Where Do Models Find Happiness? Emotion Vectors in Open-Source LLMs
Pith reviewed 2026-06-26 04:59 UTC · model grok-4.3
The pith
Emotion contrast vectors in two open-weight models recover valence geometry with correlations approaching those in Claude.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
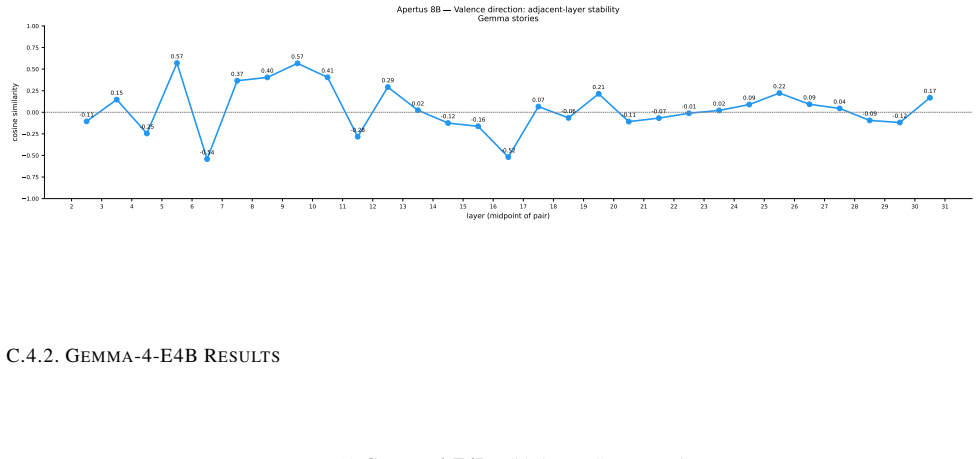
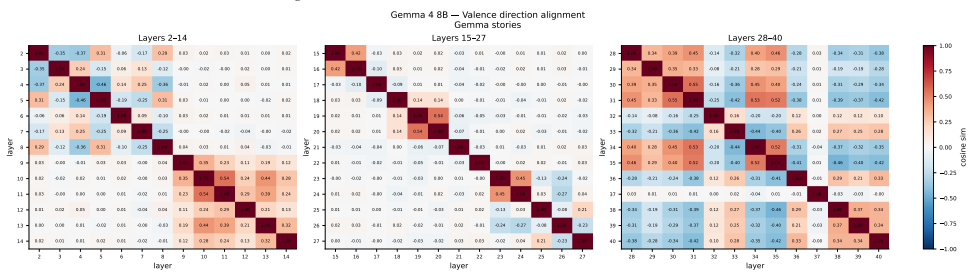
We recover valence geometry for both models, with peak PC1--valence correlations of r = 0.76 and r = 0.83, approaching the r = 0.81 reported for Claude. Beyond replication, we observe notable differences in how valence representations emerge across model depth. In Gemma-4-E4B-it, valence is strongly encoded in early layers but collapses towards later layers, whereas Apertus-8B-Instruct-2509 exhibits the opposite pattern, with valence representations absent in early layers, but emerging at mid depths. Arousal encoding, in contrast, is sensitive to the extraction corpus.
What carries the argument
Emotion contrast vectors extracted layer-wise from model-generated corpora and projected onto principal components.
If this is right
- Valence geometry appears in open models at strengths comparable to closed models.
- The depth at which valence is most strongly encoded depends on the specific model architecture.
- Arousal alignment is weaker overall and changes with the choice of generated corpus.
- Emotion concepts can be isolated as linear directions in open-weight model activations.
Where Pith is reading between the lines
- The layer-wise differences suggest that emotion geometry may be shaped by training details or architecture choices.
- Corpus sensitivity for arousal implies that richer or more varied text sources could strengthen secondary dimensions.
- Because the vectors are recoverable in open models, they become directly editable for studying causal effects on output behavior.
Load-bearing premise
The two model-generated corpora contain sufficiently rich and unbiased emotion-relevant linguistic cues for the contrast vectors to isolate internal emotion concepts rather than corpus artifacts.
What would settle it
Repeating the extraction on a new open model or with human-authored emotion stories and obtaining no significant PC1-valence correlation.
Figures


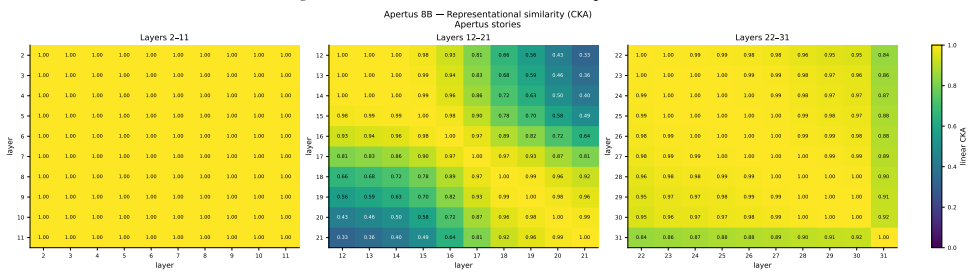

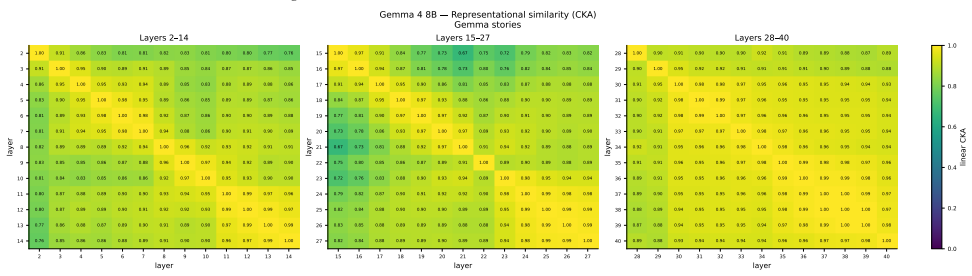

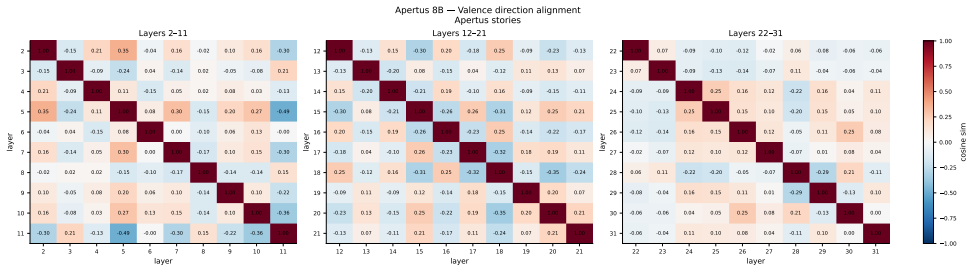
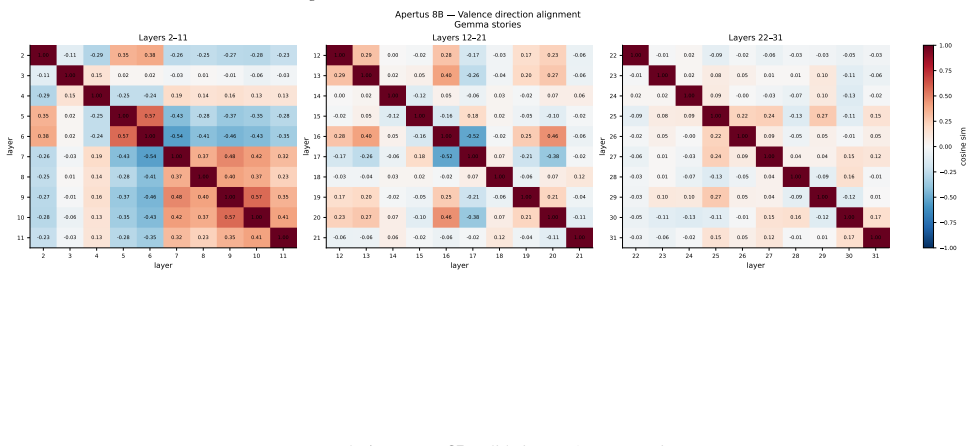



read the original abstract
Recent work identified emotion vectors in Claude Sonnet 4.5, which are internal representations that encode emotion concepts, causally influence behavior, and exhibit geometry mirroring human psychological structure. We test the generality of these findings in two open-weight models, Apertus-8B-Instruct-2509 and Gemma-4-E4B-it, extracting emotion contrast vectors across all layers, using two model-generated corpora. We recover valence geometry for both models, with peak PC1--valence correlations of $r = 0.76$ and $r = 0.83$, approaching the $r = 0.81$ reported for Claude.Beyond replication, we observe notable differences in how valence representations emerge across model depth. In Gemma-4-E4B-it, valence is strongly encoded in early layers but collapses towards later layers, whereas Apertus-8B-Instruct-2509 exhibits the opposite pattern, with valence representations absent in early layers, but emerging at mid depths. Arousal encoding, in contrast, is sensitive to the extraction corpus: both models show stronger PC2--arousal alignment with Gemma-generated stories ($r$ up to $0.45$) than Apertus-generated ones ($r \leq 0.21$), suggesting arousal-relevant cues are unevenly distributed across generated corpora. We open-source our experiment code and dataset for reproducible investigation of emotion representations across language model architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends findings on emotion vectors from Claude to two open-weight models (Apertus-8B-Instruct-2509 and Gemma-4-E4B-it). Using contrast vectors extracted from two model-generated corpora, it reports recovery of valence geometry via PCA, with peak PC1-valence correlations of r=0.76 and r=0.83. It additionally documents depth-dependent differences in valence encoding across models and corpus sensitivity in arousal alignment (stronger on Gemma-generated data). Code and data are open-sourced.
Significance. Replication of valence geometry in open models would support the generality of internal emotion representations beyond proprietary systems. The reported layer-wise emergence patterns and the explicit corpus-sensitivity finding for arousal provide concrete observations that could guide future mechanistic work. Open-sourcing the experiment code and dataset is a clear strength that enables direct reproducibility and extension by others.
major comments (2)
- [Results on arousal and valence encoding] Results section on arousal encoding: the manuscript explicitly reports corpus dependence for PC2-arousal alignment (r up to 0.45 on Gemma corpus vs r ≤ 0.21 on Apertus corpus) yet provides no parallel breakdown of PC1-valence correlations computed separately on each corpus. Because the central claim is that the contrast vectors isolate stable model-internal emotion concepts rather than corpus artifacts, the absence of this robustness check for the headline valence results (r=0.76/0.83) leaves the interpretation underdetermined.
- [Results on valence geometry] Results on valence geometry: the peak PC1-valence correlations are stated without error bars, confidence intervals, p-values, or any description of layer-selection criteria and correction for multiple comparisons across layers. Given that the maxima are identified post-hoc by scanning all layers, these omissions prevent assessment of whether the reported values are statistically distinguishable from chance or from other layers.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the two major comments below and will incorporate revisions to enhance the statistical reporting and robustness checks as suggested.
read point-by-point responses
-
Referee: Results on arousal and valence encoding: the manuscript explicitly reports corpus dependence for PC2-arousal alignment (r up to 0.45 on Gemma corpus vs r ≤ 0.21 on Apertus corpus) yet provides no parallel breakdown of PC1-valence correlations computed separately on each corpus. Because the central claim is that the contrast vectors isolate stable model-internal emotion concepts rather than corpus artifacts, the absence of this robustness check for the headline valence results (r=0.76/0.83) leaves the interpretation underdetermined.
Authors: We agree that a corpus-specific breakdown for the valence correlations would provide stronger evidence for the stability of the emotion vectors. Although the original analysis pooled the corpora to identify the peak correlations, we will recompute and report the PC1-valence correlations separately for each corpus in the revised manuscript. This will include the maximum r values per corpus for each model, allowing direct comparison to the arousal results and addressing concerns about corpus artifacts. revision: yes
-
Referee: Results on valence geometry: the peak PC1-valence correlations are stated without error bars, confidence intervals, p-values, or any description of layer-selection criteria and correction for multiple comparisons across layers. Given that the maxima are identified post-hoc by scanning all layers, these omissions prevent assessment of whether the reported values are statistically distinguishable from chance or from other layers.
Authors: The referee correctly identifies a gap in our statistical reporting. The correlations were computed layer-wise, with peaks selected as the maximum across layers. In the revision, we will add bootstrap-derived confidence intervals and standard errors for the reported correlations, p-values for the peak correlations (testing against zero), and apply a multiple-comparison correction (e.g., false discovery rate) across the layers tested. We will also explicitly describe the layer-selection procedure. These additions will allow readers to evaluate the reliability of the reported peaks. revision: yes
Circularity Check
No significant circularity; empirical measurement against external ratings
full rationale
The paper extracts contrast vectors from model-generated text, computes PCA, and reports direct Pearson correlations between PC1/PC2 and independent human valence/arousal ratings (r values given explicitly). No equations, fitted parameters, or self-citations reduce these correlations to inputs by construction. The work cites prior Claude results only for comparison and does not invoke uniqueness theorems, ansatzes, or renamings from overlapping authors. Corpus sensitivity for arousal is reported transparently rather than hidden, but this affects validity, not circularity of the derivation chain. The central results remain independent empirical measurements.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Model-generated stories contain emotion-relevant cues that are representative of the concepts the model internally represents.
- domain assumption Principal components of contrast vectors correspond to psychologically meaningful dimensions such as valence and arousal.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2410.19750 , year=
The Geometry of Concepts: Sparse Autoencoder Feature Structure , author=. arXiv preprint arXiv:2410.19750 , year=
-
[2]
arXiv preprint arXiv:2403.19647 , year=
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author=. arXiv preprint arXiv:2403.19647 , year=
-
[3]
arXiv preprint arXiv:2309.08600 , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. arXiv preprint arXiv:2309.08600 , year=
-
[4]
Transformer Circuits Thread , year=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. Transformer Circuits Thread , year=
-
[5]
arXiv preprint arXiv:2408.05147 , year=
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2 , author=. arXiv preprint arXiv:2408.05147 , year=
-
[6]
arXiv preprint arXiv:2407.14435 , year=
Jumping Ahead: Improving Reconstruction Fidelity with JumpReLU Sparse Autoencoders , author=. arXiv preprint arXiv:2407.14435 , year=
-
[7]
arXiv preprint arXiv:2406.04093 , year=
Scaling and Evaluating Sparse Autoencoders , author=. arXiv preprint arXiv:2406.04093 , year=
-
[8]
Transformer Circuits Thread , year=
A Mathematical Framework for Transformer Circuits , author=. Transformer Circuits Thread , year=
-
[9]
Interpretability in the Wild: A Circuit for Indirect Object Identification in
Wang, Kevin and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , booktitle=. Interpretability in the Wild: A Circuit for Indirect Object Identification in
-
[10]
Advances in Neural Information Processing Systems , year=
Towards Automated Circuit Discovery for Mechanistic Interpretability , author=. Advances in Neural Information Processing Systems , year=
-
[11]
Advances in Neural Information Processing Systems , year=
Investigating Gender Bias in Language Models Using Causal Mediation Analysis , author=. Advances in Neural Information Processing Systems , year=
-
[12]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle=. Locating and Editing Factual Associations in
-
[13]
arXiv preprint arXiv:2304.05969 , year=
Localizing Model Behavior with Path Patching , author=. arXiv preprint arXiv:2304.05969 , year=
-
[14]
arXiv preprint arXiv:1610.01644 , year=
Understanding Intermediate Layers Using Linear Classifier Probes , author=. arXiv preprint arXiv:1610.01644 , year=
-
[15]
Frontiers in Systems Neuroscience , volume=
Representational Similarity Analysis -- Connecting the Branches of Systems Neuroscience , author=. Frontiers in Systems Neuroscience , volume=
-
[16]
Distill , year=
Feature Visualization , author=. Distill , year=
-
[17]
arXiv preprint , year=
Gemma 3 Technical Report , author=. arXiv preprint , year=
-
[18]
Transformer Circuits Thread , year=
Sofroniew, Nicholas and Kauvar, Isaac and Saunders, William and Chen, Runjin and Henighan, Tom and Hydrie, Sasha and Citro, Craig and Pearce, Adam and Tarng, Julius and Gurnee, Wes and Batson, Joshua and Zimmerman, Sam and Rivoire, Kelley and Fish, Kyle and Olah, Chris and Lindsey, Jack , title=. Transformer Circuits Thread , year=
-
[19]
NeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning , year=
BatchTopK Sparse Autoencoders , author=. NeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning , year=
2024
-
[20]
Alejandro Hernández-Cano and Alexander Hägele and Allen Hao Huang and Angelika Romanou and Antoni-Joan Solergibert and Barna Pasztor and Bettina Messmer and Dhia Garbaya and Eduard Frank Ďurech and Ido Hakimi and Juan García Giraldo and Mete Ismayilzada and Negar Foroutan and Skander Moalla and Tiancheng Chen and Vinko Sabolčec and Yixuan Xu and Michael A...
-
[21]
ICML 2024 Workshop on Mechanistic Interpretability , year=
Language Models Linearly Represent Sentiment , author=. ICML 2024 Workshop on Mechanistic Interpretability , year=
2024
-
[22]
Linguistic Regularities in Continuous Space Word Representations
Mikolov, Tomas and Yih, Wen-tau and Zweig, Geoffrey. Linguistic Regularities in Continuous Space Word Representations. Proceedings of the 2013 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies. 2013
2013
-
[23]
Causal Representation Learning Workshop at NeurIPS 2023 , year=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. Causal Representation Learning Workshop at NeurIPS 2023 , year=
2023
-
[24]
2022 , journal=
Toy Models of Superposition , author=. 2022 , journal=
2022
-
[25]
2024 , eprint=
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. 2024 , eprint=
2024
-
[26]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Refusal in Language Models Is Mediated by a Single Direction , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[27]
Steering Llama 2 via Contrastive Activation Addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander. Steering Llama 2 via Contrastive Activation Addition. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.828
-
[28]
2017 , eprint=
Learning to Generate Reviews and Discovering Sentiment , author=. 2017 , eprint=
2017
-
[29]
European Conference on Information Retrieval , year=
On Interpretability and Feature Representations: An Analysis of the Sentiment Neuron , author=. European Conference on Information Retrieval , year=
-
[30]
Thirty-seventh Conference on Neural Information Processing Systems , year=
The geometry of hidden representations of large transformer models , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[31]
The Thirteenth International Conference on Learning Representations , year=
Emergence of a High-Dimensional Abstraction Phase in Language Transformers , author=. The Thirteenth International Conference on Learning Representations , year=
-
[32]
Proceedings of ACL , year=
Obtaining Reliable Human Ratings of Valence, Arousal, and Dominance for 20,000 English Words , author=. Proceedings of ACL , year=
-
[33]
, author=
A circumplex model of affect. , author=. Journal of personality and social psychology , volume=. 1980 , publisher=
1980
-
[34]
International conference on machine learning , pages=
Similarity of neural network representations revisited , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[35]
2026 , url =
Gemma 4: Expanding the Gemmaverse with Apache 2.0 , author =. 2026 , url =
2026
-
[36]
2026 , eprint=
Latent Structure of Affective Representations in Large Language Models , author=. 2026 , eprint=
2026
-
[37]
2026 , eprint=
Valence-Arousal Subspace in LLMs: Circular Emotion Geometry and Multi-Behavioral Control , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.