Nonparametric undirected graphical model selection using diffusion models
Pith reviewed 2026-06-27 18:06 UTC · model grok-4.3
The pith
Diffusion models enable consistent nonparametric selection of undirected graphical models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We develop a nonparametric approach to undirected graphical model selection based on diffusion models. Recent work has shown that diffusion models can adapt to the unknown graph structure of the underlying distribution, yet utilizing these models for explicit graph estimation remains unexplored. To bridge this gap, we introduce a novel diffusion-based method for nonparametric undirected graphical model selection. We establish the model selection consistency of the proposed method and demonstrate its empirical performance through extensive simulations and two real data analyses.
What carries the argument
A diffusion-based estimator that adapts to the unknown graph structure to perform explicit estimation of the conditional independence graph.
If this is right
- The estimator achieves model selection consistency without assuming any parametric form for the joint distribution.
- The approach applies directly to high-dimensional random variables.
- Simulations confirm reliable recovery of the graph structure under the stated conditions.
- Real-data applications recover interpretable conditional independence structures.
Where Pith is reading between the lines
- The consistency result may transfer to other score-based or generative models that capture dependence without parametric restrictions.
- The method could be tested on synthetic nonparametric distributions with known graphs to isolate the adaptation step.
- Hybrid estimators that combine diffusion adaptation with kernel or nearest-neighbor dependence measures become natural next steps.
Load-bearing premise
Diffusion models can adapt to the unknown graph structure of the underlying distribution.
What would settle it
A large-sample simulation with a known nonparametric distribution in which the method selects an incorrect graph structure that violates the true conditional independences would contradict the consistency claim.
Figures

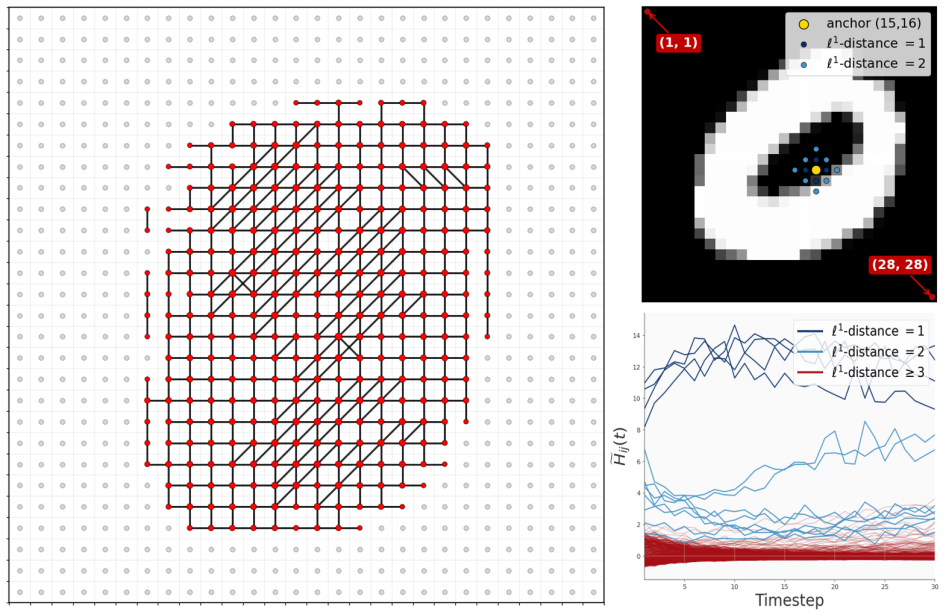
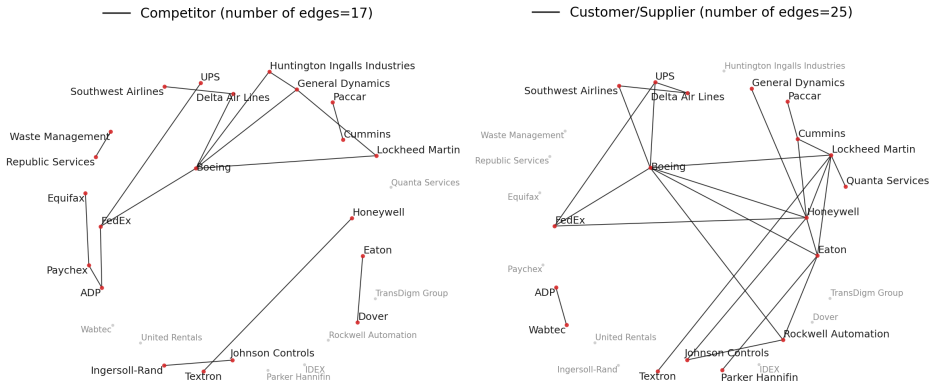
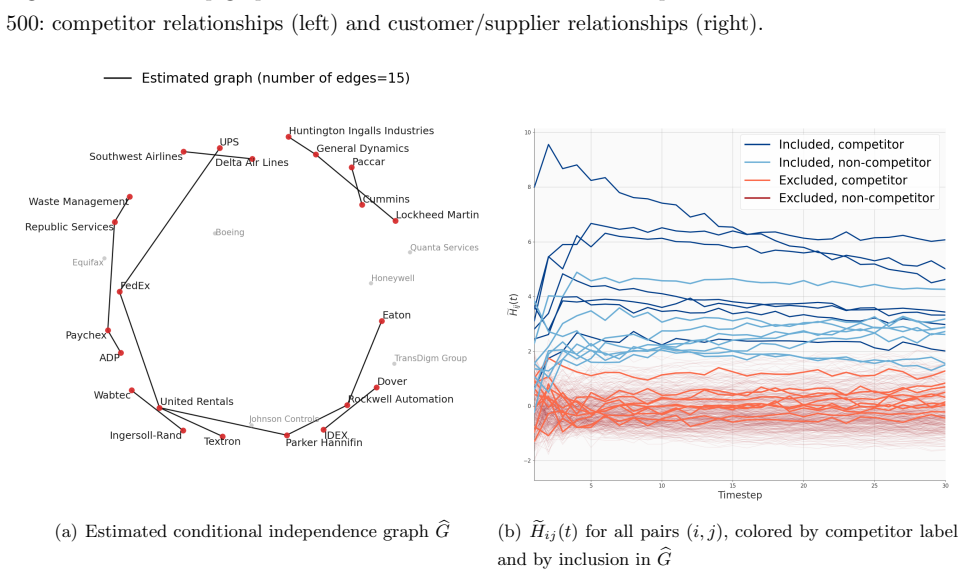
read the original abstract
Undirected graphical models provide a fundamental framework for representing conditional independence structures among high-dimensional random variables. While undirected graphical model selection has become a central problem in high-dimensional statistics, most existing methods are restricted to parametric settings. In this paper, we develop a nonparametric approach to undirected graphical model selection based on diffusion models. Recent work has shown that diffusion models can adapt to the unknown graph structure of the underlying distribution, yet utilizing these models for explicit graph estimation remains unexplored. To bridge this gap, we introduce a novel diffusion-based method for nonparametric undirected graphical model selection. We establish the model selection consistency of the proposed method and demonstrate its empirical performance through extensive simulations and two real data analyses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a nonparametric method for undirected graphical model selection that leverages diffusion models' ability to adapt to unknown graph structures. It claims to establish model selection consistency for the proposed estimator and reports empirical success on simulations plus two real-data examples.
Significance. A rigorously proven consistency result for nonparametric graphical model selection would be a notable contribution, as most existing high-dimensional methods remain parametric. The diffusion-model route could supply a flexible, structure-adaptive alternative if the technical conditions are mild and the rates are competitive.
minor comments (2)
- The abstract states that 'recent work has shown that diffusion models can adapt to the unknown graph structure,' but does not cite the specific references; these should be added in the introduction.
- Notation for the diffusion process, score function, and graph estimator should be introduced with explicit definitions before the consistency theorem is stated.
Simulated Author's Rebuttal
We thank the referee for their summary of the manuscript and for recognizing the potential significance of a rigorously proven consistency result for nonparametric undirected graphical model selection. We are encouraged by the positive assessment of the diffusion-model approach as a flexible alternative.
Circularity Check
No significant circularity
full rationale
The provided abstract claims model selection consistency for a diffusion-based nonparametric graphical model selector but presents no equations, fitted parameters, or derivation steps that reduce the consistency result to a self-definition, a renamed input, or a self-citation chain. The reference to prior work on diffusion models adapting to unknown graphs is external and not shown to be load-bearing for the consistency proof. Without any exhibited reduction of the central claim to its own inputs, the derivation chain is treated as self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2015 , publisher=
Statistical Learning with Sparsity , author=. 2015 , publisher=
2015
-
[2]
van de Geer, Sara , year=
-
[3]
Approximation by superpositions of a sigmoidal function , author=. Math. Control Signals Systems , volume=. 1989 , publisher=
1989
-
[4]
Searching for activation functions , author=. ArXiv:1710.05941 , year=
-
[5]
Incorporating second-order functional knowledge for better option pricing , booktitle = NIPS, year =
Dugas, Charles and Bengio, Yoshua and B\'. Incorporating second-order functional knowledge for better option pricing , booktitle = NIPS, year =
-
[6]
ICML Workshop on Deep Learning for Audio, Speech, and Language Processing , year =
Rectifier nonlinearities improve neural network acoustic models , author=. ICML Workshop on Deep Learning for Audio, Speech, and Language Processing , year =
-
[7]
, title =
Nair, Vinod and Hinton, Geoffrey E. , title =. 2010 , booktitle = ICML, pages =
2010
-
[8]
Statistically Efficient Estimation for Non-Smooth Probability Densities , author =
-
[9]
2022 , volume =
Masaaki Imaizumi and Kenji Fukumizu , title=. 2022 , volume =
2022
-
[10]
Generative modeling by estimating gradients of the data distribution , author=
-
[11]
Neural Comput
A connection between score matching and denoising autoencoders , author=. Neural Comput. , volume=. 2011 , publisher=
2011
-
[12]
Sliced score matching: A scalable approach to density and score estimation , author=. Proc. UAI , pages=
-
[13]
Estimation of non-normalized statistical models by score matching , author=
-
[14]
Handbook of Markov Chain Monte Carlo , publisher=
Neal, Radford M , title=. Handbook of Markov Chain Monte Carlo , publisher=. 2011 , editor=
2011
-
[15]
Maximum likelihood training of score-based diffusion models , author=
-
[16]
Deep Unsupervised Learning using Nonequilibrium Thermodynamics , author =
-
[17]
2023 , pages =
Diffusion Models are Minimax Optimal Distribution Estimators , author=. 2023 , pages =
2023
-
[18]
2018 , pages =
Sobolev GAN , author=. 2018 , pages =
2018
-
[19]
2021 , pages =
Score-Based Generative Modeling through Stochastic Differential Equations , author=. 2021 , pages =
2021
-
[20]
Optimal rates of approximation by shallow
Yang, Yunfei and Zhou, Ding-Xuan , journal=. Optimal rates of approximation by shallow
-
[21]
A likelihood approach to nonparametric estimation of a singular distribution using deep generative models , author=
-
[22]
Denoising diffusion probabilistic models , author=
-
[23]
2015 , pages=
Nice: Non-linear independent components estimation , author=. 2015 , pages=
2015
-
[24]
Expectation-propagation for the generative aspect model , author=. Proc. UAI , year=
-
[25]
Broderick, Tamara and Boyd, Nicholas and Wibisono, Andre and Wilson, Ashia C and Jordan, Michael I , journal=NIPS, volume=
-
[26]
Hoffman, Matthew and Bach, Francis and Blei, David , journal=NIPS, volume=
-
[27]
Variational Continual Learning , author=
-
[28]
Generalized Variational Continual Learning , author=
-
[29]
Practical variational inference for neural networks , author=
-
[30]
Weight uncertainty in neural network , author=
-
[31]
Louizos, Christos and Welling, Max , booktitle=ICML, pages=
-
[32]
Ghosh, Soumya and Yao, Jiayu and Doshi-Velez, Finale , booktitle=ICML, pages=
-
[33]
Efficient variational inference for sparse deep learning with theoretical guarantee , author=
-
[34]
Oh, Changyong and Adamczewski, Kamil and Park, Mijung , booktitle=AAAI, pages=
-
[35]
Sun, Shengyang and Zhang, Guodong and Shi, Jiaxin and Grosse, Roger , booktitle=ICLR, year=
-
[36]
2022 , pages=
Rudner, Tim GJ and Chen, Zonghao and Teh, Yee Whye and Gal, Yarin , journal=NeurIPS, volume=. 2022 , pages=
2022
-
[37]
Tran, Ba-Hien and Rossi, Simone and Milios, Dimitrios and Filippone, Maurizio , journal=JMLR, volume=
-
[38]
A bound on tail probabilities for quadratic forms in independent random variables , author=. Ann. Math. Statist. , volume=. 1971 , publisher=
1971
-
[39]
1973 , publisher=
A bound on tail probabilities for quadratic forms in independent random variables whose distributions are not necessarily symmetric , author=. 1973 , publisher=
1973
-
[40]
2017 , publisher=
Adaptive posterior contraction rates for the horseshoe , author=. 2017 , publisher=
2017
-
[41]
2015 , publisher=
Andrieu, Christophe and Vihola, Matti , journal=AoAS, volume=. 2015 , publisher=
2015
-
[42]
2015 , publisher=
Doucet, Arnaud and Pitt, Michael K and Deligiannidis, George and Kohn, Robert , journal=. 2015 , publisher=
2015
-
[43]
Biometrika , volume=
Large-sample asymptotics of the pseudo-marginal method , author=. Biometrika , volume=. 2021 , publisher=
2021
-
[44]
Biometrika , volume=
Posterior contraction in sparse generalized linear models , author=. Biometrika , volume=. 2021 , publisher=
2021
-
[45]
2021 , publisher=
Rossell, David and Abril, Oriol and Bhattacharya, Anirban , journal=JRSSB, volume=. 2021 , publisher=
2021
-
[46]
2021 , publisher=
Wan, Kitty Yuen Yi and Griffin, Jim E , journal=STCO, volume=. 2021 , publisher=
2021
-
[47]
2009 , publisher=
Andrieu, Christophe and Roberts, Gareth O , journal=AoS, volume=. 2009 , publisher=
2009
-
[48]
1996 , publisher=
Regression shrinkage and selection via the lasso , author=. 1996 , publisher=
1996
-
[49]
Zhao, Peng and Yu, Bin , journal=JMLR, volume=
-
[50]
2006 , publisher=
Zou, Hui , journal=JASA, volume=. 2006 , publisher=
2006
-
[51]
Tang, Rong and Yang, Yun , booktitle=COLT, pages=
-
[52]
2022 , publisher=
Bos, Thijs and Schmidt-Hieber, Johannes , journal=EJS, volume=. 2022 , publisher=
2022
-
[53]
Neural Networks , volume=
Fast convergence rates of deep neural networks for classification , author=. Neural Networks , volume=. 2021 , publisher=
2021
-
[54]
2021 , publisher=
On the rate of convergence of fully connected deep neural network regression estimates , author=. 2021 , publisher=
2021
-
[55]
Neural Comput
Neural networks for optimal approximation of smooth and analytic functions , author=. Neural Comput. , volume=. 1996 , publisher=
1996
-
[56]
The limits of min-max optimization algorithms: Convergence to spurious non-critical sets , author=
-
[57]
Mescheder, Lars and Geiger, Andreas and Nowozin, Sebastian , booktitle=ICML, pages=
-
[58]
, author=
Logistic stick-breaking process. , author=
-
[59]
2001 , publisher=
Gibbs sampling methods for stick-breaking priors , author=. 2001 , publisher=
2001
-
[60]
2020 , publisher=
-variational inference with statistical guarantees , author=. 2020 , publisher=
2020
-
[61]
Ghosh, Soumya and Delle Fave, Francesco Maria and Yedidia, Jonathan , booktitle=AAAI, pages=
-
[62]
2014 , publisher=
Zhang, Xiaole and Nott, David J and Yau, Christopher and Jasra, Ajay , journal=JCGS, volume=. 2014 , publisher=
2014
-
[63]
2011 , publisher=
Wang, Lianming and Dunson, David B , journal=JCGS, volume=. 2011 , publisher=
2011
-
[64]
Online learning of nonparametric mixture models via sequential variational approximation , author=
-
[65]
Experiments with a new boosting algorithm , author=. Proc. UAI , pages=
-
[66]
1990 , publisher=
Generalized Additive Models , author=. 1990 , publisher=
1990
-
[67]
2002 , publisher=
Wahba, Grace , journal=. 2002 , publisher=
2002
-
[68]
1996 , publisher=
The Nature of Statistical Learning Theory , author=. 1996 , publisher=
1996
-
[69]
2001 , publisher=
Greedy function approximation: A gradient boosting machine , author=. 2001 , publisher=
2001
-
[70]
2000 , publisher=
Additive logistic regression: A statistical view of boosting (with discussion) , author=. 2000 , publisher=
2000
-
[71]
1996 , organization=
Experiments with a new boosting algorithm , author=. 1996 , organization=
1996
-
[72]
Boosting a weak learning algorithm by majority , author=. Inform. and Comput. , volume=. 1995 , publisher=
1995
-
[73]
1990 , publisher=
The strength of weak learnability , author=. 1990 , publisher=
1990
-
[74]
Neural Comput
Nonconvex sparse regularization for deep neural networks and its optimality , author=. Neural Comput. , volume=. 2022 , publisher=
2022
-
[75]
Posterior concentration for sparse deep learning , author=
-
[76]
Salimans, Tim and Goodfellow, Ian and Zaremba, Wojciech and Cheung, Vicki and Radford, Alec and Chen, Xi , booktitle=NIPS, volume=
-
[77]
Minimum width for universal approximation , author=
-
[78]
Rethinking the inception architecture for computer vision , author=
-
[79]
Sinkhorn distances: Lightspeed computation of optimal transport , author=
-
[80]
Heusel, Martin and Ramsauer, Hubert and Unterthiner, Thomas and Nessler, Bernhard and Hochreiter, Sepp , booktitle = NIPS, pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.