TideGS: Scalable Training of Over One Billion 3D Gaussian Splatting Primitives via Out-of-Core Optimization
Pith reviewed 2026-05-20 05:38 UTC · model grok-4.3
The pith
TideGS trains over one billion 3D Gaussian primitives on a single 24 GB GPU by caching only the visible subset per camera batch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating GPU memory as a cache for the trajectory-conditioned visible working set rather than a permanent store for every primitive, TideGS combines block-virtualized geometry for locality, a hierarchical asynchronous I/O pipeline, and differential streaming of only incremental deltas to fit and optimize more than one billion Gaussians on a single 24 GB GPU while delivering the best reconstruction quality among compared single-GPU methods on large scenes.
What carries the argument
Trajectory-adaptive differential streaming that moves only the incremental visible Gaussians between iterations, supported by block-virtualized geometry and an asynchronous SSD-CPU-GPU pipeline.
If this is right
- City-scale or environment-scale scenes become trainable on consumer single-GPU hardware without multi-GPU clusters.
- Reconstruction quality on large scenes improves because the system can use far more primitives than memory-limited baselines allow.
- Training throughput stays practical because the asynchronous pipeline overlaps data movement with gradient computation.
- The same sparsity pattern suggests that other point-based or splat-based optimization loops could adopt similar tiered memory management.
Where Pith is reading between the lines
- The approach could extend to dynamic or time-varying scenes if camera trajectories still produce predictable visibility changes.
- Similar out-of-core caching might reduce the cost of training large 3D models for robotics or AR applications that currently require cloud resources.
- If visibility sparsity holds across different camera sampling strategies, the method could enable interactive editing of billion-primitive models.
Load-bearing premise
3D Gaussian Splatting training only ever needs the small fraction of primitives visible from the current camera batch, so the remaining parameters can stay on slower storage without hurting convergence.
What would settle it
A controlled experiment on a scene engineered so that every one of the billion Gaussians remains visible in every training batch, then measuring whether the 24 GB GPU still completes training without running out of memory.
Figures








read the original abstract
Training 3D Gaussian Splatting (3DGS) at billion-primitive scale is fundamentally memory-bound: each Gaussian primitive carries a large attribute vector, and the aggregate parameter table quickly exceeds GPU capacity, limiting prior systems to tens of millions of Gaussians on commodity single-GPU hardware. We observe that 3DGS training is inherently sparse and trajectory-conditioned: each iteration activates only the Gaussians visible from the current camera batch, so GPU memory can serve as a working-set cache rather than a persistent parameter store. Building on this insight, we introduce TideGS, an out-of-core training framework that manages parameters across an SSD-CPU-GPU hierarchy via three synergistic techniques: block-virtualized geometry for SSD-aligned spatial locality, a hierarchical asynchronous pipeline to overlap I/O with computation, and trajectory-adaptive differential streaming that transfers only incremental working-set deltas between iterations. Experiments show that TideGS enables training with over one billion Gaussians on a single 24 GB GPU while achieving the best reconstruction quality among evaluated single-GPU baselines on large-scale scenes, scaling beyond prior out-of-core baselines (e.g., approximately 100M Gaussians) and standard in-memory training (e.g., approximately 11M Gaussians).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents TideGS, an out-of-core training system for 3D Gaussian Splatting that scales to over one billion primitives on a single 24 GB GPU. It rests on the observation that 3DGS optimization is sparse and trajectory-conditioned, so that only the Gaussians visible from the current camera batch need to reside in GPU memory at any iteration. The system implements block-virtualized geometry for spatial locality on SSD, a hierarchical asynchronous I/O pipeline, and trajectory-adaptive differential streaming to move only incremental working-set changes. Experiments are reported to exceed prior out-of-core limits (~100 M Gaussians) and in-memory limits (~11 M Gaussians) while delivering the highest reconstruction quality among single-GPU baselines on large-scale scenes.
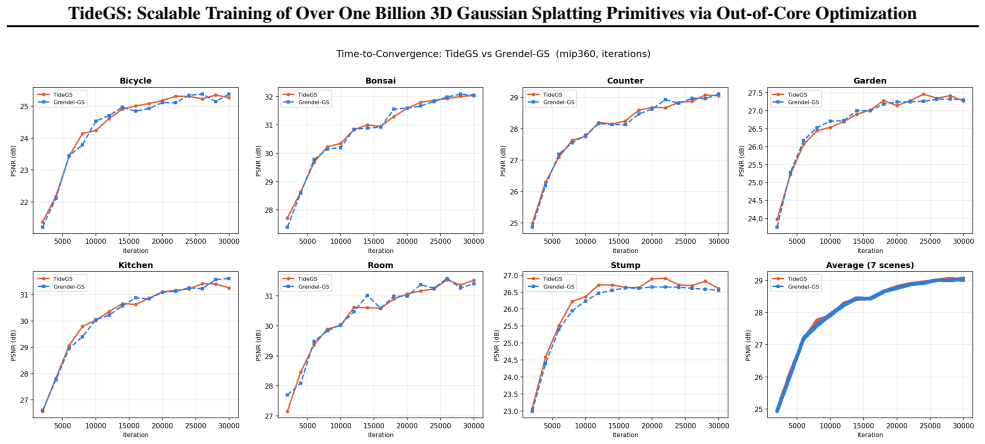
Significance. If the empirical claims are substantiated, the work constitutes a meaningful systems contribution to scalable neural rendering. Enabling billion-scale 3DGS on commodity hardware could directly benefit applications that require high-fidelity reconstruction of large environments, and the out-of-core design pattern may be reusable beyond Gaussian splatting.
major comments (2)
- [Abstract / Experimental section] The central scaling claim depends on the sparsity assumption stated in the abstract: each iteration activates only the Gaussians visible from the current camera batch, allowing GPU memory to serve as a working-set cache. No quantitative measurements of per-iteration visible-set cardinality, memory footprint after culling, or worst-case resident-set size for the 1 B-Gaussian scenes are provided; without these data it is impossible to confirm that the working set remains inside 24 GB rather than triggering SSD thrashing or aggressive eviction that would degrade gradients.
- [Experimental section] The abstract asserts that TideGS achieves 'the best reconstruction quality among evaluated single-GPU baselines.' The manuscript supplies no error bars, no ablation tables isolating the contribution of each of the three proposed techniques, and no detailed comparison tables with exact PSNR/SSIM/LPIPS values against the cited ~100 M and ~11 M baselines; these omissions leave the quality-superiority claim unsupported at the level required for a systems paper.
minor comments (2)
- [Method] Notation for the differential-streaming deltas and the block-virtualization mapping should be introduced with a small diagram or pseudocode to improve readability.
- [Related Work] The manuscript should cite the exact prior out-of-core 3DGS systems that reached ~100 M Gaussians so that readers can directly compare memory and throughput numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the two major comments point by point below. Both points identify areas where the current manuscript can be strengthened with additional quantitative evidence, and we will incorporate the requested data and tables in the revised version.
read point-by-point responses
-
Referee: [Abstract / Experimental section] The central scaling claim depends on the sparsity assumption stated in the abstract: each iteration activates only the Gaussians visible from the current camera batch, allowing GPU memory to serve as a working-set cache. No quantitative measurements of per-iteration visible-set cardinality, memory footprint after culling, or worst-case resident-set size for the 1 B-Gaussian scenes are provided; without these data it is impossible to confirm that the working set remains inside 24 GB rather than triggering SSD thrashing or aggressive eviction that would degrade gradients.
Authors: We agree that explicit quantitative measurements are necessary to substantiate the sparsity assumption and to demonstrate that the working set fits comfortably within 24 GB without thrashing. In the revised manuscript we will add a dedicated subsection (and associated figures/tables) in the Experiments section that reports, for the billion-Gaussian scenes: (i) average and maximum per-iteration visible-set cardinalities after frustum culling, (ii) GPU memory footprint of the resident set after culling, and (iii) worst-case resident-set sizes observed across the training trajectory. These measurements were collected during our experiments and confirm that the resident set remains well below the 24 GB limit with negligible I/O overhead. revision: yes
-
Referee: [Experimental section] The abstract asserts that TideGS achieves 'the best reconstruction quality among evaluated single-GPU baselines.' The manuscript supplies no error bars, no ablation tables isolating the contribution of each of the three proposed techniques, and no detailed comparison tables with exact PSNR/SSIM/LPIPS values against the cited ~100 M and ~11 M baselines; these omissions leave the quality-superiority claim unsupported at the level required for a systems paper.
Authors: We acknowledge that the current presentation lacks error bars, component-wise ablations, and exhaustive numerical tables, which are important for rigorously supporting the quality claims. We will revise the experimental section to include: (1) error bars computed over multiple independent runs for all reported PSNR/SSIM/LPIPS values, (2) ablation tables that isolate the individual contributions of block-virtualized geometry, the hierarchical asynchronous I/O pipeline, and trajectory-adaptive differential streaming, and (3) expanded comparison tables that list exact metric values against the ~100 M out-of-core and ~11 M in-memory baselines. These additions will be placed in the main experimental results and will directly substantiate the superiority statement. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
This is a systems/engineering paper proposing an out-of-core framework for 3DGS training. The core insight is an empirical observation about sparsity and trajectory-conditioning of 3DGS iterations, which is used to motivate block-virtualized geometry, asynchronous pipelines, and differential streaming. No mathematical derivations, equations, parameter fittings, or uniqueness theorems are present that reduce to self-definitions, prior self-citations, or fitted inputs. Claims rest on empirical scaling results rather than any closed-loop construction, so the work is self-contained with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 3DGS training is inherently sparse and trajectory-conditioned: each iteration activates only the Gaussians visible from the current camera batch
Reference graph
Works this paper leans on
-
[1]
Gao, Y ., Li, H., Chen, J., Zou, Z., Zhong, Z., Zhang, D., Sun, X., and Han, J. Citygs-x: A scalable architecture for efficient and geometrically accurate large-scale scene reconstruction.arXiv preprint arXiv:2503.23044,
-
[2]
Gui, H., Hu, L., Chen, R., Huang, M., Yin, Y ., Yang, J., Wu, Y ., Liu, C., Sun, Z., Zhang, X., et al. Balanced 3dgs: Gaussian-wise parallelism rendering with fine-grained tiling.arXiv preprint arXiv:2412.17378,
-
[3]
Virtual memory for 3d gaussian splatting.arXiv preprint arXiv:2506.19415,
Haberl, J., Fleck, P., and Arth, C. Virtual memory for 3d gaussian splatting.arXiv preprint arXiv:2506.19415,
-
[4]
Lee, D., Jeong, D., Lee, J. W., and Yoon, H. Gs-scale: Unlocking large-scale 3d gaussian splatting training via host offloading.arXiv preprint arXiv:2509.15645,
-
[5]
Li, B., Chen, S., Wang, L., Liao, K., Yan, S., and Xiong, Y . Retinags: Scalable training for dense scene ren- dering with billion-scale 3d gaussians.arXiv preprint arXiv:2406.11836,
-
[6]
Liao, K. Litegs: A high-performance modular frame- work for gaussian splatting training.arXiv preprint arXiv:2503.01199,
-
[7]
Rip-nerf: Anti-aliasing radiance fields with ripmap-encoded platonic solids
Liu, J., Hu, W., Yang, Z., Chen, J., Wang, G., Chen, X., Cai, Y ., Gao, H.-a., and Zhao, H. Rip-nerf: Anti-aliasing radiance fields with ripmap-encoded platonic solids. In ACM SIGGRAPH 2024 Conference Papers, pp. 1–11, 2024a. Liu, S., Tang, X., Li, Z., He, Y ., Ye, C., Liu, J., Huang, B., Zhou, S., and Wu, X. Occlugaussian: Occlusion- aware gaussian splat...
-
[8]
Liu, Y ., Luo, C., Fan, L., Wang, N., Peng, J., and Zhang, Z. Citygaussian: Real-time high-quality large-scale scene rendering with gaussians. InEuropean Conference on Computer Vision, pp. 265–282. Springer, 2024b. Liu, Y ., Luo, C., Mao, Z., Peng, J., and Zhang, Z. City- gaussianv2: Efficient and geometrically accurate re- construction for large-scale sc...
-
[9]
S., Goel, R., Kerbl, B., Steinberger, M., Carrasco, F
Mallick, S. S., Goel, R., Kerbl, B., Steinberger, M., Carrasco, F. V ., and De La Torre, F. Taming 3dgs: High-quality radiance fields with limited resources. InSIGGRAPH Asia 2024 Conference Papers, pp. 1–11,
work page 2024
-
[10]
Mohtashami, A., Stich, S., and Jaggi, M. Character- izing & finding good data orderings for fast conver- gence of sequential gradient methods.arXiv preprint arXiv:2202.01838,
-
[11]
arXiv preprint arXiv:2511.04283 , year=
Ren, S., Wen, T., Fang, Y ., and Lu, B. Fastgs: Training 3d gaussian splatting in 100 seconds.arXiv preprint arXiv:2511.04283,
-
[12]
Tao, M., Zhou, Y ., Xu, H., He, Z., Yang, Z., Zhang, Y ., Su, Z., Xu, L., Ma, Z., Fu, R., et al. Gs-cache: A gs-cache inference framework for large-scale gaussian splatting models.arXiv preprint arXiv:2502.14938,
-
[13]
Drone-assisted road gaussian splatting with cross-view uncertainty.arXiv preprint arXiv:2408.15242,
Zhang, S., Ye, B., Chen, X., Chen, Y ., Zhang, Z., Peng, C., Shi, Y ., and Zhao, H. Drone-assisted road gaussian splatting with cross-view uncertainty.arXiv preprint arXiv:2408.15242,
-
[14]
Clm: Removing the gpu mem- ory barrier for 3d gaussian splatting.arXiv preprint arXiv:2511.04951,
Zhao, H., Min, X., Liu, X., Gong, M., Li, Y ., Li, A., Xie, S., Li, J., and Panda, A. Clm: Removing the gpu mem- ory barrier for 3d gaussian splatting.arXiv preprint arXiv:2511.04951,
-
[15]
and with the two empirical properties exploited by TideGS: (i) visibility-induced sparsity, where each iteration updates only a small subset of Gaussians, and (ii)trajectory continuity, where consecutive views along a smooth camera path tend to have similar visibility and gradients. A.1.1. PROBLEMSETUP ANDNOTATION Let θ∈R d denote the concatenation of all...
work page 2022
-
[16]
A.2. Ordering Ablation: Shuffle vs. Trajectory To quantify the effect of trajectory ordering on optimization quality, we compare TideGS with randomized view shuffling and trajectory-ordered views on thebicyclescene from Mip-NeRF 360, which fits in GPU memory. Both variants use the same training views, loss, and optimization recipe; only the view presentat...
-
[17]
A.3. Dense Initialization Without Training-Time Densification Our large-scale MatrixCity experiments use fixed-size initializations and disable densification and pruning to isolate out-of-core memory management from adaptive model growth. To check whether this design choice materially changes reconstruction quality, we compare dense-initialized fixed-size...
work page 2025
-
[18]
and RetinaGS (Li et al., 2024). Distributed training can reduce wall-clock time when multiple GPUs, aggregate VRAM, and interconnect bandwidth are available, while TideGS lowers the hardware floor by trading additional storage hierarchy management for single-GPU scalability. Tab. 10 provides a bill-of-materials-style capacity-per-dollar comparison to cont...
work page 2024
-
[19]
from wall-clock and iteration-wise convergence perspectives. Table 10.Capacity-per-dollar operating point.The comparison contextualizes TideGS against a representative 4-GPU distributed in-memory setup; it is intended as an operating-point comparison rather than a claim of universal superiority. System Node cost Max trainable Gaussian primitives Gaussian ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.