T-FunS3D: Task-Driven Hierarchical Open-Vocabulary 3D Functionality Segmentation
Pith reviewed 2026-06-28 02:50 UTC · model grok-4.3
The pith
T-FunS3D segments functional components in 3D scenes for specific tasks by querying an instance-based scene graph with a vision-language model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
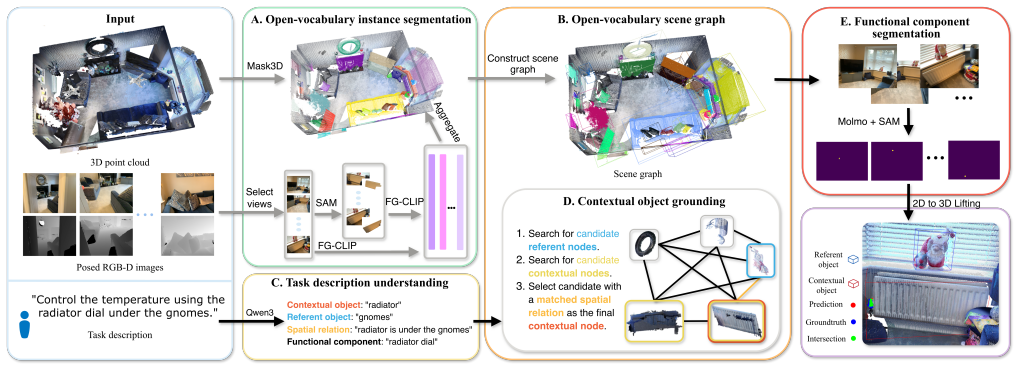
T-FunS3D takes 3D point clouds and posed RGB-D images to construct an open-vocabulary scene graph of instances and embeddings. For any task description, it selects the most relevant instances from the graph and applies a vision-language model to localize their functional components, delivering hierarchical segmentation focused on actionable parts rather than the entire scene.
What carries the argument
The open-vocabulary scene graph of extracted instances and visual embeddings, which enables task-specific selection followed by vision-language model localization of functional components.
If this is right
- Robots gain actionable 3D perception for tasks without processing every object in a scene.
- Resource requirements drop because segmentation stays limited to task-relevant instances.
- The approach supports varied indoor robotic applications through open-vocabulary task input.
- Comparable accuracy to prior methods is maintained on the SceneFun3D benchmark.
Where Pith is reading between the lines
- The scene-graph structure could support incremental updates for changing environments if paired with online mapping.
- Direct connection to motion planners might turn the segmented functional parts into executable robot actions.
- The same hierarchical selection could apply to other perception tasks such as affordance prediction beyond the current indoor focus.
Load-bearing premise
Instance extraction and the vision-language model can reliably identify and localize functional parts for arbitrary task descriptions without major errors or the need for exhaustive segmentation.
What would settle it
Running T-FunS3D on a new collection of real indoor scenes with unseen tasks and finding that its accuracy falls below state-of-the-art methods or that its runtime and memory exceed the reported gains would disprove the central performance claim.
Figures



read the original abstract
Open-vocabulary 3D functionality segmentation enables robots to localize functional object components in 3D scenes. It is a challenging task that requires spatial understanding and task interpretation. Current open-vocabulary 3D segmentation methods primarily focus on object-level recognition, while scene-wide part segmentation methods attempt to segment the entire scene exhaustively, making them highly resource-intensive and time consuming. Balancing segmentation performance in terms of granularity, accuracy, and speed remains a challenge. As one step towards alleviating this, we introduce T-FunS3D, a task-driven hierarchical open-vocabulary 3D functionality segmentation method that provides actionable perception for robotic applications. Our method takes as input the 3D point cloud and posed RGB-D images of an indoor scene. We construct an open-vocabulary scene graph by extracting instances and their visual embeddings in the environment. Given a task description, T-FunS3D identifies the most relevant instances in the scene graph and locates their functional components leveraging a vision-language model. Experiments on the SceneFun3D dataset demonstrate that T-FunS3D is comparable to state-of-the-art in open-vocabulary 3D functionality segmentation, while achieving faster runtime and reduced memory usage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces T-FunS3D, a task-driven hierarchical open-vocabulary 3D functionality segmentation method. It takes 3D point clouds and posed RGB-D images as input, constructs an open-vocabulary scene graph via instance extraction and visual embeddings, and for a given task description identifies relevant instances then localizes functional components using a vision-language model. The abstract asserts that experiments on the SceneFun3D dataset show performance comparable to state-of-the-art open-vocabulary 3D functionality segmentation methods while achieving faster runtime and reduced memory usage.
Significance. If the experimental claims hold with proper validation, the approach could enable more efficient task-specific perception for robotics by avoiding exhaustive scene-wide part segmentation, trading off full coverage for targeted localization with lower resource demands.
major comments (2)
- [Abstract] Abstract: the central claim of comparability to SOTA together with runtime and memory gains is asserted without any quantitative metrics, tables, ablation studies, or references to experimental protocols or results, leaving the primary contribution without visible empirical support.
- [Method description] Method (inferred from abstract description of VLM localization): the pipeline delegates functional component localization to a 2D VLM applied to selected instances followed by 3D mapping, yet provides no details on prompting strategy, 3D projection of VLM attention, or handling of partial occlusions/ambiguous tasks; these steps are load-bearing for the claimed segmentation accuracy and efficiency advantage.
minor comments (1)
- [Abstract] The phrase 'open-vocabulary scene graph' is used without a definition or citation to related scene-graph literature, which could confuse readers unfamiliar with the exact construction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and method description. We address each major comment below and will revise the manuscript to strengthen clarity and empirical support.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of comparability to SOTA together with runtime and memory gains is asserted without any quantitative metrics, tables, ablation studies, or references to experimental protocols or results, leaving the primary contribution without visible empirical support.
Authors: The abstract is intentionally concise as a summary. The full manuscript includes quantitative results in Section 4 with tables comparing T-FunS3D to prior methods on SceneFun3D (accuracy, runtime, memory), plus ablations. To address the concern, we will revise the abstract to include key metrics (e.g., mIoU, runtime in ms, memory footprint) and a brief reference to the experimental protocol. revision: yes
-
Referee: [Method description] Method (inferred from abstract description of VLM localization): the pipeline delegates functional component localization to a 2D VLM applied to selected instances followed by 3D mapping, yet provides no details on prompting strategy, 3D projection of VLM attention, or handling of partial occlusions/ambiguous tasks; these steps are load-bearing for the claimed segmentation accuracy and efficiency advantage.
Authors: We agree that explicit details on VLM prompting templates, the 2D-to-3D projection of attention maps, and handling of occlusions/ambiguous tasks are important for reproducibility. The current method section outlines the high-level pipeline but lacks these specifics. We will expand Section 3 with the required implementation details, including example prompts and occlusion-handling heuristics, in the revised manuscript. revision: yes
Circularity Check
No circularity: algorithmic pipeline without equations or self-referential fits
full rationale
The paper presents T-FunS3D as an algorithmic pipeline: input 3D point cloud and RGB-D images, construct open-vocabulary scene graph via instance extraction and visual embeddings, then apply VLM to identify relevant instances and localize functional components for a task description. No equations, derivations, fitted parameters, or predictions are described anywhere in the abstract or method outline. Experiments claim comparability to SOTA on SceneFun3D with efficiency gains, but this is an empirical evaluation of the pipeline, not a reduction of any claimed result to its own inputs. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way. This is a standard non-circular engineering contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scenefun3d: Fine-grained functionality and affordance understanding in 3d scenes,
A. Delitzas, A. Takmaz, F. Tombari, R. Sumner, M. Pollefeys, and F. Engelmann, “Scenefun3d: Fine-grained functionality and affordance understanding in 3d scenes,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[2]
J. J. Gibson,The ecological approach to visual perception: classic edition. Psychology press, 2014
2014
-
[3]
The generative lexicon,
J. Pustejovsky, “The generative lexicon,”Computational linguistics, 1991
1991
-
[4]
Search3D: Hierarchical Open-V ocabulary 3D Segmenta- tion,
A. Takmaz, A. Delitzas, R. W. Sumner, F. Engelmann, J. Wald, and F. Tombari, “Search3D: Hierarchical Open-V ocabulary 3D Segmenta- tion,”IEEE Robotics and Automation Letters, 2024
2024
-
[5]
Func- tionality understanding and segmentation in 3d scenes,
J. Corsetti, F. Giuliari, A. Fasoli, D. Boscaini, and F. Poiesi, “Func- tionality understanding and segmentation in 3d scenes,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[6]
Open-vocabulary functional 3d scene graphs for real- world indoor spaces,
C. Zhang, A. Delitzas, F. Wang, R. Zhang, X. Ji, M. Pollefeys, and F. Engelmann, “Open-vocabulary functional 3d scene graphs for real- world indoor spaces,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[7]
Fungraph: Functionality aware 3d scene graphs for language-prompted scene interaction,
D. Rotondi, F. Scaparro, H. Blum, and K. O. Arras, “Fungraph: Functionality aware 3d scene graphs for language-prompted scene interaction,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
2025
-
[8]
Sam3d: Segment anything in 3d scenes,
Y . Yang, X. Wu, T. He, H. Zhao, and X. Liu, “Sam3d: Segment anything in 3d scenes,”arXiv preprint arXiv:2306.03908, 2023
arXiv 2023
-
[9]
Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation,
A. Werby, C. Huang, M. B ¨uchner, A. Valada, and W. Burgard, “Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation,” inFirst Workshop on Vision-Language Models for Navigation and Manipulation at ICRA, 2024
2024
-
[10]
Clio: Real-time task-driven open-set 3d scene graphs,
D. Maggio, Y . Chang, N. Hughes, M. Trang, D. Griffith, C. Dougherty, E. Cristofalo, L. Schmid, and L. Carlone, “Clio: Real-time task-driven open-set 3d scene graphs,”IEEE Robotics and Automation Letters, 2024
2024
-
[11]
Openmask3d: open-vocabulary 3d instance seg- mentation,
A. Takmaz, E. Fedele, R. W. Sumner, M. Pollefeys, F. Tombari, and F. Engelmann, “Openmask3d: open-vocabulary 3d instance seg- mentation,” in37th International Conference on Neural Information Processing Systems, 2023
2023
-
[12]
Open3DIS: Open-V ocabulary 3D Instance Segmentation with 2D Mask Guidance,
P. D. A. Nguyen, T. D. Ngo, C. Gan, E. Kalogerakis, A. Tran, C. Pham, and K. Nguyen, “Open3DIS: Open-V ocabulary 3D Instance Segmentation with 2D Mask Guidance,”2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2024
-
[13]
Openins3d: Snap and lookup for 3d open-vocabulary instance seg- mentation,
Z. Huang, X. Wu, X. Chen, H. Zhao, L. Zhu, and J. Lasenby, “Openins3d: Snap and lookup for 3d open-vocabulary instance seg- mentation,” inEuropean Conference on Computer Vision, 2024
2024
-
[14]
Conceptfusion: Open-set multimodal 3d mapping,
K. Jatavallabhula, A. Kuwajerwala, Q. Gu, M. Omama, T. Chen, S. Li, G. Iyer, S. Saryazdi, N. Keetha, A. Tewari, J. Tenenbaum, C. de Melo, M. Krishna, L. Paull, F. Shkurti, and A. Torralba, “Conceptfusion: Open-set multimodal 3d mapping,”Robotics: Science and Systems (RSS), 2023
2023
-
[15]
Scenesplat: Gaussian splatting-based scene understanding with vision-language pretraining,
Y . Li, Q. Ma, R. Yang, H. Li, M. Ma, B. Ren, N. Popovic, N. Sebe, E. Konukoglu, T. Geverset al., “Scenesplat: Gaussian splatting-based scene understanding with vision-language pretraining,” inIEEE/CVF International Conference on Computer Vision, 2025
2025
-
[16]
Lerf: Language embedded radiance fields,
J. Kerr, C. M. Kim, K. Goldberg, A. Kanazawa, and M. Tancik, “Lerf: Language embedded radiance fields,” inIEEE/CVF international con- ference on computer vision, 2023
2023
-
[17]
Opennerf: Open set 3d neural scene segmentation with pixel-wise features and rendered novel views,
F. Engelmann, F. Manhardt, M. Niemeyer, K. Tateno, and F. Tombari, “Opennerf: Open set 3d neural scene segmentation with pixel-wise features and rendered novel views,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[18]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappaet al., “Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024
2024
-
[19]
Context-aware entity grounding with open-vocabulary 3d scene graphs,
H. Chang, K. Boyalakuntla, S. Lu, S. Cai, E. P. Jing, S. Keskar, S. Geng, A. Abbas, L. Zhou, K. Bekriset al., “Context-aware entity grounding with open-vocabulary 3d scene graphs,” in7th Annual Conference on Robot Learning, 2023
2023
-
[20]
Open3dsg: Open-vocabulary 3d scene graphs from point clouds with queryable objects and open-set relationships,
S. Koch, N. Vaskevicius, M. Colosi, P. Hermosilla, and T. Ropinski, “Open3dsg: Open-vocabulary 3d scene graphs from point clouds with queryable objects and open-set relationships,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[21]
Locate 3d: Real-world object localization via self-supervised learning in 3d,
P. McVay, S. Arnaud, A. Martin, A. Majumdar, K. M. Jatavallabhula, P. Thomas, R. Partsey, D. Dugas, A. Gejji, A. Saxet al., “Locate 3d: Real-world object localization via self-supervised learning in 3d,” in F orty-second International Conference on Machine Learning, 2025
2025
-
[22]
Part- slip: Low-shot part segmentation for 3d point clouds via pretrained image-language models,
M. Liu, Y . Zhu, H. Cai, S. Han, Z. Ling, F. Porikli, and H. Su, “Part- slip: Low-shot part segmentation for 3d point clouds via pretrained image-language models,” inIEEE/CVF conference on computer vision and pattern recognition, 2023
2023
-
[23]
Partslip++: Enhancing low-shot 3d part segmentation via multi-view instance segmentation and maximum likelihood estimation,
Y . Zhou, J. Gu, X. Li, M. Liu, and H. Su, “Partslip++: Enhancing low-shot 3d part segmentation via multi-view instance segmentation and maximum likelihood estimation,” inICCV 2025 Workshop on Wild 3D: 3D Modeling, Reconstruction, and Generation in the Wild, 2025
2025
-
[24]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inIEEE/CVF international conference on computer vision, 2023
2023
-
[25]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning, 2021
2021
-
[26]
Glip, a multimodular nonribosomal peptide synthetase in aspergillus fumigatus, makes the diketopiper- azine scaffold of gliotoxin,
C. J. Balibar and C. T. Walsh, “Glip, a multimodular nonribosomal peptide synthetase in aspergillus fumigatus, makes the diketopiper- azine scaffold of gliotoxin,”Biochemistry, 2006
2006
-
[27]
Emerging properties in self-supervised vision trans- formers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision trans- formers,” inIEEE/CVF international conference on computer vision, 2021
2021
-
[28]
Sampart3d: Segment any part in 3d objects,
Y . Yang, Y . Huang, Y .-C. Guo, L. Lu, X. Wu, E. Y . Lam, Y .-P. Cao, and X. Liu, “Sampart3d: Segment any part in 3d objects,”arXiv preprint arXiv:2411.07184, 2024
arXiv 2024
-
[29]
Fg-clip: Fine-grained visual and textual alignment,
C. Xie, B. Wang, F. Kong, J. Li, D. Liang, G. Zhang, D. Leng, and Y . Yin, “Fg-clip: Fine-grained visual and textual alignment,” in International Conference on Machine Learning, 2025
2025
-
[30]
Mask3D: Mask Transformer for 3D Semantic Instance Segmentation,
J. Schult, F. Engelmann, A. Hermans, O. Litany, S. Tang, and B. Leibe, “Mask3D: Mask Transformer for 3D Semantic Instance Segmentation,” inIEEE International Conference on Robotics and Automation (ICRA), 2023
2023
-
[31]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[32]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models,
M. Deitke, C. Clark, S. Lee, R. Tripathi, Y . Yang, J. S. Park, M. Salehi, N. Muennighoff, K. Lo, L. Soldainiet al., “Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[33]
3d scene graph: A structure for unified semantics, 3d space, and camera,
I. Armeni, Z.-Y . He, J. Gwak, A. R. Zamir, M. Fischer, J. Malik, and S. Savarese, “3d scene graph: A structure for unified semantics, 3d space, and camera,” inIEEE/CVF international conference on computer vision, 2019
2019
-
[34]
Kimera: an open- source library for real-time metric-semantic localization and mapping,
A. Rosinol, M. Abate, Y . Chang, and L. Carlone, “Kimera: an open- source library for real-time metric-semantic localization and mapping,” inIEEE International Conference on Robotics and Automation (ICRA), 2020
2020
-
[35]
3d dynamic scene graphs: Actionable spatial perception with places, objects, and humans,
A. Rosinol, A. Gupta, M. Abate, J. Shi, and L. Carlone, “3d dynamic scene graphs: Actionable spatial perception with places, objects, and humans,”Robotics: Science and Systems XVI, 2020
2020
-
[36]
Language-grounded indoor 3d semantic segmentation in the wild,
D. Rozenberszki, O. Litany, and A. Dai, “Language-grounded indoor 3d semantic segmentation in the wild,” inEuropean conference on computer vision, 2022
2022
-
[37]
Sigmoid loss for language image pre-training,
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” inIEEE/CVF international conference on computer vision, 2023
2023
-
[38]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdul- mohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafaet al., “Siglip 2: Multilingual vision-language encoders with improved se- mantic understanding, localization, and dense features,”arXiv preprint arXiv:2502.14786, 2025. T-FunS3D: Task-Driven Hierarchical Open-Vocabulary 3D Functi...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.