AliyunConsoleAgent: Training Web Agents in Real-World Cloud Environments via Distillation and Reinforcement Learning
Pith reviewed 2026-06-27 16:20 UTC · model grok-4.3
The pith
A 32B open model trained by distillation and RL reaches 63.52 percent success on cloud console verification tasks, within 1.82 points of the best proprietary model at 92 percent lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
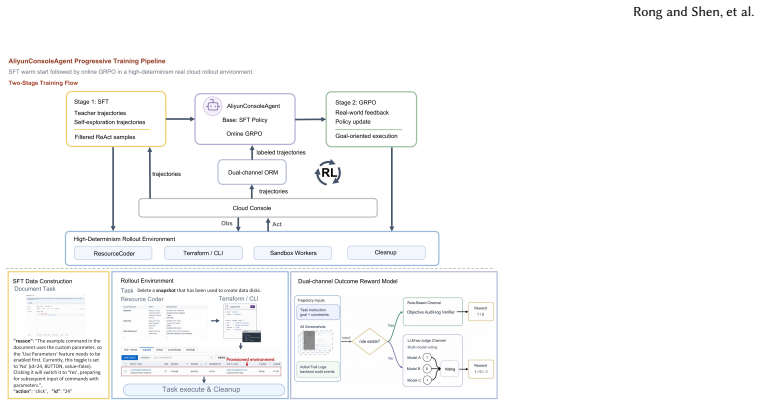
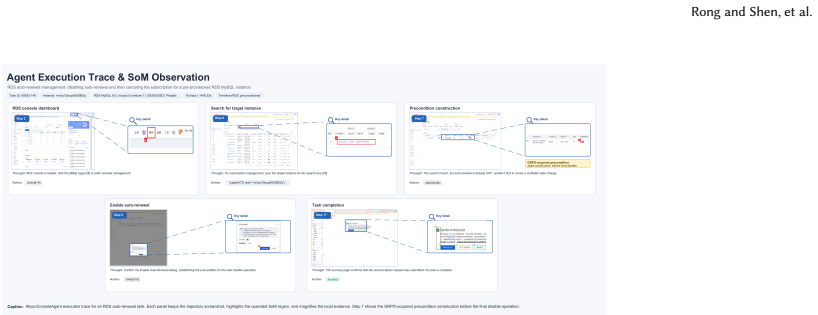
Through a two-stage process of supervised fine-tuning on trajectories distilled from frontier models and subsequent reinforcement learning with Group Relative Policy Optimization using a dual-channel outcome reward model, the AliyunConsoleAgent-32B evolves to handle real cloud console tasks autonomously. Supported by Terraform-based resource provisioning for high-determinism rollouts and rule-based evaluation from backend audit logs, it achieves a 63.52% mean success rate on a 278-task benchmark. This represents a 20.24 percentage point gain over the base model and narrows the gap to the leading frontier model to 1.82 percentage points while cutting inference costs by 92%.
What carries the argument
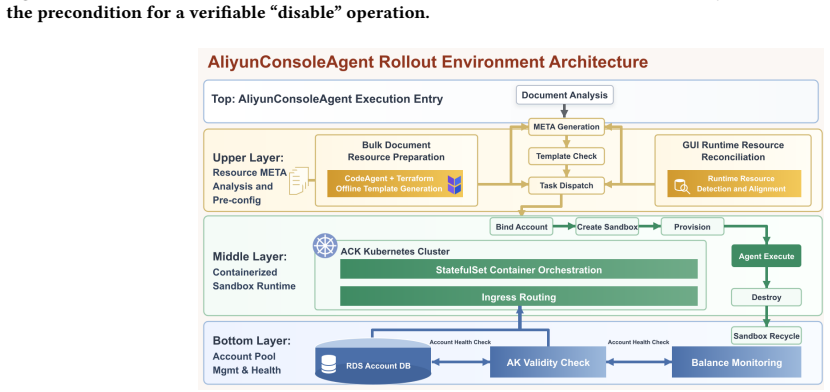
The two-stage distillation followed by GRPO reinforcement learning in real cloud environments with rule-based rewards from audit logs and a high-determinism rollout system using Terraform pre-provisioning.
If this is right
- Automated verification of cloud documentation can scale to the required millions of annual inspections.
- The trained model acquires product-specific understanding beyond mechanical instruction following.
- Real-world RL training becomes feasible without environment noise corrupting the signal.
- Cost and privacy barriers to deploying web agents in enterprise cloud settings are substantially reduced.
Where Pith is reading between the lines
- Similar distillation and RL pipelines could adapt open models for other complex web-based enterprise systems.
- The emphasis on backend audit logs for rewards may generalize to other domains where objective outcome signals are available.
- Further scaling the number of cloud products in training could enhance the model's ability to handle feature iterations autonomously.
Load-bearing premise
The rule-based reward protocol from backend audit logs delivers objective, reward-hacking-resistant signals that stay unbiased across varied cloud products and UI states.
What would settle it
Running the AliyunConsoleAgent-32B independently on the 278-task benchmark and observing whether its success rate remains within the bootstrap 95% confidence interval of being only 1.82 points below the frontier model.
Figures

read the original abstract
We present AliyunConsoleAgent, a web agent framework for automated documentation verification in real-world cloud consoles. Major cloud platforms encompass hundreds of products with rapid feature iteration, causing console UIs to frequently diverge from their corresponding documentation. Verifying that documented procedures accurately reflect the current console and can be executed end-to-end demands an estimated 4 million recurring inspections annually, yet manual coverage remains below 1%. While agent systems built on frontier proprietary models achieve high success rates, their prohibitive cost and data privacy constraints preclude large-scale deployment. We propose a two-stage training paradigm: supervised fine-tuning (SFT) on distilled frontier-model trajectories, followed by reinforcement learning using Group Relative Policy Optimization (GRPO) and a dual-channel outcome reward model in real cloud environments. To support large-scale RL training, we construct a high-determinism rollout system featuring Terraform-based resource pre-provisioning and LLM-driven on-demand provisioning, which effectively isolates environment noise from the training signal. We further introduce a rule-based reward evaluation protocol grounded in backend audit logs, providing objective, reward-hacking-resistant outcome judgment. Our model evolves from mechanical instruction following to autonomous decision-making with cloud console and product-specific understanding. Experiments on a challenging 278-task benchmark where the best frontier model achieves only 65.34% demonstrate that AliyunConsoleAgent-32B achieves a 63.52% mean success rate -- a 20.24 percentage-point improvement over the base model, narrowing the gap to the best frontier proprietary model to 1.82 pp (bootstrap 95% CI [-1.27, 7.39]) -- at 92% lower inference cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AliyunConsoleAgent, a web agent framework for automated documentation verification in real-world cloud consoles. It proposes a two-stage training paradigm consisting of supervised fine-tuning on distilled frontier-model trajectories followed by reinforcement learning with Group Relative Policy Optimization (GRPO) and a dual-channel outcome reward model grounded in backend audit logs. A high-determinism rollout system using Terraform-based provisioning is introduced to support large-scale RL. On a 278-task benchmark where the best frontier model achieves 65.34%, the resulting 32B model reaches 63.52% mean success rate (20.24 pp improvement over base model), narrowing the gap to 1.82 pp (bootstrap 95% CI [-1.27, 7.39]) at 92% lower inference cost.
Significance. If the empirical results hold, the work would show that open 32B-scale models can be trained via distillation and RL to approach proprietary frontier performance on complex, product-specific web agent tasks in live cloud environments while achieving substantial cost reductions. The engineering contribution of the high-determinism rollout system for isolating environment noise is a practical strength for scalable agent training.
major comments (2)
- [Abstract] Abstract (rule-based reward protocol): The protocol is described as objective and reward-hacking-resistant because it uses backend audit logs rather than LLM-as-judge. However, the same protocol supplies the dual-channel outcome reward for GRPO training and the success-rate metric for the 278-task benchmark. No human validation study, inter-rater agreement check, or analysis of log incompleteness/ambiguity across diverse cloud products is reported, which directly affects the reliability of both the training signal and the headline 63.52% result.
- [Experiments] Experiments (implied by abstract results): The abstract supplies concrete success rates, a 20.24 pp improvement, and a bootstrap CI, yet supplies no details on task construction, data splits, ablation studies, or statistical controls for the 278-task benchmark. These omissions make it impossible to assess whether the reported narrowing of the gap to the frontier model is robust.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. The comments highlight important aspects of evaluation reliability and experimental transparency that we address below. We propose targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (rule-based reward protocol): The protocol is described as objective and reward-hacking-resistant because it uses backend audit logs rather than LLM-as-judge. However, the same protocol supplies the dual-channel outcome reward for GRPO training and the success-rate metric for the 278-task benchmark. No human validation study, inter-rater agreement check, or analysis of log incompleteness/ambiguity across diverse cloud products is reported, which directly affects the reliability of both the training signal and the headline 63.52% result.
Authors: We agree that explicit validation of the rule-based protocol would increase confidence in both the RL training signal and the reported results. The audit logs record all API invocations and resource state changes with high fidelity as they originate from the cloud provider's production logging system. Nevertheless, to address potential edge cases such as partial log coverage for certain products, we will add a dedicated subsection in Section 4 (Experiments) that (i) quantifies log completeness across the 278 tasks, (ii) discusses known ambiguities, and (iii) reports a post-hoc human validation study on a random 50-task subset, including inter-rater agreement statistics between the rule-based judgments and two human annotators. These additions will be included in the revised version. revision: yes
-
Referee: [Experiments] Experiments (implied by abstract results): The abstract supplies concrete success rates, a 20.24 pp improvement, and a bootstrap CI, yet supplies no details on task construction, data splits, ablation studies, or statistical controls for the 278-task benchmark. These omissions make it impossible to assess whether the reported narrowing of the gap to the frontier model is robust.
Authors: The full manuscript contains Section 4 (Experiments) that describes benchmark construction (tasks derived from real documentation-verification tickets across 12 cloud products), the 70/30 train/test split used for SFT, and ablation studies isolating the contributions of SFT distillation and GRPO. The bootstrap CI is obtained via 1,000 resamples of the task set with replacement. We acknowledge that the abstract itself is too concise to convey these controls. In revision we will (i) expand the abstract with one additional sentence summarizing benchmark provenance and (ii) add per-product success-rate tables and variance estimates as supplementary statistical controls in Section 4.2. revision: partial
Circularity Check
No significant circularity; empirical benchmark results independent of training signal
full rationale
The paper reports measured success rates on a 278-task benchmark after SFT+GRPO training. The rule-based reward protocol supplies the RL training signal and is also used to compute the reported success rates, but this does not constitute circularity under the enumerated patterns: no equation reduces a derived quantity to a fitted parameter by construction, no self-citation chain justifies a uniqueness claim, and no ansatz or renaming is smuggled in. The headline numbers are direct empirical counts on held-out tasks rather than predictions forced by the training objective itself. The derivation chain (distillation followed by GRPO with dual-channel rewards) remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real cloud console environments can be provisioned with sufficient determinism using Terraform and LLM-driven methods to isolate training signals from noise.
Reference graph
Works this paper leans on
- [1]
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, and Zhiyong Wu. 2024. SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents. InProceedings of ACL
2024
-
[4]
DeepSeek-AI. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. 2023. Mind2Web: Towards a Generalist Agent for the Web. In Advances in Neural Information Processing Systems
2023
-
[6]
Hiroki Furuta, Kuang-Huei Lee, Ofir Nachum, Yutaka Matsuo, Aleksandra Faust, Shixiang Gu, and Izzeddin Gur. 2024. Multimodal Web Navigation with Instruction-Finetuned Foundation Models. InInternational Conference on Learn- ing Representations
2024
-
[7]
HashiCorp. 2024. Terraform: Infrastructure as Code. https://www.terraform.io
2024
-
[8]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. 2024. WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models.Proceedings of ACL(2024)
2024
- [9]
-
[10]
Haojia Lin, Xiaoyu Tan, Yulei Qin, Zihan Xu, Yuchen Shi, Zongyi Li, Gang Li, Shaofei Cai, Siqi Cai, Chaoyou Fu, Ke Li, and Xing Sun. 2025. CUAReward- Bench: A Benchmark for Evaluating Reward Models on Computer-using Agent. arXiv:2510.18596 [cs.SE] https://arxiv.org/abs/2510.18596
- [11]
-
[12]
Xing Han Lu, Zdeněk Kasner, and Siva Reddy. 2024. WebLINX: Real-World Website Navigation with Multi-Turn Dialogue.Proceedings of ICML(2024)
2024
-
[13]
Pranav Putta, Edmund Mills, Naman Garg, Sumeet Motwani, Chelsea Finn, Divyansh Garg, and Rafael Rafailov. 2024. Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents.arXiv preprint arXiv:2408.07199(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Wenyi Zhao, Yu Yang, Xinyue Yang, Jiadai Sun, Shuntian Yao, Tianjie Zhang, Wei Xu, Jie Tang, and Yuxiao Dong. 2025. WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning. arXiv:2411.02337 [cs.CL] https: //arxiv.org/abs/2411.02337
-
[15]
Yujia Qin et al . 2025. UI-TARS: Pioneering Automated GUI Interaction with Native Agents.arXiv preprint arXiv:2501.12326(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. 2023. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. InProceedings of NeurIPS
2023
-
[17]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[18]
Proximal Policy Optimization Algorithms.arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y.K. Li, Yang Wu, et al. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Tianlin Shi, Andrej Karpathy, Linxi Fan, Jonathan Hernandez, and Percy Liang
-
[21]
In Proceedings of ICML
World of Bits: An Open-Domain Platform for Web-Based Agents. In Proceedings of ICML
-
[22]
Qiushi Sun, Kanzhi Cheng, Zichen Ding, Chuanyang Jin, Yian Wang, Fangzhi Xu, Zhenyu Wu, Chengyou Jia, Liheng Chen, Zhoumianze Liu, Ben Kao, Guo- hao Li, Junxian He, Yu Qiao, and Zhiyong Wu. 2024. OS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task Synthesis.arXiv preprint arXiv:2412.19723(2024)
- [23]
-
[24]
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxiang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, et al . 2025. UI- TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning.arXiv preprint arXiv:2509.02544(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. 2024. OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments.Advances in Neural Information Processing Systems37 (2024), 52040–52094
2024
- [26]
- [27]
- [28]
-
[29]
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao
-
[30]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V.arXiv preprint arXiv:2310.11441(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InProceedings of ICLR
2023
-
[32]
Qiying Yu et al. 2025. DAPO: An Open-Source LLM Reinforcement Learning System at Scale.arXiv preprint arXiv:2503.14476(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena. InProceedings of NeurIPS
2023
- [34]
-
[35]
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. 2024. WebArena: A Realistic Web Environment for Building Autonomous Agents. InProceedings of ICLR. GenAI Usage Disclosure In accordance with the ACM Policy on the use of Generative AI, we disclose that generative AI tools ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.