SGSoft: Learning Fused Semantic-Geometric Features for 3D Shape Correspondence via Template-Guided Soft Signals
Pith reviewed 2026-05-20 11:44 UTC · model grok-4.3
The pith
SGSoft learns fused semantic-geometric descriptors supervised by a geodesic field on a canonical template to retrieve 3D shape correspondences in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
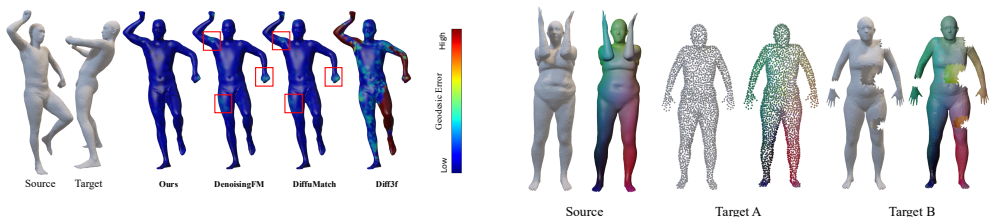
SGSoft constructs a geodesic correspondence field on a canonical template to supply stable, topology-invariant supervision. This field guides the learning of fused semantic-geometric dense descriptors. Once trained, the descriptors allow dense correspondences to be retrieved by simple nearest-neighbor search in a single feed-forward pass, eliminating the need for pre-alignment, pairwise optimization, or post-refinement. The method thereby achieves state-of-the-art inter-category generalization together with the best accuracy-efficiency trade-off reported among prior techniques.
What carries the argument
The geodesic correspondence field constructed on a canonical template, which supplies stable and topology-invariant supervision for training the multimodal descriptors.
If this is right
- Dense correspondences become available in near real time for arbitrary new shapes without any additional alignment or optimization steps.
- The learned descriptors generalize across object categories that differ substantially in structure and connectivity.
- Features trained for correspondence transfer directly to semantic segmentation and deformation transfer without retraining.
- Deployment becomes simpler because the pipeline requires neither pre-processing nor post-refinement stages.
Where Pith is reading between the lines
- The same template-guided supervision strategy could be adapted to other tasks that require consistent feature matching across non-isometric surfaces, such as texture transfer or animation retargeting.
- Because the method avoids pairwise optimization, it may scale to large collections of shapes where exhaustive matching would be prohibitive.
- Combining semantic priors with geometric signals inside a single descriptor might increase robustness when input meshes contain scanning noise or incomplete regions.
Load-bearing premise
A geodesic correspondence field on a canonical template remains stable and supplies topology-invariant supervision even under large pose variation, structural differences, and remeshing.
What would settle it
A controlled experiment in which the method's correspondence accuracy falls below that of prior baselines when evaluated on shape pairs that undergo arbitrary remeshing or extreme topological changes not seen during template construction.
Figures













read the original abstract
Learning dense correspondences across deformable 3D shapes remains a long-standing challenge due to structural variability, non-isometric deformation, and inconsistent topology. Existing methods typically trade off generalization, geometric fidelity, and efficiency. We address this by proposing SGSoft, a unified intrinsic pipeline that (i) constructs a geodesic correspondence field on a canonical template, (ii) learns multimodal dense descriptors guided by pretrained semantic priors with this geodesic correspondence field supervision, (iii) retrieves dense correspondences in a single feed-forward pass via nearest-neighbor search in descriptor space. This formulation enables stable and topology-invariant supervision under large pose variation, structural differences, and remeshing. SGSoft achieves state-of-the-art inter-category generalization while offering the best accuracy-efficiency trade-off among prior methods. It also achieves near real-time inference without pre-alignment, pairwise optimization, or post-refinement. Learned descriptors can be transferred effectively to downstream tasks such as semantic segmentation and deformation transfer, establishing a scalable and deployment-ready paradigm for dense 3D correspondence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SGSoft, a unified intrinsic pipeline for dense 3D shape correspondence. It constructs a geodesic correspondence field on a canonical template to supervise the learning of multimodal dense descriptors that fuse geometric features with pretrained semantic priors. Dense correspondences are then retrieved in a single feed-forward pass using nearest-neighbor search in the descriptor space. The authors assert that this enables stable and topology-invariant supervision under large pose variations, structural differences, and remeshing, leading to state-of-the-art inter-category generalization, the best accuracy-efficiency trade-off, near real-time inference without pre-alignment, pairwise optimization or post-refinement, and effective transfer to downstream tasks such as semantic segmentation and deformation transfer.
Significance. Should the experimental validation confirm the claims, this work would offer a notable contribution to the field of 3D computer vision by presenting an efficient, template-guided approach to dense correspondence that addresses key challenges like non-isometric deformations and inconsistent topologies through the integration of semantic and geometric cues. The emphasis on feed-forward inference and transferability to other tasks highlights its potential for practical deployment in applications requiring scalable shape analysis.
major comments (2)
- The abstract states SOTA results and efficiency claims but supplies no quantitative evidence, error bars, or experimental details; this undermines the ability to verify support for the central claims without the full experimental section.
- The claim that the geodesic correspondence field constructed on a canonical template provides stable and topology-invariant supervision under structural differences and remeshing (as stated in the abstract) is load-bearing for the inter-category generalization result. Since geodesics depend on mesh connectivity and global metric, a field from one template may not transfer isometrically to dissimilar categories; the manuscript should include a specific derivation or ablation showing how semantic priors compensate for these mismatches.
minor comments (1)
- The phrasing 'unified intrinsic pipeline' in the abstract could be clarified with a brief definition or reference to prior intrinsic methods for improved readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the potential contribution. We address each major comment in detail below, providing clarifications and indicating revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: The abstract states SOTA results and efficiency claims but supplies no quantitative evidence, error bars, or experimental details; this undermines the ability to verify support for the central claims without the full experimental section.
Authors: We agree that the abstract, as a high-level summary, does not include specific numerical results or error bars. The full manuscript provides these details in the experimental section, including tables with mean errors, standard deviations across multiple runs, runtime benchmarks, and comparisons to baselines. To improve accessibility, we have revised the abstract to incorporate key quantitative highlights (e.g., correspondence accuracy and inference speed) while maintaining its brevity. revision: yes
-
Referee: The claim that the geodesic correspondence field constructed on a canonical template provides stable and topology-invariant supervision under structural differences and remeshing (as stated in the abstract) is load-bearing for the inter-category generalization result. Since geodesics depend on mesh connectivity and global metric, a field from one template may not transfer isometrically to dissimilar categories; the manuscript should include a specific derivation or ablation showing how semantic priors compensate for these mismatches.
Authors: We appreciate this insightful observation on the potential limitations of geodesic-based supervision across categories. The semantic priors, derived from large-scale pretrained models, provide category-agnostic cues that mitigate sensitivity to exact mesh connectivity and metric variations. In the revised manuscript, we have added a dedicated ablation study (new Table and accompanying analysis) that isolates the contribution of semantic fusion versus pure geometric/geodesic supervision. The results quantify improved robustness to structural differences and remeshing, supporting the generalization claims. We have also expanded the method section with a brief discussion of the compensation mechanism. revision: yes
Circularity Check
Derivation chain is self-contained with external template supervision and pretrained priors
full rationale
The paper constructs a geodesic correspondence field on a canonical template as explicit supervision and fuses it with external pretrained semantic priors to learn descriptors; correspondences are then retrieved by nearest-neighbor search in the learned descriptor space. No equation or step reduces a claimed output (e.g., inter-category correspondences or generalization) to a fitted parameter or self-citation by construction. The pipeline is feed-forward, uses independent geometric computation on the template, and external priors, making the central claims falsifiable against held-out data rather than tautological with the inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
constructs a geodesic correspondence field on a canonical template... ˜Si,v = exp(−dgeo(th(i),tv)²/σ²)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
geodesic correspondence field-weighted InfoNCE loss... Lsoft = −1/M Σ ˜Si,v log exp(Ai,v/τ)/Σ exp(Ai,u/τ)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Neural jaco- bian fields: Learning intrinsic mappings of arbitrary meshes
Noam Aigerman, Kunal Gupta, Vladimir G Kim, Siddhartha Chaudhuri, Jun Saito, and Thibault Groueix. Neural jaco- bian fields: Learning intrinsic mappings of arbitrary meshes. arXiv preprint arXiv:2205.02904, 2022. 2, 3, 7
-
[2]
Optimal step nonrigid icp algorithms for surface registration
Brian Amberg, Sami Romdhani, and Thomas Vetter. Optimal step nonrigid icp algorithms for surface registration. In2007 IEEE conference on computer vision and pattern recogni- tion, pages 1–8. IEEE, 2007. 2, 3
work page 2007
-
[3]
Scape: shape completion and animation of people
Dragomir Anguelov, Praveen Srinivasan, Daphne Koller, Se- bastian Thrun, Jim Rodgers, and James Davis. Scape: shape completion and animation of people. InACM Siggraph 2005 Papers, pages 408–416. 2005. 6
work page 2005
-
[4]
Souhaib Attaiki and Maks Ovsjanikov. Ncp: Neural cor- respondence prior for effective unsupervised shape match- ing.Advances in Neural Information Processing Systems, 35:28842–28857, 2022. 2, 3
work page 2022
-
[5]
Souhaib Attaiki and Maks Ovsjanikov. Shape non-rigid kine- matics (snk): A zero-shot method for non-rigid shape match- ing via unsupervised functional map regularized reconstruc- tion.Advances in Neural Information Processing Systems, 36:70012–70032, 2023. 3
work page 2023
-
[6]
Hybrid functional maps for crease-aware non- isometric shape matching
Lennart Bastian, Yizheng Xie, Nassir Navab, and Zorah L¨ahner. Hybrid functional maps for crease-aware non- isometric shape matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3313–3323, 2024. 3
work page 2024
-
[7]
Yoshua Bengio, J ´erˆome Louradour, Ronan Collobert, and Ja- son Weston. Curriculum learning. InProceedings of the 26th annual international conference on machine learning, pages 41–48, 2009. 6
work page 2009
-
[8]
Mina: Convex mixed-integer programming for non-rigid shape alignment
Florian Bernard, Zeeshan Khan Suri, and Christian Theobalt. Mina: Convex mixed-integer programming for non-rigid shape alignment. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 13826–13835, 2020. 3
work page 2020
-
[9]
Faust: Dataset and evaluation for 3d mesh registration
Federica Bogo, Javier Romero, Matthew Loper, and Michael J Black. Faust: Dataset and evaluation for 3d mesh registration. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3794–3801,
-
[10]
On unsuper- vised partial shape correspondence
Amit Bracha, Thomas Dag `es, and Ron Kimmel. On unsuper- vised partial shape correspondence. InProceedings of the Asian Conference on Computer Vision, pages 4488–4504,
-
[11]
Worm- hole loss for partial shape matching.arXiv preprint arXiv:2410.22899, 2024
Amit Bracha, Thomas Dag `es, and Ron Kimmel. Worm- hole loss for partial shape matching.arXiv preprint arXiv:2410.22899, 2024
-
[12]
Unsupervised deep multi-shape matching
Dongliang Cao and Florian Bernard. Unsupervised deep multi-shape matching. InEuropean conference on computer vision, pages 55–71. Springer, 2022
work page 2022
-
[13]
Unsupervised Learning of Robust Spectral Shape Matching
Dongliang Cao, Paul Roetzer, and Florian Bernard. Unsu- pervised learning of robust spectral shape matching.arXiv preprint arXiv:2304.14419, 2023. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Spectral meets spa- tial: Harmonising 3d shape matching and interpolation
Dongliang Cao, Marvin Eisenberger, Nafie El Amrani, Daniel Cremers, and Florian Bernard. Spectral meets spa- tial: Harmonising 3d shape matching and interpolation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 3658–3668, 2024. 3
work page 2024
-
[15]
Syn- chronous diffusion for unsupervised smooth non-rigid 3d shape matching
Dongliang Cao, Zorah L ¨ahner, and Florian Bernard. Syn- chronous diffusion for unsupervised smooth non-rigid 3d shape matching. InEuropean Conference on Computer Vi- sion, pages 262–281. Springer, 2024. 3
work page 2024
-
[16]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the International Conference on Computer Vi- sion (ICCV), 2021. 3
work page 2021
-
[17]
Dv- matcher: Deformation-based non-rigid point cloud matching guided by pre-trained visual features
Zhangquan Chen, Puhua Jiang, and Ruqi Huang. Dv- matcher: Deformation-based non-rigid point cloud matching guided by pre-trained visual features. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27264–27274, 2025. 2
work page 2025
-
[18]
Keenan Crane, Clarisse Weischedel, and Max Wardetzky. Geodesics in heat: A new approach to computing distance based on heat flow.ACM Transactions on Graphics (TOG), 32(5):1–11, 2013. 1
work page 2013
-
[19]
Vision transformers need registers, 2023
Timoth ´ee Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers, 2023. 3
work page 2023
-
[20]
Deformed implicit field: Modeling 3d shapes with learned dense correspon- dence
Yu Deng, Jiaolong Yang, and Xin Tong. Deformed implicit field: Modeling 3d shapes with learned dense correspon- dence. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 10286–10296,
-
[21]
Deep geometric functional maps: Robust feature learning for shape correspondence
Nicolas Donati, Abhishek Sharma, and Maks Ovsjanikov. Deep geometric functional maps: Robust feature learning for shape correspondence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8592–8601, 2020. 2, 3
work page 2020
-
[22]
Complex functional maps: A conformal link be- tween tangent bundles
Nicolas Donati, Etienne Corman, Simone Melzi, and Maks Ovsjanikov. Complex functional maps: A conformal link be- tween tangent bundles. InComputer Graphics Forum, pages 317–334. Wiley Online Library, 2022. 3
work page 2022
-
[23]
Diffusion 3d features (diff3f): Decorating untextured shapes with distilled semantic features
Niladri Shekhar Dutt, Sanjeev Muralikrishnan, and Niloy J Mitra. Diffusion 3d features (diff3f): Decorating untextured shapes with distilled semantic features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4494–4504, 2024. 2, 3, 7
work page 2024
-
[24]
Partial-to- partial shape matching with geometric consistency
Viktoria Ehm, Maolin Gao, Paul Roetzer, Marvin Eisen- berger, Daniel Cremers, and Florian Bernard. Partial-to- partial shape matching with geometric consistency. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27488–27497, 2024. 3
work page 2024
-
[25]
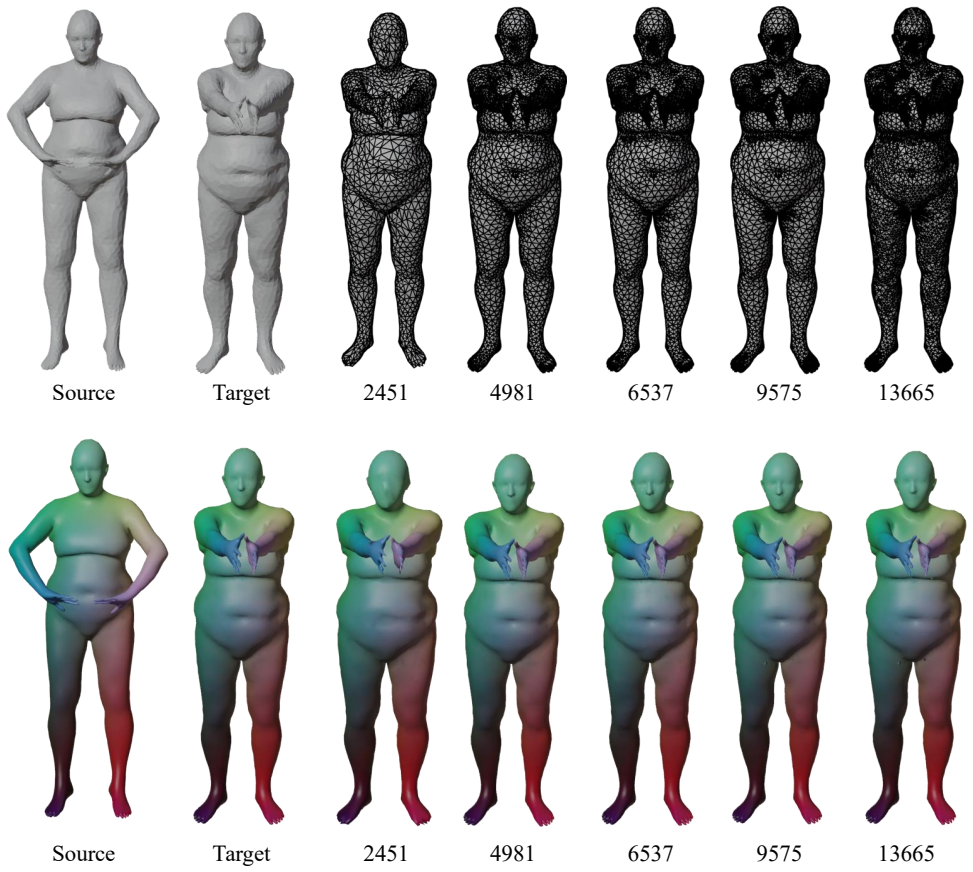
Viktoria Ehm, Paul Roetzer, Marvin Eisenberger, Maolin Gao, Florian Bernard, and Daniel Cremers. Geometrically 2451 9575 13665 6537 4981 Target Source 2451 9575 1366565374981TargetSource Figure 16.Topology robustness.Colors are transferred from a source to targets with different mesh resolutions. Numbers denote vertex counts. SGSoft preserves smooth and s...
work page 2024
-
[26]
Divergence-free shape correspondence by deformation
Marvin Eisenberger, Zorah L ¨ahner, and Daniel Cremers. Divergence-free shape correspondence by deformation. In Computer Graphics Forum, pages 1–12. Wiley Online Li- brary, 2019. 2
work page 2019
-
[27]
Smooth shells: Multi-scale shape registration with functional maps
Marvin Eisenberger, Zorah Lahner, and Daniel Cremers. Smooth shells: Multi-scale shape registration with functional maps. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 12265–12274,
-
[28]
Marvin Eisenberger, Aysim Toker, Laura Leal-Taix ´e, and Daniel Cremers. Deep shells: Unsupervised shape corre- spondence with optimal transport.Advances in Neural infor- mation processing systems, 33:10491–10502, 2020. 2
work page 2020
-
[29]
Neuromorph: Unsupervised shape interpo- lation and correspondence in one go
Marvin Eisenberger, David Novotny, Gael Kerchenbaum, Patrick Labatut, Natalia Neverova, Daniel Cremers, and An- drea Vedaldi. Neuromorph: Unsupervised shape interpo- lation and correspondence in one go. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7473–7483, 2021. 3
work page 2021
-
[30]
Meshnet: Mesh neural network for 3d shape rep- resentation
Yutong Feng, Yifan Feng, Haoxuan You, Xibin Zhao, and Yue Gao. Meshnet: Mesh neural network for 3d shape rep- resentation. InProceedings of the AAAI conference on arti- ficial intelligence, pages 8279–8286, 2019. 5 Source Target Faust Shrec19Scape Source Target Source Target Source Target Source Target Source Target Figure 17.Symmetry disambiguation.We vi...
work page 2019
-
[31]
3d-coded: 3d corre- spondences by deep deformation
Thibault Groueix, Matthew Fisher, Vladimir G Kim, Bryan C Russell, and Mathieu Aubry. 3d-coded: 3d corre- spondences by deep deformation. InProceedings of the eu- ropean conference on computer vision (ECCV), pages 230– 246, 2018. 2, 3
work page 2018
-
[32]
Pct: Point cloud transformer.Computational visual media, 7(2):187–199,
Meng-Hao Guo, Jun-Xiong Cai, Zheng-Ning Liu, Tai-Jiang Mu, Ralph R Martin, and Shi-Min Hu. Pct: Point cloud transformer.Computational visual media, 7(2):187–199,
-
[33]
Ziyu Guo, Renrui Zhang, Xiangyang Zhu, Yiwen Tang, Xi- anzheng Ma, Jiaming Han, Kexin Chen, Peng Gao, Xi- anzhi Li, Hongsheng Li, et al. Point-bind & point-llm: Aligning point cloud with multi-modality for 3d understand- ing, generation, and instruction following.arXiv preprint arXiv:2309.00615, 2023. 3, 5
-
[34]
Meshcnn: a network with an edge.ACM Transactions on Graphics (ToG), 38(4):1–12,
Rana Hanocka, Amir Hertz, Noa Fish, Raja Giryes, Shachar Fleishman, and Daniel Cohen-Or. Meshcnn: a network with an edge.ACM Transactions on Graphics (ToG), 38(4):1–12,
-
[35]
Arapreg: An as-rigid-as possible regularization loss for learning deformable shape generators
Qixing Huang, Xiangru Huang, Bo Sun, Zaiwei Zhang, Jun- feng Jiang, and Chandrajit Bajaj. Arapreg: An as-rigid-as possible regularization loss for learning deformable shape generators. InProceedings of the IEEE/CVF international conference on computer vision, pages 5815–5825, 2021. 3
work page 2021
-
[36]
Semantic-aware implicit template learning via part deformation consistency
Sihyeon Kim, Minseok Joo, Jaewon Lee, Juyeon Ko, Juhan Cha, and Hyunwoo J Kim. Semantic-aware implicit template learning via part deformation consistency. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 593–603, 2023. 3
work page 2023
-
[37]
4dcomplete: Non-rigid motion es- timation beyond the observable surface
Yang Li, Hikari Takehara, Takafumi Taketomi, Bo Zheng, and Matthias Nießner. 4dcomplete: Non-rigid motion es- timation beyond the observable surface. InProceedings of Mannequin DrakeNinjaPrisonerSkeletonzombie CryptoZlorp Intra Inter Source Target Source Target Source Target Source Target Source Target Source Target Source Target Source Target Source Targ...
work page 2021
-
[38]
Deep functional maps: Structured prediction for dense shape correspondence
Or Litany, Tal Remez, Emanuele Rodola, Alex Bronstein, and Michael Bronstein. Deep functional maps: Structured prediction for dense shape correspondence. InProceedings of the IEEE international conference on computer vision, pages 5659–5667, 2017. 2
work page 2017
-
[39]
Dingning Liu, Xiaoshui Huang, Yuenan Hou, Zhihui Wang, Zhenfei Yin, Yongshun Gong, Peng Gao, and Wanli Ouyang. Uni3d-llm: Unifying point cloud perception, generation and editing with large language models.arXiv preprint arXiv:2402.03327, 2024. 3, 5
-
[40]
Feng Liu and Xiaoming Liu. Learning implicit functions for dense 3d shape correspondence of generic objects.IEEE transactions on pattern analysis and machine intelligence, 46(3):1852–1867, 2023. 3
work page 2023
-
[41]
Stable-score: A stable registration-based framework for 3d shape correspondence
Haolin Liu, Xiaohang Zhan, Zizheng Yan, Zhongjin Luo, Yuxin Wen, and Xiaoguang Han. Stable-score: A stable registration-based framework for 3d shape correspondence. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 917–928, 2025. 2, 3
work page 2025
-
[42]
Unsupervised template warp con- sistency for implicit surface correspondences
Mengya Liu, Ajad Chhatkuli, Janis Postels, Luc Van Gool, and Federico Tombari. Unsupervised template warp con- sistency for implicit surface correspondences. InComputer Graphics Forum, pages 77–87. Wiley Online Library, 2023. 3
work page 2023
-
[43]
Self-supervised shape completion via involution and implicit correspondences
Mengya Liu, Ajad Chhatkuli, Janis Postels, Luc Van Gool, and Federico Tombari. Self-supervised shape completion via involution and implicit correspondences. InEuropean Con- ference on Computer Vision, pages 212–229. Springer, 2024. 3
work page 2024
-
[44]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. Smpl: a skinned multi- person linear model.ACM Trans. Graph., 34(6), 2015. 3, 4
work page 2015
-
[45]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Nicp: neural icp for 3d human registration at scale
Riccardo Marin, Enric Corona, and Gerard Pons-Moll. Nicp: neural icp for 3d human registration at scale. InEuropean Conference on Computer Vision, pages 265–285. Springer,
-
[47]
Shrec’19: matching humans with different connectivity
Simone Melzi, Riccardo Marin, Emanuele Rodol `a, Umberto Castellani, Jing Ren, Adrien Poulenard, P Ovsjanikov, et al. Shrec’19: matching humans with different connectivity. In Eurographics Workshop on 3D Object Retrieval, pages 1–8. The Eurographics Association, 2019. 6
work page 2019
-
[48]
Texture transfer using geometry corre- lation.Rendering Techniques, 273(10.2312):273–284, 2006
Tom Mertens, Jan Kautz, Jiawen Chen, Philippe Bekaert, and Fr ´edo Durand. Texture transfer using geometry corre- lation.Rendering Techniques, 273(10.2312):273–284, 2006. 2
work page 2006
-
[49]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. 5
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[50]
Maxime Oquab, Timoth ´ee Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Rus- sell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang- Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nico- las Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patri...
work page 2023
-
[51]
Maks Ovsjanikov, Mirela Ben-Chen, Justin Solomon, Adrian Butscher, and Leonidas Guibas. Functional maps: a flexible representation of maps between shapes.ACM Transactions on Graphics (ToG), 31(4):1–11, 2012. 2, 3
work page 2012
-
[52]
Gianluca Paravati, Fabrizio Lamberti, Valentina Gatteschi, Claudio Demartini, and Paolo Montuschi. Point cloud-based automatic assessment of 3d computer animation course- works.IEEE Transactions on Learning Technologies, 10(4): 532–543, 2016. 2
work page 2016
-
[53]
Diffumatch: Category-agnostic spectral diffusion priors for robust non-rigid shape matching
Emery Pierson, Lei Li, Angela Dai, and Maks Ovsjanikov. Diffumatch: Category-agnostic spectral diffusion priors for robust non-rigid shape matching. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5745–5756, 2025. 2, 6, 7, 3
work page 2025
-
[54]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660,
-
[56]
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017. 3, 4, 5
work page 2017
-
[57]
Unigs: Unified representa- tion for image generation and segmentation
Lu Qi, Lehan Yang, Weidong Guo, Yu Xu, Bo Du, Varun Jampani, and Ming-Hsuan Yang. Unigs: Unified representa- tion for image generation and segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 6305–6315, 2024. 3
work page 2024
-
[58]
Fridu: Functional map refinement with guided image dif- fusion
Avigail Cohen Rimon, Mirela Ben-Chen, and Or Litany. Fridu: Functional map refinement with guided image dif- fusion. InComputer Graphics Forum, page e70203. Wiley Online Library, 2025. 2, 3
work page 2025
-
[59]
Estimating curvatures and their derivatives on triangle meshes
Szymon Rusinkiewicz. Estimating curvatures and their derivatives on triangle meshes. InProceedings. 2nd Interna- tional Symposium on 3D Data Processing, Visualization and Transmission, 2004. 3DPVT 2004., pages 486–493. IEEE,
work page 2004
-
[60]
Pifu: Pixel-aligned implicit function for high-resolution clothed human digitiza- tion
Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Mor- ishima, Angjoo Kanazawa, and Hao Li. Pifu: Pixel-aligned implicit function for high-resolution clothed human digitiza- tion. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 2304–2314, 2019. 3
work page 2019
-
[61]
Nicholas Sharp, Souhaib Attaiki, Keenan Crane, and Maks Ovsjanikov. Diffusionnet: Discretization agnostic learning on surfaces.ACM Transactions on Graphics (TOG), 41(3): 1–16, 2022. 5
work page 2022
-
[62]
As-rigid-as-possible surface modeling
Olga Sorkine and Marc Alexa. As-rigid-as-possible surface modeling. InSymposium on Geometry processing, pages 109–116, 2007. 2, 3
work page 2007
-
[63]
Spatially and spectrally consistent deep functional maps
Mingze Sun, Shiwei Mao, Puhua Jiang, Maks Ovsjanikov, and Ruqi Huang. Spatially and spectrally consistent deep functional maps. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 14497–14507,
-
[64]
Yang-Tian Sun, Qian-Cheng Fu, Yue-Ren Jiang, Zitao Liu, Yu-Kun Lai, Hongbo Fu, and Lin Gao. Human motion trans- fer with 3d constraints and detail enhancement.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 45(4): 4682–4693, 2022. 2
work page 2022
-
[65]
Surface-aware distilled 3d semantic features.arXiv preprint arXiv:2503.18254, 2025
Lukas Uzolas, Elmar Eisemann, and Petr Kellnhofer. Surface-aware distilled 3d semantic features.arXiv preprint arXiv:2503.18254, 2025. 2
-
[66]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 5
work page 2017
-
[67]
Icon: Implicit clothed humans obtained from nor- mals
Yuliang Xiu, Jinlong Yang, Dimitrios Tzionas, and Michael J Black. Icon: Implicit clothed humans obtained from nor- mals. In2022 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 13286–13296. IEEE, 2022. 3
work page 2022
-
[68]
Pointllm: Empowering large language models to understand point clouds
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiang- miao Pang, and Dahua Lin. Pointllm: Empowering large language models to understand point clouds. InEuropean Conference on Computer Vision, pages 131–147. Springer,
-
[69]
Rignet: Neural rigging for artic- ulated characters.arXiv preprint arXiv:2005.00559, 2020
Zhan Xu, Yang Zhou, Evangelos Kalogerakis, Chris Lan- dreth, and Karan Singh. Rignet: Neural rigging for artic- ulated characters.arXiv preprint arXiv:2005.00559, 2020. 2
-
[70]
Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding
Le Xue, Mingfei Gao, Chen Xing, Roberto Mart ´ın-Mart´ın, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 1179–1189, 2023. 3, 5
work page 2023
-
[71]
Haitao Yang, Xiangru Huang, Bo Sun, Chandrajit Bajaj, and Qixing Huang. Gencorres: Consistent shape matching via coupled implicit-explicit shape generative models.arXiv preprint arXiv:2304.10523, 2023. 2, 3
-
[72]
Zijie Ye, Jia-Wei Liu, Jia Jia, Shikun Sun, and Mike Zheng Shou. Skinned motion retargeting with dense geometric in- teraction perception.Advances in Neural Informat Process- ing Systems, 2024. 2
work page 2024
-
[73]
Gal Yona, Roy Velich, Ehud Rivlin, and Ron Kimmel. Neu- ral descriptors: Self-supervised learning of robust local sur- face descriptors using polynomial patches. InInternational Conference on Scale Space and Variational Methods in Com- puter Vision, pages 218–230. Springer, 2025. 2
work page 2025
-
[74]
Point-bert: Pre-training 3d point cloud transformers with masked point modeling
Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19313–19322, 2022. 3, 5
work page 2022
-
[75]
Baowen Zhang, Jiahe Li, Xiaoming Deng, Yinda Zhang, Cuixia Ma, and Hongan Wang. Self-supervised learning of implicit shape representation with dense correspondence for deformable objects. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 14268– 14278, 2023. 3
work page 2023
-
[76]
Telling left from right: Identifying geometry-aware semantic corre- spondence
Junyi Zhang, Charles Herrmann, Junhwa Hur, Eric Chen, Varun Jampani, Deqing Sun, and Ming-Hsuan Yang. Telling left from right: Identifying geometry-aware semantic corre- spondence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3076– 3085, 2024. 2
work page 2024
-
[77]
Deep implicit templates for 3d shape representation
Zerong Zheng, Tao Yu, Qionghai Dai, and Yebin Liu. Deep implicit templates for 3d shape representation. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1429–1439, 2021. 2, 3
work page 2021
-
[78]
Uni3d: Exploring unified 3d representation at scale
Junsheng Zhou, Jinsheng Wang, Baorui Ma, Yu-Shen Liu, Tiejun Huang, and Xinlong Wang. Uni3d: Exploring unified 3d representation at scale.arXiv preprint arXiv:2310.06773,
-
[79]
Junzhe Zhu, Yuanchen Ju, Junyi Zhang, Muhan Wang, Zhecheng Yuan, Kaizhe Hu, and Huazhe Xu. Dense- matcher: Learning 3d semantic correspondence for category- level manipulation from a single demo.arXiv preprint arXiv:2412.05268, 2024. 2, 3
-
[80]
Denoising functional maps: Diffusion models for shape cor- respondence
Aleksei Zhuravlev, Zorah L ¨ahner, and Vladislav Golyanik. Denoising functional maps: Diffusion models for shape cor- respondence. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26899–26909, 2025. 2, 3, 6, 7
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.