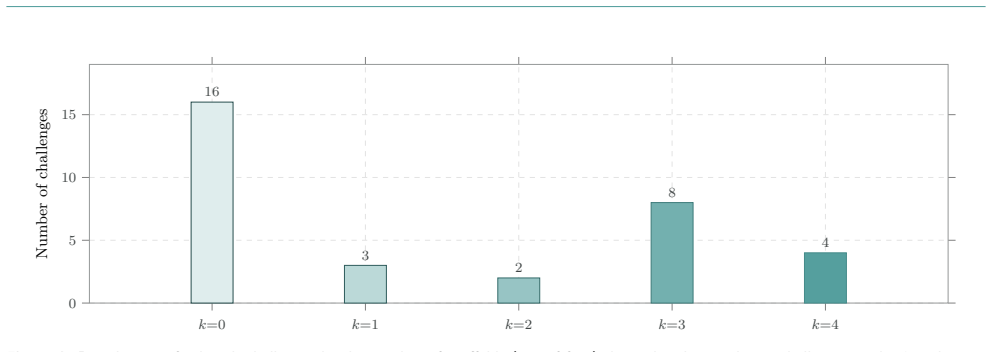
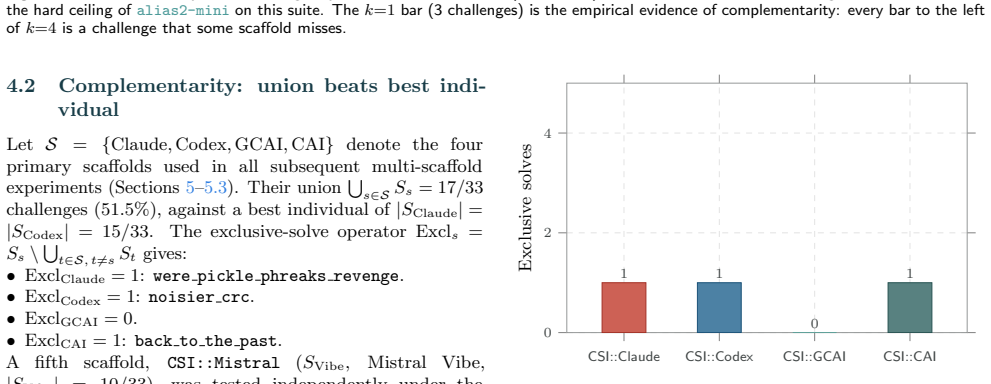
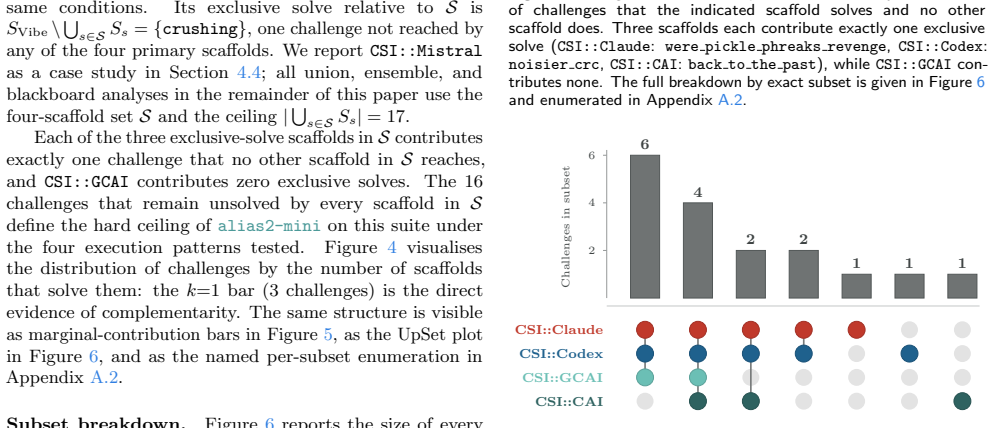
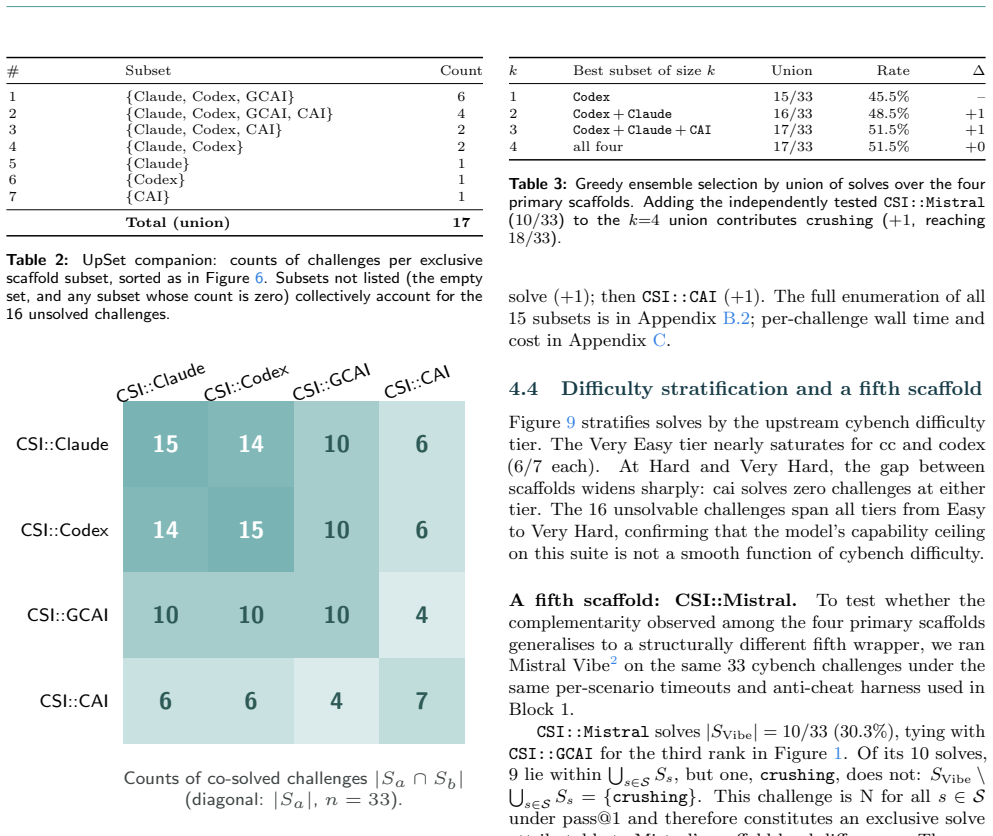
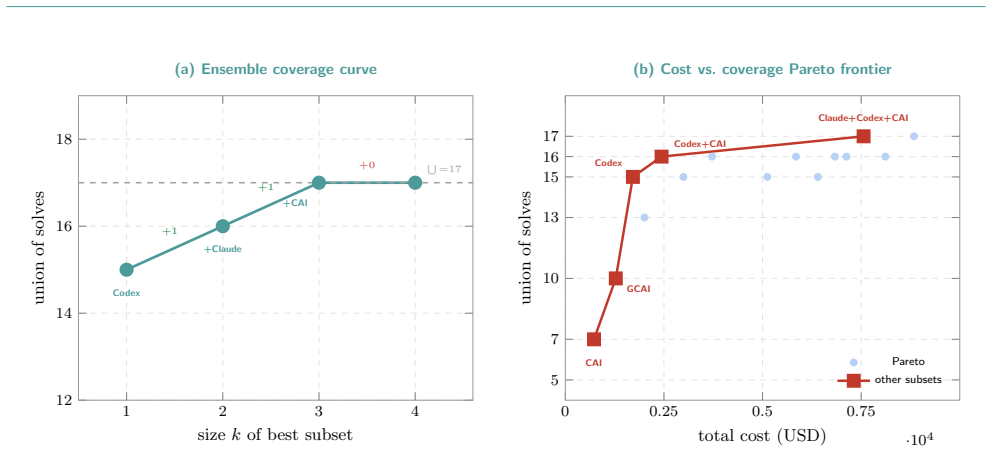
- Union of four scaffolds already reaches 17 solves, with the fifth adding one exclusive solve.
- Blackboard use yields a 27 percent relative gain over the best individual scaffold.
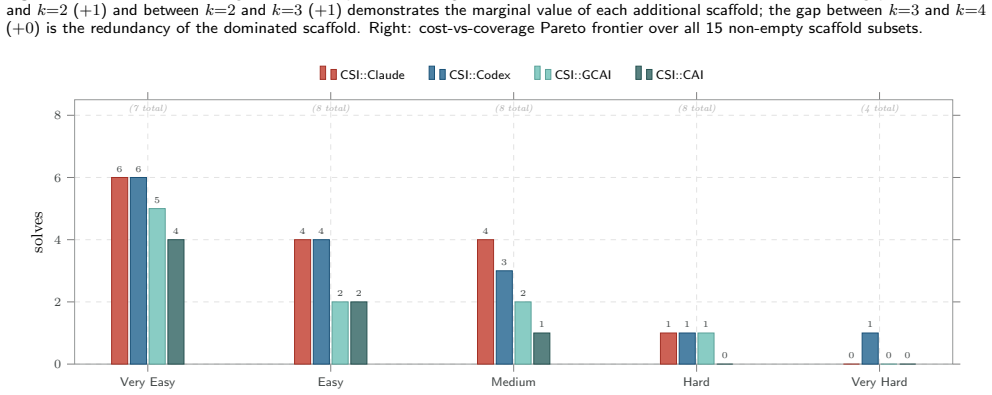
- No scaffold dominates every challenge type, so coverage improves only when heterogeneous designs are combined.
- The blackboard approach maintains comparable cost while reducing total runtime by about 25 percent.
Where Pith is reading between the lines
- The same blackboard pattern could be tested on real-world incident response logs rather than benchmark challenges.
- Adding further scaffolds or refining the sharing rules on the blackboard might increase the number of unique solves beyond 19.
- The result suggests that progress toward more capable cybersecurity AI may depend more on orchestration diversity than on improving any one harness.
Load-bearing premise
The 33 cybench challenges form a representative sample of cybersecurity tasks and the five scaffolds are different enough that parallel execution and blackboard sharing produce non-redundant solves.
What would settle it
Repeating the benchmark on a fresh collection of cybersecurity tasks outside the cybench set and finding that the blackboard no longer exceeds the best single scaffold.
Figures






read the original abstract
What is the best harness for cybersecurity AI? Cybersecurity systems are converging on a single execution scaffold per agent, an iterative shell loop driven by a Large Language Model (LLM). However, scaffolds are not interchangeable, rarely interoperable, and no single scaffold dominates across all challenge types. In our path towards researching Cybersecurity SuperIntelligence (CSI), we present a meta-scaffold that unifies heterogeneous agent harnesses under a common orchestration layer, enabling any LLM-driven scaffold to be deployed, benchmarked, and composed within the same infrastructure. Using CSI, we benchmark five scaffolds (CSI::Claude, CSI::Codex, CSI::GCAI, CSI::Mistral, CSI::CAI) on the 33 cybench challenges, holding the model fixed at alias2-mini. The best individual scaffolds solve 15/33 (45.5%); the four-scaffold union solves 17/33 (51.5%), with the fifth (CSI::Mistral, 10/33) contributing one exclusive solve. We find that no single scaffold is the best harness: it is the combination of structurally heterogeneous scaffolds that yields the highest coverage. We validate this through CSI's blackboard-based multi-agent architecture, in which scaffold-specialised agents run in parallel and exchange intermediate findings via a shared substrate (a blackboard). The blackboard solves 19/33 (57.6%), a 27% relative gain over CSI::Claude, one of the best individual scaffolds (15/33, 45.5%), 25% faster (20.2 h vs. 26.8 h), at comparable cost ($5,480 vs. $5,122).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CSI, a meta-scaffold unifying heterogeneous LLM-driven agent harnesses for cybersecurity tasks. It benchmarks five scaffolds (CSI::Claude, CSI::Codex, CSI::GCAI, CSI::Mistral, CSI::CAI) on the 33 Cybench challenges with fixed model alias2-mini. Key results: best single scaffold solves 15/33 (45.5%), four-scaffold union solves 17/33 (51.5%), and blackboard multi-agent architecture solves 19/33 (57.6%), achieving a 27% relative gain over the best single scaffold, 25% faster (20.2h vs 26.8h) at comparable cost ($5,480 vs $5,122). The central claim is that no single scaffold dominates and that structurally heterogeneous scaffolds combined via blackboard yield highest coverage.
Significance. If the empirical results hold under scrutiny, the work demonstrates that multi-harness orchestration leveraging scaffold heterogeneity can improve coverage on cybersecurity benchmarks without added cost, providing a concrete step toward Cybersecurity SuperIntelligence. It merits credit for using a public benchmark suite and reporting concrete solve counts, timing, and cost metrics. However, the absence of detailed methods substantially limits verifiability and immediate impact.
major comments (2)
- [Results section] Results section (and abstract): The manuscript reports concrete performance claims including 19/33 solves for the blackboard vs. 15/33 for the best single scaffold (CSI::Claude), but provides no experimental protocol, run parameters, success criteria for Cybench challenges, timeout handling, per-challenge attribution, or any statistical tests/error analysis/controls. This is load-bearing for the central claim of a 27% relative gain, as the numbers cannot be reproduced or assessed for robustness without these details.
- [Blackboard architecture] Blackboard architecture description: The paper states that the blackboard enables parallel execution and exchange of intermediate findings to produce non-redundant solves, but does not specify the exact orchestration rules, conflict resolution, or how scaffold outputs are integrated on the shared substrate. This detail is required to evaluate whether the reported 19/33 count follows from the heterogeneity premise or from unstated implementation choices.
minor comments (1)
- [Abstract] Abstract: The phrasing 'the four-scaffold union solves 17/33 (51.5%), with the fifth (CSI::Mistral, 10/33) contributing one exclusive solve' could be clarified to explicitly state whether the union includes all five or only four, to avoid ambiguity in interpreting the incremental contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that additional methodological details are required for reproducibility and will revise the manuscript to address both major comments. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Results section] Results section (and abstract): The manuscript reports concrete performance claims including 19/33 solves for the blackboard vs. 15/33 for the best single scaffold (CSI::Claude), but provides no experimental protocol, run parameters, success criteria for Cybench challenges, timeout handling, per-challenge attribution, or any statistical tests/error analysis/controls. This is load-bearing for the central claim of a 27% relative gain, as the numbers cannot be reproduced or assessed for robustness without these details.
Authors: We acknowledge that the current version lacks a complete experimental protocol, which limits verifiability of the reported solve counts. In the revised manuscript we will add a dedicated experimental setup subsection (and update the abstract) that specifies: (i) exact run parameters and model configurations for alias2-mini across all five scaffolds, (ii) Cybench success criteria and verification procedure, (iii) timeout and retry handling, (iv) per-challenge solve attribution table, and (v) any statistical controls or error analysis performed. These additions will allow independent reproduction of the 15/33, 17/33, and 19/33 figures while leaving the empirical claims unchanged. revision: yes
-
Referee: [Blackboard architecture] Blackboard architecture description: The paper states that the blackboard enables parallel execution and exchange of intermediate findings to produce non-redundant solves, but does not specify the exact orchestration rules, conflict resolution, or how scaffold outputs are integrated on the shared substrate. This detail is required to evaluate whether the reported 19/33 count follows from the heterogeneity premise or from unstated implementation choices.
Authors: We agree that the orchestration mechanics must be stated explicitly. The revised manuscript will expand the blackboard architecture section to describe: (i) the precise rules governing parallel execution of the five scaffold-specialised agents, (ii) the protocol for posting and reading intermediate findings on the shared substrate, (iii) conflict-resolution logic (priority weighting by per-scaffold historical accuracy plus consensus fallback), and (iv) the integration step that produces the final non-redundant solve set. This will make clear that the additional solves arise from scaffold heterogeneity rather than hidden implementation details. revision: yes
Circularity Check
No significant circularity; empirical benchmark results are self-contained
full rationale
The paper reports direct empirical measurements of solve rates on the external Cybench benchmark suite (33 challenges) using a fixed model (alias2-mini) across five scaffolds and a blackboard meta-scaffold. The central claims (e.g., best single scaffold at 15/33, blackboard at 19/33) are counts from execution runs, with no equations, fitted parameters, or derivations that reduce the reported deltas to inputs by construction. No self-citations are invoked as load-bearing for uniqueness or ansatzes, and the architecture description does not rename known results or smuggle assumptions via prior work. The derivation chain consists solely of experimental protocol and observed outcomes on an independent test set.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pentestgpt: Evaluating and harnessing large language models for automated penetration testing.33rd USENIX Security Symposium (USENIX Security 24), pages 847–864, 2024
Gelei Deng, Yi Liu, V´ ıctor Mayoral-Vilches, Peng Liu, Yuekang Li, Yuan Xu, Tianwei Zhang, Yang Liu, Martin Pinzger, and Stefan Rass. Pentestgpt: Evaluating and harnessing large language models for automated penetration testing.33rd USENIX Security Symposium (USENIX Security 24), pages 847–864, 2024
2024
-
[2]
V´ ıctor Mayoral-Vilches. Offensive robot cybersecurity. arXiv preprint arXiv:2506.15343, 2025
-
[3]
Cai fluency: A framework for cybersecurity ai fluency.arXiv e-prints, pages arXiv–2508, 2025
V´ ıctor Mayoral-Vilches, Jasmin Wachter, Crist´ obal RJ Veas Chavez, Cathrin Schachner, Luis Javier Navarrete- Lozano, and Mar´ ıa Sanz-G´ omez. Cai fluency: A framework for cybersecurity ai fluency.arXiv e-prints, pages arXiv–2508, 2025
2025
-
[4]
V´ ıctor Mayoral-Vilches, Mar´ ıa Sanz-G´ omez, Francesco Balassone, Stefan Rass, Lidia Salas-Espejo, Ben- jamin Jablonski, Luis Javier Navarrete-Lozano, Maite del Mundo de Torres, and Crist´ obal RJ Chavez. Cyber- security ai: A game-theoretic ai for guiding attack and defense.arXiv preprint arXiv:2601.05887, 2026
-
[5]
Measuring and augmenting large language models for solving capture-the-flag challenges
Zimo Ji, Daoyuan Wu, et al. Measuring and augmenting large language models for solving capture-the-flag challenges. InProceedings of the ACM Conference on Computer and Communications Security (CCS), pages 603–617, 2025. doi: 10.1145/3719027.3744855
-
[6]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.International Conference on Learning Representations (ICLR), 2023. URL https: //arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, R´ emi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pus...
-
[8]
Ranked voting based self-consistency of large language models.arXiv preprint arXiv:2505.10772,
Anonymous. Ranked voting based self-consistency of large language models. InFindings of the As- sociation for Computational Linguistics (ACL Find- ings), 2025. URL https://arxiv.org/abs/2505.10772. arXiv:2505.10772
-
[9]
CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative agents for “mind” exploration of large scale language model society.Advances in Neural Information Processing Systems (NeurIPS), 2023. URL https://arxiv.org/abs/2303.17760
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversations. InICLR 2024 Workshop on Large Language Model (LLM) Agents, 2024. URL https: //arxiv.org/abs/2...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and J¨ urgen Schmidhuber. MetaGPT: Meta programming for multi-agent collaborative framework. InInternational Conference on Learning Representations (ICLR), 2024. UR...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
ChatDev: Communicative Agents for Software Development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative agents for software development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024. URL https://arxiv.org/ abs/2307.07924
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chen-Ming Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, Yujia Qin, Xin Cong, Ruobing Xie, Zhiyuan Liu, Maosong Sun, and Jie Zhou. AgentVerse: Facilitating multi-agent collaboration and exploring emergent behaviors. InInternational Conference on Learning Representations (ICLR), 2024. URLht...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Scaling large language model-based multi-agent collab- oration.arXiv preprint arXiv:2406.07155, 2025
Chen Qian, Zihao Xie, Yifei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, Zhiyuan Liu, and Maosong Sun. Scaling large language model-based multi-agent collab- oration.arXiv preprint arXiv:2406.07155, 2025. URL https://arxiv.org/abs/2406.07155. MacNet, multi- agent DAG topology
-
[15]
Erman, Frederick Hayes-Roth, Victor R
Lee D. Erman, Frederick Hayes-Roth, Victor R. Lesser, and D. Raj Reddy. The Hearsay-II speech- understanding system: Integrating knowledge to resolve uncertainty.ACM Computing Surveys, 12(2):213–253,
-
[16]
doi: 10.1145/356810.356816
-
[17]
A blackboard architecture for control.Artificial Intelligence, 26(3):251–321, 1985
Barbara Hayes-Roth. A blackboard architecture for control.Artificial Intelligence, 26(3):251–321, 1985. doi: 10.1016/0004-3702(85)90063-3
-
[18]
Exploring advanced LLM multi-agent systems based on blackboard architecture
Bowen Han and Gang Zhang. Exploring advanced LLM multi-agent systems based on blackboard architecture. arXiv preprint arXiv:2507.01701, 2025. URL https: //arxiv.org/abs/2507.01701
-
[19]
Anonymous. LLM-based multi-agent blackboard system for information discovery in data science.arXiv preprint arXiv:2510.01285, 2024. URL https://arxiv.org/ abs/2510.01285
-
[20]
Yifeng He et al. Co-RedTeam: Orchestrated security discovery and exploitation with LLM agents.arXiv preprint arXiv:2602.02164, 2026. URL https://arxiv. org/abs/2602.02164
-
[21]
Claude code: an agentic coding tool that lives in your terminal
Anthropic. Claude code: an agentic coding tool that lives in your terminal. https://github.com/ anthropics/claude-code, 2025. Pinned to v2.1.87 for the experiments reported here
2025
-
[22]
RedTeamLLM: An agentic ai framework for offensive security.arXiv preprint arXiv:2505.06913, 2025
Brian Challita and Pierre Parrend. RedTeamLLM: An agentic ai framework for offensive security.arXiv preprint arXiv:2505.06913, 2025. URL https://arxiv. org/abs/2505.06913
-
[23]
Codex CLI: a lightweight coding agent that runs in your terminal
OpenAI. Codex CLI: a lightweight coding agent that runs in your terminal. https://github.com/openai/ codex, 2025. Pinned to v0.104.0 for the experiments reported here
2025
-
[24]
autoresearch: a self-improving ai researcher
Andrej Karpathy. autoresearch: a self-improving ai researcher. https://github.com/karpathy/ autoresearch, 2025. Accessed May 2026
2025
-
[25]
Mar´ ıa Sanz-G´ omez, V´ ıctor Mayoral-Vilches, Francesco Balassone, Luis Javier Navarrete-Lozano, Crist´ obal R. J. Veas Chavez, and Maite del Mundo de Torres. Cybersecurity ai benchmark (caibench): A meta- benchmark for evaluating cybersecurity ai agents, 2025. URLhttps://arxiv.org/abs/2510.24317
-
[26]
solve before 20% of budget
V´ ıctor Mayoral-Vilches, Mar´ ıa Sanz-G´ omez, and Endika Gil-Uriarte. Towards cybersecurity superintelligence. arXiv preprint, 2026. In preparation. Alias Robotics technical report; figures reproduced with permission of the authors. Challenge Claude Codex GCAI CAI avatar N N N N back to the past N N N Y crushing N N N N data siege N N N N delulu N N N N...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.