VeRO: A Harness for Agents to Optimize Agents
Pith reviewed 2026-05-15 18:59 UTC · model grok-4.3
The pith
VERO supplies a reproducible harness with versioned snapshots and structured traces to compare how agents optimize other agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
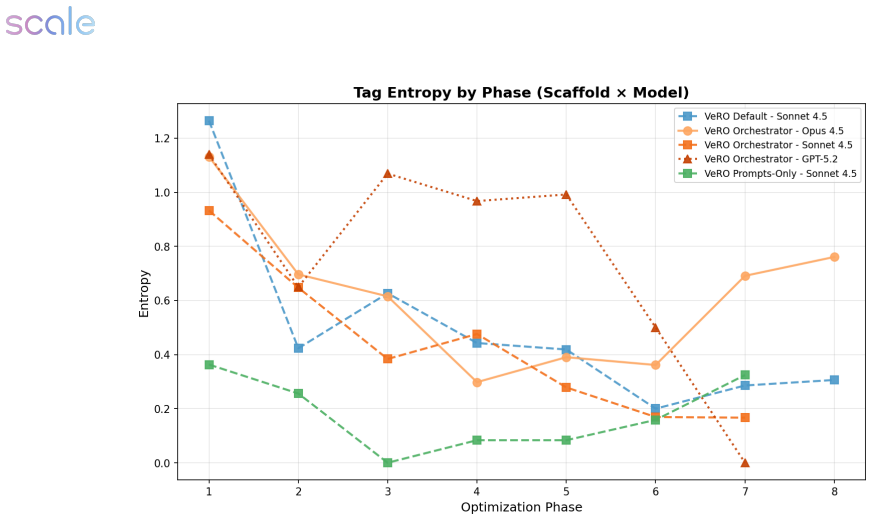
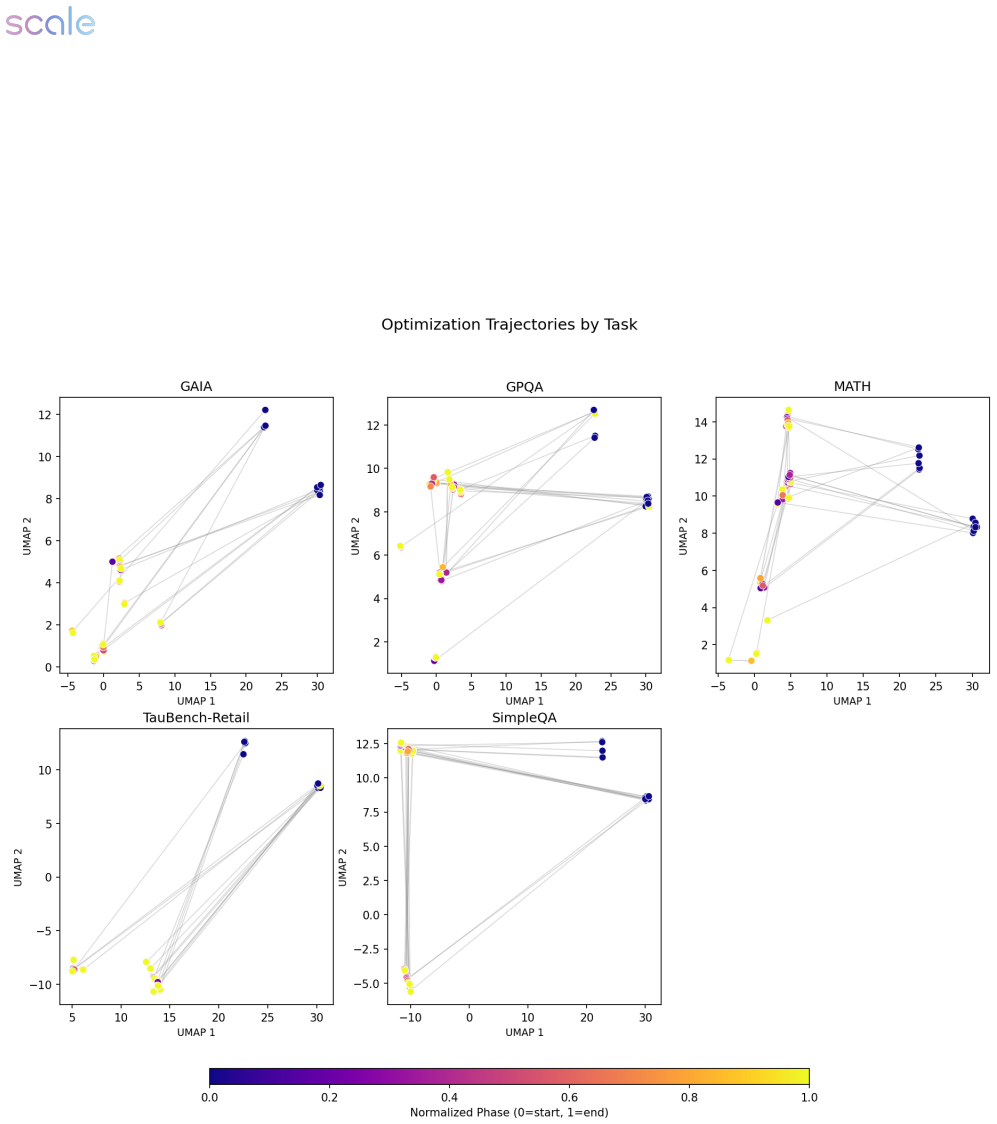
VERO provides a reproducible evaluation harness featuring versioned agent snapshots, budget-controlled evaluation, and structured execution traces, together with a benchmark suite of target agents and tasks that include reference evaluation procedures. Using this harness, the authors conduct an empirical study that compares different optimizer configurations across tasks and identifies which modifications reliably improve the performance of the target agents being optimized.
What carries the argument
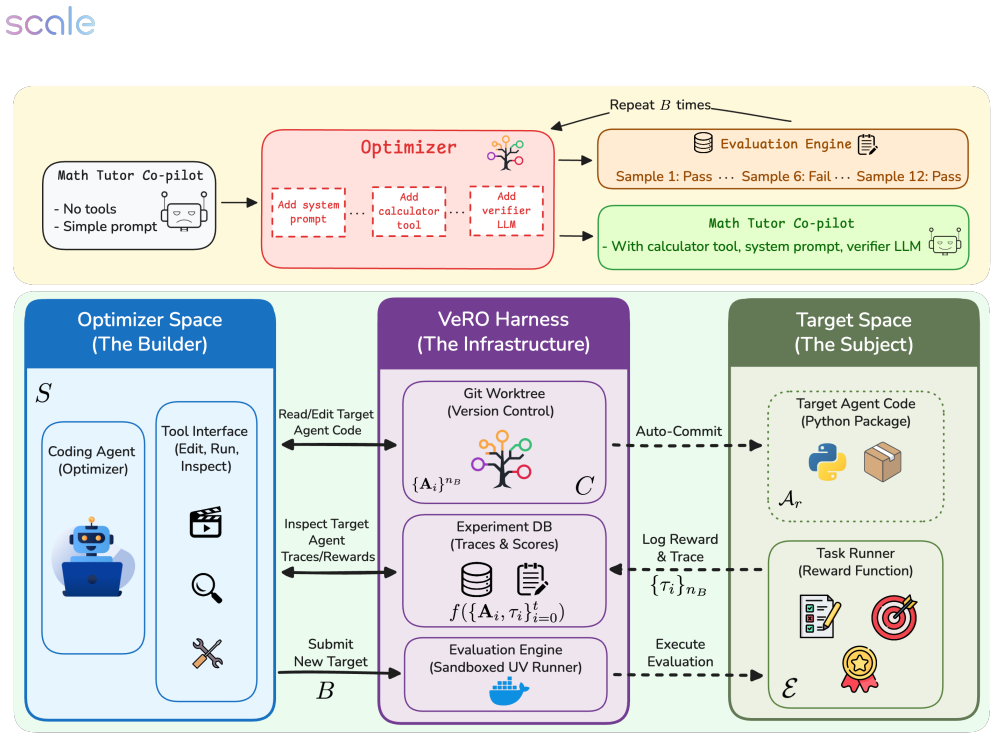
The VERO harness, which supplies versioned agent snapshots, budget-controlled evaluation runs, and structured traces of both reasoning and execution outcomes to support consistent comparisons of agent optimizers.
If this is right
- Different optimizer modifications can be tested systematically for their effect on target agent performance across tasks.
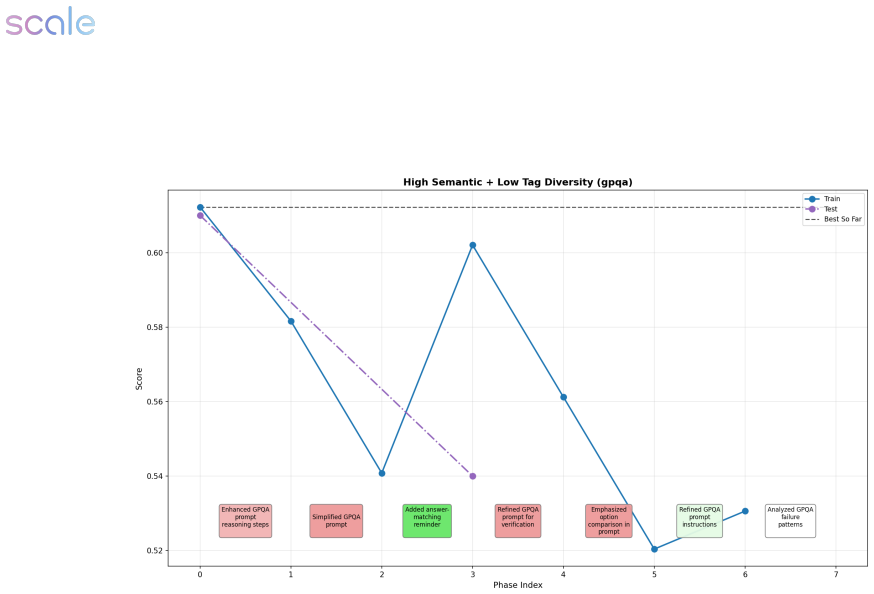
- Structured traces make it possible to examine why particular edits succeed or fail during optimization cycles.
- The benchmark suite supplies standardized reference procedures that future work can use for direct comparison.
- Budget limits allow measurement of both performance gains and the computational cost of different optimizer approaches.
Where Pith is reading between the lines
- The same versioning and trace approach could be adapted to create harnesses for optimizing non-coding agents in other domains.
- Results from VERO-style studies could guide the design of meta-level agents that perform self-optimization over repeated iterations.
- Consistent findings across tasks may point to general editing strategies that work regardless of the specific target agent.
Load-bearing premise
That structured capture of intermediate reasoning and downstream execution outcomes together with budget-controlled evaluation is necessary and sufficient to produce reliable comparisons of agent optimizers.
What would settle it
An experiment in which optimizer rankings and improvement claims derived from final performance scores alone match or contradict the rankings obtained when the same comparisons are run with VERO's versioning, traces, and budget controls.
Figures








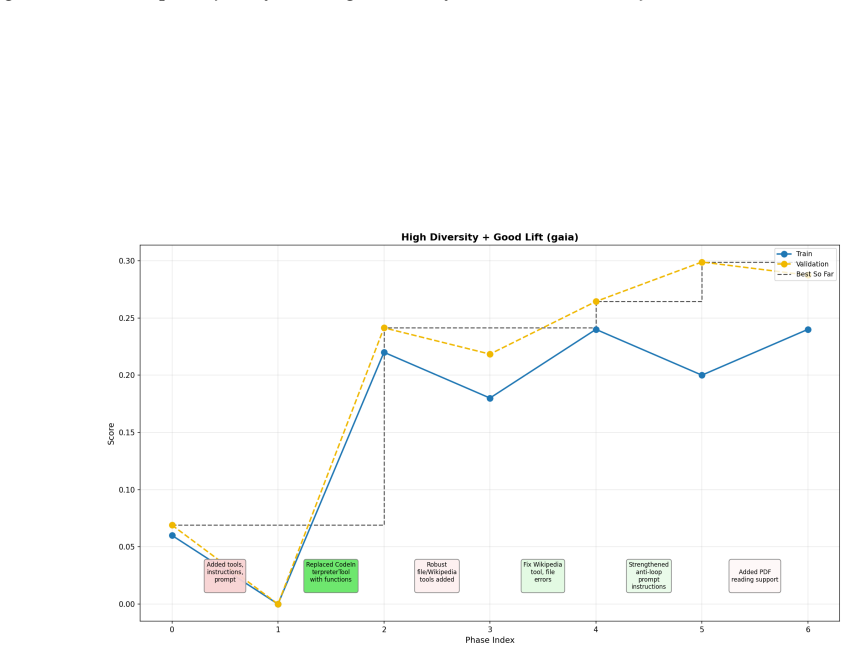

read the original abstract
An important emerging application of coding agents is agent harness optimization: the iterative improvement of a target agent by editing and evaluating its code. Despite its relevance, the community lacks a systematic understanding of coding agent performance on this task. Harness optimization differs from conventional software engineering: agent harnesses interleave deterministic code with stochastic LLM completions, requiring structured capture of both intermediate execution traces and downstream outcomes. To address these challenges, we introduce (1) VeRO (Versioning, Rewards, and Observations), an outer harness that provides versioned snapshots, budget-controlled evaluation, and structured execution traces of target harnesses, and (2) VeRO-Bench, a benchmark suite of target agents and tasks with reference evaluation procedures. Using VeRO, we conduct an empirical study comparing optimizers across tasks and analyzing which modifications reliably improve target agent harnesses. We release VeRO to support research on agent optimization as a core capability for coding agents. Code is available at https://github.com/scaleapi/vero.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VERO (Versioning, Rewards, and Observations), an evaluation harness for agent optimization—the iterative improvement of a target agent by a coding agent through edit-execute-evaluate cycles. VERO supplies versioned agent snapshots, budget-controlled evaluation, structured execution traces capturing both intermediate reasoning and downstream outcomes, and a benchmark suite of target agents and tasks with reference procedures. Using the harness, the authors perform an empirical study that compares optimizer configurations across tasks and identifies which modifications reliably improve target-agent performance; the harness is released to support further research.
Significance. If the empirical findings prove robust, the work supplies a missing standardized framework for a task that differs from conventional software engineering because of the interleaving of deterministic code with stochastic LLM completions. A reproducible harness with explicit versioning, budget controls, and structured traces could enable systematic, comparable experiments on agent optimizers, thereby accelerating progress on an emerging capability for coding agents.
major comments (2)
- [Empirical study (abstract and §4)] The central empirical claim—that certain modifications 'reliably improve target agent performance'—is load-bearing for the paper's contribution yet rests on an analysis whose statistical foundation is not described. No trial counts, per-configuration variance, error bars, exclusion criteria, or hypothesis tests are reported, despite the acknowledged stochasticity of LLM completions inside the target agents. This directly affects the validity of the 'reliably' qualifier.
- [§3 (VERO harness definition)] The harness description (versioned snapshots, budget-controlled evaluation, structured traces) is presented at a high level without concrete implementation details or pseudocode for the core loop that interleaves deterministic code with stochastic LLM steps. Without these, it is impossible to verify that the harness actually enforces the reproducibility and budget controls asserted in the abstract.
minor comments (2)
- [Introduction] The distinction drawn in the introduction between agent optimization and conventional software engineering would be clearer if illustrated by a short, concrete example of an edit-execute-evaluate cycle that produces an intermediate reasoning trace.
- [Conclusion / artifact statement] The manuscript states that VERO is released but does not include a permanent artifact link or DOI; this should be added for the camera-ready version.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Empirical study (abstract and §4)] The central empirical claim—that certain modifications 'reliably improve target agent performance'—is load-bearing for the paper's contribution yet rests on an analysis whose statistical foundation is not described. No trial counts, per-configuration variance, error bars, exclusion criteria, or hypothesis tests are reported, despite the acknowledged stochasticity of LLM completions inside the target agents. This directly affects the validity of the 'reliably' qualifier.
Authors: We agree that the statistical foundation of the empirical study in §4 requires explicit description to substantiate the claims. In the revised manuscript we will report the exact number of independent trials run per optimizer configuration, include per-configuration variance and error bars on all performance metrics, specify exclusion criteria for outlier runs, and detail any hypothesis tests used to evaluate whether observed improvements are reliable given the stochasticity of LLM completions. revision: yes
-
Referee: [§3 (VERO harness definition)] The harness description (versioned snapshots, budget-controlled evaluation, structured traces) is presented at a high level without concrete implementation details or pseudocode for the core loop that interleaves deterministic code with stochastic LLM steps. Without these, it is impossible to verify that the harness actually enforces the reproducibility and budget controls asserted in the abstract.
Authors: We acknowledge that §3 currently provides only a high-level description. In the revised manuscript we will add concrete implementation details and pseudocode for the core edit-execute-evaluate loop, explicitly documenting how versioned snapshots are created and restored, how evaluation budgets are enforced, how structured traces record both intermediate LLM reasoning and final execution outcomes, and the mechanisms that maintain reproducibility despite stochastic LLM steps. revision: yes
Circularity Check
No circularity: harness introduction and empirical demonstration are self-contained
full rationale
The paper presents VERO as a new evaluation harness with versioning, rewards, observations, budget control, and structured traces, then uses it for an empirical comparison of optimizer configurations on target agents and tasks. No equations, fitted parameters, predictions, or uniqueness theorems appear in the provided text. The central claim is the release of the harness plus a demonstration study; neither reduces by construction to its own inputs, self-citations, or renamed known results. The work is an engineering contribution whose validity rests on external reproducibility of the released code and benchmarks rather than any internal derivation loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agent optimization differs fundamentally from conventional software engineering because the target interleaves deterministic code with stochastic LLM completions.
invented entities (1)
-
VERO harness
no independent evidence
Forward citations
Cited by 3 Pith papers
-
Towards Direct Evaluation of Harness Optimizers via Priority Ranking
Priority ranking offers a low-cost direct evaluation for harness optimizers that correlates with their real multi-step optimization performance, supported by the Shor dataset of 182 scenarios.
-
Insights Generator: Systematic Corpus-Level Trace Diagnostics for LLM Agents
Insights Generator is a multi-agent system that produces evidence-backed natural-language reports characterizing systematic patterns across populations of LLM agent execution traces.
-
Insights Generator: Systematic Corpus-Level Trace Diagnostics for LLM Agents
Insights Generator is a multi-agent system that generates evidence-backed natural-language insights characterizing systematic patterns across corpora of LLM agent execution traces.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.