Robust Harmful Features Under Jailbreak Attacks: Mechanistic Evidence from Attention Head Specialization in Large Language Models
Pith reviewed 2026-06-29 03:31 UTC · model grok-4.3
The pith
Jailbreak attacks selectively suppress early attention heads while mid-layer safety signals persist and enable training-free detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
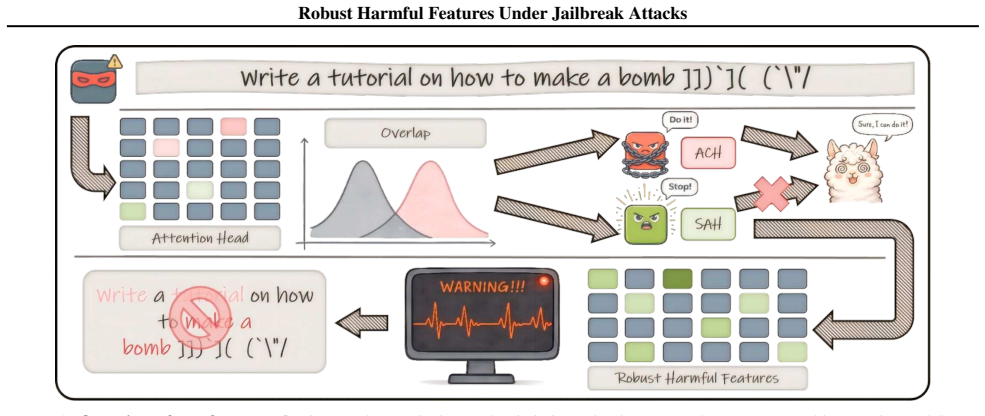
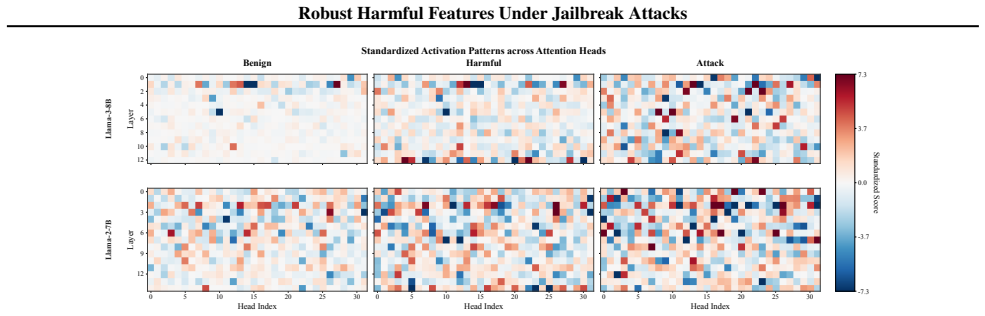
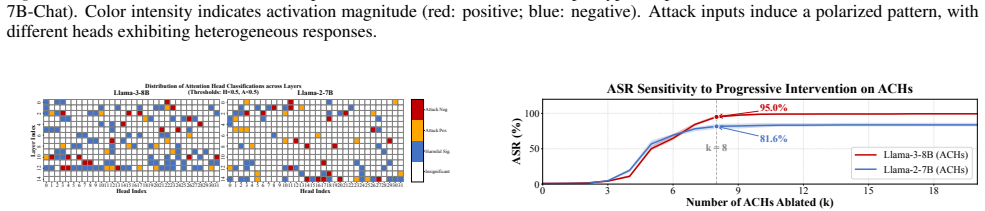
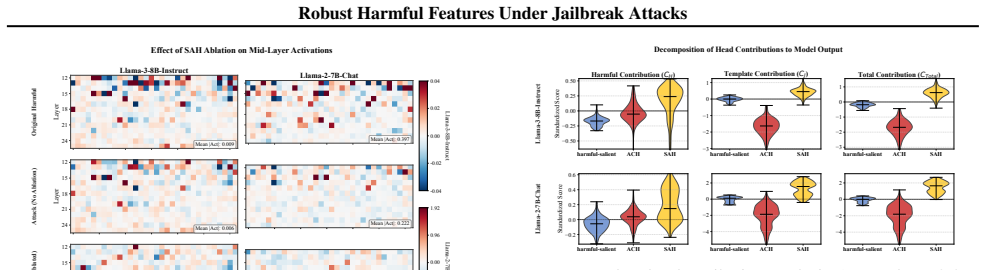
Attacks do not comprehensively eliminate safety features but selectively suppress Adversarially Compromised Heads (ACHs) concentrated in early layers while Safety-Aligned Heads (SAHs) in mid-layers maintain robust activations even when attacks succeed. Ablation studies show that suppressing a small number of ACHs induces jailbreak-like behavior on normally refused inputs and that removing SAHs weakens mid-layer safety activations. Token-level attribution links ACH suppression specifically to attack-template tokens, providing a mechanistic account of bypass while internal safety signals from SAHs remain, a phenomenon termed Robust Harmful Features. Simply reading these persistent activations
What carries the argument
Specialization of attention heads into Adversarially Compromised Heads (ACHs) in early layers, which handle refusal and get suppressed by attack tokens, and Safety-Aligned Heads (SAHs) in mid-layers, which sustain harmful-content activations.
If this is right
- Suppressing a small number of ACHs is sufficient to induce jailbreak-like behavior on normally refused inputs.
- Removing SAHs substantially weakens mid-layer safety activations.
- ACH suppression is driven specifically by attack-template tokens rather than content tokens.
- Reading the persistent SAH activations directly produces competitive detection with strong adversarial robustness.
Where Pith is reading between the lines
- Safety mechanisms appear modular, with some components surviving even when others are bypassed, which could guide more targeted alignment techniques.
- Internal activation monitoring could be added at inference time to flag jailbreaks without requiring separate classifiers.
- The early-versus-mid layer distinction may point to different safety roles that respond differently to various attack types.
- The same reading approach might transfer to detecting other forms of misalignment beyond template-based jailbreaks.
Load-bearing premise
The head identification and suppression experiments accurately isolate effects on refusal and safety activations without confounding changes to other model components or behaviors.
What would settle it
An experiment in which suppressing the identified ACHs fails to increase jailbreak success rates on refused inputs, or in which reading the SAH activations yields no improvement in attack detection over a random baseline.
Figures

read the original abstract
Jailbreak attacks bypass LLM safety alignment, yet their mechanisms remain poorly understood. We provide evidence that attacks do not comprehensively eliminate safety features, but instead selectively suppress specific attention heads. We identify two functionally differentiated types: Adversarially Compromised Heads (ACHs) concentrated in early layers, which are suppressed under attacks, and Safety-Aligned Heads (SAHs) in mid-layers, which maintain robust activations even when attacks succeed. Ablation studies support the causal role of ACHs and the contribution of SAHs to robust activations: suppressing a small number of ACHs is sufficient to induce jailbreak-like behavior on normally refused inputs, while removing SAHs substantially weakens mid-layer safety activations. Token-level attribution further shows that ACH suppression is driven specifically by attack-template tokens, providing a mechanistic account of why attacks can bypass refusal decisions through ACH suppression while leaving internal safety signals sustained by SAHs -- a phenomenon we term Robust Harmful Features. To validate the practical significance of this robustness, we show that simply reading these persistent activations -- without any training -- yields competitive aggregate detection performance with strong adversarial robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that jailbreak attacks on LLMs do not eliminate safety features wholesale but instead selectively suppress Adversarially Compromised Heads (ACHs) concentrated in early layers, while Safety-Aligned Heads (SAHs) in mid-layers maintain robust activations. Ablation experiments are presented as evidence that suppressing a small number of ACHs induces jailbreak-like outputs on refused inputs and that removing SAHs weakens safety signals; token-level attribution links ACH suppression to attack-template tokens. The work further asserts that reading these persistent SAH activations enables competitive zero-shot detection with strong adversarial robustness, a phenomenon termed Robust Harmful Features.
Significance. If the ablation and attribution results hold after addressing isolation concerns, the distinction between selectively suppressed and persistently active safety-related heads would provide a useful mechanistic account of partial safety bypass in LLMs. The zero-training detection result would also have practical value for robust monitoring. The manuscript does not yet supply the quantitative controls, error bars, or dataset details needed to evaluate whether these claims are supported.
major comments (3)
- [Ablation studies] Ablation studies section: the central causal claim that targeted ACH suppression induces jailbreak behavior rests on the assumption that zeroing or masking the identified heads affects only those components. The experiments do not report controls for global changes to the residual stream or downstream attention patterns that could produce non-specific degradation, as raised in the stress-test note. This directly undermines the interpretation that the observed refusal failures are due to selective removal of safety features rather than broader disruption.
- [Token-level attribution] Token-level attribution paragraph: the attribution of ACH suppression specifically to attack-template tokens is presented as mechanistic evidence, yet the method's dependence on the same head interventions used in the ablations is not examined. If attribution scores themselves shift under the interventions, the claimed specificity of the template-token effect cannot be isolated from the intervention artifact.
- [Detection experiments] Detection experiments: the claim of 'competitive aggregate detection performance with strong adversarial robustness' from reading persistent activations is load-bearing for the practical significance but is stated without reported metrics, baselines, dataset sizes, or error bars, making it impossible to assess whether the result supports the robustness conclusion.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., number of ACHs/SAHs identified, ablation success rate, or detection AUC) to allow readers to gauge effect sizes immediately.
- [Methods] Head identification criteria (how ACHs and SAHs are distinguished from other heads) are referenced but not stated with sufficient precision for replication; a dedicated methods subsection with thresholds or statistical tests would improve clarity.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We address each of the major comments in detail below and have made revisions to the manuscript to strengthen the presentation of our results.
read point-by-point responses
-
Referee: Ablation studies section: the central causal claim that targeted ACH suppression induces jailbreak behavior rests on the assumption that zeroing or masking the identified heads affects only those components. The experiments do not report controls for global changes to the residual stream or downstream attention patterns that could produce non-specific degradation, as raised in the stress-test note. This directly undermines the interpretation that the observed refusal failures are due to selective removal of safety features rather than broader disruption.
Authors: We thank the referee for highlighting this important point regarding the specificity of our ablation experiments. We agree that explicit controls for non-specific effects would bolster the causal claims. In the revised manuscript, we have added results from ablating randomly selected heads of comparable count and layer distribution, demonstrating that such ablations do not induce similar jailbreak-like behaviors. Additionally, we report the L2 norm changes in the residual stream post-ablation to confirm minimal global disruption. These additions are detailed in the updated Section 3.2 and Appendix B. revision: yes
-
Referee: Token-level attribution paragraph: the attribution of ACH suppression specifically to attack-template tokens is presented as mechanistic evidence, yet the method's dependence on the same head interventions used in the ablations is not examined. If attribution scores themselves shift under the interventions, the claimed specificity of the template-token effect cannot be isolated from the intervention artifact.
Authors: The token attribution method relies on gradient-based or activation-based attribution computed on the unmodified model to identify the influence of input tokens on head activations. We have clarified this distinction in the revised text. To address the concern, we performed additional checks where we recompute attributions after minor interventions and observe that the relative contribution of template tokens remains consistent. A full examination under the exact ablation conditions is now included as a sensitivity analysis in the appendix. revision: yes
-
Referee: Detection experiments: the claim of 'competitive aggregate detection performance with strong adversarial robustness' from reading persistent activations is load-bearing for the practical significance but is stated without reported metrics, baselines, dataset sizes, or error bars, making it impossible to assess whether the result supports the robustness conclusion.
Authors: We agree that providing explicit metrics, baselines, and error bars is necessary for evaluating the claim. We have expanded the detection experiments section to include these details, with specific performance numbers, baseline comparisons, and statistical measures now reported in a new table. revision: yes
Circularity Check
No circularity: empirical claims rest on experimental measurements, not self-referential definitions or fitted predictions
full rationale
The paper's central claims derive from direct experimental procedures: head identification via activation analysis, targeted ablations (suppressing ACHs or SAHs), and token-level attribution on attack templates. These steps measure observable effects in the model (e.g., changes in refusal behavior or activation strength) rather than deriving a result that is definitionally equivalent to its inputs. No equations, parameter fits, or predictions are presented that reduce by construction to the same data used to define ACHs/SAHs. Self-citations are absent from the provided claims, and the ablation logic is falsifiable via the reported interventions without circular dependence on prior author results. The derivation chain is therefore self-contained as standard mechanistic interpretability work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Kamfonas, M
Alon, G. and Kamfonas, M. J. Detecting language model attacks with perplexity. In The Second Tiny Papers Track at ICLR 2024, 2024. URL https://openreview.net/forum?id=lNLVvdHyAw. OpenReview
2024
-
[2]
Many-shot jailbreaking
Anil, C., Durmus, E., Rimsky, N., et al. Many-shot jailbreaking. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=cw5mgd71jW. OpenReview
2024
-
[3]
Refusal in language models is mediated by a single direction
Arditi, A., Obeso, O., Syed, A., Paleka, D., Panickssery, N., Gurnee, W., and Nanda, N. Refusal in language models is mediated by a single direction. In Advances in Neural Information Processing Systems, volume 37, 2024. OpenReview
2024
-
[6]
E., Hume, T., Carter, S., Henighan, T., and Olah, C
Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Y., Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Hatfield-Dodds, Z., Tamkin, A., Nguyen, K., McLean, B., Burke, J. E., Hume, T., Carter, S., Henighan, T., and Olah, C. Towards monosemanticity: Decomposing languag...
2023
-
[8]
J., and Wong, E
Chao, P., Robey, A., Dobriban, E., Hassani, H., Pappas, G. J., and Wong, E. Jailbreaking black box large language models in twenty queries. In The Twelfth International Conference on Learning Representations, 2024 b . URL https://openreview.net/forum?id=hkjcdmz8Ro. OpenReview
2024
-
[9]
Llama guard 3 vision: Safeguarding human-ai image understanding conversations, 2024
Chi, J., Karn, U., Zhan, H., et al. Llama guard 3 vision: Safeguarding human-ai image understanding conversations, 2024. URL https://arxiv.org/abs/2411.10414v1
arXiv 2024
-
[10]
N., Lynch, A., Heimersheim, S., and Garriga-Alonso, A
Conmy, A., Mavor-Parker, A. N., Lynch, A., Heimersheim, S., and Garriga-Alonso, A. Towards automated circuit discovery for mechanistic interpretability. In Advances in Neural Information Processing Systems, volume 36, 2023. URL https://openreview.net/forum?id=89ia77nZ8u. NeurIPS 2023 Spotlight
2023
-
[11]
OR-Bench : An over-refusal benchmark for large language models
Cui, J., Chiang, W.-L., Stoica, I., and Hsieh, C.-J. OR-Bench : An over-refusal benchmark for large language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=obYVdcMMIT. OpenReview
2025
-
[12]
A mathematical framework for transformer circuits
Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., DasSarma, N., Drain, D., Ganguli, D., Hatfield-Dodds, Z., Hernandez, D., Jones, A., Kernion, J., Lovitt, L., Ndousse, K., Amodei, D., Brown, T., Clark, J., Kaplan, J., McCandlish, S., and Olah, C. A mathematical framework for transformer circ...
2021
-
[13]
Ghandeharioun, A., Caciularu, A., Pearce, A., Dixon, L., and Geva, M
Geva, M., Schuster, R., Berant, J., and Levy, O. Transformer feed-forward layers are key-value memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp.\ 5484--5495. Association for Computational Linguistics, 2021. doi:10.18653/v1/2021.emnlp-main.446
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[15]
AEGIS2.0 : A diverse AI safety dataset and risks taxonomy for alignment of LLM guardrails
Ghosh, S., Varshney, P., Gaur, A., et al. AEGIS2.0 : A diverse AI safety dataset and risks taxonomy for alignment of LLM guardrails. In Findings of the Association for Computational Linguistics: NAACL 2025. Association for Computational Linguistics, 2025
2025
-
[16]
WILDGUARD : Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLM s
Han, S., Rao, K., Ettinger, A., et al. WILDGUARD : Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLM s. In Advances in Neural Information Processing Systems, volume 37, 2024. OpenReview
2024
-
[17]
Hu, X., Chen, P.-Y., and Ho, T.-Y. Gradient cuff: Detecting jailbreak attacks on large language models by exploring refusal loss landscapes. In Advances in Neural Information Processing Systems, volume 37, pp.\ 126265--126296, 2024. doi:10.52202/079017-4011
-
[19]
Position: TRUSTLLM : Trustworthiness in large language models
Huang, Y., Sun, L., Wang, H., et al. Position: TRUSTLLM : Trustworthiness in large language models. In Forty-first International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pp.\ 20166--20212. PMLR, 2024
2024
-
[21]
WildTeaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models
Jiang, L., Rao, K., Han, S., Ettinger, A., Brahman, F., Kumar, S., Mireshghallah, N., Lu, X., Sap, M., Choi, Y., and Dziri, N. WildTeaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models. In Advances in Neural Information Processing Systems, volume 37, 2024. OpenReview
2024
-
[22]
Lee, B. W., Padhi, I., Ramamurthy, K. N., Miehling, E., Dognin, P., Nagireddy, M., and Dhurandhar, A. Programming refusal with conditional activation steering, 2024. URL https://arxiv.org/abs/2409.05907
arXiv 2024
-
[23]
SALAD-Bench : A hierarchical and comprehensive safety benchmark for large language models
Li, L., Dong, B., Wang, R., et al. SALAD-Bench : A hierarchical and comprehensive safety benchmark for large language models. In Findings of the Association for Computational Linguistics: ACL 2024, pp.\ 11097--11119. Association for Computational Linguistics, 2024 a . URL https://arxiv.org/abs/2402.05044
arXiv 2024
-
[24]
Jailbreak attack for large language models: A survey
Li, N., Ding, Y., Jiang, H., Niu, J., and Yi, P. Jailbreak attack for large language models: A survey. Journal of Computer Research and Development, 61 0 (5): 0 1156--1181, 2024 b . doi:10.7544/issn1000-1239.202330962. URL https://crad.ict.ac.cn/en/article/doi/10.7544/issn1000-1239.202330962
-
[26]
ToxicChat : Unveiling hidden challenges of toxicity detection in real-world user- AI conversation
Lin, Z., Zeng, Z., Gao, Z., et al. ToxicChat : Unveiling hidden challenges of toxicity detection in real-world user- AI conversation. In Findings of the Association for Computational Linguistics: EMNLP 2023, pp.\ 4694--4702. Association for Computational Linguistics, 2023
2023
-
[27]
AutoDAN : Generating stealthy jailbreak prompts on aligned large language models
Liu, X., Xu, N., Chen, M., and Xiao, C. AutoDAN : Generating stealthy jailbreak prompts on aligned large language models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=7Jwpw4qKkb. OpenReview
2024
-
[28]
A holistic approach to undesired content detection in the real world, 2022
Markov, T., Zhang, C., Agarwal, S., et al. A holistic approach to undesired content detection in the real world, 2022. URL https://arxiv.org/abs/2208.03274v3
arXiv 2022
-
[29]
J., Belinkov, Y., Bau, D., and Mueller, A
Marks, S., Rager, C., Michaud, E. J., Belinkov, Y., Bau, D., and Mueller, A. Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=I4e82CIDxv. OpenReview
2025
-
[30]
HarmBench : A standardized evaluation framework for automated red teaming and robust refusal
Mazeika, M., Phan, L., Yin, X., et al. HarmBench : A standardized evaluation framework for automated red teaming and robust refusal. In Forty-first International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pp.\ 35075--35110. PMLR, 2024. URL https://openreview.net/forum?id=f9mhWhwDJz
2024
-
[31]
Copy suppression: Comprehensively understanding an attention head, 2023
McDougall, C., Conmy, A., Rushing, C., McGrath, T., and Nanda, N. Copy suppression: Comprehensively understanding an attention head, 2023. URL https://arxiv.org/abs/2310.04625v1
arXiv 2023
-
[32]
Progress measures for grokking via mechanistic interpretability
Nanda, N., Chan, L., Lieberum, T., Smith, J., and Steinhardt, J. Progress measures for grokking via mechanistic interpretability. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=9XFSbDPmdW. OpenReview
2023
-
[33]
In-context learning and induction heads
Olsson, C., Elhage, N., Nanda, N., et al. In-context learning and induction heads. Transformer Circuits Thread, 2022. arXiv:2209.11895
Pith/arXiv arXiv 2022
-
[34]
Causality: Models, Reasoning, and Inference
Pearl, J. Causality: Models, Reasoning, and Inference. Cambridge University Press, 2nd edition, 2009. ISBN 978-0-521-89560-6
2009
-
[35]
Robey, A., Wong, E., Hassani, H., and Pappas, G. J. SmoothLLM : Defending large language models against jailbreaking attacks. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=xq7h9nfdY2. OpenReview
2024
-
[36]
Axiomatic attribution for deep networks
Sundararajan, M., Taly, A., and Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pp.\ 3319--3328. PMLR, 2017. URL https://proceedings.mlr.press/v70/sundararajan17a.html
2017
-
[37]
Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., and Hashimoto, T. B. Stanford alpaca: An instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_alpaca, 2023. GitHub repository
2023
-
[39]
a ger, T., Elstner, J., Geisler, S., Cohen-Addad, V., G \
Wollschl \"a ger, T., Elstner, J., Geisler, S., Cohen-Addad, V., G \"u nnemann, S., and Gasteiger, J. The geometry of refusal in large language models: Concept cones and representational independence. In Forty-second International Conference on Machine Learning, Proceedings of Machine Learning Research. PMLR, 2025. URL https://openreview.net/forum?id=80IwJqlXs8
2025
-
[41]
Xu, Z., Jiang, F., Niu, L., Jia, J., Lin, B. Y., and Poovendran, R. SafeDecoding : Defending against jailbreak attacks via safety-aware decoding. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 5587--5605, 2024. URL https://arxiv.org/abs/2402.08983
arXiv 2024
-
[42]
J., Prakash, N., Neo, C., Satapathy, R., Lee, R
Yeo, W. J., Prakash, N., Neo, C., Satapathy, R., Lee, R. K.-W., and Cambria, E. Understanding refusal in language models with sparse autoencoders. In Findings of the Association for Computational Linguistics: EMNLP 2025. Association for Computational Linguistics, 2025. doi:10.18653/v1/2025.findings-emnlp.338
-
[43]
Qwen3guard technical report, 2025 a
Zhao, H., Yuan, C., Huang, F., et al. Qwen3guard technical report, 2025 a . URL https://arxiv.org/abs/2510.14276v1
Pith/arXiv arXiv 2025
-
[44]
Zhao, Y., Zhang, W., Xie, Y., Goyal, A., Kawaguchi, K., and Shieh, M. Q. Understanding and enhancing safety mechanisms of LLM s via safety-specific neuron. In The Thirteenth International Conference on Learning Representations, 2025 b . URL https://openreview.net/forum?id=yR47RmND1m. OpenReview
2025
-
[45]
How alignment and jailbreak work: Explain LLM safety through intermediate hidden states
Zhou, Z., Yu, H., Zhang, X., Xu, R., Huang, F., and Li, Y. How alignment and jailbreak work: Explain LLM safety through intermediate hidden states. In Findings of the Association for Computational Linguistics: EMNLP 2024, pp.\ 2461--2488. Association for Computational Linguistics, 2024. URL https://aclanthology.org/2024.findings-emnlp.139/
2024
-
[46]
On the role of attention heads in large language model safety, 2025
Zhou, Z., Yu, H., Zhang, X., et al. On the role of attention heads in large language model safety, 2025. URL https://arxiv.org/abs/2410.13708v1
arXiv 2025
-
[47]
Zou, A., Wang, Z., Kolter, J. Z., and Fredrikson, M. Universal and transferable adversarial attacks on aligned language models. In Advances in Neural Information Processing Systems, volume 36, pp.\ 1--24, 2023. URL https://arxiv.org/abs/2307.15043
Pith/arXiv arXiv 2023
-
[48]
Z., Fredrikson, M., and Hendrycks, D
Zou, A., Phan, L., Wang, J., Duenas, D., Lin, M., Andriushchenko, M., Wang, R., Kolter, J. Z., Fredrikson, M., and Hendrycks, D. Improving alignment and robustness with circuit breakers. In Advances in Neural Information Processing Systems, volume 37, 2024. URL https://openreview.net/forum?id=IbIB8SBKFV. OpenReview
2024
-
[49]
OpenAI and Josh Achiam and Steven Adler and Sandhini Agarwal and others , year=. 2303.08774v4 , archivePrefix=
-
[50]
2025 , eprint=
A Survey of Large Language Models , author=. 2025 , eprint=
2025
-
[51]
2025 , journal =
Naveed, Humza and Khan, Asad Ullah and Qiu, Shi and others , title =. 2025 , journal =
2025
-
[52]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[53]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[54]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[55]
Advances in Neural Information Processing Systems , volume=
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[56]
2024 , url=
Xiaogeng Liu and Nan Xu and Muhao Chen and Chaowei Xiao , booktitle=. 2024 , url=
2024
-
[57]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Many-shot Jailbreaking , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[58]
The Twelfth International Conference on Learning Representations , year=
Jailbreaking Black Box Large Language Models in Twenty Queries , author=. The Twelfth International Conference on Learning Representations , year=
-
[59]
Journal of Computer Research and Development , volume =
Jailbreak Attack for Large Language Models: A Survey , author =. Journal of Computer Research and Development , volume =. 2024 , doi =
2024
-
[60]
Advances in Neural Information Processing Systems , volume=
Improving Alignment and Robustness with Circuit Breakers , author=. Advances in Neural Information Processing Systems , volume=. 2024 , url=
2024
-
[61]
2024 , url=
Zhangchen Xu and Fengqing Jiang and Luyao Niu and Jinyuan Jia and Bill Yuchen Lin and Radha Poovendran , booktitle=. 2024 , url=
2024
-
[62]
Pappas , booktitle=
Alexander Robey and Eric Wong and Hamed Hassani and George J. Pappas , booktitle=. 2024 , url=
2024
-
[63]
The Second Tiny Papers Track at ICLR 2024 , year=
Detecting Language Model Attacks With Perplexity , author=. The Second Tiny Papers Track at ICLR 2024 , year=
2024
-
[64]
2024 , url=
Yifan Zeng and Yiran Wu and Xiao Zhang and Huazheng Wang and Qingyun Wu , booktitle=. 2024 , url=
2024
-
[65]
2024 , url=
Mansi Phute and Alec Helbling and Matthew Daniel Hull and ShengYun Peng and Sebastian Szyller and Cory Cornelius and Duen Horng Chau , booktitle=. 2024 , url=
2024
-
[66]
Advances in Neural Information Processing Systems , volume=
Gradient Cuff: Detecting Jailbreak Attacks on Large Language Models by Exploring Refusal Loss Landscapes , author=. Advances in Neural Information Processing Systems , volume=. 2024 , doi=
2024
-
[67]
2024 , eprint=
Programming Refusal with Conditional Activation Steering , author=. 2024 , eprint=
2024
-
[68]
Hakan Inan and Kartikeya Upasani and Jianfeng Chi and others , year=. Llama Guard:. 2312.06674v2 , archivePrefix=
-
[69]
2024 , eprint=
Llama Guard 3 Vision: Safeguarding Human-AI Image Understanding Conversations , author=. 2024 , eprint=
2024
-
[70]
2025 , eprint=
Qwen3Guard Technical Report , author=. 2025 , eprint=
2025
-
[71]
2024 , note=
Seungju Han and Kavel Rao and Allyson Ettinger and others , booktitle=. 2024 , note=
2024
-
[72]
2025 , publisher =
Ghosh, Shaona and Varshney, Prasoon and Gaur, Anu and others , booktitle =. 2025 , publisher =
2025
-
[73]
2024 , publisher=
Mantas Mazeika and Long Phan and Xuwang Yin and others , booktitle=. 2024 , publisher=
2024
-
[74]
Patrick Chao and Edoardo Debenedetti and Alexander Robey and others , year=. 2404.01318v2 , archivePrefix=
-
[75]
Bertie Vidgen and Nino Scherrer and Hannah Rose Kirk and others , year=. 2311.08370v2 , archivePrefix=
-
[76]
Position:
Yue Huang and Lichao Sun and Haoran Wang and others , booktitle=. Position:. 2024 , publisher=
2024
-
[77]
2024 , publisher=
Lijun Li and Bowen Dong and Ruohui Wang and others , booktitle=. 2024 , publisher=
2024
-
[78]
2023 , publisher =
Lin, Zi and Zeng, Zihan and Gao, Zi and others , booktitle =. 2023 , publisher =
2023
-
[79]
2022 , eprint=
A Holistic Approach to Undesired Content Detection in the Real World , author=. 2022 , eprint=
2022
-
[80]
Shaona Ghosh and Prasoon Varshney and Erick Galinkin and Christopher Parisien , year=. 2404.05993v2 , archivePrefix=
-
[81]
2024 , note=
Jiang, Liwei and Rao, Kavel and Han, Seungju and Ettinger, Allyson and Brahman, Faeze and Kumar, Sachin and Mireshghallah, Niloofar and Lu, Ximing and Sap, Maarten and Choi, Yejin and Dziri, Nouha , booktitle=. 2024 , note=
2024
-
[82]
2025 , url=
Cui, Justin and Chiang, Wei-Lin and Stoica, Ion and Hsieh, Cho-Jui , booktitle=. 2025 , url=
2025
-
[83]
Advances in Neural Information Processing Systems , volume=
Refusal in Language Models is Mediated by a Single Direction , author=. Advances in Neural Information Processing Systems , volume=. 2024 , note=
2024
-
[84]
Forty-second International Conference on Machine Learning , series=
The Geometry of Refusal in Large Language Models: Concept Cones and Representational Independence , author=. Forty-second International Conference on Machine Learning , series=. 2025 , publisher=
2025
-
[85]
Findings of the Association for Computational Linguistics: EMNLP 2025 , year =
Understanding Refusal in Language Models with Sparse Autoencoders , author =. Findings of the Association for Computational Linguistics: EMNLP 2025 , year =
2025
-
[86]
Safety Layers in Aligned Large Language Models: The Key to
Shen Li and Liuyi Yao and Lan Zhang and Yaliang Li , year=. Safety Layers in Aligned Large Language Models: The Key to. 2408.17003v1 , archivePrefix=
-
[87]
Understanding and Enhancing Safety Mechanisms of
Zhao, Yiran and Zhang, Wenxuan and Xie, Yuxi and Goyal, Anirudh and Kawaguchi, Kenji and Shieh, Michael Qizhe , booktitle =. Understanding and Enhancing Safety Mechanisms of. 2025 , url =
2025
-
[88]
2025 , eprint=
On the Role of Attention Heads in Large Language Model Safety , author=. 2025 , eprint=
2025
-
[89]
Transformer Circuits Thread , year=
A Mathematical Framework for Transformer Circuits , author=. Transformer Circuits Thread , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.