Back to Parsimonious Latents: Learning Task-Centric World Models from Visual Foundations
Pith reviewed 2026-06-29 21:41 UTC · model grok-4.3
The pith
Linear projection plus contrastive alignment turns visual foundation embeddings into compact task-centric world models sufficient for offline planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
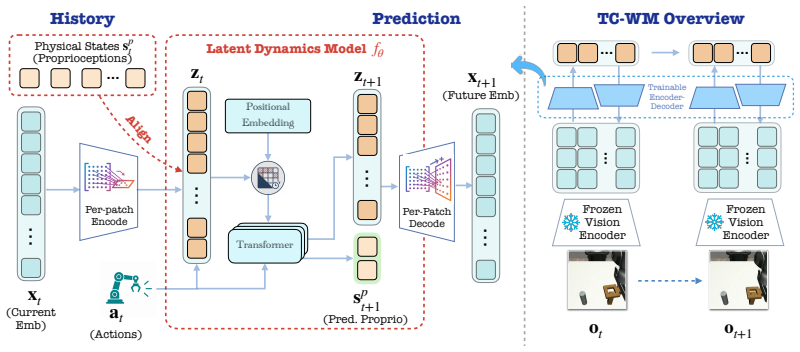
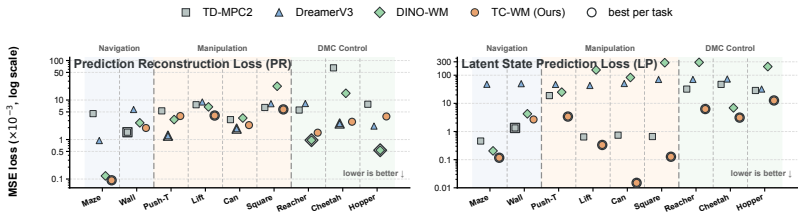
TC-WM linearly projects high-dimensional visual embeddings into a compact latent as the dynamic space, aligns a subspace with the agent's physical state via contrastive learning, and reconstructs embeddings to preserve useful visual structure. Theoretically, TC-WM suffices to identify the underlying task-centric latent factors up to a simple transformation. Empirically it achieves better world-modeling quality and more precise control than prior methods on Robomimic and D4RL.
What carries the argument
TC-WM, the linear projection of foundation embeddings combined with contrastive alignment to physical states and embedding reconstruction that isolates task-centric dynamics.
If this is right
- Test-time planning becomes feasible across diverse environments using only fixed offline trajectories.
- Task-centric latent factors are identifiable up to a simple transformation without explicit reward supervision.
- World modeling quality improves while retaining controllability from the aligned physical subspace.
- The approach combines the generality of foundation features with the compactness needed for precise control.
Where Pith is reading between the lines
- The same projection-plus-alignment pattern could adapt foundation models from other modalities such as audio or text for control tasks.
- Minimal supervision from physical state measurements might suffice to repurpose large pretrained models for new domains with limited data.
- If the linear projection step is replaced by a mildly nonlinear one, performance might improve in environments with more complex visual dynamics.
Load-bearing premise
The pretrained visual foundation model embeddings contain a semantic scaffold that a linear projection plus contrastive alignment to physical state can isolate as the task-centric dynamics without reward signals or online interaction.
What would settle it
An experiment in which the projected latents produce no improvement in planning accuracy or world-model prediction error over raw foundation embeddings or pixel-based baselines on D4RL tasks would falsify the identification claim.
Figures








read the original abstract
World models enable agents to predict future dynamics conditioned on actions, making the choice of latent representation central to planning and control. Such representations are often either learned directly from pixels with limited semantic structure or inherited from frozen visual foundation models with excessive task-irrelevant detail, yielding state spaces that are poorly matched to downstream planning and control. This is especially challenging in reward-free offline settings, where the model must learn from fixed trajectories without reward supervision or online interaction. To address this, we propose TC-WM, a framework for turning foundation-model embeddings into compact, task-sufficient world representations. The key design is to treat the pretrained embedding space as a semantic scaffold rather than as the final state space: TC-WM linearly projects high-dimensional visual embeddings into a compact latent as the dynamic space, aligns a subspace with the agent's physical state via contrastive learning, and reconstructs embeddings to preserve useful visual structure. This combines the generality of foundation features with the controllability of task-centric dynamics. Theoretically, we show that TC-WM suffices to identify the underlying task-centric latent factors up to a simple transformation. Empirically, TC-WM enables test-time planning across diverse environments (e.g., Robomimic and D4RL), achieving better world-modeling quality and more precise control than state-of-the-art approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TC-WM, a framework for learning compact task-centric world models from frozen pretrained visual foundation model embeddings in reward-free offline settings. The method applies a linear projection to the high-dimensional embeddings to form the dynamic latent space, uses contrastive learning to align a subspace with observed physical states, and adds an embedding reconstruction term to retain useful visual structure. It claims that this suffices to identify the underlying task-centric latent factors up to a simple transformation and reports improved world-modeling quality and control precision over SOTA baselines on Robomimic and D4RL benchmarks.
Significance. If the identification result is valid, the approach offers a way to obtain parsimonious, controllable latents that combine the semantic richness of foundation models with the task-specific structure needed for planning, without reward supervision or online interaction. This could improve sample efficiency in visual control by avoiding both pixel-level learning and overly detailed foundation embeddings.
major comments (2)
- [Theoretical analysis] Theoretical identification section: the central claim that TC-WM identifies task-centric latent factors up to a simple transformation rests on the assumption that foundation embeddings contain these factors in a linearly recoverable form and that contrastive alignment to physical state (from offline trajectories) isolates exactly the controllable subspace. The manuscript must state the precise assumptions (linearity, span of physical state over task dynamics, absence of nonlinear mixing) and provide a proof sketch or key derivation steps; without them the result cannot be verified and remains load-bearing for the theoretical contribution.
- [Experiments] Empirical section (results on Robomimic/D4RL): the abstract asserts superior world-modeling quality and more precise control, but without reported metrics (e.g., prediction MSE, planning success rate), baseline details, or ablations isolating the contrastive alignment term, it is impossible to assess whether the gains are attributable to the proposed components or to other factors. These quantitative results are required to support the empirical claims.
minor comments (2)
- Clarify the planning procedure used at test time (e.g., which optimizer or horizon) to support reproducibility of the control results.
- Define all acronyms (TC-WM, D4RL, etc.) on first use in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to improve clarity on both the theoretical assumptions and the empirical results.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical identification section: the central claim that TC-WM identifies task-centric latent factors up to a simple transformation rests on the assumption that foundation embeddings contain these factors in a linearly recoverable form and that contrastive alignment to physical state (from offline trajectories) isolates exactly the controllable subspace. The manuscript must state the precise assumptions (linearity, span of physical state over task dynamics, absence of nonlinear mixing) and provide a proof sketch or key derivation steps; without them the result cannot be verified and remains load-bearing for the theoretical contribution.
Authors: We agree that the identification claim requires explicit assumptions and a verifiable derivation. In the revised manuscript we will add a new subsection that enumerates the precise assumptions (linear recoverability of the task factors in the foundation embeddings, that the observed physical states span the controllable dynamics, and absence of nonlinear mixing) together with a concise proof sketch showing identification up to a linear transformation. revision: yes
-
Referee: [Experiments] Empirical section (results on Robomimic/D4RL): the abstract asserts superior world-modeling quality and more precise control, but without reported metrics (e.g., prediction MSE, planning success rate), baseline details, or ablations isolating the contrastive alignment term, it is impossible to assess whether the gains are attributable to the proposed components or to other factors. These quantitative results are required to support the empirical claims.
Authors: The full manuscript already reports prediction MSE, planning success rates, baseline details, and an ablation isolating the contrastive term. To make these results more immediately accessible we will add a consolidated metrics table in the main text and explicitly reference the ablation study in the experimental discussion. revision: partial
Circularity Check
No circularity; theoretical identification claim lacks equations or self-referential steps in provided text
full rationale
The abstract asserts that TC-WM suffices to identify task-centric latent factors up to a simple transformation, but supplies no equations, proof sketch, or derivation chain. No fitted parameters are renamed as predictions, no self-citations are invoked as load-bearing uniqueness results, and no ansatz or renaming of known results appears. Without explicit steps that reduce to inputs by construction, the claim cannot be shown to be circular; the derivation is treated as self-contained pending the full manuscript.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained visual foundation model embeddings contain sufficient semantic structure to serve as a scaffold for task-centric dynamics.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chat- topadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Am- mar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Back to the features: Dino as a foundation for video world models.arXiv preprint arXiv:2507.19468,
Federico Baldassarre, Marc Szafraniec, Basile Terver, Vasil Khalidov, Francisco Massa, Yann Le- Cun, Patrick Labatut, Maximilian Seitzer, and Piotr Bojanowski. Back to the features: Dino as a foundation for video world models.arXiv preprint arXiv:2507.19468,
-
[4]
VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning
Adrien Bardes, Jean Ponce, and Yann LeCun. Vicreg: Variance-invariance-covariance regularization for self-supervised learning.arXiv preprint arXiv:2105.04906,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video.arXiv preprint arXiv:2404.08471,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[8]
David Ha and J ¨urgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Mastering Diverse Domains through World Models
URL https://openreview.net/forum?id=0oabwyZbOu. Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URL https://openreview.net/forum?id=Oxh5CstDJU. Nicklas Hansen, Hao Su, and Xiaolong Wang. Learning massively multitask world models for continuous control.arXiv preprint arXiv:2511.19584,
-
[11]
arXiv preprint arXiv:2312.08782 (2023)
Yafei Hu, Quanting Xie, Vidhi Jain, Jonathan Francis, Jay Patrikar, Nikhil Keetha, Seungchan Kim, Yaqi Xie, Tianyi Zhang, Hao-Shu Fang, et al. Toward general-purpose robots via foundation models: A survey and meta-analysis.arXiv preprint arXiv:2312.08782,
-
[12]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei- Fei, Silvio Savarese, Yuke Zhu, and Roberto Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation.arXiv preprint arXiv:2108.03298,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predic- tive coding.arXiv preprint arXiv:1807.03748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Zero-shot visual imitation
Deepak Pathak, Parsa Mahmoudieh, Guanghao Luo, Pulkit Agrawal, Dian Chen, Yide Shentu, Evan Shelhamer, Jitendra Malik, Alexei A Efros, and Trevor Darrell. Zero-shot visual imitation. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 2050–2053,
2050
-
[16]
12 Oriane Sim´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Integrated architectures for learning, planning, and reacting based on approxi- mating dynamic programming
Richard S Sutton. Integrated architectures for learning, planning, and reacting based on approxi- mating dynamic programming. InMachine learning proceedings 1990, pages 216–224. Elsevier,
1990
-
[18]
Jinzhou Tang, Fan Feng, Minghao Fu, Wenjun Lin, Biwei Huang, and Keze Wang. Dreamsac: Learning hamiltonian world models via symmetry exploration.arXiv preprint arXiv:2603.07545,
-
[19]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Bud- den, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, et al. Deepmind control suite.arXiv preprint arXiv:1801.00690,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Yilin Wu, Anqi Li, Tucker Hermans, Fabio Ramos, Andrea Bajcsy, and Claudia P’erez-D’Arpino. Do what you say: Steering vision-language-action models via runtime reasoning-action alignment verification.arXiv preprint arXiv:2510.16281,
-
[21]
Latent diffusion planning for imitation learning.arXiv preprint arXiv:2504.16925,
Amber Xie, Oleh Rybkin, Dorsa Sadigh, and Chelsea Finn. Latent diffusion planning for imitation learning.arXiv preprint arXiv:2504.16925,
-
[22]
arXiv preprint arXiv:2510.18135 (2025)
Jiahan Zhang, Muqing Jiang, Nanru Dai, Taiming Lu, Arda Uzunoglu, Shunchi Zhang, Yana Wei, Jiahao Wang, Vishal M Patel, Paul Pu Liang, et al. World-in-world: World models in a closed-loop world.arXiv preprint arXiv:2510.18135,
-
[23]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with repre- sentation autoencoders.arXiv preprint arXiv:2510.11690,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
URLhttps://openreview.net/forum?id=D5RNACOZEI. Yuke Zhu, Josiah Wong, Ajay Mandlekar, Roberto Mart´ın-Mart´ın, Abhishek Joshi, Soroush Nasiri- any, and Yifeng Zhu. robosuite: A modular simulation framework and benchmark for robot learning.arXiv preprint arXiv:2009.12293,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[25]
Back to Parsimonious Latents: Learning Task-Centric World Models from Visual Foundations
13 Appendixof “Back to Parsimonious Latents: Learning Task-Centric World Models from Visual Foundations” A Experiment Details 15 A.1 Environments and Dataset Collection . . . . . . . . . . . . . . . . . . . . . . . . . 15 A.2 Details of Selected Visual Foundation Models . . . . . . . . . . . . . . . . . . . . 15 A.3 Pipeline of Planning on Manipulation Ta...
2025
-
[26]
For each task we collect trajectories over multiple rounds, with actions produced by the TD-MPC2 policy conditioned on the current observation
in the DeepMind Control Suite. For each task we collect trajectories over multiple rounds, with actions produced by the TD-MPC2 policy conditioned on the current observation. We record rendered frames and low-dimensional state observations at each step. To ensure demonstration quality we apply a return-based filter: episodes are accepted only if their tot...
2025
-
[27]
Following standard practice, we discard the CLS token and any register tokens, retaining only the patch tokens of the shapeR B×N×768 as the final visual representation
The raw output has shape(B,1+R+N, D), whereN= (H/16)·(W/16)denotes the number of patch tokens andRthe number of register tokens. Following standard practice, we discard the CLS token and any register tokens, retaining only the patch tokens of the shapeR B×N×768 as the final visual representation. Cosmos CI Tokenizer.For Cosmos, we use theNVIDIA/Cosmos-0.1...
2025
-
[28]
, H p, and the trajectory costC i is computed according to the objective above
(4)Trajectory Rollout.For each sampled sequence, the learned world model predicts the latent rollout: ˆzt =f t θ(z0,a 0:t−1), t= 1, . . . , H p, and the trajectory costC i is computed according to the objective above. (5)Elite Selection and Update.The topKtrajectories with the lowest costs are selected as elites, and the sampling distribution is updated b...
2025
-
[29]
dynamics on pretrained encoders,
Section B.1 discusses the motivation, the underlying hierarchical generative model, the assumptions, and an empirical sanity check on Lift. Section B.2 contains the full proof. B.1 Illustration and Analysis Understanding when and how task-centric representation can be learned from visual foundation models is critical for modern world-model training. We st...
2023
-
[30]
w/o Embed recon
We now bring the present embeddingxt into the picture. By the second relation in (CI), the four-way joint factorises withx t entering only throughp(x t |z t): p(xt−H:t−1 ,x t,x t+1:t+H) = Z Z p(xt−H:t−1 |z t)p(x t |z t)p(x t+1:t+H |z t)p(z t) dzt. Dividing by the marginalp(x t+1:t+H)and treatingx t as a parameter (so thatp(x t |z t)becomes a zt-indexed sc...
1990
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.