Agentic Clustering: Controllable Text Taxonomies via Multi-Agent Refinement
Pith reviewed 2026-06-28 17:29 UTC · model grok-4.3
The pith
An orchestrator LLM adapts text clustering by dispatching specialized agents to refine taxonomies on the fly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
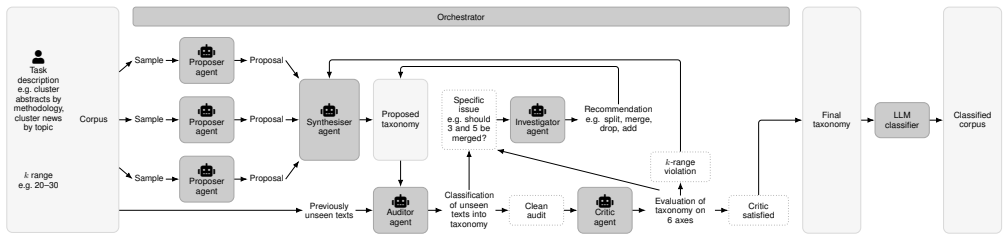
Recent text-clustering methods use large language models to propose a cluster taxonomy from a corpus and then assign each text to it. These pipelines are fundamentally programmatic: the sequence of LLM calls and the rules for stopping, merging, and splitting clusters are fixed in code in advance, so they generalise poorly across corpora of different structure and cannot easily incorporate user-supplied constraints such as a target cluster count or a clustering intent. The agentic alternative lets an orchestrator LLM inspect the state of the discovery process at each step and dispatch one of a small set of specialised agents, adapting the pipeline to the corpus rather than executing a fixed o
What carries the argument
The orchestrator LLM that inspects the current clustering state and dispatches one of five specialized agents (proposer, synthesizer, auditor, investigator, critic) to refine the taxonomy.
If this is right
- User constraints such as target cluster count or clustering intent can be incorporated without rewriting the pipeline code.
- The same system can process corpora that differ in structure without manual retuning of stopping rules or merge criteria.
- Performance on standard benchmarks reaches state-of-the-art levels, exceeding the strongest prior LLM baseline by up to 32 percent in adjusted rand index.
- Taxonomies become dynamic outputs of an adaptive process rather than static products of a fixed program.
Where Pith is reading between the lines
- The same orchestration pattern could be reused for other iterative discovery tasks that currently rely on rigid LLM call sequences.
- If the orchestrator generalizes, manual engineering of clustering hyperparameters across domains may become unnecessary.
- Controllability suggests an interactive mode in which users steer taxonomy construction in real time through additional constraints.
- The approach may extend to very large or streaming collections by letting agents focus on local refinements while the orchestrator maintains global consistency.
Load-bearing premise
The orchestrator can reliably decide which specialized agent to invoke and when to stop or change direction for arbitrary corpora and user constraints.
What would settle it
On a held-out corpus the orchestrator repeatedly selects the wrong agent or fails to produce a taxonomy that meets a supplied constraint such as an exact cluster count.
Figures
read the original abstract
Recent text-clustering methods use large language models to propose a cluster taxonomy from a corpus and then assign each text to it. These pipelines are fundamentally programmatic: the sequence of LLM calls and the rules for stopping, merging, and splitting clusters are fixed in code in advance, so they generalise poorly across corpora of different structure and cannot easily incorporate user-supplied constraints such as a target cluster count or a clustering intent. We propose an agentic alternative in which an orchestrator LLM inspects the state of the discovery process at each step and dispatches one of a small set of specialised agents - proposer, synthesizer, auditor, investigator, and critic - adapting the pipeline to the corpus rather than executing a fixed one. On seven public text-clustering benchmarks the method achieves state-of-the-art performance, beating the strongest prior LLM baseline by up to 32% in ARI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an agentic clustering framework in which an orchestrator LLM dynamically invokes one of five specialized agents (proposer, synthesizer, auditor, investigator, critic) to iteratively build and refine text taxonomies. This replaces fixed programmatic pipelines with an adaptive process intended to handle varying corpora and user constraints such as target cluster count or clustering intent. On seven standard public text-clustering benchmarks the method reports state-of-the-art ARI scores, outperforming the strongest prior LLM baseline by up to 32%.
Significance. If the empirical gains are reproducible and the agentic design demonstrably respects user constraints, the work would provide a concrete alternative to rigid LLM clustering pipelines and could influence controllable taxonomy construction in applied NLP. The manuscript supplies no parameter-free derivations or machine-checked proofs; its contribution rests entirely on the reported benchmark improvements.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the headline motivation is that prior pipelines 'cannot easily incorporate user-supplied constraints' while the orchestrator 'adapts the pipeline to the corpus'; however, all seven benchmarks are standard unconstrained clustering tasks with no injected constraints (target k, intent statements, etc.). Consequently the measured ARI gains demonstrate only unconstrained performance and supply no evidence that the orchestrator reliably detects, respects, or exploits explicit constraints when present.
- [§4] §4, results tables: the abstract asserts 'SOTA' and a '32% ARI gain' yet the provided text supplies neither the identity of the strongest prior LLM baseline, the exact ARI values per dataset, nor any statistical significance tests or variance estimates across runs. Without these, the magnitude and reliability of the claimed improvement cannot be assessed.
minor comments (2)
- [§3] Notation for the five agent roles is introduced only in the abstract; a concise table or diagram in §3 would clarify their distinct responsibilities and invocation conditions.
- [§3] The manuscript should include at least one illustrative trace (e.g., a short corpus with an injected constraint) showing the sequence of agent calls and final taxonomy to make the adaptation mechanism concrete.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point-by-point below, agreeing where the observations are accurate and outlining specific revisions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the headline motivation is that prior pipelines 'cannot easily incorporate user-supplied constraints' while the orchestrator 'adapts the pipeline to the corpus'; however, all seven benchmarks are standard unconstrained clustering tasks with no injected constraints (target k, intent statements, etc.). Consequently the measured ARI gains demonstrate only unconstrained performance and supply no evidence that the orchestrator reliably detects, respects, or exploits explicit constraints when present.
Authors: We agree that the seven benchmarks are standard unconstrained tasks and that the reported ARI gains therefore speak only to unconstrained performance. The manuscript's core motivation concerns the orchestrator's ability to adapt to corpus structure and user constraints, but the current experiments do not test explicit constraint injection. In the revision we will add a dedicated subsection to §4 containing new experiments that supply target cluster counts and intent statements, measuring both clustering quality and constraint adherence. revision: yes
-
Referee: [§4] §4, results tables: the abstract asserts 'SOTA' and a '32% ARI gain' yet the provided text supplies neither the identity of the strongest prior LLM baseline, the exact ARI values per dataset, nor any statistical significance tests or variance estimates across runs. Without these, the magnitude and reliability of the claimed improvement cannot be assessed.
Authors: We accept that greater detail is required. The revised §4 tables will name the strongest prior LLM baseline for each dataset, list the exact per-dataset ARI scores, and include statistical significance tests together with variance estimates (standard deviation across five runs with different seeds). revision: yes
Circularity Check
No circularity; purely empirical method with external benchmark evaluation
full rationale
The paper introduces an agentic multi-LLM pipeline for text clustering and evaluates it solely via ARI scores on seven public benchmarks. No equations, parameter fittings, derivations, or self-referential constructions appear in the provided text. The central performance claim rests on direct comparison to prior LLM baselines on fixed external datasets, with no reduction of outputs to inputs by definition or self-citation chains. This is self-contained empirical work; the controllability motivation is untested in the reported experiments but does not create circularity in any derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can reliably serve as proposer, synthesizer, auditor, investigator, and critic agents when guided by an orchestrator.
invented entities (1)
-
Orchestrator LLM plus proposer, synthesizer, auditor, investigator, and critic agents
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI , year =
Efficient Intent Detection with Dual Sentence Encoders , author =. Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI , year =
-
[9]
Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing , year =
An Evaluation Dataset for Intent Classification and Out-of-Scope Prediction , author =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing , year =
2019
-
[10]
2023 , pages =
FitzGerald, Jack and Hench, Christopher and Peris, Charith and Mackie, Scott and Rottmann, Kay and Sanchez, Ana and Nash, Aaron and Urbach, Liam and Kakarala, Vishesh and Singh, Richa and Ranganath, Swetha and Crist, Laurie and Britan, Misha and Leeuwis, Wouter and Tur, Gokhan and Natarajan, Prem , booktitle =. 2023 , pages =
2023
-
[11]
2020 , pages =
Demszky, Dorottya and Movshovitz-Attias, Dana and Ko, Jeongwoo and Cowen, Alan and Nemade, Gaurav and Ravi, Sujith , booktitle =. 2020 , pages =
2020
-
[12]
Lang, Ken , booktitle =. 1995 , pages =. doi:10.1016/B978-1-55860-377-6.50048-7 , url =
-
[13]
2023 , pages =
Zhang, Yuwei and Wang, Zihan and Shang, Jingbo , booktitle =. 2023 , pages =
2023
-
[14]
2022 , url =
Grootendorst, Maarten , journal =. 2022 , url =
2022
-
[15]
and Ng, Andrew Y
Blei, David M. and Ng, Andrew Y. and Jordan, Michael I. , journal =. Latent. 2003 , url =
2003
-
[16]
Advances in Neural Information Processing Systems 30 (NeurIPS 2017) , year =
Attention is All You Need , author =. Advances in Neural Information Processing Systems 30 (NeurIPS 2017) , year =
2017
-
[17]
2019 , pages =
Reimers, Nils and Gurevych, Iryna , booktitle =. 2019 , pages =
2019
-
[18]
Transactions of the Association for Computational Linguistics , volume =
Large Language Models Enable Few-Shot Clustering , author =. Transactions of the Association for Computational Linguistics , volume =. 2024 , url =
2024
-
[19]
2024 , url =
Pham, Chau Minh and Hoyle, Alexander and Sun, Simeng and Resnik, Philip and Iyyer, Mohit , booktitle =. 2024 , url =
2024
-
[20]
Text Clustering as Classification with
Huang, Chen and He, Guoxiu , year =. Text Clustering as Classification with. 2410.00927 , archivePrefix =
-
[21]
Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics , year =
Incorporating Lexical Priors into Topic Models , author =. Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics , year =
-
[22]
Angelov, Dimo , journal =. Top2. 2020 , url =
2020
-
[23]
2024 , url =
Akash, Pritom Saha and Das, Trisha and Chang, Kevin Chen-Chuan , booktitle =. 2024 , url =
2024
-
[24]
2025 , url =
Lee, Chankyu and Roy, Rajarshi and Xu, Mengyao and Raiman, Jonathan and Shoeybi, Mohammad and Catanzaro, Bryan and Ping, Wei , booktitle =. 2025 , url =
2025
-
[25]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics , year =
Supporting Clustering with Contrastive Learning , author =. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics , year =
2021
-
[26]
Proceedings of the 5th Workshop on NLP for Conversational AI (NLP4ConvAI 2023) , year =
De Raedt, Maarten and Godin, Fr. Proceedings of the 5th Workshop on NLP for Conversational AI (NLP4ConvAI 2023) , year =
2023
-
[27]
2024 , pages =
Feng, Zijin and Lin, Luyang and Wang, Lingzhi and Cheng, Hong and Wong, Kam-Fai , booktitle =. 2024 , pages =
2024
-
[28]
Proceedings of the 2023 IEEE International Conference on Big Data (BigData) , year =
Prompting Large Language Models for Topic Modeling , author =. Proceedings of the 2023 IEEE International Conference on Big Data (BigData) , year =
2023
-
[29]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
Goal-Driven Explainable Clustering via Language Descriptions , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year =
2023
-
[30]
Liu, Jianghan and Shang, Ziyu and Ke, Wenjun and Wang, Peng and Luo, Zhizhao and Liu, Jiajun and Li, Guozheng and Li, Yining , booktitle =
-
[31]
Context-Aware Hierarchical Taxonomy Generation for Scientific Papers via
Zhu, Kun and Liao, Lizi and Gu, Yuxuan and Huang, Lei and Feng, Xiaocheng and Qin, Bing , booktitle =. Context-Aware Hierarchical Taxonomy Generation for Scientific Papers via. 2025 , url =
2025
-
[32]
Hong, Mengze and Ng, Wailing and Zhang, Chen Jason and Song, Yuanfeng and Jiang, Di , booktitle =. Dial-. 2025 , url =
2025
-
[33]
Advances in Neural Information Processing Systems 36 (NeurIPS 2023) , year =
Goal Driven Discovery of Distributional Differences via Language Descriptions , author =. Advances in Neural Information Processing Systems 36 (NeurIPS 2023) , year =
2023
-
[34]
Iterative Topic Taxonomy Induction with
Brady and Islam , year =. Iterative Topic Taxonomy Induction with
-
[35]
Agent-Centric Personalized Multiple Clustering with Multi-Modal
Chen, Ziye and Duan, Yiqun and Zhu, Riheng and Sun, Zhenbang and Gong, Mingming , year =. Agent-Centric Personalized Multiple Clustering with Multi-Modal. 2503.22241 , archivePrefix =
-
[36]
and Yang, Longqi and Andersen, Reid and Buscher, Georg and Joshi, Dhruv and Rangan, Nagu , booktitle =
Wan, Mengting and Safavi, Tara and Jauhar, Sujay Kumar and Kim, Yujin and Counts, Scott and Neville, Jennifer and Suri, Siddharth and Shah, Chirag and White, Ryen W. and Yang, Longqi and Andersen, Reid and Buscher, Georg and Joshi, Dhruv and Rangan, Nagu , booktitle =. 2024 , doi =
2024
-
[37]
International Journal of Cognitive Computing in Engineering , volume =
Text Clustering with Large Language Model Embeddings , author =. International Journal of Cognitive Computing in Engineering , volume =. 2025 , url =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.