Sandboxed Coding Agents are Competitive Omni-modal Task Solvers
Pith reviewed 2026-06-28 18:58 UTC · model grok-4.3
The pith
Coding agents limited to text and images match or beat native omnimodal models on audio-video benchmarks by using code to extract evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
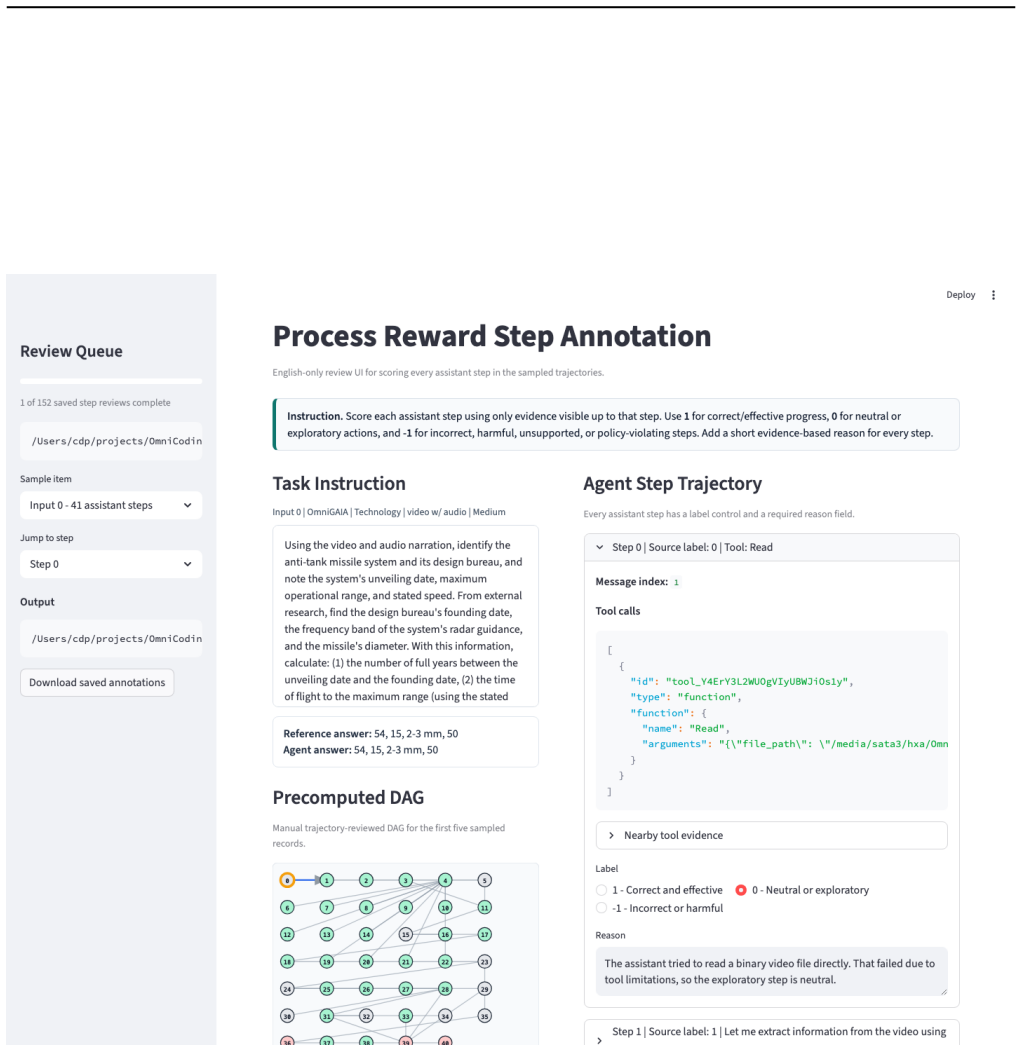
Coding agents equipped only with text and image access plus a sandboxed tool-use interface match and in several settings outperform SOTA native omnimodal models and predefined multimodal agent scaffolds on multiple audio-video benchmarks; their strength lies in writing code that extracts relevant evidence from transcripts, frames, and other signals, thereby converting the tasks into retrieval and information-processing problems.
What carries the argument
The sandboxed tool-use interface that lets agents write and execute code to orchestrate evidence extraction from modality signals.
If this is right
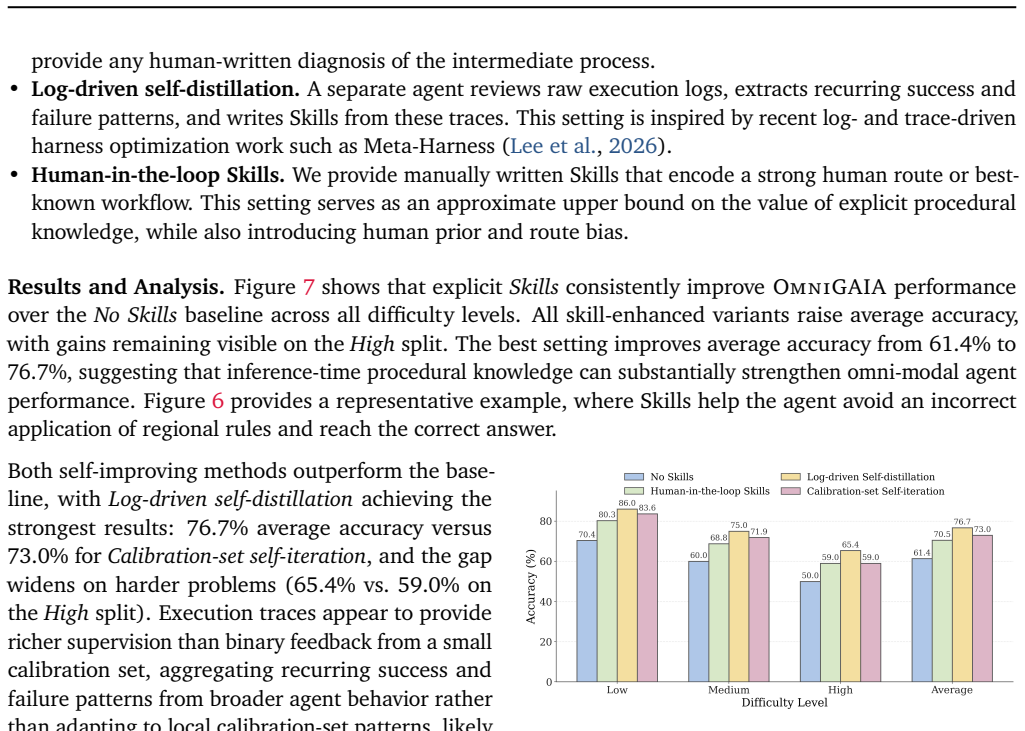
- Simple injection of human-written or self-distilled skills substantially raises agent performance on these tasks.
- The Code-X training recipe using the OmniCoding trajectory dataset and verifiable reward produces usable baselines on 9B and 27B open-source models.
- Process-level trace analysis and a failure taxonomy reveal concrete limits of the current approach.
- TerminalBench-O provides a process-level benchmark for evaluating real-world many-modality processing tasks.
Where Pith is reading between the lines
- If the reduction to retrieval holds, then many existing code-execution environments could be repurposed for multimodal work without new model architectures.
- The failure taxonomy suggests targeted improvements in code generation for complex temporal reasoning would extend the approach.
- TerminalBench-O could serve as a template for process-level evaluation in other agent domains beyond audio and video.
Load-bearing premise
Performance gains come primarily from code-based evidence extraction rather than from benchmark-specific artifacts or the particular choice of underlying LLM and sandbox environment.
What would settle it
A controlled experiment in which the same agents lose the ability to write and run extraction code yet still match or exceed the native omnimodal models on the same benchmarks.
Figures
























read the original abstract
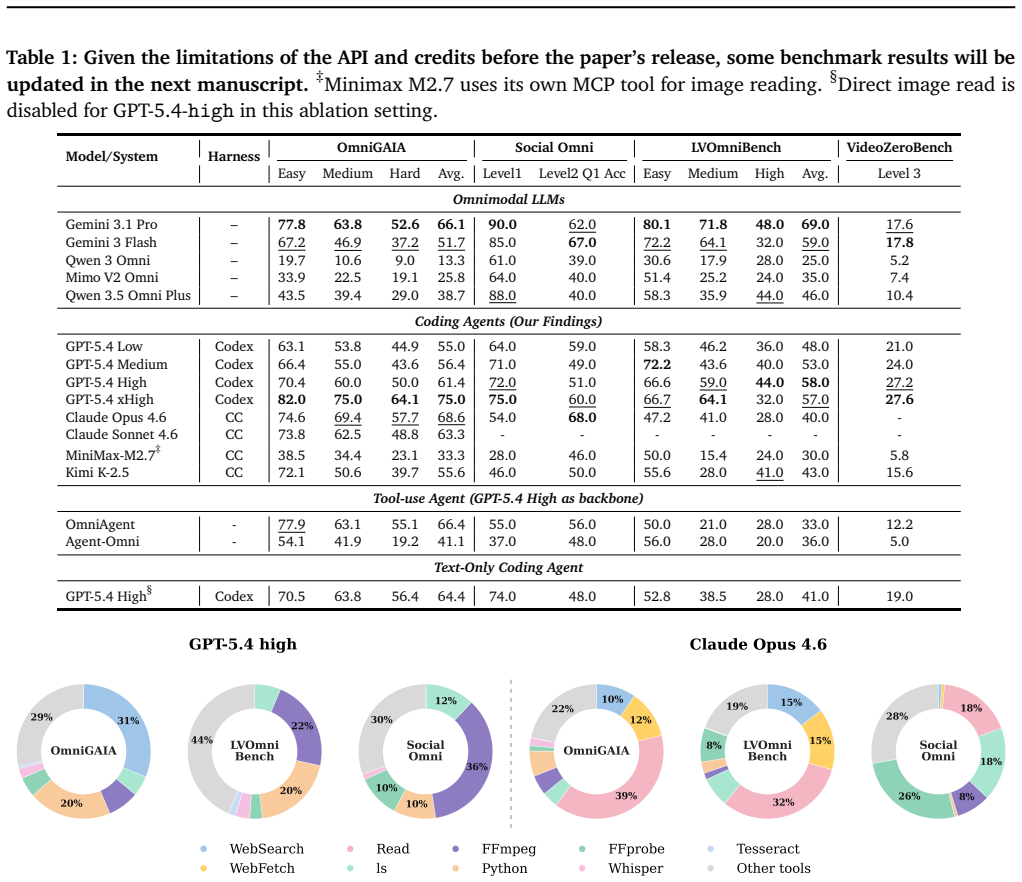
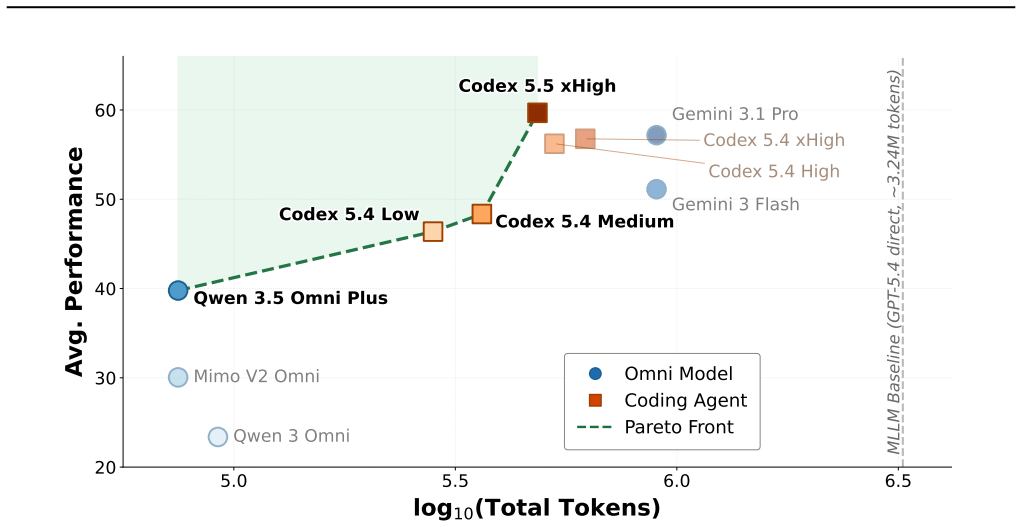
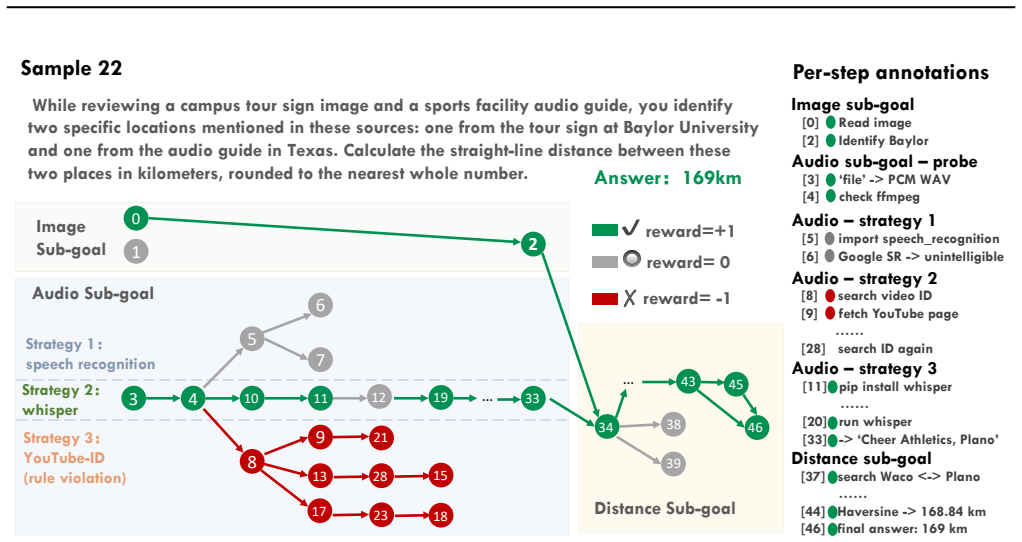
As multimodal LLMs increasingly target video and audio, it is often assumed that such tasks require native omnimodal models. We show that this is not always the case: coding agents with only text+image access and a sandboxed tool-use interface can match, and in several settings outperform, SOTA native omnimodal models and predefined multimodal agent scaffolds across multiple audio-video benchmarks. Our trajectory analysis suggests that their strength comes from writing code and orchestrating tools to extract relevant evidence from transcripts, frames, and other modality signals, thereby converting omnimodal tasks into retrieval and information-processing problems rather than ingesting entire media streams. We further characterize their limitations through a failure taxonomy and process-level trace analysis, and show that simple skill injection, including human-written and self-distilled skills, substantially improves performance. To explore open-source elicitation, we introduce Code-X, a training recipe with the OmniCoding trajectory dataset and verifiable reward, and provide baselines on Qwen-3.5-9B and Qwen-3.6-27B. Finally, we argue that the next frontier is many-modality processing, and introduce TerminalBench-O, a process-level benchmark for real-world omnimodal processing tasks. Code will be available at https://github.com/Dongping-Chen/OmniCoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that sandboxed coding agents limited to text+image inputs and tool-use interfaces can match or outperform SOTA native omnimodal models and multimodal agent scaffolds on audio-video benchmarks. It attributes this to code-based extraction of evidence from transcripts/frames rather than native multimodal fusion, supports the claim via trajectory analysis and failure taxonomy, shows gains from skill injection, introduces the Code-X training recipe with OmniCoding trajectories and verifiable rewards (with baselines on Qwen-3.5-9B and Qwen-3.6-27B), and proposes TerminalBench-O as a process-level benchmark for many-modality tasks.
Significance. If the central empirical claim holds after isolating the agent interface from base-model scale and benchmark artifacts, the result would be significant: it would demonstrate that many omnimodal tasks can be reduced to retrieval/processing problems solvable by code orchestration, reducing reliance on native multimodal architectures and opening a path for open-source elicitation via verifiable rewards. The introduction of TerminalBench-O and the Code-X recipe are concrete contributions that could be reused.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the central claim that gains arise 'primarily from writing code and orchestrating tools' rather than from the choice of underlying LLM or sandbox affordances is not isolated. No ablation is described that holds the base model fixed while varying only the agent interface (coding agent vs. native omnimodal), nor are results reported on tasks where tool access cannot substitute for native fusion; without these controls the attribution remains correlational.
- [§4.2] §4.2 (Trajectory Analysis): the process-level traces are used to argue for the code-extraction mechanism, but the section does not report quantitative metrics (e.g., fraction of successful trajectories that rely on code vs. direct LLM reasoning) or a controlled comparison against a non-coding agent using the same LLM and sandbox; this leaves the mechanistic explanation under-supported relative to the strength of the headline claim.
- [§5] §5 (Code-X and open-source elicitation): the reported baselines on Qwen-3.5-9B and Qwen-3.6-27B use the new OmniCoding dataset and verifiable reward, yet no comparison is provided against the same models fine-tuned with standard SFT or RL on the original benchmark data; this makes it difficult to attribute any improvement specifically to the coding-agent formulation versus dataset or reward design.
minor comments (2)
- [Abstract] The abstract introduces 'Code-X' and 'TerminalBench-O' without a one-sentence definition or pointer to the section where they are formally defined; add these on first use.
- [Figures in §4] Figure captions for the failure taxonomy and trajectory visualizations should explicitly state the number of trajectories or examples analyzed and the inter-annotator agreement if human labeling was involved.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that help clarify the strength of our empirical claims. We address each major point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim that gains arise 'primarily from writing code and orchestrating tools' rather than from the choice of underlying LLM or sandbox affordances is not isolated. No ablation is described that holds the base model fixed while varying only the agent interface (coding agent vs. native omnimodal), nor are results reported on tasks where tool access cannot substitute for native fusion; without these controls the attribution remains correlational.
Authors: We agree that a controlled ablation holding the base model fixed would strengthen attribution to the coding-agent interface. Our current results compare against published SOTA native omnimodal models that use different base models and training. The manuscript does not contain such an ablation. We will revise the abstract and §4 to explicitly acknowledge this limitation and clarify that the claim is supported by trajectory evidence of code usage rather than a fully isolated causal demonstration. A full ablation is not feasible without new experiments matching exact base models across interfaces. revision: partial
-
Referee: [§4.2] §4.2 (Trajectory Analysis): the process-level traces are used to argue for the code-extraction mechanism, but the section does not report quantitative metrics (e.g., fraction of successful trajectories that rely on code vs. direct LLM reasoning) or a controlled comparison against a non-coding agent using the same LLM and sandbox; this leaves the mechanistic explanation under-supported relative to the strength of the headline claim.
Authors: We acknowledge that quantitative metrics would better support the mechanistic argument. §4.2 currently presents qualitative trajectories and a failure taxonomy. We will revise the section to include quantitative statistics computed from the existing trajectory data, such as the fraction of successful trajectories that rely on code-based extraction versus direct reasoning. A controlled comparison to a non-coding agent would require additional runs, but the added metrics will provide stronger quantitative grounding for the code-extraction claim. revision: yes
-
Referee: [§5] §5 (Code-X and open-source elicitation): the reported baselines on Qwen-3.5-9B and Qwen-3.6-27B use the new OmniCoding dataset and verifiable reward, yet no comparison is provided against the same models fine-tuned with standard SFT or RL on the original benchmark data; this makes it difficult to attribute any improvement specifically to the coding-agent formulation versus dataset or reward design.
Authors: We agree that comparisons against standard SFT and RL on the original benchmark data are needed to isolate the contribution of the coding-agent formulation. We will add these baselines for both Qwen models in the revised §5, training with standard SFT/RL on the original benchmark data under the same compute budget. This will allow direct attribution of gains to the OmniCoding trajectories and verifiable rewards. revision: yes
Circularity Check
No circularity: empirical claims rest on benchmark comparisons without derivations or self-referential reductions
full rationale
The paper presents an empirical argument that sandboxed coding agents with text+image access can match or exceed native omnimodal models on audio-video tasks by converting them into code-orchestrated retrieval problems. The abstract and provided text contain no equations, fitted parameters, predictions derived from prior fits, or load-bearing self-citations. Claims are supported by experimental results, trajectory analysis, failure taxonomy, and new benchmarks (Code-X, TerminalBench-O) rather than any derivation that reduces to its own inputs by construction. No self-definitional, fitted-input, or uniqueness-imported patterns appear. The central attribution to code-based evidence extraction is an interpretation of results, not a mathematical reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Omnimodal tasks can be reframed as retrieval and information-processing problems solvable by code orchestration without native multimodal ingestion
invented entities (2)
-
Code-X
no independent evidence
-
TerminalBench-O
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2603.14145. Kaixiong Gong, Kaituo Feng, Bohao Li, Yibing Wang, Mofan Cheng, Shijia Yang, Jiaming Han, Benyou Wang, Yutong Bai, Zhuoran Yang, and Xiangyu Yue. Av-odyssey bench: Can your multimodal llms really understand audio-visual information?arXiv preprint arXiv:2412.02611, 2024. URLhttps://arxiv.org/abs/2412.02611. Jack Hong, S...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
URLhttps://arxiv.org/abs/2406.09403. Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kilian Lieret, Karthik Narasimhan, and Ofir Press. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023. URL https://arxiv.org/abs/2310.06770. Geewook Kim and Minjoon Seo. Do modern video-llms need to listen? a ...
-
[3]
Gorilla: Large Language Model Connected with Massive APIs
Accessed: 2026-04-01. Nous Research. Hermes agent: The agent that grows with you. https://github.com/nousresearch/ hermes-agent, 2026. Accessed: 2026-04-27. OpenAI. Introducing swe-bench verified. OpenAI blog, 2024. URL https://openai.com/index/ introducing-swe-bench-verified/. Updated February 24, 2025. OpenAI. Introducing GPT-5.4.https://openai.com/inde...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
URLhttps://arxiv.org/abs/2307.16789. Qwen Team. Qwen3.5-Omni: Scaling up, toward native omni-modal AGI.https://qwen.ai/blog?id=qwen3. 5-omni, 2026. Accessed: 2026-04-01. Ahmed Y. Radwan, Christos Emmanouilidis, Hina Tabassum, Deval Pandya, and Shaina Raza. Sonic-o1: A real- world benchmark for evaluating multimodal large language models on audio-video und...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Toolformer: Language Models Can Teach Themselves to Use Tools
URLhttps://arxiv.org/abs/2302.04761. Guangzhi Sun, Wenyi Yu, Changli Tang, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Yuxuan Wang, and Chao Zhang. video-salmonn: Speech-enhanced audio-visual large language models.arXiv preprint arXiv:2406.15704,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URLhttps://arxiv.org/abs/2406.15704. SWE-agent Team. mini-swe-agent: The minimal ai software engineering agent.https://github.com/SWE-agent/ mini-swe-agent, 2025. Accessed: 2026-05-02. Keda Tao, Wenjie Du, Bohan Yu, Weiqiang Wang, Jian Liu, and Huan Wang. Active perception agent for omnimodal audio-video understanding.arXiv preprint arXiv:2512.23646, 2025...
-
[7]
URLhttps://arxiv.org/abs/2503.20215. Qiantong Xu, Fenglu Hong, Bo Li, Changran Hu, Zhengyu Chen, and Jian Zhang. On the tool manipulation capability of open-source large language models.arXiv preprint arXiv:2305.16504, 2023. URLhttps://arxiv.org/abs/ 2305.16504. 22 Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Required
target more realistic settings that require integrating visual, auditory, and textual evidence over longer horizons. At the same time, recent audits show that several audio-video benchmarks admit strong visual shortcuts (Kim and Seo, 2025), suggesting that progress in omni-modal evaluation depends not only on stronger models but also on shortcut-resistant...
2025
-
[9]
Update the previous guide into a better next-round guide
-
[10]
Use only generic, reusable tactics suggested by the sanitized summary
-
[11]
Do not include benchmark-specific facts, named entities, dates, exact answers, or any clues tied to individual cases
-
[12]
Do not quote or paraphrase specific questions
-
[13]
question_id
Keep the guide concise, operational, and directly useful during future runs. What to extract from the summary: - recurring failure patterns - search-breadth problems - weak verification habits - answer-format mistakes - underused or misused tools - signals about when a workflow should escalate from local inspection to search, OCR, ASR, calculation, or mul...
2048
-
[14]
workspace and leakage rules,
-
[15]
tool-use heuristics,
-
[16]
media-processing workflows,
-
[17]
verification checkpoints,
-
[18]
answer-format discipline,
-
[19]
common recovery rules. - Explain not only which tools to use, but in what order and with what verification checks. - Convert stronger reference pipelines into reusable playbooks rather than case-specific tips. Hard prohibitions: - Do not include benchmark-specific examples. - Do not quote or paraphrase individual questions. - Do not include named entities...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.