An Embarrassingly Simple Detector for Model Extraction Attacks in Large Language Model API Traffic
Pith reviewed 2026-06-28 00:56 UTC · model grok-4.3
The pith
Model extraction attacks on LLM APIs are detectable by testing whether windows of embedded queries deviate in distribution from historical benign traffic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
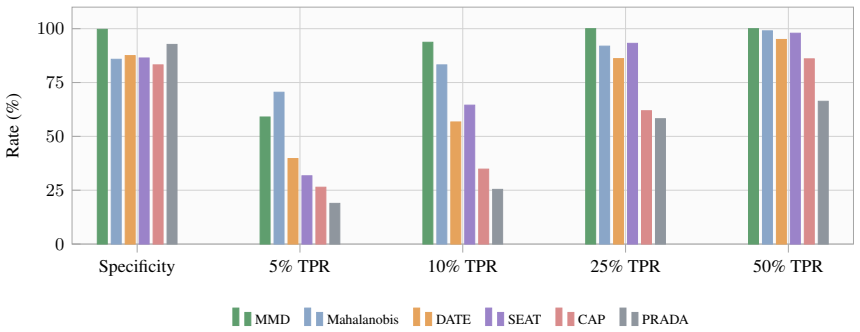
Model extraction monitoring formulated as benign-calibrated traffic-window distribution testing is effective: embed incoming queries into a semantic space and apply maximum mean discrepancy to test whether their aggregate distribution deviates from historical benign traffic. Using only benign-vs-benign comparisons to set thresholds, the detector reaches 0.3 percent benign FPR, 100.0 percent pure-attacker TPR, 90.5 percent average TPR over attacker fractions, and 95.1 percent balanced accuracy across fourteen attacker-normal pairs from four extraction scenarios.
What carries the argument
Maximum mean discrepancy (MMD) statistic computed on windows of semantic embeddings of queries, with decision threshold calibrated solely from historical benign traffic.
If this is right
- Detection remains effective when attackers constitute only a fraction of multi-user traffic rather than isolated accounts.
- Thresholds require no attack examples, only a stable history of benign queries.
- The approach applies to both per-user and pooled multi-user API traffic settings.
- The same embedding-plus-MMD pipeline outperforms several adapted single-query or marginal baselines on the evaluated extraction scenarios.
Where Pith is reading between the lines
- Periodic recomputation of the benign reference distribution could handle slow concept drift in normal usage patterns.
- The method might be combined with lightweight per-query checks to reduce the window size needed for reliable detection.
- If the chosen embedding space fails to separate certain extraction strategies, substituting a different embedding model would be a direct test of the framework's robustness.
Load-bearing premise
Attacker queries will reliably produce a measurable shift in the aggregate distribution of their semantic embeddings even when individual queries look normal and even when mixed with benign traffic.
What would settle it
An attacker who generates queries whose embedding distribution matches the historical benign distribution while still successfully extracting model parameters would falsify the detector if it produces no alert at the reported operating point.
Figures


read the original abstract
Large language models (LLMs) are increasingly deployed through hosted APIs, making model extraction a practical threat to model ownership and service security. However, individual extraction queries often resemble benign requests, and existing evaluations often focus on single-query anomaly scoring or pure benign-versus-attacker user settings. We formulate model extraction monitoring as benign-calibrated traffic-window distribution testing and show that an embarrassingly simple detector is effective: embed incoming queries into a semantic space and test whether their aggregate distribution deviates from historical benign traffic. We instantiate the detector with maximum mean discrepancy (MMD), using only benign-vs-benign comparisons to set the decision threshold. We evaluate on fourteen attacker-normal query pairs from four extraction scenarios and compare with adapted PRADA, SEAT, CAP, DATE, and marginal Mahalanobis baselines. Across three random seeds, MMD achieves 0.3% benign FPR, 100.0% pure-attacker TPR, 90.5% average TPR over attacker fractions, and 95.1% balanced accuracy. These results show that benign-calibrated distribution testing is a strong empirical baseline for model extraction detection in both user-level and mixed multi-user LLM API traffic. Code is released at: https://github.com/LabRAI/mmd-llm-mea-detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that model extraction attacks on LLM APIs can be detected via an embarrassingly simple approach: embed API queries into a semantic space and apply maximum mean discrepancy (MMD) to test whether the distribution of queries in a traffic window deviates from a reference distribution derived from historical benign traffic. The decision threshold is set exclusively using benign-vs-benign MMD comparisons. On fourteen attacker-normal query pairs drawn from four extraction scenarios, the method reports 0.3% benign FPR, 100% TPR on pure attackers, 90.5% average TPR across attacker fractions, and 95.1% balanced accuracy, outperforming adapted versions of PRADA, SEAT, CAP, DATE, and marginal Mahalanobis detectors. Code is released.
Significance. If the central empirical claims hold under the stationarity premise, the work supplies a strong, minimal, and reproducible baseline for monitoring mixed multi-user LLM API traffic. The emphasis on aggregate distribution testing rather than per-query scoring, together with the public code release, would make the result a useful reference point for future detection research.
major comments (2)
- [Evaluation] Evaluation section: the MMD threshold is calibrated exclusively via benign-vs-benign comparisons on historical traffic, yet the reported results (0.3% FPR, 95.1% balanced accuracy) are obtained on fixed, non-temporal datasets across the fourteen attacker-normal pairs with no temporal splits, long-window stability tests, or injected concept-drift experiments. This leaves the performance numbers conditional on the untested assumption that benign query distributions remain stationary.
- [Methodology] Methodology and experimental setup: insufficient detail is provided on the embedding model, window size and stride parameters, and the precise adaptations made to the five baseline detectors (PRADA, SEAT, CAP, DATE, marginal Mahalanobis). These choices are load-bearing for reproducing the reported performance numbers on the fourteen pairs.
minor comments (2)
- The abstract states that four extraction scenarios are considered but does not name them; this should be stated explicitly in the introduction or evaluation section for immediate clarity.
- Figure captions and table headers should explicitly state the number of random seeds and the exact attacker fractions used for the 90.5% average TPR figure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the MMD threshold is calibrated exclusively via benign-vs-benign comparisons on historical traffic, yet the reported results (0.3% FPR, 95.1% balanced accuracy) are obtained on fixed, non-temporal datasets across the fourteen attacker-normal pairs with no temporal splits, long-window stability tests, or injected concept-drift experiments. This leaves the performance numbers conditional on the untested assumption that benign query distributions remain stationary.
Authors: We acknowledge that this observation is correct. Our evaluation is conducted on fixed, non-temporal datasets constructed from the fourteen attacker-normal pairs, without temporal splits, long-window stability tests, or injected concept-drift experiments. The performance figures are therefore conditional on the untested stationarity assumption for benign traffic. While this premise is standard for many distribution-based detectors and our threshold calibration uses only benign data, we agree it constitutes a limitation. In the revised manuscript we will add an explicit limitations subsection discussing the stationarity assumption and its implications for real-world deployment. We will also report supplementary results across multiple window sizes and strides using the existing data to provide evidence of robustness to different temporal granularities. This is a partial revision. revision: partial
-
Referee: [Methodology] Methodology and experimental setup: insufficient detail is provided on the embedding model, window size and stride parameters, and the precise adaptations made to the five baseline detectors (PRADA, SEAT, CAP, DATE, marginal Mahalanobis). These choices are load-bearing for reproducing the reported performance numbers on the fourteen pairs.
Authors: We agree that the current level of detail is insufficient for full reproducibility. The manuscript describes the overall approach at a high level but does not specify the exact embedding model (including architecture or checkpoint), the numerical window sizes and strides used, or the precise modifications applied to adapt each of the five baselines to the traffic-window evaluation setting. In the revised manuscript we will expand the Methodology and Experimental Setup sections with these concrete details, including any necessary tables or pseudocode. This change will be made. revision: yes
Circularity Check
No significant circularity; derivation is self-contained empirical evaluation
full rationale
The paper formulates detection as MMD-based distribution testing between query embeddings and a historical benign reference, with the threshold set exclusively via benign-vs-benign comparisons and performance measured on separate attacker scenarios. No equations or steps reduce a claimed result to its own inputs by construction, no self-citations are load-bearing for the central claim, and no uniqueness theorems or ansatzes are smuggled in. The reported metrics (0.3% FPR, 95.1% balanced accuracy) follow directly from the described experimental protocol on the fourteen attacker-normal pairs rather than from any definitional or fitted circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Maximum mean discrepancy is a valid kernel-based statistic for detecting differences between distributions in embedding space.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Orekondy, Tribhuvanesh and Schiele, Bernt and Fritz, Mario , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[2]
Advances in Neural Information Processing Systems , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , volume =
-
[3]
On the Opportunities and Risks of Foundation Models
On the Opportunities and Risks of Foundation Models , author =. arXiv preprint arXiv:2108.07258 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2506.22521 , year =
A Survey on Model Extraction Attacks and Defenses for Large Language Models , author =. arXiv preprint arXiv:2506.22521 , year =
-
[5]
Stealing Machine Learning Models via Prediction
Florian Tram. Stealing Machine Learning Models via Prediction. 25th USENIX Security Symposium (USENIX Security 16) , year =
-
[6]
, booktitle=
Juuti, Mika and Szyller, Sebastian and Marchal, Samuel and Asokan, N. , booktitle=. PRADA: Protecting Against DNN Model Stealing Attacks , year=
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Query-Efficient Domain Knowledge Stealing Against Large Language Models , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2026 , doi =
2026
-
[8]
WildChat: 1M ChatGPT Interaction Logs in the Wild
WildChat: 1M ChatGPT Interaction Logs in the Wild , author =. arXiv preprint arXiv:2405.01470 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2309.10544 , year =
Model Leeching: An Extraction Attack Targeting LLMs , author =. arXiv preprint arXiv:2309.10544 , year =
-
[10]
Dai, Chengwei and Lv, Minxuan and Li, Kun and Zhou, Wei , booktitle =
-
[11]
and Papernot, Nicolas and Iyyer, Mohit , booktitle =
Krishna, Kalpesh and Tomar, Gaurav Singh and Parikh, Ankur P. and Papernot, Nicolas and Iyyer, Mohit , booktitle =. Thieves on Sesame Street! Model Extraction of
-
[12]
Pointer Sentinel Mixture Models
Pointer Sentinel Mixture Models , author =. arXiv preprint arXiv:1609.07843 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy , booktitle =
-
[14]
Advances in Neural Information Processing Systems , volume =
Character-level Convolutional Networks for Text Classification , author =. Advances in Neural Information Processing Systems , volume =
-
[15]
Proceedings of the International AAAI Conference on Web and Social Media , volume =
Automated Hate Speech Detection and the Problem of Offensive Language , author =. Proceedings of the International AAAI Conference on Web and Social Media , volume =
-
[16]
Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing , pages =
Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank , author =. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing , pages =
2013
-
[17]
Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages =
Learning Word Vectors for Sentiment Analysis , author =. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages =
-
[18]
, booktitle =
Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R. , booktitle =
-
[19]
Clark, Christopher and Lee, Kenton and Chang, Ming-Wei and Kwiatkowski, Tom and Collins, Michael and Toutanova, Kristina , booktitle =
-
[20]
2023 , eprint =
C-Pack: Packaged Resources To Advance General Chinese Embedding , author =. 2023 , eprint =
2023
-
[21]
Journal of Machine Learning Research , volume =
A Kernel Two-Sample Test , author =. Journal of Machine Learning Research , volume =
-
[22]
Zhang, Zhanyuan and Chen, Yizheng and Wagner, David , booktitle =
-
[23]
Stealing and Defending the Ends of
Kulkarni, Nupur and Boenisch, Franziska and Dziedzic, Adam , year =. Stealing and Defending the Ends of
-
[24]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Revisiting Mahalanobis Distance for Transformer-Based Out-of-Domain Detection , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2021 , doi =
2021
-
[25]
2021 , address =
Manolache, Andrei and Brad, Florin and Burceanu, Elena , booktitle =. 2021 , address =
2021
-
[26]
Proceedings of the 41st International Conference on Machine Learning , series =
Stealing Part of a Production Language Model , author =. Proceedings of the 41st International Conference on Machine Learning , series =
-
[27]
ACM Transactions on Information and System Security , volume =
Clustering Intrusion Detection Alarms to Support Root Cause Analysis , author =. ACM Transactions on Information and System Security , volume =. 2003 , publisher =
2003
-
[28]
Proceedings of the Human Factors and Ergonomics Society Annual Meeting , volume =
A Controlled Experiment on the Impact of Intrusion Detection False Alarm Rate on Analyst Performance , author =. Proceedings of the Human Factors and Ergonomics Society Annual Meeting , volume =. 2023 , publisher =
2023
-
[29]
Distilling the Knowledge in a Neural Network
Distilling the Knowledge in a Neural Network , author =. arXiv preprint arXiv:1503.02531 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security , pages =
Practical Black-Box Attacks against Machine Learning , author =. Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security , pages =. 2017 , publisher =
2017
-
[31]
Proceedings of the 29th USENIX Security Symposium , pages =
High Accuracy and High Fidelity Extraction of Neural Networks , author =. Proceedings of the 29th USENIX Security Symposium , pages =. 2020 , publisher =
2020
-
[32]
Proceedings of the 29th USENIX Security Symposium , pages =
Exploring Connections Between Active Learning and Model Extraction , author =. Proceedings of the 29th USENIX Security Symposium , pages =. 2020 , publisher =
2020
-
[33]
Proceedings of the 27th USENIX Security Symposium , pages =
Turning Your Weakness into a Strength: Watermarking Deep Neural Networks by Backdooring , author =. Proceedings of the 27th USENIX Security Symposium , pages =. 2018 , publisher =
2018
-
[34]
, booktitle =
Szyller, Sebastian and Atli, Buse Gul and Marchal, Samuel and Asokan, N. , booktitle =. 2021 , publisher =
2021
-
[35]
Advances in Neural Information Processing Systems , volume =
A Kernel Method for the Two-Sample-Problem , author =. Advances in Neural Information Processing Systems , volume =
-
[36]
International Conference on Learning Representations , year =
Generative Models and Model Criticism via Optimized Maximum Mean Discrepancy , author =. International Conference on Learning Representations , year =
-
[37]
Neural Computation , volume =
Estimating the Support of a High-Dimensional Distribution , author =. Neural Computation , volume =. 2001 , doi =
2001
-
[38]
International Conference on Learning Representations , year =
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks , author =. International Conference on Learning Representations , year =
-
[39]
Advances in Neural Information Processing Systems , volume =
A Simple Unified Framework for Detecting Out-of-Distribution Samples and Adversarial Attacks , author =. Advances in Neural Information Processing Systems , volume =
-
[40]
Proceedings of the 35th International Conference on Machine Learning , series =
Deep One-Class Classification , author =. Proceedings of the 35th International Conference on Machine Learning , series =
-
[41]
Advances in Neural Information Processing Systems , volume =
Energy-Based Out-of-Distribution Detection , author =. Advances in Neural Information Processing Systems , volume =
-
[42]
Sentence-
Reimers, Nils and Gurevych, Iryna , booktitle =. Sentence-. 2019 , publisher =
2019
-
[43]
2021 , publisher =
Gao, Tianyu and Yao, Xingcheng and Chen, Danqi , booktitle =. 2021 , publisher =
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.