Empirical Evaluation of Multi-Modal Touch Detection in Over-the-Shoulder Video Surveillance
Pith reviewed 2026-06-30 06:59 UTC · model grok-4.3
The pith
A multi-modal touch detector for over-the-shoulder video fails to reconstruct keystrokes reliably outside staged tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
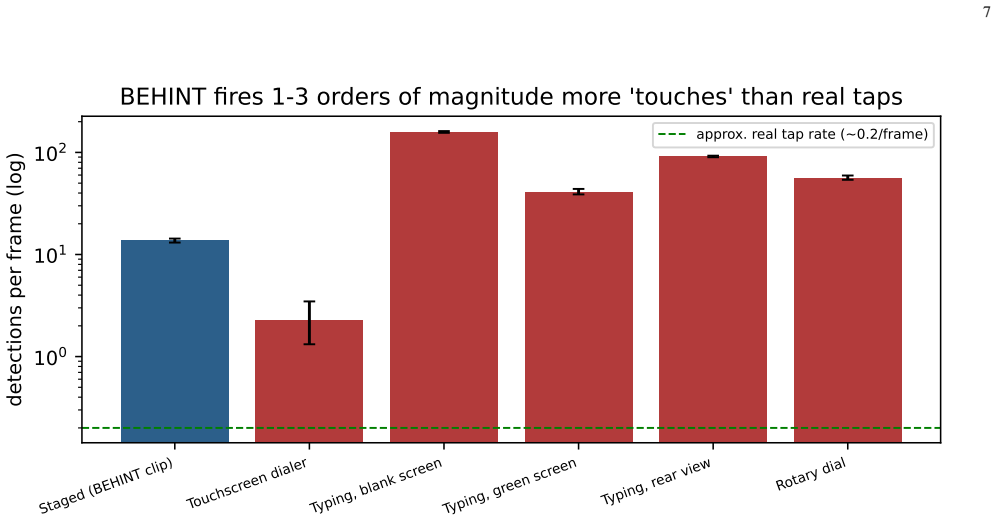
The combined MediaPipe-landmark, HSV-skin, motion-differencing, and Canny-edge pipeline achieves only 16.7 percent F1 and 3 percent sequence similarity on a staged first-person passcode video; on five real third-person videos the detector emits a median 57 touch points per frame because the skin filter responds to the whole hand rather than fingertip contact, so the staged keystroke result does not survive contact with uncontrolled footage.
What carries the argument
Four parallel detection modalities (MediaPipe hand landmarks, HSV skin filtering, temporal frame differencing, shape-guided Canny edges) whose outputs are thresholded and mapped to a reference screen layout to produce touch sequences.
If this is right
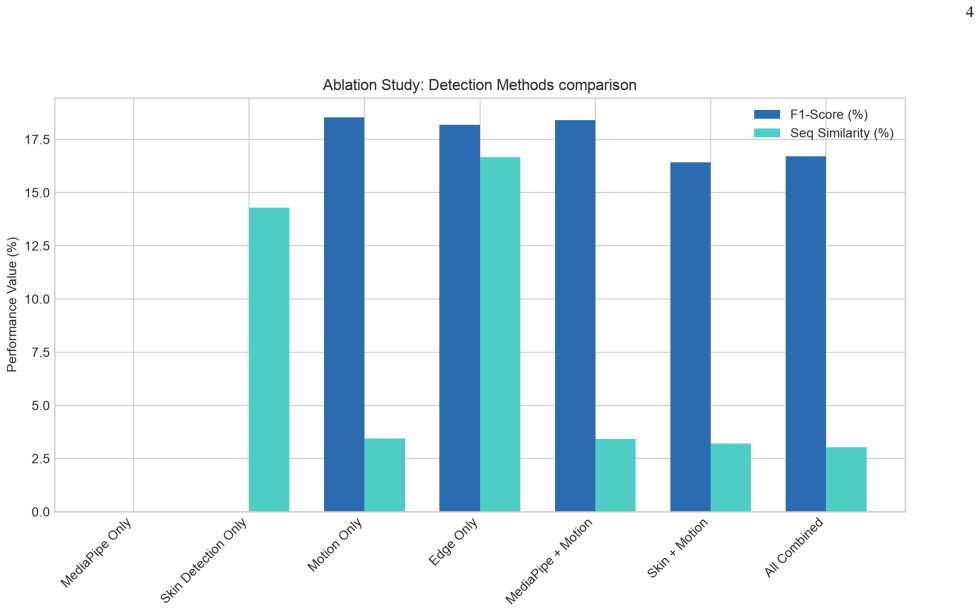
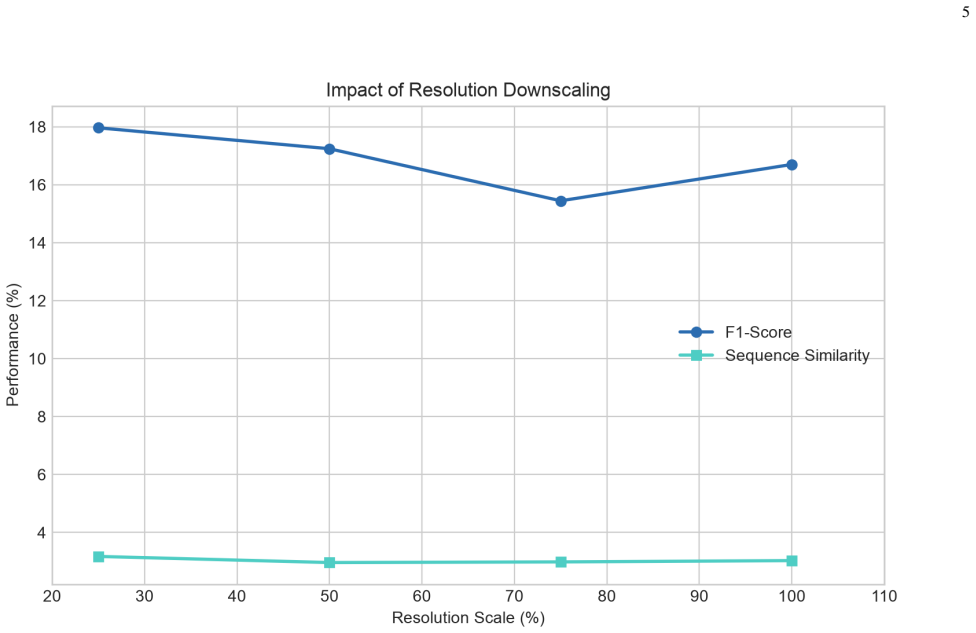
- Ablation and resolution-decay tests show that no single modality exceeds roughly 18 percent F1 even under ideal conditions.
- The skin filter's over-response produces between one and three orders of magnitude more candidate touches than actual keystrokes.
- Sequence similarity after mapping to an iOS layout drops to 3 percent once coordinate noise is introduced.
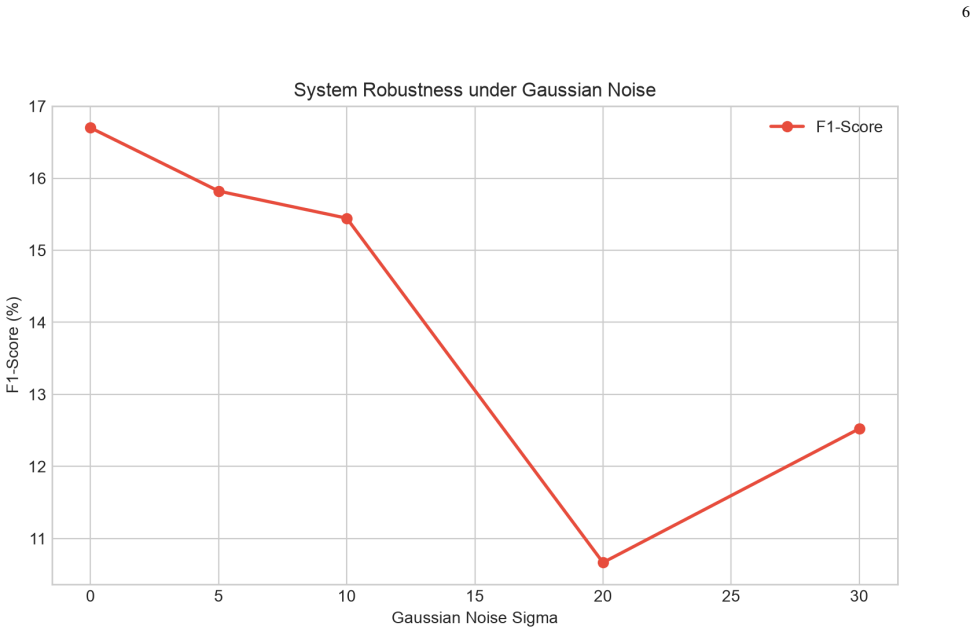
- Proximity-threshold tuning and noise-sensitivity sweeps map the narrow operational envelope of the current pipeline.
Where Pith is reading between the lines
- Future detectors would need an explicit fingertip-isolation step before skin or edge cues are applied.
- The same failure mode would appear in any surveillance pipeline that relies on whole-hand skin segmentation for fine motor events.
- Sequence reconstruction accuracy may remain low even if per-frame false-positive rate is reduced, because coordinate jitter compounds across frames.
Load-bearing premise
The five real third-person videos are representative enough to show that the skin filter's response to the whole hand is a general failure mode.
What would settle it
A larger collection of uncontrolled third-person videos in which the detector produces a number of touch points per frame close to the actual tap rate would falsify the generalization claim.
Figures

read the original abstract
Video Intelligence Surveillance (VIDINT) on over-the-shoulder footage is a proposed vector for monitoring human-computer interaction patterns without direct screen recording access. In this paper, we evaluate a Behavioral Intelligence (BEHINT) touch-detection framework designed to reconstruct keystroke events on mobile keypad interfaces from physical finger interactions. Our system integrates four parallel detection modalities: (1) anatomical hand landmarks via MediaPipe, (2) HSV skin color filtering, (3) temporal frame differencing for motion detection, and (4) shape-guided Canny edge analysis. We map relative touch coordinates to a reference screen layout to reconstruct typing sequences. Evaluation on a 120-frame first-person staged video of passcode entry reveals that while MediaPipe and Skin Detection fail to run autonomously due to partial hand occlusion and ambient noise, Motion-Only and Edge-Only configurations achieve F1-scores of 18.5% and 18.2%, respectively. The combined multi-modal configuration achieves an F1-score of 16.7% and a sequence similarity of 3.0% when mapped to the iOS passcode layout. We conduct ablation, resolution decay, noise sensitivity, and proximity threshold tuning to characterize the system's operational envelope. We then audit generalization on 5 real, publicly licensed third-person phone videos and find that the detector emits a median of 57 touch points per frame (peaking at 205), one to three orders of magnitude more than the rate of real taps, because the skin filter responds to the whole hand rather than to fingertip contact. The staged keystroke result does not survive contact with uncontrolled footage; the system does not achieve reliable keystroke reconstruction outside the calibrated staged setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a multi-modal touch detection system (MediaPipe hand landmarks, HSV skin filtering, temporal frame differencing, and shape-guided Canny edges) for reconstructing keystrokes from over-the-shoulder video fails to generalize. On a 120-frame staged first-person passcode video, motion-only and edge-only achieve F1 scores of 18.5% and 18.2%, while the combined system reaches only 16.7% F1 and 3.0% sequence similarity on an iOS layout. Ablations cover resolution decay, noise, and proximity threshold. On five real third-person videos, the detector emits a median 57 detections per frame (peak 205), orders of magnitude above actual taps, because the skin filter responds to the whole hand rather than fingertip contact. Conclusion: reliable reconstruction does not hold outside the calibrated staged setting.
Significance. If the results hold, the work supplies a direct, quantitative demonstration of generalization failure in multi-modal CV for touch detection, contrasting controlled staged performance against uncontrolled real footage with concrete metrics (F1, sequence similarity, per-frame counts). The mechanistic attribution to the skin filter, together with the reported ablations on resolution, noise sensitivity, and threshold tuning, delineates operational limits and supplies falsifiable evidence that could steer future VIDINT/BEHINT research away from skin- and landmark-heavy pipelines. The empirical focus on failure rather than claimed success is a constructive contribution.
minor comments (2)
- The sequence similarity metric (reported as 3.0% when mapped to the iOS passcode layout) is not defined or referenced; an explicit formula or citation would aid replication.
- In the real-video audit, reporting only the median and peak detection counts without per-video breakdown or variance leaves the consistency of the skin-filter failure mode less transparent.
Simulated Author's Rebuttal
We thank the referee for the detailed summary, positive significance assessment, and recommendation to accept. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper is a purely empirical evaluation reporting direct measurements (F1-scores, sequence similarity, detection counts) from staged and real-video experiments. No derivation chain, fitted parameters, predictions, or self-citations are present; all metrics are computed from the described detection modalities and ablation tests without reduction to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- proximity threshold
axioms (1)
- standard math MediaPipe hand landmarks, HSV skin segmentation, temporal frame differencing, and Canny edge detection perform as documented in their original references under the tested conditions
Reference graph
Works this paper leans on
-
[1]
Blind recognition of touched keys on mobile devices,
Q. Yue, Z. Ling, X. Fu, B. Liu, K. Ren, and W. Zhao, “Blind recognition of touched keys on mobile devices,” inProceedings of the 21st ACM SIGSAC Conference on Computer and Communications Security. ACM, 2014, pp. 1403–1414
2014
-
[2]
Clearshot: Eavesdropping on keyboard input from video,
D. Balzarotti, M. Cova, and G. Vigna, “Clearshot: Eavesdropping on keyboard input from video,” inProceedings of the 29th IEEE Symposium on Security and Privacy. IEEE Computer Society, May 2008, pp. 170–183
2008
-
[3]
Z. Tong, Y . Song, J. Wang, and L. Wang, “VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022, arXiv:2203.12602
-
[4]
EgoTouch: On-body touch input using ar/vr headset cameras,
V . Mollyn and C. Harrison, “EgoTouch: On-body touch input using ar/vr headset cameras,” inProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology, ser. UIST ’24, 2024. [Online]. Available: https://doi.org/10.1145/3654777.3676455
-
[5]
V-Hands: Touchscreen-based hand tracking for remote whiteboard interaction,
X. Liu, Y . Zhang, and X. Tong, “V-Hands: Touchscreen-based hand tracking for remote whiteboard interaction,”arXiv preprint arXiv:2409.13347, 2024. [Online]. Available: https://arxiv.org/abs/2409.13347
-
[7]
Detecting Precise Hand Touch Moments in Egocentric Video
[Online]. Available: https://arxiv.org/abs/2604.12343
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
SurfaceXR: Fusing smartwatch imus and egocentric hand pose for seamless surface interactions,
V . Xu, B. Chen, E. J. Gonzalez, A. Colac ¸o, H. Hoffmann, M. Gonzalez-Franco, and K. Ahuja, “SurfaceXR: Fusing smartwatch imus and egocentric hand pose for seamless surface interactions,”arXiv preprint arXiv:2603.19529, 2026. [Online]. Available: https://arxiv.org/abs/2603.19529
-
[9]
iSpy: Automatic reconstruction of typed input from compromising reflections,
R. Raguram, A. M. White, D. Goswami, F. Monrose, and J.-M. Frahm, “iSpy: Automatic reconstruction of typed input from compromising reflections,” inACM Conference on Computer and Communications Security (CCS), 2011, pp. 527–536
2011
-
[10]
PlaceRaider: Virtual Theft in Physical Spaces with Smartphones
R. Templeman, Z. Rahman, D. Crandall, and A. Kapadia, “PlaceRaider: Virtual theft in physical spaces with smartphones,” inNetwork and Distributed System Security Symposium (NDSS), 2013, arXiv:1209.5982
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[11]
Zoom on the keystrokes: Exploiting video calls for keystroke inference attacks,
M. Sabra, A. Maiti, and M. Jadliwala, “Zoom on the keystrokes: Exploiting video calls for keystroke inference attacks,” inNetwork and Distributed System Security Symposium (NDSS), 2021, arXiv:2010.12078
-
[12]
Revisiting the threat space for vision-based keystroke inference attacks,
J. Lim, T. Price, F. Monrose, and J.-M. Frahm, “Revisiting the threat space for vision-based keystroke inference attacks,” inEuropean Conference on Computer Vision (ECCV) Workshops, 2020, arXiv:2009.05796
-
[13]
J. Lim, J.-M. Frahm, and F. Monrose, “Leveraging disentangled representations to improve vision-based keystroke inference attacks under low data constraints,” inACM Conference on Data and Application Security and Privacy (CODASPY), 2022, arXiv:2204.02494
-
[14]
Cracking android pattern lock in five attempts,
G. Ye, Z. Tang, D. Fang, X. Chen, K. I. Kim, B. Taylor, and Z. Wang, “Cracking android pattern lock in five attempts,” inNetwork and Distributed System Security Symposium (NDSS), 2017
2017
-
[15]
Beware, your hands reveal your secrets!
D. Shukla, R. Kumar, A. Serwadda, and V . V . Phoha, “Beware, your hands reveal your secrets!” inACM Conference on Computer and Communications Security (CCS), 2014, pp. 904–917
2014
-
[16]
VISIBLE: Video-assisted keystroke inference from tablet backside motion,
J. Sun, X. Jin, Y . Chen, J. Zhang, Y . Zhang, and R. Zhang, “VISIBLE: Video-assisted keystroke inference from tablet backside motion,” inNetwork and Distributed System Security Symposium (NDSS), 2016. 9
2016
- [17]
-
[18]
R. C. Gonzalez and R. E. Woods,Digital Image Processing, 4th ed. Pearson, 2018
2018
-
[19]
Open source computer vision library,
Itseez, “Open source computer vision library,” https://github.com/itseez/opencv, 2015
2015
-
[20]
A computational approach to edge detection,
J. Canny, “A computational approach to edge detection,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. PAMI-8, no. 6, pp. 679–698, 1986
1986
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.