Pixel Wised Lesion Prediction on COVID-19 CT Imagery: A Comparative Analysis of Automated Image Segmentation Architectures
Pith reviewed 2026-05-21 06:43 UTC · model grok-4.3
The pith
Deep learning architectures produce precise segmentation of COVID-19 lesions from CT scans when tested across multiple models and datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The findings derived from our analysis of three distinct COVID-19 CT segmentation datasets indicate that deep learning architectures yield precise and efficient segmentation outcomes. Significantly, a maximum F1-Score of 98% was attained for binary class segmentation, while multi-class segmentation yielded F1-Scores of 75% and 77% across two separate datasets. The utilization of artificial intelligence and deep learning enhances the diagnostic process for pandemic diseases across multiple dimensions.
What carries the argument
Comparative evaluation of Unet, PSPNet, Linknet and FPN architectures combined with six pre-trained encoders on three COVID-19 CT datasets for binary and multi-class lesion segmentation.
If this is right
- Deep learning can support faster and more consistent lesion measurement in CT scans for COVID-19 patients.
- The performance numbers offer a reference point for judging segmentation methods in other medical imaging tasks.
- Combining different architectures with pre-trained backbones improves reliability of automated diagnosis for pandemic diseases.
- Both binary and multi-class approaches prove useful depending on the level of detail required.
Where Pith is reading between the lines
- If the best-performing combinations generalize, they could be adapted to track disease progression over time in follow-up scans.
- Future work might test these models on data from different hospitals to confirm they work across varying scan qualities.
- Integration into clinical software could reduce the time radiologists spend on manual segmentation.
Load-bearing premise
The three selected COVID-19 CT datasets are representative enough that the performance patterns observed here will hold for segmentation tasks in other medical imaging contexts.
What would settle it
Running the same model combinations on a fourth COVID-19 CT dataset collected from different scanners or patient groups and finding F1 scores drop below 70 percent for binary segmentation would challenge the reliability of the reported outcomes as a general reference.
Figures


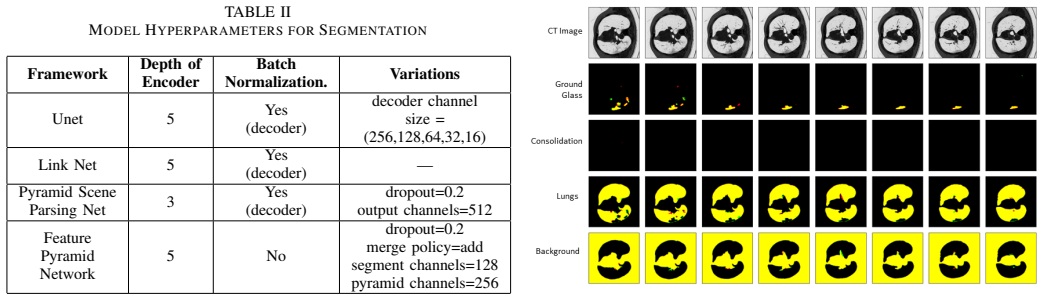


read the original abstract
In recent years, there has been a notable increase in the level of attention that is given to algorithms based on deep learning in the context of medical image segmentation. Nevertheless, the reliability of the field has been hindered due to the absence of a standardized methodology for performance analysis and the utilization of different datasets in previous research. The primary objective of the research is to comprehensively evaluate contemporary segmentation frameworks combined with state-of-the-art pre-trained backbones in order to accurately predict COVID-19 lesions in CT images. Moreover, this evaluation can serve as a point of reference for the segmentation of images in various other imaging scenarios. In order to accomplish this, we integrate four distinct deep learning architectures, namely Unet, PSPNet, Linknet, and FPN, with six pre-trained encoders, including VGG 19, DenseNet 121, Inception ResNet V2, MobileNet V2, SeresNet 101, and EfficientNet B0. This approach enables the development of diverse testing architectures. In the context of image segmentation, our research encompassed both binary and multi-class experimentation. The findings derived from our analysis of three distinct COVID-19 CT segmentation datasets indicate that deep learning architectures yield precise and efficient segmentation outcomes. Significantly, a maximum F1-Score of 98% was attained for binary class segmentation, while multi-class segmentation yielded F1-Scores of 75% and 77% across two separate datasets. The utilization of artificial intelligence and deep learning enhances the diagnostic process for pandemic diseases across multiple dimensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper performs an empirical comparison of four segmentation architectures (U-Net, PSPNet, LinkNet, FPN) combined with six pre-trained encoders (VGG19, DenseNet121, InceptionResNetV2, MobileNetV2, SeResNet101, EfficientNetB0) on three COVID-19 CT datasets. Experiments cover both binary and multi-class lesion segmentation, with reported peak F1 scores of 98% (binary) and 75-77% (multi-class), and position the results as a reference benchmark for other imaging scenarios.
Significance. If the experimental protocol were fully documented and reproducible, the work would supply a useful side-by-side benchmark of established segmentation models on COVID-19 CT data. The reported F1 numbers, if verified, indicate that standard encoder-decoder pipelines can achieve high binary-segmentation accuracy on these particular datasets, but the absence of methodological transparency prevents the results from serving as a reliable external reference.
major comments (3)
- [Abstract] Abstract and objectives paragraph: the assertion that the three COVID-19 CT datasets are sufficiently representative to serve as 'a point of reference for the segmentation of images in various other imaging scenarios' is unsupported; no quantitative comparison of scanner protocols, acquisition parameters, lesion-size distributions, or external validation set is provided.
- [Methods] Methods / experimental setup (inferred from absence in abstract and results description): no training hyperparameters, optimizer settings, learning-rate schedule, data-augmentation policy, cross-validation scheme, or number of random seeds are reported, so the headline F1 scores (98 % binary, 75-77 % multi-class) cannot be independently verified or reproduced.
- [Results] Results section: performance figures are presented without error bars, standard deviations across folds or runs, or statistical significance tests, making it impossible to assess whether observed differences between architectures are reliable or merely within-run variation.
minor comments (2)
- [Abstract] The abstract contains several run-on sentences that could be split for readability.
- [Figures/Tables] Figure captions and table headings should explicitly state the exact metric (F1-score) and the class setting (binary vs. multi-class) rather than relying on surrounding text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that several aspects of the manuscript require clarification and expansion to improve reproducibility and to ensure claims are appropriately scoped. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and objectives paragraph: the assertion that the three COVID-19 CT datasets are sufficiently representative to serve as 'a point of reference for the segmentation of images in various other imaging scenarios' is unsupported; no quantitative comparison of scanner protocols, acquisition parameters, lesion-size distributions, or external validation set is provided.
Authors: We agree that the claim regarding the datasets serving as a general reference for other imaging scenarios is not supported by quantitative comparisons of scanner protocols, acquisition parameters, lesion distributions, or external validation. We will revise the abstract and objectives paragraph to remove this assertion and limit the stated contribution to a comparative evaluation on the three specific COVID-19 CT datasets. revision: yes
-
Referee: [Methods] Methods / experimental setup (inferred from absence in abstract and results description): no training hyperparameters, optimizer settings, learning-rate schedule, data-augmentation policy, cross-validation scheme, or number of random seeds are reported, so the headline F1 scores (98 % binary, 75-77 % multi-class) cannot be independently verified or reproduced.
Authors: The referee correctly identifies that these experimental details are missing from the current manuscript. We will add a dedicated subsection in the Methods section that fully documents the training hyperparameters, optimizer, learning-rate schedule, data-augmentation policy, cross-validation or train/validation/test split scheme, and random seeds employed, enabling independent reproduction of the reported results. revision: yes
-
Referee: [Results] Results section: performance figures are presented without error bars, standard deviations across folds or runs, or statistical significance tests, making it impossible to assess whether observed differences between architectures are reliable or merely within-run variation.
Authors: We acknowledge that the absence of variability measures and statistical tests limits the ability to evaluate the reliability of performance differences. We will revise the Results section to report standard deviations or error bars across multiple runs or folds and to include appropriate statistical significance tests (e.g., paired comparisons) between the leading models. revision: yes
Circularity Check
No circularity: purely empirical comparison of existing models
full rationale
The paper evaluates four standard segmentation architectures (Unet, PSPNet, Linknet, FPN) paired with six pre-trained encoders on three COVID-19 CT datasets and directly reports measured F1-scores (98% binary, 75-77% multi-class). No equations, fitted parameters, predictions derived from first principles, or self-citation chains appear. All claims reduce to experimental measurements on the chosen data; the generalization remark is an interpretive statement rather than a load-bearing derivation that collapses to the inputs by construction. The work is self-contained against external benchmarks of model performance.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
integrate four distinct deep learning architectures, namely Unet, PSPNet, Linknet, and FPN, with six pre-trained encoders... maximum F1-Score of 98%... multi-class segmentation yielded F1-Scores of 75% and 77%
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three distinct COVID-19 CT segmentation datasets... point of reference for the segmentation of images in various other imaging scenarios
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Coronavirus Disease (COVID-19) Situation Reports. Who.int. Published
-
[2]
https://www.who.int/emergencies/diseases/novel-coronavirus- 2019/situation-reports
work page 2019
-
[3]
Wang, D., Hu, B., Hu, C., Zhu, F., Liu, X., Zhang, J., Wang, B., Xiang, H., Cheng, Z., Xiong, Y . & Others Clinical characteristics of 138 hospitalized patients with 2019 novel coronavirus–infected pneumonia in Wuhan, China.Jama.323, 1061-1069 (2020)
work page 2019
- [4]
-
[5]
Saeedizadeh, N., Minaee, S., Kafieh, R., Yazdani, S. & Sonka, M. COVID TV-Unet: Segmenting COVID-19 chest CT images using connectivity imposed Unet.Computer Methods And Programs In Biomedicine Update.1pp. 100007 (2021)
work page 2021
-
[6]
Saood, A. & Hatem, I. COVID-19 lung CT image segmentation using deep learning methods: U-Net versus SegNet.BMC Medical Imaging. 21, 1-10 (2021)
work page 2021
-
[7]
M ¨uller, D., Rey, I. & Kramer, F. Automated chest ct image segmen- tation of covid-19 lung infection based on 3d u-net.ArXiv Preprint ArXiv:2007.04774. (2020)
-
[8]
V oulodimos, A., Protopapadakis, E., Katsamenis, I., Doulamis, A. & Doulamis, N. Deep learning models for COVID-19 infected area seg- mentation in CT images.The 14th PErvasive Technologies Related To Assistive Environments Conference. pp. 404-411 (2021)
work page 2021
-
[9]
Gao, K., Su, J., Jiang, Z., Zeng, L., Feng, Z., Shen, H., Rong, P., Xu, X., Qin, J., Yang, Y . & Others Dual-branch combination network (DCN): Towards accurate diagnosis and lesion segmentation of COVID-19 using CT images.Medical Image Analysis.67pp. 101836 (2021)
work page 2021
- [10]
-
[11]
Raj, A., Zhu, H., Khan, A., Zhuang, Z., Yang, Z., Mahesh, V . & Karthik, G. ADID-UNET—a segmentation model for COVID-19 infection from lung CT scans.PeerJ Computer Science.7pp. e349 (2021)
work page 2021
-
[12]
http://medicalsegmentation.com/covid19/
- [13]
- [14]
- [15]
-
[16]
Chaurasia, A. & Culurciello, E. Linknet: Exploiting encoder represen- tations for efficient semantic segmentation.2017 IEEE Visual Commu- nications And Image Processing (VCIP). pp. 1-4 (2017)
work page 2017
-
[17]
Lin, T., Doll ´ar, P., Girshick, R., He, K., Hariharan, B. & Belongie, S. Feature pyramid networks for object detection.Proceedings Of The IEEE Conference On Computer Vision And Pattern Recognition. pp. 2117- 2125 (2017)
work page 2017
-
[18]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition.ArXiv Preprint ArXiv:1409.1556. (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
Deng, J., Dong, W., Socher, R., Li, L., Li, K. & Fei-Fei, L. Imagenet: A large-scale hierarchical image database.2009 IEEE Conference On Computer Vision And Pattern Recognition. pp. 248-255 (2009)
work page 2009
-
[20]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Howard, A., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M. & Adam, H. Mobilenets: Efficient convo- lutional neural networks for mobile vision applications.ArXiv Preprint ArXiv:1704.04861
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Huang, G., Liu, Z., Van Der Maaten, L. & Weinberger, K. Densely connected convolutional networks.Proceedings Of The IEEE Confer- ence On Computer Vision And Pattern Recognition. pp. 4700-4708 (2017)(2017)
work page 2017
-
[22]
Tan, M. & Le, Q. Efficientnet: Rethinking model scaling for convolu- tional neural networks.International Conference On Machine Learning. pp. 6105-6114 (2019)
work page 2019
- [23]
-
[24]
Szegedy, C., Liu, W., Jia, Y ., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V . & Rabinovich, A. Going deeper with convo- lutions.Proceedings Of The IEEE Conference On Computer Vision And Pattern Recognition. pp. 1-9 (2015)
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.