Bayesian-Agent: Posterior-Guided Skill Evolution for LLM Agent Harnesses
Pith reviewed 2026-06-27 19:24 UTC · model grok-4.3
The pith
Bayesian-Agent maintains a feature-conditioned categorical posterior over each LLM agent skill based on verified trajectories and uses it to decide actions like patch, split, compress, retire, or explore.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
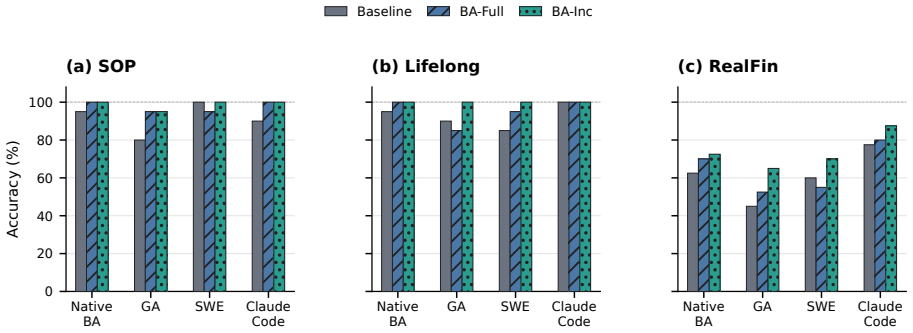
Bayesian-Agent records verified trajectory evidence, maintains a feature-conditioned categorical posterior over each skill, and maps posterior state into inspectable actions such as patch, split, compress, retire, and explore; with deepseek-v4-flash this produces SOP-Bench gains from 80% to 95%, Lifelong AgentBench from 90% to 100%, and RealFin-Bench from 45% to 65%.
What carries the argument
The feature-conditioned categorical posterior over skills, which converts accumulated trajectory evidence into a probability distribution used to select evolution actions.
Load-bearing premise
Verified trajectory evidence collected under the current harness is sufficient to produce a stable posterior that generalizes to future tasks and harness changes.
What would settle it
Running the same benchmarks with a version that replaces posterior updates by simple success-count heuristics and measuring whether the performance gaps disappear.
Figures




read the original abstract
LLM agents increasingly rely on external inference conditions: prompts, tools, memory, SOPs, skills, and harness feedback. These assets can improve task execution without changing model weights, but they are often revised by heuristic reflection or by reusing observed successes and failures as if counts alone were reliable belief. We introduce \textbf{Bayesian-Agent}, a native and cross-harness framework that treats reusable skills and SOPs as hypotheses about whether a frozen model will succeed under a particular prompt, context, and harness environment. Bayesian-Agent records verified trajectory evidence, maintains a feature-conditioned categorical posterior over each skill, and maps posterior state into inspectable actions such as patch, split, compress, retire, and explore. Model-facing prompts receive executable guardrails and failure-mode patches, while posterior summaries remain available for audit. With \texttt{deepseek-v4-flash}, incremental repair improves SOP-Bench from 80\% to 95\%, Lifelong AgentBench from 90\% to 100\%, and RealFin-Bench from 45\% to 65\%. We further evaluate Bayesian-Agent's native backend and optional GenericAgent, mini-swe-agent, and Claude Code backends. The results include positive, negative, saturated, and case-study settings, suggesting that agent skill evolution is best viewed as posterior-guided harness optimization rather than uncalibrated prompt accumulation. The source code is available at https://github.com/DataArcTech/Bayesian-Agent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Bayesian-Agent, a cross-harness framework that treats skills and SOPs as hypotheses and maintains a feature-conditioned categorical posterior over them using verified trajectory evidence. Posterior state is mapped to inspectable actions (patch, split, compress, retire, explore) that produce guardrails and patches for model-facing prompts. With deepseek-v4-flash the authors report concrete lifts on SOP-Bench (80%→95%), Lifelong AgentBench (90%→100%), and RealFin-Bench (45%→65%), and evaluate native, GenericAgent, mini-swe-agent, and Claude Code backends. Code is released at the cited GitHub repository.
Significance. If the posterior-guided mechanism is shown to be the operative driver, the work supplies a more auditable and potentially stable alternative to heuristic reflection for evolving agent assets. The availability of source code and the evaluation across multiple backends and positive/negative/saturated regimes are concrete strengths that would support follow-on verification.
major comments (2)
- [Abstract] Abstract (paragraph on posterior maintenance): the headline benchmark gains are presented as resulting from the feature-conditioned categorical posterior, yet no ablation is described that holds the repair actions fixed while replacing the posterior update with a simpler baseline (raw success counts or heuristic reflection). Without this isolation the numerical improvements cannot be attributed specifically to the Bayesian component rather than to the incremental repair loop itself.
- [Abstract] Abstract: the reported lifts (e.g., 80%→95% on SOP-Bench) are given without error bars, number of runs, or variance estimates, and the text provides no description of how features are selected for the posterior or how many trajectories are required for stability. These omissions directly affect the claim that the posterior generalizes to future tasks and harness changes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on attribution and statistical rigor. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on posterior maintenance): the headline benchmark gains are presented as resulting from the feature-conditioned categorical posterior, yet no ablation is described that holds the repair actions fixed while replacing the posterior update with a simpler baseline (raw success counts or heuristic reflection). Without this isolation the numerical improvements cannot be attributed specifically to the Bayesian component rather than to the incremental repair loop itself.
Authors: We agree the abstract does not isolate the posterior update from the repair loop. The manuscript describes the feature-conditioned categorical posterior and its mapping to actions but lacks a controlled ablation holding actions fixed against a raw-count or heuristic baseline. We will add this ablation in the revised version, reporting results under identical repair actions to attribute gains specifically to the Bayesian mechanism. revision: yes
-
Referee: [Abstract] Abstract: the reported lifts (e.g., 80%→95% on SOP-Bench) are given without error bars, number of runs, or variance estimates, and the text provides no description of how features are selected for the posterior or how many trajectories are required for stability. These omissions directly affect the claim that the posterior generalizes to future tasks and harness changes.
Authors: The abstract is a concise summary and omits these details. The full manuscript reports results across multiple backends and regimes but does not explicitly state run counts, error bars, feature selection, or stability thresholds in the abstract. We will revise the abstract and add a dedicated experimental-details subsection (or appendix) specifying the number of runs, variance estimates, feature-selection criteria, and trajectory requirements for posterior stability to support generalization claims. revision: yes
Circularity Check
No significant circularity; empirical framework evaluated on external benchmarks
full rationale
The paper defines Bayesian-Agent as a new framework that records verified trajectories to maintain a feature-conditioned categorical posterior over skills and maps it to actions such as patch or retire. Reported gains (SOP-Bench 80% to 95%, etc.) are presented as measured outcomes on external benchmarks rather than quantities derived from internal equations or self-cited priors. No load-bearing step reduces the posterior mechanism or the benchmark deltas to a tautology, fitted input renamed as prediction, or self-citation chain. The derivation is therefore self-contained as an independently specified method whose claims rest on observable external results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Verified trajectories provide unbiased evidence for updating the categorical posterior over each skill.
Reference graph
Works this paper leans on
-
[1]
Liang, Jiaqing and Han, Jinyi and Li, Weijia and Wang, Xinyi and Zhang, Zhoujia and Jiang, Zishang and Liao, Ying and Li, Tingyun and Huang, Ying and Shen, Hao and others , year =. 2604.17091 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
2026 , doi =
Huang, Hengguan and Shen, Xing and Hao, Guang-Yuan and Wang, Songtao and Meng, Lingfa and Liu, Dianbo and Duchene, David Alejandro and Wang, Hao and Bhatt, Samir , journal =. 2026 , doi =
2026
-
[3]
2023 , url =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , url =
2023
-
[4]
2023 , url =
Schick, Timo and Dwivedi-Yu, Jane and Dessi, Roberto and Raileanu, Roberta and Lomeli, Maria and Hambro, Eric and Zettlemoyer, Luke and Cancedda, Nicola and Scialom, Thomas , booktitle =. 2023 , url =
2023
-
[5]
Advances in Neural Information Processing Systems , volume =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[6]
2023 , eprint =
Voyager: An Open-Ended Embodied Agent with Large Language Models , author =. 2023 , eprint =
2023
-
[7]
Transactions on Machine Learning Research , year =
Cognitive Architectures for Language Agents , author =. Transactions on Machine Learning Research , year =
-
[8]
and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik , booktitle =
Yang, John and Jimenez, Carlos E. and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik , booktitle =. 2024 , url =
2024
-
[9]
2025 , url =
Wang, Xingyao and Jiang, Boxuan and Lu, Ziniu and Liu, Yufan and Li, Abishek Sridhar and Shi, Bolun and Fang, Jiannan and Mohanty, Rithvik and Muennighoff, Niklas and Ren, Kaixuan and others , booktitle =. 2025 , url =
2025
-
[10]
2024 , url =
Hong, Sirui and Zhuge, Mingchen and Chen, Jonathan and Zheng, Xiawu and Cheng, Yuheng and Zhang, Ceyao and Wang, Jinlin and Wang, Zili and Yau, Steven Ka Shing and Lin, Zijuan and others , booktitle =. 2024 , url =
2024
-
[11]
and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Bisk, Yonatan and Fried, Daniel and Alon, Uri and others , booktitle =
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Bisk, Yonatan and Fried, Daniel and Alon, Uri and others , booktitle =. 2024 , url =
2024
-
[12]
2024 , url =
Mialon, Gregoire and Fourrier, Clementine and Swift, Craig and Wolf, Thomas and LeCun, Yann and Scialom, Thomas , booktitle =. 2024 , url =
2024
-
[13]
2023 , url =
Deng, Xiang and Gu, Yu and Zheng, Boyuan and Chen, Shijie and Stevens, Samuel and Wang, Boshi and Sun, Huan and Su, Yu , booktitle =. 2023 , url =
2023
-
[14]
MemGPT: Towards LLMs as Operating Systems
Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G. and Stoica, Ion and Gonzalez, Joseph E. , year =. 2310.08560 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
2024 , url =
Zhao, Andrew and Huang, Daniel and Xu, Quentin and Lin, Matthieu and Liu, Yong-Jin and Huang, Gao , booktitle =. 2024 , url =
2024
-
[16]
2024 , doi =
Zhang, Wenqi and Tang, Ke and Wu, Hai and Wang, Mengna and Shen, Yongliang and Hou, Guiyang and Tan, Zeqi and Li, Peng and Zhuang, Yueting and Lu, Weiming , booktitle =. 2024 , doi =
2024
-
[17]
Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , pages =
Generative Agents: Interactive Simulacra of Human Behavior , author =. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , pages =. 2023 , doi =
2023
-
[18]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Li, Xiangyi and Chen, Wenbo and Liu, Yimin and Zheng, Shenghan and Chen, Xiaokun and He, Yifeng and Li, Yubo and You, Bingran and Shen, Haotian and Sun, Jiankai and others , year =. 2602.12670 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Zheng, Boyuan and Fatemi, Michael Y. and Jin, Xiaolong and Wang, Zora Zhiruo and Gandhi, Apurva and Song, Yueqi and Gu, Yu and Srinivasa, Jayanth and Liu, Gaowen and Neubig, Graham and Su, Yu , year =. 2504.07079 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Ye, Anbang and Ma, Qianran and Chen, Jia and Li, Muqi and Li, Tong and Liu, Fujiao and Mai, Siqi and Lu, Meichen and Bao, Haitao and You, Yang , year =. 2501.09316 , archivePrefix =
-
[21]
Chen, Tianyi and Li, Yinheng and Solodko, Michael and Wang, Sen and Jiang, Nan and Cui, Tingyuan and Hao, Junheng and Ko, Jongwoo and Abdali, Sara and Xu, Leon and others , year =. 2601.21123 , archivePrefix =
-
[22]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
Zhang, Haozhen and Long, Quanyu and Bao, Jianzhu and Feng, Tao and Zhang, Weizhi and Yue, Haodong and Wang, Wenya , year =. 2602.02474 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Nandi, Subhrangshu and Datta, Arghya and Nama, Rohith and Patel, Udita and Vichare, Nikhil and Bhattacharya, Indranil and Grover, Prince and Asija, Shivam and Carenini, Giuseppe and Zhang, Wei and Gupta, Arushi and Bhaduri, Sreyoshi and Xu, Jing and Raja, Huzefa and Ray, Shayan and Chan, Aaron and Fei, Esther Xu and Du, Gaoyuan and Akhtar, Zuhaib and Asna...
-
[24]
arXiv preprint arXiv:2505.11942 , year=
Zheng, Junhao and Cai, Xidi and Li, Qiuke and Zhang, Duzhen and Li, ZhongZhi and Zhang, Yingying and Song, Le and Ma, Qianli , year =. 2505.11942 , archivePrefix =
-
[25]
RealFin: How Well Do LLMs Reason About Finance When Users Leave Things Unsaid?
Dai, Yuyang and Lin, Yan and Xie, Zhuohan and Wang, Yuxia , year =. 2602.07096 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Transactions of the Association for Computational Linguistics , year =
Lost in the Middle: How Language Models Use Long Contexts , author =. Transactions of the Association for Computational Linguistics , year =
-
[27]
Why Does the Effective Context Length of
An, Chenxin and Zhang, Jun and Zhong, Ming and Li, Lei and Gong, Shansan and Luo, Yao and Xu, Jingjing and Kong, Lingpeng , booktitle =. Why Does the Effective Context Length of. 2025 , url =
2025
-
[28]
2024 , doi =
Jiang, Huiqiang and Wu, Qianhui and Luo, Xufang and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili , booktitle =. 2024 , doi =
2024
-
[29]
Proceedings of the IEEE , volume =
Taking the Human Out of the Loop: A Review of Bayesian Optimization , author =. Proceedings of the IEEE , volume =. 2016 , doi =
2016
-
[30]
Advances in Neural Information Processing Systems , volume =
Practical Bayesian Optimization of Machine Learning Algorithms , author =. Advances in Neural Information Processing Systems , volume =. 2012 , url =
2012
-
[31]
2018 , eprint =
A Tutorial on Bayesian Optimization , author =. 2018 , eprint =
2018
-
[32]
Advances in Neural Information Processing Systems , volume =
Algorithms for Hyper-Parameter Optimization , author =. Advances in Neural Information Processing Systems , volume =. 2011 , url =
2011
-
[33]
2006 , url =
Gaussian Processes for Machine Learning , author =. 2006 , url =
2006
-
[34]
2012 , url =
Machine Learning: A Probabilistic Perspective , author =. 2012 , url =
2012
-
[35]
2009 , url =
Probabilistic Graphical Models: Principles and Techniques , author =. 2009 , url =
2009
-
[36]
2025 , url =
Feng, Yu and Zhou, Ben and Lin, Weidong and Roth, Dan , booktitle =. 2025 , url =
2025
-
[37]
International Conference on Machine Learning , pages =
On Calibration of Modern Neural Networks , author =. International Conference on Machine Learning , pages =. 2017 , url =
2017
-
[38]
Xiong, Miao and Hu, Zhiyuan and Lu, Xinyang and Li, Yifei and Fu, Jie and He, Junxian and Hooi, Bryan , booktitle =. Can. 2024 , url =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.