Beyond Gradient-Based Attacks: Adversarial Robustness and Explainability Stability in Cybersecurity Classifiers
Pith reviewed 2026-07-03 11:35 UTC · model grok-4.3
The pith
Gradient-based attacks leave XGBoost predictions intact yet shift their SHAP explanations substantially on cybersecurity data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
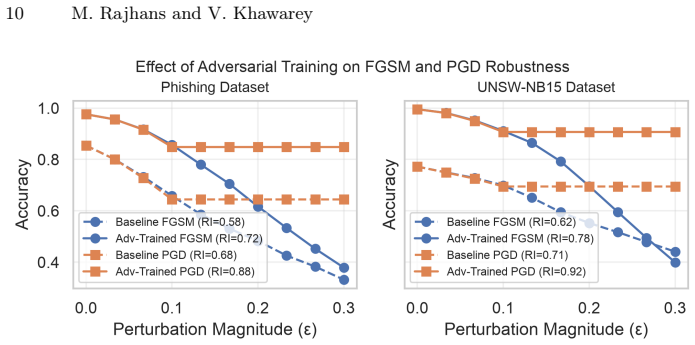
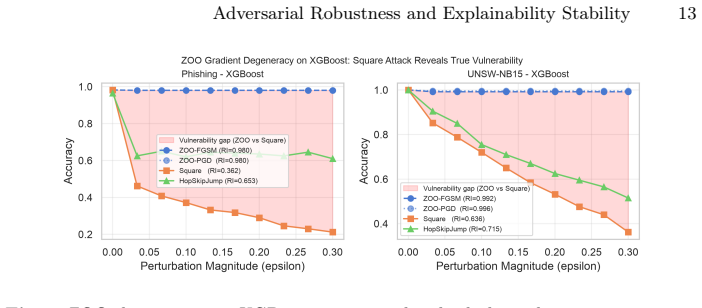
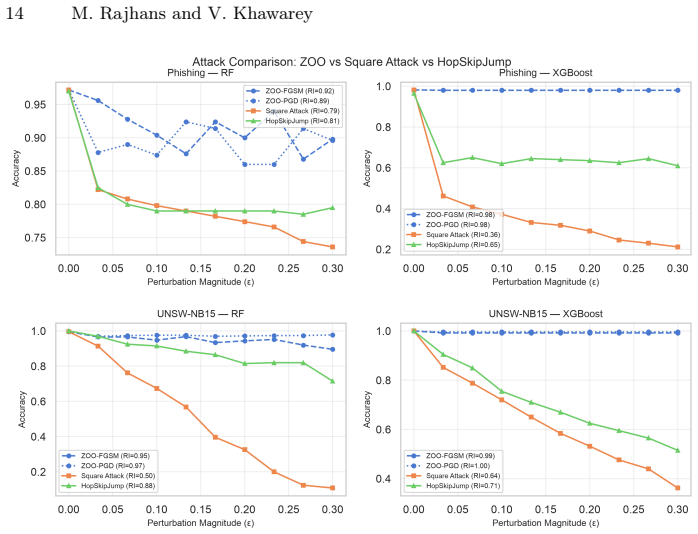
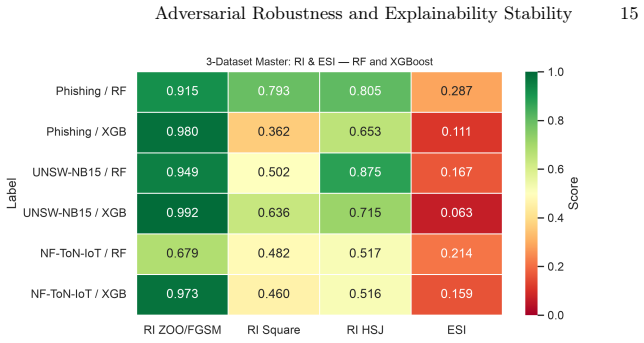
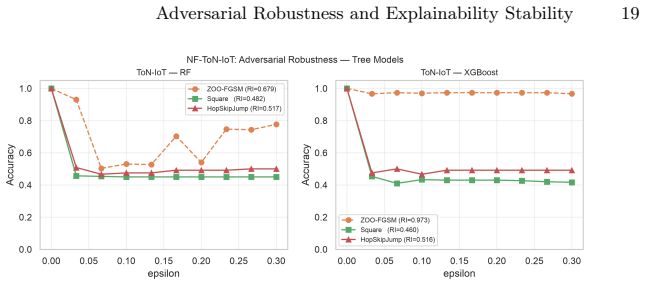
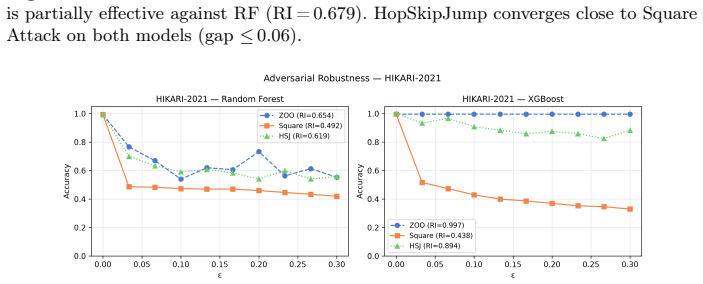
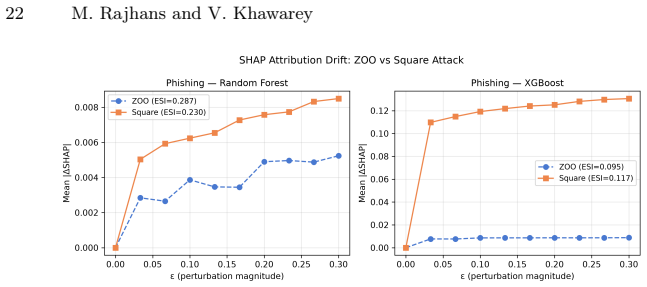
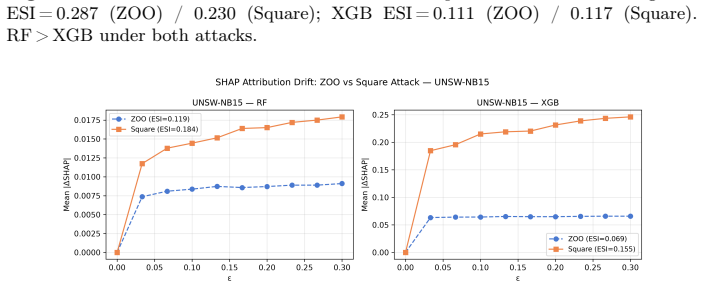
Gradient-based black-box attacks such as ZOO yield near-perfect robustness indices of approximately 0.98 against XGBoost owing to the model's piecewise-constant prediction surfaces, yet score-based attacks like Square Attack produce indices around 0.36; the same ZOO perturbations still induce substantial TreeSHAP attribution drift, resulting in ESI values of 0.06-0.16 for XGBoost versus 0.14-0.29 for Random Forest, establishing that robust predictions and stable explanations constitute distinct axes.
What carries the argument
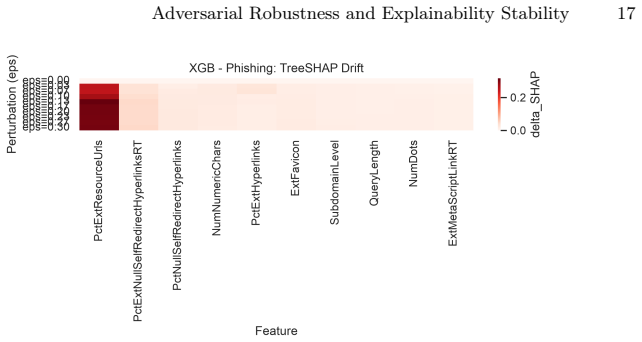
The Explainability Stability Index (ESI), a scalar computed from the drift in TreeSHAP feature attributions between an original input and its adversarially perturbed version, placed on the same [0,1] scale as the Robustness Index (RI).
If this is right
- ZOO attacks are degenerate for measuring true robustness on XGBoost because of its piecewise-constant surfaces.
- Score-based Square Attack provides a more reliable indicator of vulnerability with an RI around 0.36.
- Substantial attribution drift occurs even under near-perfect prediction robustness, requiring separate ESI reporting.
- A two-axis view of gradient dependence and query efficiency accounts for observed attack rankings across models.
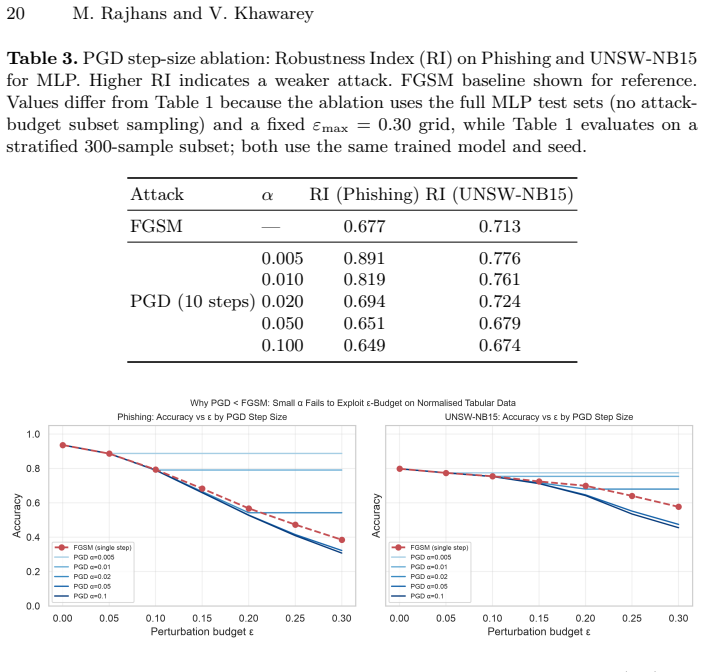
- Step-size ablation on z-score normalized tabular data explains anomalous PGD behavior.
Where Pith is reading between the lines
- Evaluation suites for cybersecurity tree models should report both RI and ESI rather than robustness alone.
- Attacks designed explicitly to maximize attribution drift without changing predictions could evade analyst review more effectively.
- The observed separation of axes may generalize to other explanation techniques beyond TreeSHAP on tabular security data.
Load-bearing premise
TreeSHAP attributions computed on the original and perturbed inputs provide a faithful and comparable measure of explanation stability that security analysts actually rely upon when triaging alerts.
What would settle it
A controlled study in which security analysts triage the same alerts with original versus drifted TreeSHAP attributions and show no measurable change in their decisions or alert-handling behavior would falsify the practical relevance of the ESI metric.
Figures


read the original abstract
Adversarial attacks on cybersecurity classifiers pose a dual threat: degrading predictions and destabilising the SHAP-based explanations that security analysts rely on to understand and triage alerts. We extend our prior MLP conference study to Random Forest and XGBoost across four tabular security datasets (phishing URLs, UNSW-NB15, NF-ToN-IoT, HIKARI-2021), evaluating five attacks including three black-box methods applicable to non-differentiable tree models. We introduce the Explainability Stability Index (ESI), a scalar metric computed from TreeSHAP attribution drift under adversarial perturbation, reported on the same [0,1] scale as the Robustness Index (RI). A key finding is that gradient-based black-box attacks (ZOO) produce degenerate results against XGBoost (apparent RI ~0.98) due to piecewise-constant prediction surfaces, while score-based Square Attack reveals genuine vulnerability (RI ~0.36). These degenerate perturbations still drive substantial attribution drift: XGBoost ESI ~0.06-0.16 despite near-perfect ZOO robustness, versus 0.14-0.29 for RF, showing that prediction robustness and explanation stability are distinct axes requiring joint measurement. A two-axis framework (gradient dependence, query efficiency) explains the observed attack ranking and yields practical guidance for tree ensemble evaluation. A step-size ablation explains a counterintuitive PGD anomaly on z-score normalised tabular data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates five adversarial attacks (including ZOO, Square, and PGD) on Random Forest and XGBoost models trained on four tabular cybersecurity datasets (phishing URLs, UNSW-NB15, NF-ToN-IoT, HIKARI-2021). It reports Robustness Index (RI) and introduces the Explainability Stability Index (ESI) derived from TreeSHAP attribution drift under perturbation. The central claim is that gradient-based black-box attacks like ZOO produce degenerate high RI (~0.98) on XGBoost due to piecewise-constant surfaces while score-based Square Attack reveals lower RI (~0.36), and that ESI remains low (0.06-0.16 for XGBoost) even under high-RI perturbations, establishing prediction robustness and explanation stability as distinct axes. A two-axis framework (gradient dependence, query efficiency) and a step-size ablation on z-score normalized data are also presented.
Significance. If the ESI metric is shown to be a faithful and analyst-relevant measure of stability, the distinction between RI and ESI would provide a practical two-axis evaluation framework for tree ensembles in security settings where SHAP explanations inform alert triage. The empirical demonstration that piecewise-constant surfaces cause ZOO to fail while still inducing attribution drift, together with the attack-ranking framework, could guide selection of evaluation methods beyond gradient-based attacks.
major comments (3)
- [§3] §3 (ESI definition and computation): The ESI is presented as a [0,1] scalar from TreeSHAP attribution drift, but the manuscript provides no derivation, normalization procedure, or ablation showing how it accounts for the piecewise-constant nature of tree predictions (where a perturbation may remain in the same leaf yet change marginal contributions). This is load-bearing for the claim that ESI values of 0.06-0.16 indicate 'substantial' drift distinct from RI.
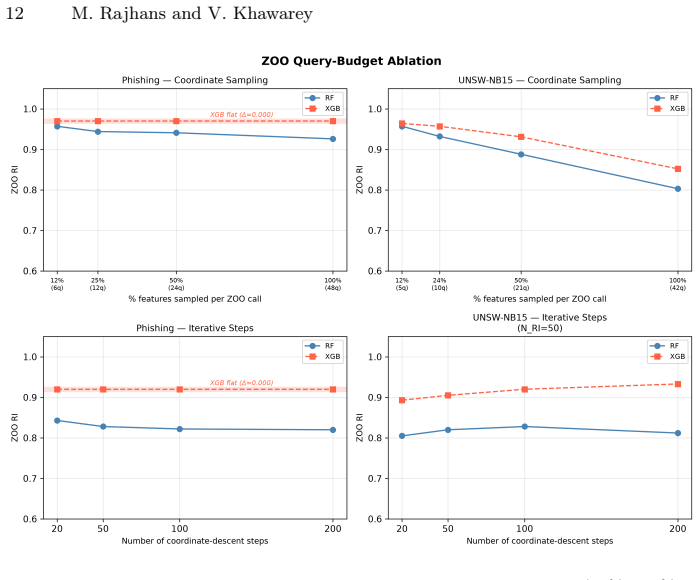
- [§4.2] §4.2 and Table 2 (ZOO vs. Square results on XGBoost): The reported RI~0.98 for ZOO versus RI~0.36 for Square is used to argue degenerate vs. genuine vulnerability, yet no statistical tests, multiple-run variance, or controls for query budget are reported to confirm that the difference is not an artifact of the specific attack implementations or dataset normalizations.
- [§5] §5 (two-axis framework): The claim that the gradient-dependence / query-efficiency axes explain the observed attack ranking and yield 'practical guidance' rests on post-hoc interpretation of the five attacks; no cross-validation or hold-out dataset is used to test whether the framework generalizes beyond the four datasets studied.
minor comments (2)
- [Abstract / §1] The abstract and §1 refer to 'our prior MLP conference study' without a citation; add the reference for context.
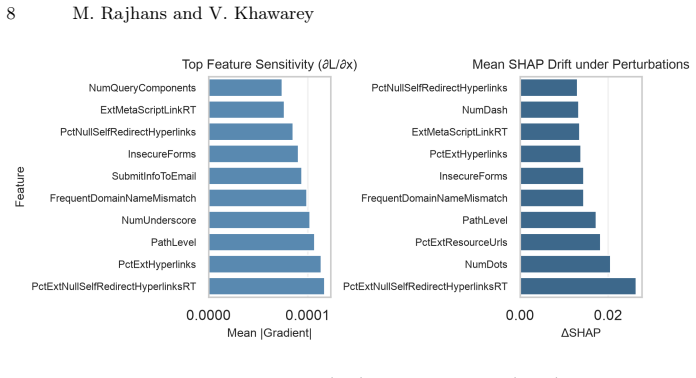
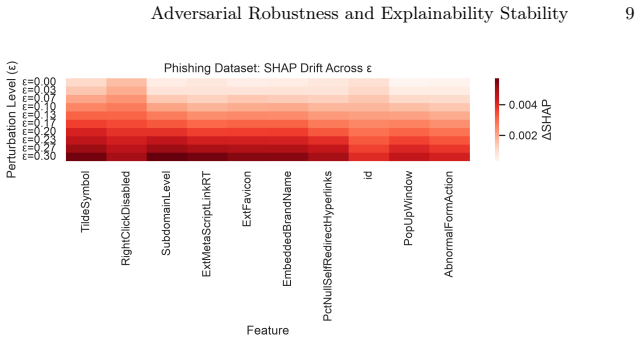
- [Figures] Figure captions for the attribution-drift plots should explicitly state the number of samples and perturbation budgets used to compute the reported ESI ranges.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our metrics and framework. We address each major point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [§3] §3 (ESI definition and computation): The ESI is presented as a [0,1] scalar from TreeSHAP attribution drift, but the manuscript provides no derivation, normalization procedure, or ablation showing how it accounts for the piecewise-constant nature of tree predictions (where a perturbation may remain in the same leaf yet change marginal contributions). This is load-bearing for the claim that ESI values of 0.06-0.16 indicate 'substantial' drift distinct from RI.
Authors: We agree that the ESI section would benefit from greater formality. In the revision we will add an explicit derivation of the ESI formula (including the exact normalization to the [0,1] interval), a step-by-step computation procedure, and a targeted ablation that isolates leaf-stability versus marginal-contribution drift on the piecewise-constant surfaces. These additions will directly support the interpretation of the reported ESI ranges. revision: yes
-
Referee: [§4.2] §4.2 and Table 2 (ZOO vs. Square results on XGBoost): The reported RI~0.98 for ZOO versus RI~0.36 for Square is used to argue degenerate vs. genuine vulnerability, yet no statistical tests, multiple-run variance, or controls for query budget are reported to confirm that the difference is not an artifact of the specific attack implementations or dataset normalizations.
Authors: The large RI gap is a direct consequence of ZOO's reliance on gradient estimates that are undefined on tree surfaces; Square Attack, being score-based, does not suffer this mismatch. Nevertheless, to strengthen the empirical claim we will (i) report results over multiple random seeds with standard deviations and (ii) explicitly document that query budgets were matched across attacks. We view these as straightforward additions rather than changes to the core finding. revision: yes
-
Referee: [§5] §5 (two-axis framework): The claim that the gradient-dependence / query-efficiency axes explain the observed attack ranking and yield 'practical guidance' rests on post-hoc interpretation of the five attacks; no cross-validation or hold-out dataset is used to test whether the framework generalizes beyond the four datasets studied.
Authors: The two-axis framework is offered as an interpretive taxonomy derived from the attack properties and the consistent empirical patterns we observed; it is not advanced as a learned predictive model. We will revise the text to make this interpretive status explicit and to acknowledge the absence of hold-out validation as a limitation. The practical guidance remains useful for practitioners choosing evaluation attacks on tree ensembles, but we accept that stronger generalization evidence would require additional experiments beyond the current scope. revision: partial
Circularity Check
Empirical study reporting measured indices on public datasets; no equations reduce ESI or RI to fitted parameters
full rationale
The paper measures Robustness Index (RI) and introduces Explainability Stability Index (ESI) from TreeSHAP drift under attacks on four public tabular datasets for RF and XGBoost. The distinction between prediction robustness and explanation stability is shown directly by the reported numerical differences (e.g., ZOO RI ~0.98 vs ESI ~0.06-0.16 on XGBoost). No derivation chain, equation, or self-citation reduces these scalars to quantities defined by the paper's own fitted parameters or prior results. The noted extension of a prior MLP study supplies context but does not carry the load of the new empirical findings or the two-axis framework.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption TreeSHAP attributions computed on perturbed inputs are directly comparable to those on clean inputs for measuring stability
invented entities (1)
-
Explainability Stability Index (ESI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Advances in Neural Information Processing Systems (NeurIPS) (2022)
Agarwal, C., Krishna, S., Saxena, E., Pawelczyk, M., Johnson, N., Puri, I., Zitnik, M., Lakkaraju, H.: OpenXAI: Towards a transparent evaluation of model explana- tions. In: Advances in Neural Information Processing Systems (NeurIPS) (2022)
2022
-
[2]
In: ICML Workshop on Human Interpretability in Machine Learning (WHI) (2018)
Alvarez-Melis, D., Jaakkola, T.S.: On the robustness of interpretability methods. In: ICML Workshop on Human Interpretability in Machine Learning (WHI) (2018)
2018
-
[3]
In: European Conference on Computer Vision (ECCV)
Andriushchenko, M., Croce, F., Flammarion, N., Hein, M.: Square attack: A query- efficient black-box adversarial attack via random search. In: European Conference on Computer Vision (ECCV). pp. 484–501. Springer (2020).https://doi.org/ 10.1007/978-3-030-58592-1_29
-
[4]
Digi- tal Threats: Research and Practice3(3), 1–19 (2022).https://doi.org/10.1145/ 3469659
Apruzzese, G., Andreolini, M., Ferretti, L., Marchetti, M., Colajanni, M.: Model- ing realistic adversarial attacks against network intrusion detection systems. Digi- tal Threats: Research and Practice3(3), 1–19 (2022).https://doi.org/10.1145/ 3469659
2022
-
[5]
Adversarial Robustness and Explainability Stability 27 In: European Conference on Machine Learning and Knowledge Discovery in Databases (ECML-PKDD)
Biggio, B., Corona, I., Maiorca, D., Nelson, B., Šrndić, N., Laskov, P., Gi- acinto, G., Roli, F.: Evasion attacks against machine learning at test time. Adversarial Robustness and Explainability Stability 27 In: European Conference on Machine Learning and Knowledge Discovery in Databases (ECML-PKDD). pp. 387–402. Springer (2013).https://doi.org/10. 1007/...
2013
-
[6]
In: IEEE Symposium on Security and Privacy (S&P)
Carlini, N., Wagner, D.: Towards evaluating the robustness of neural networks. In: IEEE Symposium on Security and Privacy (S&P). pp. 39–57 (2017).https: //doi.org/10.1109/SP.2017.49
-
[7]
In: IEEE Symposium on Security and Privacy (S&P)
Chen, J., Jordan, M.I., Wainwright, M.J.: HopSkipJumpAttack: A query-efficient decision-based attack. In: IEEE Symposium on Security and Privacy (S&P). pp. 1277–1294 (2020).https://doi.org/10.1109/SP40000.2020.00045
-
[8]
In: ACM Workshop on Artificial Intelligence and Security (AISec)
Chen, P.Y., Zhang, H., Sharma, Y., Yi, J., Hsieh, C.J.: ZOO: Zeroth order opti- mization based black-box attacks to deep neural networks without training sub- stitute models. In: ACM Workshop on Artificial Intelligence and Security (AISec). pp. 15–26 (2017).https://doi.org/10.1145/3128572.3140448
-
[9]
In: International Conference on Machine Learning (ICML)
Cohen, J., Rosenfeld, E., Kolter, Z.: Certified adversarial robustness via random- ized smoothing. In: International Conference on Machine Learning (ICML). pp. 1310–1320 (2019)
2019
-
[10]
In: International Conference on Machine Learn- ing (ICML)
Croce, F., Hein, M.: Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. In: International Conference on Machine Learn- ing (ICML). pp. 2206–2216 (2020)
2020
-
[11]
Machine Learning107(3), 481–508 (2018).https://doi.org/10
Fawzi, A., Fawzi, O., Frossard, P.: Analysis of classifiers’ robustness to adversarial perturbations. Machine Learning107(3), 481–508 (2018).https://doi.org/10. 1007/s10994-017-5663-3
2018
-
[12]
Electronics11(5), 612 (2022).https://doi.org/10.3390/electronics11050612
Ferrag, M.A., Demertzis, K., Maglaras, L., Janicke, H., Choo, K.K.R.: HIKARI- 2021, a new labelled cybersecurity network traffic dataset. Electronics11(5), 612 (2022).https://doi.org/10.3390/electronics11050612
-
[13]
Explaining and Harnessing Adversarial Examples
Goodfellow, I.J., Shlens, J., Szegedy, C.: Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[14]
In: Euro- pean Symposium on Research in Computer Security (ESORICS)
Grosse, K., Papernot, N., Manoharan, P., Backes, M., McDaniel, P.: Adversarial perturbations against deep neural networks for malware classification. In: Euro- pean Symposium on Research in Computer Security (ESORICS). pp. 62–79 (2017). https://doi.org/10.1007/978-3-319-66399-9_4
-
[15]
Nature Machine Intelligence2(1), 56–67 (2020).https://doi.org/10.1038/s42256-019-0138-9
Lundberg, S.M., Erion, G., Chen, H., DeGrave, A., Peck, J.M., Dudley, J., Nair, R., Katz, F., Himmelfarb, J., Bansal, N., et al.: From local explanations to global understanding with explainable AI for trees. Nature Machine Intelligence2(1), 56–67 (2020).https://doi.org/10.1038/s42256-019-0138-9
-
[16]
In: Advances in Neural Information Processing Systems (NeurIPS)
Lundberg, S.M., Lee, S.I.: A unified approach to interpreting model predictions. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 30 (2017)
2017
-
[17]
In: International Conference on Learning Representations (ICLR) (2018)
Madry, A., Makelov, A., Schmidt, L., Tsipras, D., Vladu, A.: Towards deep learning models resistant to adversarial attacks. In: International Conference on Learning Representations (ICLR) (2018)
2018
-
[18]
In: Military Communications and Information Systems Conference (MilCIS)
Moustafa, N., Slay, J.: UNSW-NB15: A comprehensive data set for network in- trusion detection systems. In: Military Communications and Information Systems Conference (MilCIS). pp. 1–6 (2015).https://doi.org/10.1109/MilCIS.2015. 7348942
-
[19]
In: IEEE European Symposium on Security and Privacy (EuroS&P)
Papernot, N., McDaniel, P., Wu, X., Jha, S., Swami, A.: The limitations of deep learning in adversarial settings. In: IEEE European Symposium on Security and Privacy (EuroS&P). pp. 372–387 (2016).https://doi.org/10.1109/EuroSP. 2016.36
-
[20]
In: IEEE Symposium on Security 28 M
Pierazzi, F., Pendlebury, F., Cortellazzi, J., Cavallaro, L.: Intriguing properties of adversarial ML attacks in the problem space. In: IEEE Symposium on Security 28 M. Rajhans and V. Khawarey and Privacy (S&P). pp. 1309–1326 (2020).https://doi.org/10.1109/SP40000. 2020.00073
-
[21]
Rajhans, M., Khawarey, V.: Adversarial robustness and explainability drift — experiment code (2026).https://doi.org/10.5281/zenodo.20968236,https:// doi.org/10.5281/zenodo.20968236
-
[22]
Rajhans, M., Khawarey, V.: Empirical analysis of adversarial robustness and ex- plainability drift in cybersecurity classifiers. In: Proceedings of the 18th Interna- tional Conference on Agents and Artificial Intelligence - Volume 4: ICAART. pp. 3101–3108. SciTePress (2026).https://doi.org/10.5220/0014360100004052
-
[23]
Ribeiro, M.T., Singh, S., Guestrin, C.: “Why should I trust you?”: Explaining the predictions of any classifier. In: ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). pp. 1135–1144 (2016).https:// doi.org/10.1145/2939672.2939778
-
[24]
In: International Con- ference on Big Data Technologies and Applications (BDTA)
Sarhan, M., Layeghy, S., Moustafa, N., Portmann, M.: NetFlow datasets for ma- chine learning-based network intrusion detection systems. In: International Con- ference on Big Data Technologies and Applications (BDTA). pp. 117–135. Springer (2021).https://doi.org/10.1007/978-3-030-72802-1_9
-
[25]
In: AAAI/ACM Conference on AI, Ethics, and Society (AIES)
Slack, D., Hilgard, S., Jia, E., Singh, S., Lakkaraju, H.: Fooling LIME and SHAP: Adversarial attacks on post hoc explanation methods. In: AAAI/ACM Conference on AI, Ethics, and Society (AIES). pp. 180–186 (2020).https://doi.org/10. 1145/3375627.3375830
-
[26]
In: IEEE European Symposium on Secu- rity and Privacy (EuroS&P)
Warnecke, A., Arp, D., Wressnegger, C., Rieck, K.: Evaluating explanation meth- ods for deep learning in security. In: IEEE European Symposium on Secu- rity and Privacy (EuroS&P). pp. 158–174 (2020).https://doi.org/10.1109/ EuroSP48549.2020.00018
-
[27]
Kaggle (2018),https://www.kaggle.com/ datasets/shashwatwork/phishing-dataset-for-machine-learning
Work, S.: Phishing websites dataset. Kaggle (2018),https://www.kaggle.com/ datasets/shashwatwork/phishing-dataset-for-machine-learning
2018
-
[28]
IEEE Access8, 134503–134515 (2020)
Yang, W., Wu, L., Zhong, S., Liu, W., Liu, H.: Defending deep neural networks against adversarial attacks in cybersecurity. IEEE Access8, 134503–134515 (2020). https://doi.org/10.1109/ACCESS.2020.3011769
-
[29]
In: International Conference on Machine Learning (ICML)
Zhang, H., Yu, Y., Jiao, J., Xing, E.P., Ghaoui, L.E., Jordan, M.I.: Theoretically principled trade-off between robustness and accuracy. In: International Conference on Machine Learning (ICML). pp. 7472–7482 (2019)
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.