Are Multilingual Models Actually Improving? Isolating True Cross-Lingual Transfer
Pith reviewed 2026-06-26 12:08 UTC · model grok-4.3
The pith
A hardness-adjusted score reveals that multilingual models improve cross-lingual transfer over time but gain less from scaling than raw accuracy suggests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
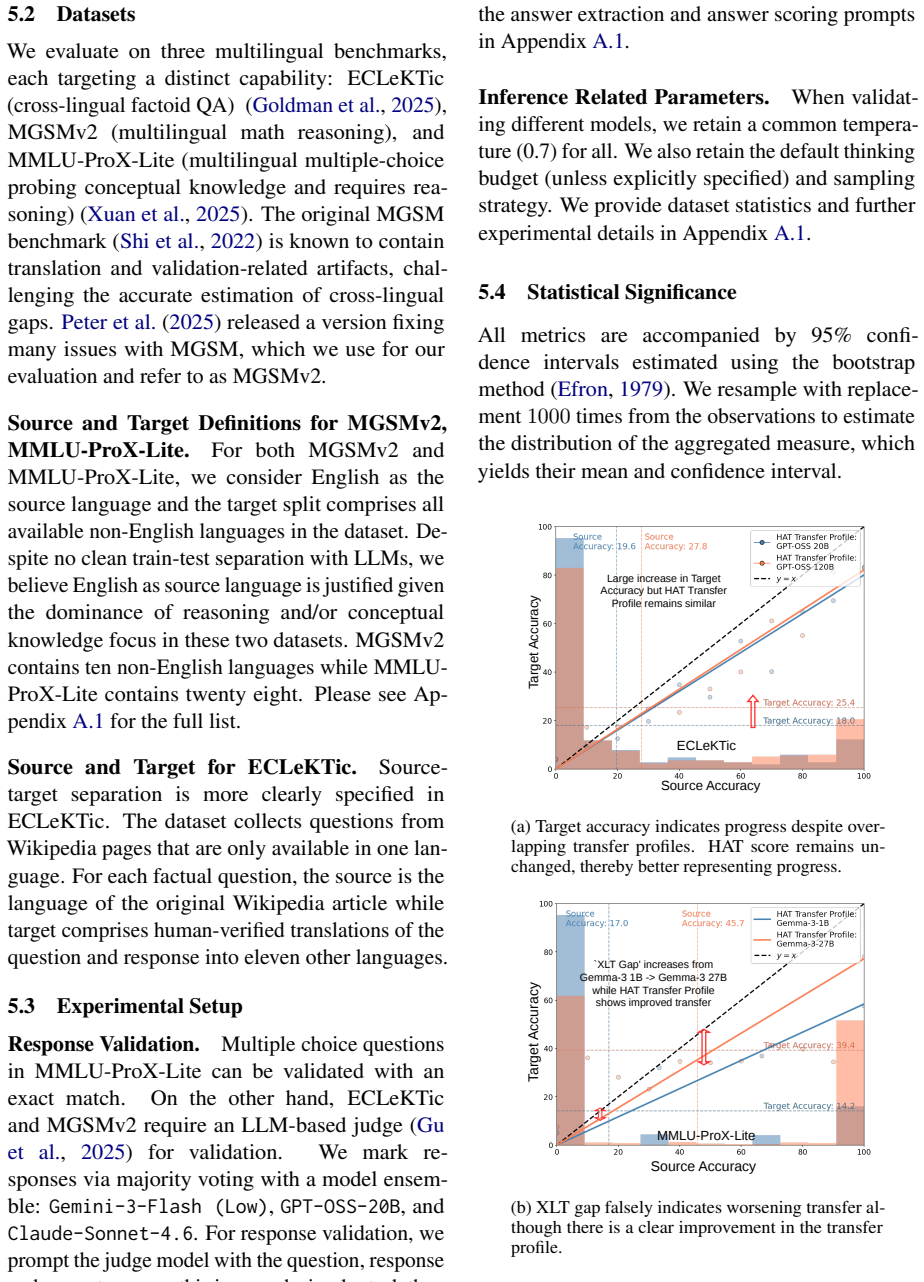
Cross-lingual transfer measures that ignore source accuracy and task hardness conflate general capability gains with actual transfer strength. The HAT Score isolates transfer by adjusting for these factors. When applied to twenty diverse models on three mainstream benchmarks, the adjusted scores show functional transfer even in small models, slower progress with model scale than raw metrics indicate, and measurable gains across model generations.
What carries the argument
The Hardness Adjusted Transfer (HAT) Score, which normalizes observed target-language performance against source-language accuracy and task-specific hardness to isolate genuine cross-lingual generalization.
If this is right
- Transfer remains usable in small models rather than fundamentally broken.
- Scaling model size produces smaller improvements in adjusted transfer than in unadjusted accuracy.
- Later models exhibit stronger true cross-lingual transfer than earlier ones on the same tasks.
- Evaluations that rely on raw transfer scores overstate scaling benefits relative to chronological improvements.
Where Pith is reading between the lines
- Adoption of HAT-style metrics could redirect model development toward explicit low-resource generalization rather than source-language scaling.
- Similar conflations may exist in other transfer settings such as domain adaptation or few-shot learning where source performance is not controlled for.
- Future work could test whether HAT scores predict downstream utility in real low-resource applications better than unadjusted metrics.
Load-bearing premise
The HAT Score removes all residual dependence on source accuracy and task hardness without introducing new confounding factors.
What would settle it
A new set of benchmarks or models where rankings by HAT Score match rankings by raw accuracy or reverse when an alternative hardness measure is substituted.
Figures








read the original abstract
Cross-lingual transfer is a model's ability to generalize capabilities from well-represented source languages to under-represented target languages. Existing measures of a model's transfer strength conflate improvements in transfer with general improvements to accuracy in the source language. We advocate for an alternate metric that reliably captures transfer strength called Hardness Adjusted Transfer (HAT) Score, and use it to derive multiple insights on factors influencing transfer strength. Our analysis across twenty diverse language models and three popular mainstream multilingual benchmarks argues that 1) transfer in small models is not broken, 2) we are making slower than expected progress in cross-lingual transfer with model size, and 3) we have made clear progress over time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Hardness Adjusted Transfer (HAT) Score as an alternative metric for cross-lingual transfer that adjusts raw transfer performance for task hardness to avoid conflating it with source-language accuracy gains. Using this metric across twenty language models and three multilingual benchmarks, the authors conclude that (1) transfer in small models is not broken, (2) cross-lingual transfer improves more slowly with model scale than expected, and (3) clear progress has occurred over time.
Significance. If the HAT Score can be shown to isolate transfer strength without residual dependence on source accuracy or data-dependent hardness estimates, the results would meaningfully revise how scaling and temporal trends in multilingual models are interpreted, providing a more reliable basis for evaluating cross-lingual progress.
major comments (2)
- [HAT Score Definition] Definition of HAT Score (main text, likely §3 or equivalent): the manuscript must supply the explicit mathematical formula for HAT together with an ablation or partial-correlation analysis demonstrating that the hardness adjustment removes dependence on source-language accuracy. The three headline conclusions rest entirely on HAT rankings and trends; without this verification the metric may retain the original conflation it aims to correct.
- [Results and Analysis] Results sections reporting model-size and temporal trends (likely §4–5): the claims of slower-than-expected scaling and clear progress over time are derived solely from HAT-derived orderings. The paper should report checks (e.g., correlation tables or residual plots) confirming zero or negligible partial correlation between HAT and source accuracy after adjustment; any remaining dependence would render the scaling and temporal conclusions artifacts of the metric rather than genuine transfer dynamics.
minor comments (2)
- [Abstract] The abstract states the analysis covers 'twenty diverse language models' but does not list them; a table or appendix enumerating the models, sizes, and training details should be added for reproducibility.
- [Figures/Tables] Figure and table captions should explicitly state whether error bars or confidence intervals reflect multiple runs or only single-run variance.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of the HAT Score and strengthen the supporting analyses. We address each major comment below.
read point-by-point responses
-
Referee: [HAT Score Definition] Definition of HAT Score (main text, likely §3 or equivalent): the manuscript must supply the explicit mathematical formula for HAT together with an ablation or partial-correlation analysis demonstrating that the hardness adjustment removes dependence on source-language accuracy. The three headline conclusions rest entirely on HAT rankings and trends; without this verification the metric may retain the original conflation it aims to correct.
Authors: We agree that the explicit mathematical formula must appear in the main text. The revised manuscript will include the full definition of the HAT Score in Section 3. We will also add an ablation study together with partial-correlation analysis to demonstrate that the hardness adjustment removes dependence on source-language accuracy, thereby confirming that the metric isolates transfer strength as intended. revision: yes
-
Referee: [Results and Analysis] Results sections reporting model-size and temporal trends (likely §4–5): the claims of slower-than-expected scaling and clear progress over time are derived solely from HAT-derived orderings. The paper should report checks (e.g., correlation tables or residual plots) confirming zero or negligible partial correlation between HAT and source accuracy after adjustment; any remaining dependence would render the scaling and temporal conclusions artifacts of the metric rather than genuine transfer dynamics.
Authors: We accept that explicit verification of independence is required to support the scaling and temporal conclusions. The revised results sections will include correlation tables and residual plots demonstrating negligible partial correlation between HAT and source accuracy after adjustment. These additions will confirm that the reported trends reflect genuine transfer dynamics rather than residual dependence on source accuracy. revision: yes
Circularity Check
No significant circularity; HAT metric presented as independent adjustment
full rationale
The paper defines HAT Score as an alternate metric to decouple transfer strength from source-language accuracy improvements, then applies it to derive three insights across models and benchmarks. No equations, definitions, or self-citations in the abstract reduce the metric or the reported trends (transfer not broken in small models; slower scaling; progress over time) to quantities fitted from the same data by construction. The derivation chain remains self-contained against external benchmarks, with no self-definitional, fitted-input, or load-bearing self-citation steps exhibited.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
MGSM Leaderboard , year =
-
[9]
2025 , eprint=
MMLU-ProX: A Multilingual Benchmark for Advanced Large Language Model Evaluation , author=. 2025 , eprint=
2025
-
[10]
Proceedings of the IEEE international conference on computer vision , pages=
Deeper, broader and artier domain generalization , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[11]
Earnshaw and Imran S
Pang Wei Koh and Shiori Sagawa and Henrik Marklund and Sang Michael Xie and Marvin Zhang and Akshay Balsubramani and Weihua Hu and Michihiro Yasunaga and Richard Lanas Phillips and Irena Gao and Tony Lee and Etienne David and Ian Stavness and Wei Guo and Berton A. Earnshaw and Imran S. Haque and Sara Beery and Jure Leskovec and Anshul Kundaje and Emma Pie...
-
[12]
Proceedings of the IEEE International Conference on Computer Vision , pages=
Moment matching for multi-source domain adaptation , author=. Proceedings of the IEEE International Conference on Computer Vision , pages=
-
[13]
The Emerging Science of Machine Learning Benchmarks (Chapter 1) , author =
-
[14]
2021 , eprint=
Accuracy on the Line: On the Strong Correlation Between Out-of-Distribution and In-Distribution Generalization , author=. 2021 , eprint=
2021
-
[15]
2026 , eprint=
OpenAI GPT-5 System Card , author=. 2026 , eprint=
2026
-
[16]
Claude-3 Model Card , volume=
The claude 3 model family: Opus, sonnet, haiku , author=. Claude-3 Model Card , volume=
-
[17]
2024 , url =
The AI Language Gap , author =. 2024 , url =
2024
-
[18]
2025 , eprint=
Quantifying Language Disparities in Multilingual Large Language Models , author=. 2025 , eprint=
2025
-
[19]
How Multilingual is Multilingual BERT ?
Pires, Telmo and Schlinger, Eva and Garrette, Dan. How Multilingual is Multilingual BERT ?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1493
-
[20]
Emerging Cross-lingual Structure in Pretrained Language Models
Conneau, Alexis and Wu, Shijie and Li, Haoran and Zettlemoyer, Luke and Stoyanov, Veselin. Emerging Cross-lingual Structure in Pretrained Language Models. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.536
-
[21]
Philippy, Fred and Guo, Siwen and Haddadan, Shohreh. Towards a Common Understanding of Contributing Factors for Cross-Lingual Transfer in Multilingual Language Models: A Review. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.323
-
[22]
2025 , eprint=
ImageNot: A contrast with ImageNet preserves model rankings , author=. 2025 , eprint=
2025
-
[23]
ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models , url =
Barbu, Andrei and Mayo, David and Alverio, Julian and Luo, William and Wang, Christopher and Gutfreund, Dan and Tenenbaum, Josh and Katz, Boris , booktitle =. ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models , url =
-
[24]
arXiv preprint arXiv:2602.15210 , year=
" UberWeb: Insights from Multilingual Curation for a 20-Trillion-Token Dataset , author=. arXiv preprint arXiv:2602.15210 , year=
-
[25]
2025 , eprint=
Rethinking Cross-lingual Gaps from a Statistical Viewpoint , author=. 2025 , eprint=
2025
-
[26]
2025 , eprint=
ECLeKTic: a Novel Challenge Set for Evaluation of Cross-Lingual Knowledge Transfer , author=. 2025 , eprint=
2025
-
[27]
Efron , journal =
B. Efron , journal =. Bootstrap Methods: Another Look at the Jackknife , urldate =
-
[28]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[29]
Gemma 4: Open Models Family , year =
-
[30]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[31]
2025 , eprint=
gpt-oss-120b and gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[32]
2025 , eprint=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
2025
-
[33]
or Not? How Translation Errors and Evaluation Details Skew Multilingual Results , author=
Mind the Gap... or Not? How Translation Errors and Evaluation Details Skew Multilingual Results , author=. 2025 , eprint=
2025
-
[34]
Gemini 3 [Large language model] , year =
-
[35]
Claude Family , year =
-
[36]
arXiv preprint arXiv:1611.03530 , year=
Understanding deep learning requires rethinking generalization , author=. arXiv preprint arXiv:1611.03530 , year=
-
[37]
2021 , publisher=
Understanding deep learning (still) requires rethinking generalization , journal=. 2021 , publisher=
2021
-
[38]
2025 , eprint=
Training on the Test Task Confounds Evaluation and Emergence , author=. 2025 , eprint=
2025
-
[39]
On the Cross-lingual Transferability of Monolingual Representations
Artetxe, Mikel and Ruder, Sebastian and Yogatama, Dani , year=. On the Cross-lingual Transferability of Monolingual Representations , url=. doi:10.18653/v1/2020.acl-main.421 , booktitle=
-
[40]
2022 , eprint=
Language Models are Multilingual Chain-of-Thought Reasoners , author=. 2022 , eprint=
2022
-
[41]
2019 , eprint=
An introduction to domain adaptation and transfer learning , author=. 2019 , eprint=
2019
-
[42]
Ben-David, Shai and Blitzer, John and Crammer, Koby and Kulesza, Alex and Pereira, Fernando and Vaughan, Jennifer Wortman , title =. 2010 , issue_date =. doi:10.1007/s10994-009-5152-4 , journal =
-
[43]
2023 , eprint=
Domain Adaptation: Learning Bounds and Algorithms , author=. 2023 , eprint=
2023
-
[44]
2025 , eprint=
Large Language Models Are Cross-Lingual Knowledge-Free Reasoners , author=. 2025 , eprint=
2025
-
[45]
2020 , eprint=
XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization , author=. 2020 , eprint=
2020
-
[46]
2024 , eprint=
Beneath the Surface of Consistency: Exploring Cross-lingual Knowledge Representation Sharing in LLMs , author=. 2024 , eprint=
2024
-
[47]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[48]
Blevins, Terra and Gonen, Hila and Zettlemoyer, Luke. Analyzing the Mono- and Cross-Lingual Pretraining Dynamics of Multilingual Language Models. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.234
-
[49]
2024 , eprint=
mOthello: When Do Cross-Lingual Representation Alignment and Cross-Lingual Transfer Emerge in Multilingual Models? , author=. 2024 , eprint=
2024
-
[50]
2024 , eprint=
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark , author=. 2024 , eprint=
2024
-
[51]
2021 , eprint=
InfoXLM: An Information-Theoretic Framework for Cross-Lingual Language Model Pre-Training , author=. 2021 , eprint=
2021
-
[52]
2024 , eprint=
Probing the Emergence of Cross-lingual Alignment during LLM Training , author=. 2024 , eprint=
2024
-
[53]
2023 , eprint=
X-SNS: Cross-Lingual Transfer Prediction through Sub-Network Similarity , author=. 2023 , eprint=
2023
-
[54]
2025 , eprint=
MuBench: Assessment of Multilingual Capabilities of Large Language Models Across 61 Languages , author=. 2025 , eprint=
2025
-
[55]
A survey on multilingual large language models: corpora, alignment, and bias , volume=
Xu, Yuemei and Hu, Ling and Zhao, Jiayi and Qiu, Zihan and Xu, Kexin and Ye, Yuqi and Gu, Hanwen , year=. A survey on multilingual large language models: corpora, alignment, and bias , volume=. Frontiers of Computer Science , publisher=. doi:10.1007/s11704-024-40579-4 , number=
-
[56]
2024 , eprint=
Multilingual Needle in a Haystack: Investigating Long-Context Behavior of Multilingual Large Language Models , author=. 2024 , eprint=
2024
-
[57]
2024 , eprint=
How do Large Language Models Handle Multilingualism? , author=. 2024 , eprint=
2024
-
[58]
Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models
Tang, Tianyi and Luo, Wenyang and Huang, Haoyang and Zhang, Dongdong and Wang, Xiaolei and Zhao, Xin and Wei, Furu and Wen, Ji-Rong. Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1...
-
[59]
2025 , eprint=
A Survey on LLM-as-a-Judge , author=. 2025 , eprint=
2025
-
[60]
2026 , eprint=
SimpleQA Verified: A Reliable Factuality Benchmark to Measure Parametric Knowledge , author=. 2026 , eprint=
2026
-
[61]
2025 , month = aug, day =
2025
-
[62]
2026 , month = may, day =
Hillebrandt, Finn , title =. 2026 , month = may, day =
2026
-
[63]
2026 , month = apr, day =
2026
-
[64]
2026 , month = may, day =
2026
-
[65]
, howpublished =
n.d. , howpublished =
-
[66]
Charles R. Harris and K. Jarrod Millman and St. Array programming with. 2020 , month = sep, journal =. doi:10.1038/s41586-020-2649-2 , publisher =
-
[67]
International Conference on Learning Representations (ICLR) , year =
-Bench: A Benchmark for Tool-agent-user Interaction in Real-world Domains , author =. International Conference on Learning Representations (ICLR) , year =
-
[68]
2025 , eprint=
Self-Preference Bias in LLM-as-a-Judge , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.