LASAR: Towards Spatio-temporal Reasoning with Latent Cognitive Map
Pith reviewed 2026-05-19 21:31 UTC · model grok-4.3
pith:JKNNJPLS Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{JKNNJPLS}
Prints a linked pith:JKNNJPLS badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
A dual-memory architecture with contrastive spatio-temporal learning builds latent cognitive maps for embodied agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LASAR features a dual-memory system for episodic experiences and a semantic cognitive map, trained with the ST-CRL contrastive objective that uses spatio-temporal cues from annotated contexts in simulation to form the internal cognitive map from the agent's experiences.
What carries the argument
The dual-memory system and ST-CRL contrastive objective, which builds sample pairs from spatio-temporal cues to maintain a semantic cognitive map alongside episodic memory.
Load-bearing premise
That the contrastive objective using simulation-generated spatio-temporal queries will compel the agent to encode actual spatial structures instead of task-specific shortcuts.
What would settle it
Observing no improvement in generalization or low self-consistency in the cognitive map when the ST-CRL objective is ablated would indicate that the spatial encoding is not occurring as claimed.
Figures






read the original abstract
A fundamental challenge in embodied AI is verifying if agents build internal models of spatial structure or merely learn to mimic task-specific expert trajectories. This is critical as foundational approaches rooted in action-centric tasks (e.g., VLN) and reasoning-centric tasks (e.g., EQA) often share a common limitation: they lack a learning signal that forces them to encode fine-grained spatial relationships (like topology or distance) over long-range, fragmented experiences. To address this, we first propose LASAR, an architecture featuring a dual-memory system designed to maintain both episodic experiences and a semantic cognitive map. We then introduce Spatio-temporal Contextual Representation Learning (ST-CRL), a contrastive objective designed to train this architecture. ST-CRL leverages spatio-temporal cues from cognitive queries generated through annotated spatio-temporal context in simulation to build sample pairs, thereby forming the internal cognitive map from the agent's experiences. Experiments demonstrate that our method achieves 2\%-3.5\% gains in both zero-shot generalization on standard VLN-CE and VSI-Bench benchmarks. We also demonstrate that our proposed cognitive map has high self-consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LASAR, a dual-memory architecture that maintains both episodic experiences and a semantic latent cognitive map, trained via Spatio-temporal Contextual Representation Learning (ST-CRL), a contrastive objective that constructs sample pairs from spatio-temporal cues generated through annotated context in simulation. It reports 2%-3.5% gains in zero-shot generalization on VLN-CE and VSI-Bench benchmarks together with high self-consistency of the proposed cognitive map.
Significance. If the central claim holds, the work supplies a targeted learning signal for encoding fine-grained spatial topology and metric relations over long-range fragmented trajectories, which is a recognized gap in action-centric and reasoning-centric embodied tasks. The dual-memory design and contrastive formulation are technically coherent and could generalize beyond the reported benchmarks.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the reported 2%-3.5% gains are presented without baselines, error bars, statistical tests, or ablation details, so it is impossible to determine whether the improvements are robust or attributable to the cognitive map rather than generic contrastive regularization or added memory capacity.
- [§3.2 and §4.3] §3.2 (ST-CRL objective) and §4.3 (self-consistency results): self-consistency is measured using the same ST-CRL objective that constructs the map, creating a circularity risk; this internal property can hold for systematically distorted maps and does not constitute an independent test of spatial fidelity.
- [§4] §4 (Evaluation): no direct measurement—such as map-derived distance queries, path lengths, or topology checks compared against simulator ground truth—is reported, leaving open the possibility that observed gains arise from task-specific mimicry rather than accurate long-range spatial encoding.
minor comments (2)
- [§3] Notation for the dual-memory components and the contrastive loss terms could be clarified with an explicit diagram or additional equations to improve readability.
- [§3.1] The description of how annotated spatio-temporal context is generated in simulation would benefit from a short pseudocode snippet or example.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important aspects of result presentation and evaluation that we address below. We have revised the manuscript to incorporate additional experimental details, statistical analyses, and independent evaluations as suggested.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the reported 2%-3.5% gains are presented without baselines, error bars, statistical tests, or ablation details, so it is impossible to determine whether the improvements are robust or attributable to the cognitive map rather than generic contrastive regularization or added memory capacity.
Authors: We agree that the original presentation of results required more supporting details to establish robustness. In the revised manuscript, Section 4 now includes additional baselines (including ablations removing the cognitive map or replacing ST-CRL with generic contrastive objectives), error bars computed over five random seeds, and statistical significance tests (paired t-tests with p-values). These additions clarify that the reported gains are attributable to the dual-memory architecture and spatio-temporal contrastive learning rather than generic regularization or capacity increases. revision: yes
-
Referee: [§3.2 and §4.3] §3.2 (ST-CRL objective) and §4.3 (self-consistency results): self-consistency is measured using the same ST-CRL objective that constructs the map, creating a circularity risk; this internal property can hold for systematically distorted maps and does not constitute an independent test of spatial fidelity.
Authors: The referee is correct that relying solely on the training objective for self-consistency introduces a circularity concern. We have revised §4.3 to include independent tests of spatial fidelity. These consist of direct comparisons between map-inferred distances, connectivity, and topology against simulator ground truth, which are not derived from the ST-CRL loss. The updated results show that the latent map maintains accurate metric and topological relations beyond what the contrastive objective alone would enforce. revision: yes
-
Referee: [§4] §4 (Evaluation): no direct measurement—such as map-derived distance queries, path lengths, or topology checks compared against simulator ground truth—is reported, leaving open the possibility that observed gains arise from task-specific mimicry rather than accurate long-range spatial encoding.
Authors: We acknowledge the value of direct measurements to rule out task-specific mimicry. The revised evaluation section now reports explicit map-derived distance queries, path-length accuracy, and topology verification against simulator ground truth on both VLN-CE and VSI-Bench. These metrics demonstrate that performance improvements correlate with faithful long-range spatial encoding in the cognitive map, providing evidence beyond downstream task success alone. revision: yes
Circularity Check
Cognitive map self-consistency is constructed and evaluated via the same ST-CRL objective
specific steps
-
self definitional
[Abstract]
"ST-CRL leverages spatio-temporal cues from cognitive queries generated through annotated spatio-temporal context in simulation to build sample pairs, thereby forming the internal cognitive map from the agent's experiences. ... We also demonstrate that our proposed cognitive map has high self-consistency."
The map is explicitly formed by the ST-CRL objective; high self-consistency is then claimed as a result. Because the objective directly trains for consistency on the same spatio-temporal query pairs, the reported self-consistency reduces to a property of the training signal rather than an independent test of accurate long-range spatial structure.
full rationale
The paper defines the cognitive map as being formed directly by the ST-CRL contrastive objective that uses annotated spatio-temporal cues to build sample pairs. Self-consistency is then reported as a positive demonstration. This creates a self-referential loop where the internal property optimized during training is presented as independent evidence of fine-grained spatial encoding (topology/distance). No external ground-truth comparison (e.g., map-derived distances vs. simulator metrics) is described in the provided text. Downstream benchmark gains supply some independent signal, preventing a higher circularity score.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contrastive learning on spatio-temporal cues extracted from simulation can force encoding of fine-grained spatial relationships such as topology and distance
invented entities (1)
-
Latent Cognitive Map
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ST-CRL is a contrastive objective... InfoNCE(m'_t, m'_p, N_t) with spatial hard negatives, semantic hard negatives, and region-id privileged information
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
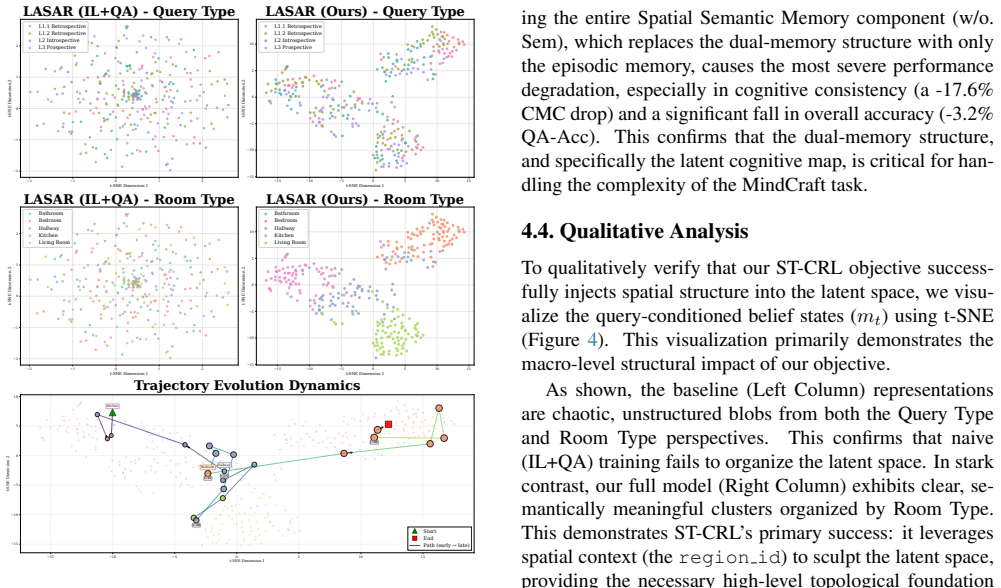
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Self-supervised object detection from egocentric videos
Peri Akiva, Jing Huang, Kevin J Liang, Rama Kovvuri, Xingyu Chen, Matt Feiszli, Kristin Dana, and Tal Hassner. Self-supervised object detection from egocentric videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5225–5237, 2023. 2
work page 2023
-
[2]
Peter Anderson, Qi Wu, Damien Teney, Joel Bruce, Mark Johnson, Stephen Gould, and Anton van den Hengel. Vision- and-language navigation: Interpreting visually-grounded navigation instructions in real environments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR 2018), Spotlight Oral, 2018. 1
work page 2018
-
[3]
Semantic world models.arXiv preprint arXiv:2510.19818, 2025
Jacob Berg, Chuning Zhu, Yanda Bao, Ishan Durugkar, and Abhishek Gupta. Semantic world models.arXiv preprint arXiv:2510.19818, 2025. 2
-
[4]
Edgar Bermudez-Contreras, Benjamin J. Clark, and Aaron Wilber. The neuroscience of spatial navigation and the rela- tionship to artificial intelligence.Frontiers in Computational Neuroscience, V olume 14 - 2020, 2020. 1
work page 2020
-
[5]
Rt-2: Vision-language-action mod- els transfer web knowledge to robotic control, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakr- ishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnik...
work page 2023
-
[6]
Neural topological SLAM for visual navigation.CoRR, abs/2005.12256, 2020
Devendra Singh Chaplot, Ruslan Salakhutdinov, Abhinav Gupta, and Saurabh Gupta. Neural topological SLAM for visual navigation.CoRR, abs/2005.12256, 2020. 2
-
[7]
Robot navigation with map-based deep reinforcement learning
Guangda Chen, Lifan Pan, Yu’an Chen, Pei Xu, Zhiqiang Wang, Peichen Wu, Jianmin Ji, and Xiaoping Chen. Robot navigation with map-based deep reinforcement learning. In Proceedings of the IEEE International Conference on Net- working, Sensing and Control (ICNSC), pages 1–6, 2020. 2
work page 2020
-
[8]
Longvila: Scaling long-context vi- sual language models for long videos
Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, et al. Longvila: Scaling long-context vi- sual language models for long videos. InThe Thirteenth In- ternational Conference on Learning Representations. 6
-
[9]
Navila: Legged robot vision-language-action model for navigation
An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Xueyan Zou, Jan Kautz, Erdem Biyik, Hongxu Yin, Sifei Liu, and Xiao- long Wang. Navila: Legged robot vision-language-action model for navigation. InRSS, 2025. 6
work page 2025
-
[10]
Simone Coppolino and Michele Migliore. An explainable artificial intelligence approach to spatial navigation based on hippocampal circuitry.Neural Networks, 163:97–107, 2023. 1
work page 2023
-
[11]
Abhishek Das, Samyak Datta, Georgia Gkioxari, Stefan Lee, Devi Parikh, and Dhruv Batra. Embodied question answer- ing.CoRR, abs/1711.11543, 2017. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duck- worth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence. Palm-e: an embodie...
work page 2023
-
[13]
Epstein, Eva Zita Patai, Joshua B
Russell A. Epstein, Eva Zita Patai, Joshua B. Julian, and Hugo J. Spiers. The cognitive map in humans: spatial nav- igation and beyond.Nature Neuroscience, 20:1504–1513,
-
[14]
David Ha and J ¨urgen Schmidhuber. World models.CoRR, abs/1803.10122, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Vln-bert: A recurrent vision-and-language bert for navigation
Yicong Hong, Qi Wu, Yuankai Qi, Cristian Rodriguez-Opazo, and Stephen Gould. Vln-bert: A recurrent vision-and-language bert for navigation. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021. 2
work page 2021
-
[16]
Ponder: Point cloud pre-training via neural rendering
Di Huang, Sida Peng, Tong He, Honghui Yang, Xiaowei Zhou, and Wanli Ouyang. Ponder: Point cloud pre-training via neural rendering. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 16089– 16098, 2023. 1
work page 2023
-
[17]
Spatio-temporal self-supervised representation learning for 3d point clouds
Siyuan Huang, Yichen Xie, Song-Chun Zhu, and Yixin Zhu. Spatio-temporal self-supervised representation learning for 3d point clouds. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 6535–6545,
-
[18]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Deepali Jain, Krzysztof M Choromanski, Kumar Avinava Dubey, Sumeet Singh, Vikas Sindhwani, Tingnan Zhang, and Jie Tan. Mnemosyne: Learning to train transformers with transformers.Advances in Neural Information Process- ing Systems, 36:77331–77358, 2023. 2
work page 2023
-
[20]
Stay on the Path: Instruction Fidelity in Vision-and-Language Navigation
Vihan Jain, Gabriel Magalh ˜aes, Alexander Ku, Ashish Vaswani, Eugene Ie, and Jason Baldridge. Stay on the path: Instruction fidelity in vision-and-language navigation. CoRR, abs/1905.12255, 2019. 1
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[21]
Yiming Ji, Yang Liu, Guanghu Xie, Boyu Ma, Zongwu Xie, and Hong Liu. Neds-slam: A neural explicit dense semantic slam framework using 3d gaussian splatting.IEEE Robotics and Automation Letters, 2024. 2
work page 2024
- [22]
-
[23]
Beyond the nav-graph: Vision and language navigation in continuous environments
Jacob Krantz, Erik Wijmans, Arjun Majundar, Dhruv Batra, and Stefan Lee. Beyond the nav-graph: Vision and language navigation in continuous environments. InEuropean Con- ference on Computer Vision (ECCV), 2020. 5, 7
work page 2020
-
[24]
Context- aware deep reinforcement learning for autonomous robotic navigation in unknown area
Jingsong Liang, Zhichen Wang, Yuhong Cao, Jimmy Chiun, Mengqi Zhang, and Guillaume Adrien Sartoretti. Context- aware deep reinforcement learning for autonomous robotic navigation in unknown area. InProceedings of The 7th Con- ference on Robot Learning, pages 1425–1436. PMLR, 2023. 2
work page 2023
-
[25]
Navcot: Boosting llm-based vision-and- language navigation via learning disentangled reasoning
Bingqian Lin, Yunshuang Nie, Ziming Wei, Jiaqi Chen, Shikui Ma, Jianhua Han, Hang Xu, Xiaojun Chang, and Xiaodan Liang. Navcot: Boosting llm-based vision-and- language navigation via learning disentangled reasoning. IEEE Transactions on Pattern Analysis and Machine Intel- ligence, 2025. 6
work page 2025
-
[26]
V olumetric environ- ment representation for vision-language navigation
Rui Liu, Wenguan Wang, and Yi Yang. V olumetric environ- ment representation for vision-language navigation. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16317–16328, 2024. 2
work page 2024
-
[27]
Self-Monitoring Navigation Agent via Auxiliary Progress Estimation
Chih-Yao Ma, Jiasen Lu, Zuxuan Wu, Ghassan AlRegib, Zsolt Kira, Richard Socher, and Caiming Xiong. Self- monitoring navigation agent via auxiliary progress estima- tion.CoRR, abs/1901.03035, 2019. 1
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[28]
Openeqa: Embodied question answering in the era of foun- dation models
Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, et al. Openeqa: Embodied question answering in the era of foun- dation models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16488– 16498, 2024. 2
work page 2024
-
[29]
Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, and Ping Luo. Embodiedgpt: Vision-language pre-training via embodied chain of thought.Advances in Neural Information Processing Systems, 36:25081–25094, 2023. 2
work page 2023
-
[30]
Octo: An open-source generalist robot policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Charles Xu, Jianlan Luo, Tobias Kreiman, You Liang Tan, Lawrence Yunliang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy. InProceedings of Robotics: Science and...
work page 2024
-
[31]
Self-supervised joint encoding of motion and appearance for first person action recognition
Mirco Planamente, Andrea Bottino, and Barbara Caputo. Self-supervised joint encoding of motion and appearance for first person action recognition. In2020 25th International Conference on Pattern Recognition (ICPR), pages 8751–
-
[32]
Zhaobo Qi, Shuhui Wang, Chi Su, Li Su, Qingming Huang, and Qi Tian. Self-regulated learning for egocentric video activity anticipation.IEEE transactions on pattern analysis and machine intelligence, 45(6):6715–6730, 2021. 2
work page 2021
-
[33]
Zhang, Bradley Emi, Amir Za- mir, Silvio Savarese, Leonidas J
Alexander Sax, Jeffrey O. Zhang, Bradley Emi, Amir Za- mir, Silvio Savarese, Leonidas J. Guibas, and Jitendra Malik. Learning to navigate using mid-level visual priors.CoRR, abs/1912.11121, 2019. 1
-
[34]
Shuo Sun, Malcolm Mielle, Achim J Lilienthal, and Mar- tin Magnusson. High-fidelity slam using gaussian splat- ting with rendering-guided densification and regularized op- timization. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10476–10482. IEEE, 2024. 2
work page 2024
-
[35]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of con- text.arXiv preprint arXiv:2403.05530, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Neural Discrete Representation Learning
A ¨aron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. CoRR, abs/1711.00937, 2017. 4
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
Representation Learning with Contrastive Predictive Coding
A ¨aron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding.CoRR, abs/1807.03748, 2018. 5
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2017. 4
work page 2017
-
[40]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 4, 6, 2
work page 2025
-
[41]
Causality-aware transformer networks for robotic naviga- tion
Ruoyu Wang, Yao Liu, Yuanjiang Cao, and Lina Yao. Causality-aware transformer networks for robotic naviga- tion. InInternational Conference on Neural Information Processing, pages 403–418. Springer, 2025. 2
work page 2025
-
[42]
Research on autonomous robots navigation based on reinforcement learning
Zixiang Wang, Hao Yan, Yining Wang, Zhengjia Xu, Zhuoyue Wang, and Zhizhong Wu. Research on autonomous robots navigation based on reinforcement learning. In2024 3rd International Conference on Robotics, Artificial Intelli- gence and Intelligent Control (RAIIC), pages 78–81. IEEE,
-
[43]
REMI: Reconstruct- ing episodic memory during internally driven path planning
Zhaoze Wang, Genela Morris, Dori Derdikman, Pratik Chaudhari, and Vijay Balasubramanian. REMI: Reconstruct- ing episodic memory during internally driven path planning. InThe Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems, 2025. 2
work page 2025
-
[44]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models.Advances in neural information processing systems, 35:24824–24837, 2022. 1
work page 2022
-
[45]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence.arXiv preprint arXiv:2505.23747, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Jiannan Xiang, Tianhua Tao, Yi Gu, Tianmin Shu, Zirui Wang, Zichao Yang, and Zhiting Hu. Language models meet world models: Embodied experiences enhance lan- guage models.Advances in neural information processing systems, 36:75392–75412, 2023. 2
work page 2023
-
[47]
Qwen2 technical report.CoRR, 2024
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2 technical report.CoRR, 2024. 6
work page 2024
-
[48]
Honghui Yang, Sha Zhang, Di Huang, Xiaoyang Wu, Haoyi Zhu, Tong He, Shixiang Tang, Hengshuang Zhao, Qibo Qiu, Binbin Lin, Xiaofei He, and Wanli Ouyang. Unipad: A uni- versal pre-training paradigm for autonomous driving.arXiv preprint arXiv:2310.08370, 2023. 1
-
[49]
Jihan Yang, Shusheng Yang, Anjali Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in Space: How Multi- modal Large Language Models See, Remember and Recall Spaces.arXiv preprint arXiv:2412.14171, 2024. 6, 7
-
[50]
Thinking in space: How mul- timodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How mul- timodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025. 1
work page 2025
-
[51]
Seqafford: Sequential 3d affordance reasoning via multimodal large language model
Chunlin Yu, Hanqing Wang, Ye Shi, Haoyang Luo, Sibei Yang, Jingyi Yu, and Jingya Wang. Seqafford: Sequential 3d affordance reasoning via multimodal large language model. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 1691–1701, 2025. 2
work page 2025
-
[52]
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision- language-action model for unifying embodied navigation tasks.arXiv preprint arXiv:2412.06224, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Navid: Video-based vlm plans the next step for vision-and-language navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and He Wang. Navid: Video-based vlm plans the next step for vision-and-language navigation. InRobotics: Science and Systems, 2024. 2
work page 2024
-
[54]
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and He Wang. Navid: Video-based vlm plans the next step for vision-and-language navigation.arXiv preprint arXiv:2402.15852, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Multi- scale video anomaly detection by multi-grained spatio- temporal representation learning
Menghao Zhang, Jingyu Wang, Qi Qi, Haifeng Sun, Zirui Zhuang, Pengfei Ren, Ruilong Ma, and Jianxin Liao. Multi- scale video anomaly detection by multi-grained spatio- temporal representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17385–17394, 2024. 2
work page 2024
-
[56]
Generative causal interpretation model for spatio- temporal representation learning
Yu Zhao, Pan Deng, Junting Liu, Xiaofeng Jia, and Jianwei Zhang. Generative causal interpretation model for spatio- temporal representation learning. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3537–3548, 2023. 2
work page 2023
-
[57]
Towards learning a generalist model for embod- ied navigation
Duo Zheng, Shijia Huang, Lin Zhao, Yiwu Zhong, and Li- wei Wang. Towards learning a generalist model for embod- ied navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13624– 13634, 2024. 2
work page 2024
-
[58]
Navgpt-2: Unleashing navigational reasoning capa- bility for large vision-language models
Gengze Zhou, Yicong Hong, Zun Wang, Xin Eric Wang, and Qi Wu. Navgpt-2: Unleashing navigational reasoning capa- bility for large vision-language models. InEuropean Con- ference on Computer Vision, pages 260–278. Springer, 2024. 2
work page 2024
-
[59]
Navgpt: explicit reasoning in vision-and-language navigation with large lan- guage models
Gengze Zhou, Yicong Hong, and Qi Wu. Navgpt: explicit reasoning in vision-and-language navigation with large lan- guage models. AAAI Press, 2024. 1
work page 2024
-
[60]
Navgpt: Explicit reasoning in vision-and-language navigation with large lan- guage models
Gengze Zhou, Yicong Hong, and Qi Wu. Navgpt: Explicit reasoning in vision-and-language navigation with large lan- guage models. InProceedings of the AAAI Conference on Artificial Intelligence, pages 7641–7649, 2024. 2
work page 2024
-
[61]
Haoyi Zhu, Honghui Yang, Xiaoyang Wu, Di Huang, Sha Zhang, Xianglong He, Tong He, Hengshuang Zhao, Chun- hua Shen, Yu Qiao, and Wanli Ouyang. Ponderv2: Pave the way for 3d foundation model with a universal pre-training paradigm.arXiv preprint arXiv:2310.08586, 2023. 1
-
[62]
3d-spatial mul- timodal memory
Xueyan Zou, Yuchen Song, Ri-Zhao Qiu, Xuanbin Peng, Jianglong Ye, Sifei Liu, and Xiaolong Wang. 3d-spatial mul- timodal memory. InThe Thirteenth International Conference on Learning Representations, 2025. 1 LASAR: Towards Spatio-temporal Reasoning with Latent Cognitive Map Supplementary Material
work page 2025
-
[63]
Model and Training Details 6.1. Train Data To accomplish the dual tasks of visual navigation and spatial rea- soning, our training dataset is constructed directly upon theVLN- CE (Vision-and-Language Navigation in Continuous Environ- ments) training set. Our core training curriculum is theMindCraft-Train dataset. As detailed in the main paper (Section 3.3...
-
[64]
Model Architecture Details Our proposed framework, LASAR, is constructed around a cen- tral Vision-Language Model (VLM) and is augmented by a series of specialized encoders. Each encoder is designed to process a specific modality (vision, geometry, trajectory), transforming raw sensory input into rich feature representations. These features are then proje...
-
[65]
Evaluation Protocol Details 8.1. Overall Reasoning Accuracy (QA-Acc) This metric measures the overall accuracy of the agent’s answers to all cognitive queries in the test set. LetQbe the set of all queries in the test set. For any queryq∈ Q, letA q be the agent’s answer and Gq be the ground-truth answer. LetI(·)be the indicator function. The Overall Reaso...
-
[66]
Is the sofa to the left of the lamp?
Template & Relational Equivalence:The query’s phrasing or logical frame of reference is different, but the semantics and ground-truth answer are identical.(e.g., “Is the sofa to the left of the lamp?” vs. “Is the lamp to the right of the sofa?” GT is “Yes” for both)
-
[67]
Temporal Misalignment:Queries within the same trajectory that are based on temporally shifted clips (e.g., offset by 1-2 steps), but the core fact and GT answer remain unchanged
-
[68]
What color is the vase you see now?
Cross-Query-Type Equivalence:Targeting the same fact us- ing queries of different cognitive types (e.g., introspective, ret- rospective).(e.g., Anintrospectivequery att= 10: “What color is the vase you see now?” (GT: “Red”) vs. aretrospec- tivequery att= 25: “What color was the vase you passed earlier?” (GT: “Red”))
-
[69]
Cross-Trajectory Metadata:Queries from different trajecto- ries that are determined (via metadata like environment/object ID) to be asking about the same fact with the same GT answer. We partition all queries intoMsuch Equivalent Probe Sets S={S 1, S2, ..., SM }. We only consider sets wherek i ≥2. 1.Calculate Total Consistent Pairs (C total):We sum the nu...
-
[70]
for generating all responses to ensure efficiency and determinis- tic outputs. All reported scores are the average of three evaluation runs with different random seeds to ensure statistical stability
-
[71]
Walk into the living room and keep walking straight past the living room
Additional Experimental Results 9.1. Baseline details Specialized Navigation ModelsFor all specialized naviga- tion baselines on VLN-CE, includingNavid,NaviLLM, and NaVILA, we adhered to the following protocol to ensure a fair and reproducible comparison: •Source:We utilized the official codebases and pre-trained model weights released by the respective a...
work page 2024
-
[72]
Feature Visualization To qualitatively validate the structural impact of our ST-CRL ob- jective, we conducted a comprehensive feature space analysis as presented in Figure 4 of the main paper. This visualization com- prises two distinct components: a static manifold structure com- parison (Top and Middle panels) and a dynamic trajectory evolu- tion analys...
-
[73]
Limitations and Future Work While our proposed LASAR framework demonstrates significant advancements in equipping embodied agents with spatio-temporal intelligence, we acknowledge several limitations that pave the way for compelling future research. First, our model’s multi-encoder architecture, while power- ful, introduces a notable computational overhea...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.