ViMax: Agentic Video Generation
Pith reviewed 2026-06-28 10:35 UTC · model grok-4.3
The pith
ViMax coordinates multiple specialized agents to plan narratives and track visual states for generating extended coherent videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
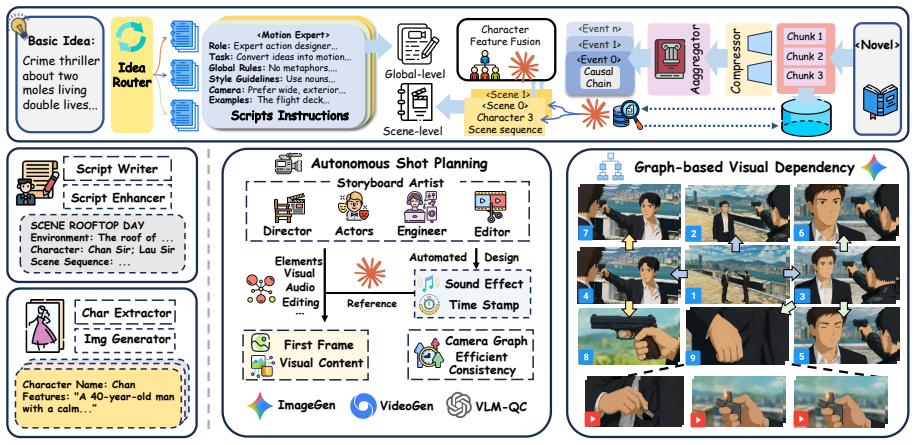
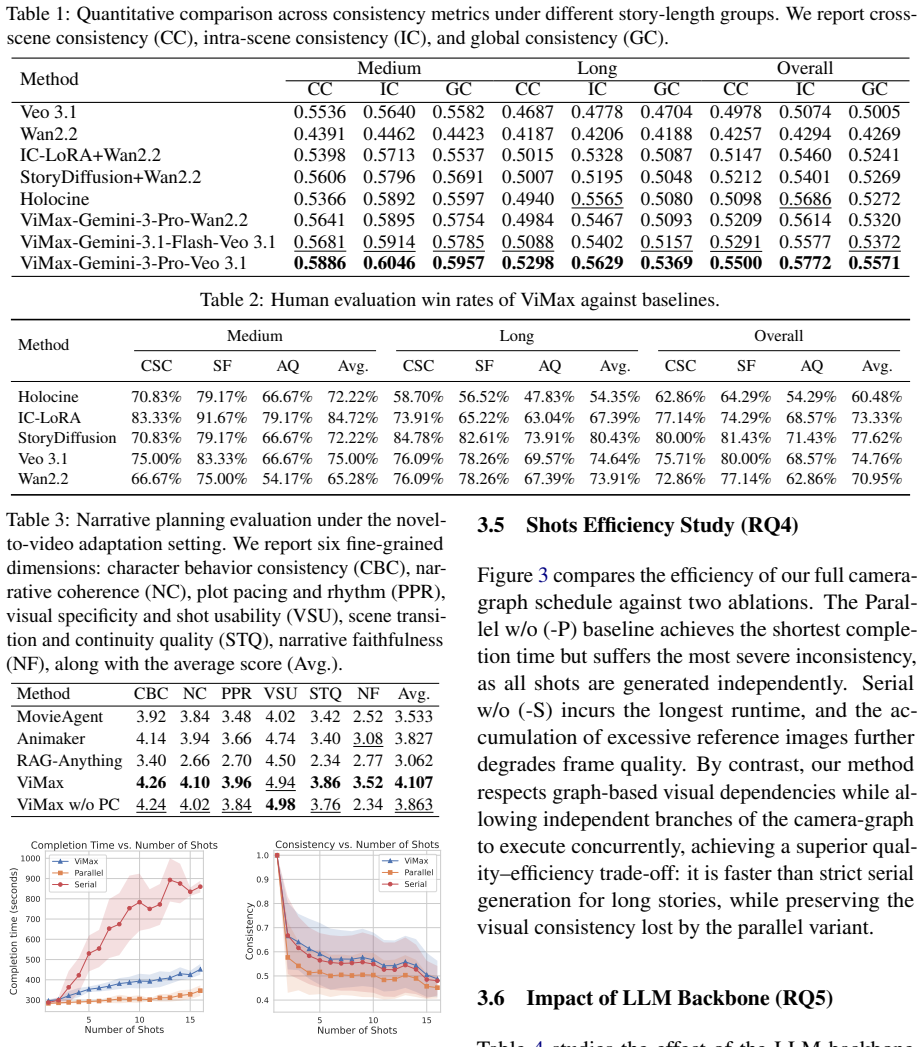
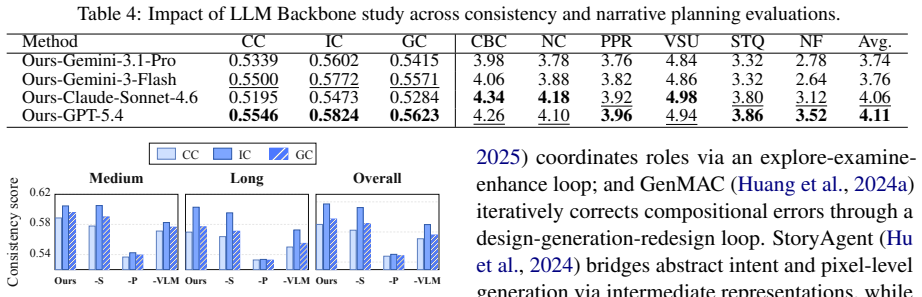
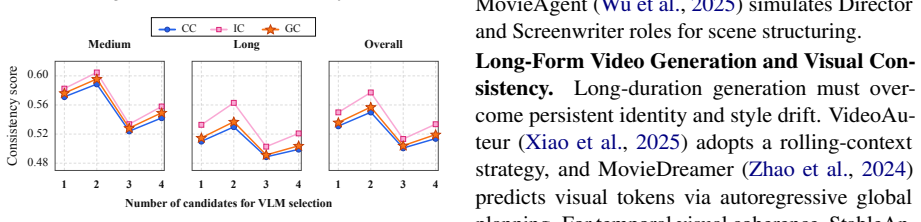
ViMax is an agentic video generation framework that addresses video creation through coordinated multi-agent collaboration where specialized components negotiate narrative decisions, visual continuity, and production quality. The framework employs a hierarchical narrative engine with retrieval-augmented generation for global story coherence and a dependency-aware visual consistency mechanism that tracks character and environmental states across temporal boundaries, while VLM-guided agents continuously monitor and refine both narrative coherence and visual fidelity.
What carries the argument
Hierarchical narrative engine paired with dependency-aware visual consistency mechanism that tracks states across scenes.
If this is right
- The system produces extended narrative content across multiple scenes while preserving storytelling integrity.
- Visual coherence holds across temporal boundaries through state tracking of characters and environments.
- VLM-guided agents provide ongoing refinement of both story and visual elements during generation.
- Coordinated collaboration replaces isolated short-clip generation for timeline-spanning videos.
Where Pith is reading between the lines
- The same agent coordination pattern could apply to other sequential media like animated series or interactive stories.
- Production pipelines might shift from human oversight of consistency to automated agent negotiation.
- Failure modes in agent negotiation could point to needs for explicit conflict-resolution rules in future versions.
Load-bearing premise
Specialized agents can negotiate narrative choices, visual continuity, and quality through the described engine and tracking tools without unresolved conflicts or coordination failures.
What would settle it
Run the system on a multi-scene script with recurring characters and check whether character appearance, environment details, or plot events remain consistent in the output video.
Figures









read the original abstract
Long-form video generation requires systematic narrative planning and visual consistency that current short-clip methods cannot provide. Existing methods generate isolated sequences without narrative structure and lack mechanisms for maintaining character and environmental consistency across scenes. We present ViMax, an agentic video generation framework that addresses video creation through coordinated multi-agent collaboration where specialized components negotiate narrative decisions, visual continuity, and production quality. Our framework employs a hierarchical narrative engine with retrieval-augmented generation for global story coherence and a dependency-aware visual consistency mechanism that tracks character and environmental states across temporal boundaries, while VLM-guided agents continuously monitor and refine both narrative coherence and visual fidelity. The framework enables coordinated agent collaboration to generate extended narrative content. This maintains both storytelling integrity and visual coherence across multi-scene timelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ViMax, an agentic video generation framework for long-form video that uses coordinated multi-agent collaboration. It employs a hierarchical narrative engine with retrieval-augmented generation for global story coherence, a dependency-aware visual consistency mechanism to track character and environmental states across temporal boundaries, and VLM-guided agents that monitor and refine narrative coherence and visual fidelity. The central claim is that this setup enables generation of extended narrative content while maintaining storytelling integrity and visual coherence across multi-scene timelines.
Significance. If the described mechanisms were fully specified with algorithms and empirically validated, the work could address a recognized gap in current short-clip video generation methods by providing systematic narrative planning and cross-scene consistency. As presented, the manuscript supplies only high-level assertions without any supporting technical content, so its significance cannot be evaluated.
major comments (3)
- [Abstract] The abstract asserts that specialized agent components 'negotiate narrative decisions, visual continuity, and production quality' and that VLM-guided agents 'continuously monitor and refine' both aspects, but supplies no algorithms, conflict-resolution protocols, state-transition rules, or pseudocode for these processes.
- [Abstract] The central claim that the framework 'enables coordinated agent collaboration' to maintain coherence across multi-scene timelines rests on an unverified functional assumption; the manuscript contains no experimental results, error analysis, qualitative examples, or quantitative metrics demonstrating that negotiation succeeds rather than fails or diverges.
- [Abstract] No details are given for the hierarchical narrative engine or the dependency-aware visual consistency mechanism beyond naming them, preventing any assessment of whether the claimed global story coherence and state tracking are achieved.
Simulated Author's Rebuttal
We thank the referee for their review. We acknowledge that the manuscript, as presented, consists of a high-level framework description without algorithms, protocols, or empirical results. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts that specialized agent components 'negotiate narrative decisions, visual continuity, and production quality' and that VLM-guided agents 'continuously monitor and refine' both aspects, but supplies no algorithms, conflict-resolution protocols, state-transition rules, or pseudocode for these processes.
Authors: We agree that the manuscript supplies no algorithms, protocols, or pseudocode. The submission is limited to a conceptual overview of the agent roles and mechanisms. A revision can incorporate pseudocode for negotiation, state transitions, and conflict resolution. revision: yes
-
Referee: [Abstract] The central claim that the framework 'enables coordinated agent collaboration' to maintain coherence across multi-scene timelines rests on an unverified functional assumption; the manuscript contains no experimental results, error analysis, qualitative examples, or quantitative metrics demonstrating that negotiation succeeds rather than fails or diverges.
Authors: The referee is correct: the manuscript contains no experimental results, error analysis, or metrics. This version presents the framework conceptually without implementation or validation. We do not claim empirical support and recognize the absence of such evidence as a limitation. revision: no
-
Referee: [Abstract] No details are given for the hierarchical narrative engine or the dependency-aware visual consistency mechanism beyond naming them, preventing any assessment of whether the claimed global story coherence and state tracking are achieved.
Authors: We agree that only high-level names are provided for the hierarchical narrative engine and dependency-aware visual consistency mechanism, with no implementation details. A revised manuscript can expand on the retrieval-augmented generation process and state-tracking rules. revision: yes
Circularity Check
No circularity: descriptive framework with no equations, predictions, or self-referential derivations
full rationale
The paper presents ViMax as an architectural description of multi-agent components for video generation. No mathematical derivations, fitted parameters, predictions, or uniqueness theorems appear in the provided abstract or description. The central claims are functional assertions about agent negotiation and consistency mechanisms, but these are not reduced to inputs by construction, self-citation chains, or renaming of known results. The derivation chain is empty of the enumerated circular patterns, making the work self-contained as a system proposal without quantitative or definitional circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kaiyi Huang, Yukun Huang, Xuefei Ning, Zinan Lin, Yu Wang, and Xihui Liu
Storyagent: Customized storytelling video generation via multi-agent collaboration.ArXiv, abs/2411.04925. Kaiyi Huang, Yukun Huang, Xuefei Ning, Zinan Lin, Yu Wang, and Xihui Liu. 2024a. Genmac: Com- positional text-to-video generation with multi-agent collaboration.ArXiv, abs/2412.04440. Kaiyi Huang, Yukun Huang, Xintao Wang, Zinan Lin, Xuefei Ning, Peng...
arXiv 2025
-
[2]
Xiangyu Meng, Zixian Zhang, Zhenghao Zhang, Jun- chao Liao, Long Qin, and Weizhi Wang
Freelong: Training-free long video genera- tion with spectralblend temporal attention.ArXiv, abs/2407.19918. Xiangyu Meng, Zixian Zhang, Zhenghao Zhang, Jun- chao Liao, Long Qin, and Weizhi Wang. 2025a. Identity-grpo: Optimizing multi-human identity- preserving video generation via reinforcement learn- ing.ArXiv, abs/2510.14256. Yihao Meng, Ouyang Hao, Yu...
arXiv 2024
-
[3]
Weijia Wu, Zeyu Zhu, and Mike Zheng Shou
Internvid: A large-scale video-text dataset for multimodal understanding and generation.ArXiv, abs/2307.06942. Weijia Wu, Zeyu Zhu, and Mike Zheng Shou. 2025. Au- tomated movie generation via multi-agent cot plan- ning.ArXiv, abs/2503.07314. Junfei Xiao, Feng Cheng, Lu Qi, Liangke Gui, Jie Cen, Zhibei Ma, A. L. Yuille, and Lu Jiang. 2025. Videoauteur: Tow...
Pith/arXiv arXiv 2025
-
[4]
Videogen-of-thought: Step-by-step generating multi-shot video with minimal manual intervention. ArXiv, abs/2503.15138. Jinsong Zhou, Yihua Du, Xinli Xu, Luozhou Wang, Zi- jie Zhuang, Yehang Zhang, Shuaibo Li, Xiaojun Hu, Bolan Su, and Ying-Cong Chen. 2026. Videomem- ory: Toward consistent video generation via memory integration.ArXiv, abs/2601.03655. Yupe...
arXiv 2026
-
[5]
Judge the output based on both storytelling quality and production usefulness
-
[6]
Focus on whether the storyboard can meaningfully guide video generation
-
[7]
Penalize contradictions, vagueness, redundant shots, missing key actions, broken continuity, and weak cinematic intent
-
[8]
Reward outputs that are clear, visually grounded, temporally coherent, emotionally aligned, and well-paced
-
[9]
## Evaluation Dimensions Score each dimension on a scale from 1 to 5: ### 1
Be objective and concise, but provide enough evidence for each score. ## Evaluation Dimensions Score each dimension on a scale from 1 to 5: ### 1. Character Behavior Consistency Assess whether characters behave consistently across shots and scenes in terms of: - motivation, - emotional state, - physical actions, - identity continuity, - and interaction lo...
-
[10]
The full source novel text
-
[11]
Evaluate only the storyboard entries in the current batch, but use the entire novel as the source of truth
A storyboard batch JSON payload containing selected entries, each with `id` and `storyboard_description`. Evaluate only the storyboard entries in the current batch, but use the entire novel as the source of truth. ## Evaluation Dimension ### Narrative Faithfulness (NF) Measures how faithfully the generated storyboard reflects the source novel in terms of ...
-
[12]
Treat the source novel as authoritative
-
[13]
Compare the storyboard batch against the novel for scene order, characters, settings, dialogue/action, and plot beats
-
[14]
Penalize invented scenes, wrong character identities, incorrect settings, altered motivations, and unsupported plot events
-
[15]
Do not penalize reasonable visual elaboration if it is consistent with the novel and does not add unsupported plot content
-
[16]
Focus on whether the current batch's content is faithful to the corresponding source narrative
Because the storyboard is evaluated in batches, do not penalize this batch for novel content that belongs outside the current storyboard span. Focus on whether the current batch's content is faithful to the corresponding source narrative
-
[17]
scores": {
Be strict about hallucinations, but distinguish harmless cinematic wording from factual contradiction. ## Required Evaluation Output Format Respond with only one valid JSON object. Do not include markdown fences or any prose before or after the JSON. Use exactly this schema: { "scores": { "narrative_faithfulness": 1 }, "rationale": { "narrative_faithfulne...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.