A Data-Enabled Primal-Dual Approach for Policy Learning with SDP Formulations
Pith reviewed 2026-07-02 07:38 UTC · model grok-4.3
The pith
A primal-dual online framework updates policies from closed-loop data for SDP-based control synthesis in linear discrete-time systems, with local linear tracking and global ergodic convergence guarantees under persistency of excitation and slow data variation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under persistency of excitation, suitable SDP regularity conditions, and sufficiently slow data variation, we establish a local linear tracking result up to residual terms governed by the Sim-to-Real Gap and the Difference-of-Signal. A global ergodic convergence bound is also derived for arbitrary initialization.
Load-bearing premise
The data variation is sufficiently slow (so that the Difference-of-Signal remains small) and the SDP coefficients satisfy suitable regularity conditions; these enter the proof of the local linear tracking result and are stated as prerequisites in the abstract.
Figures
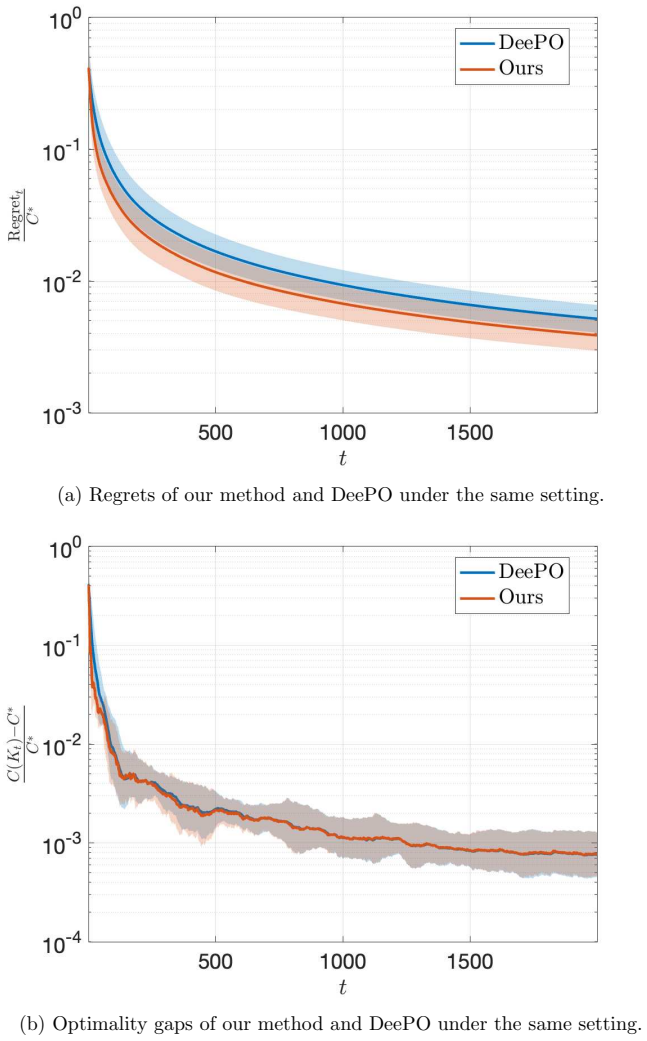
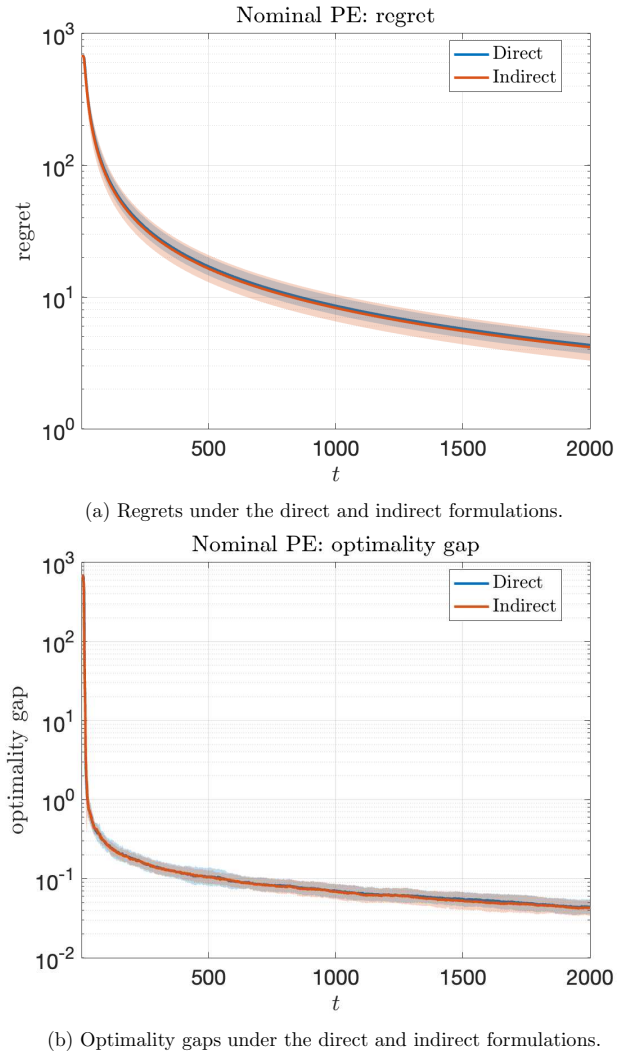
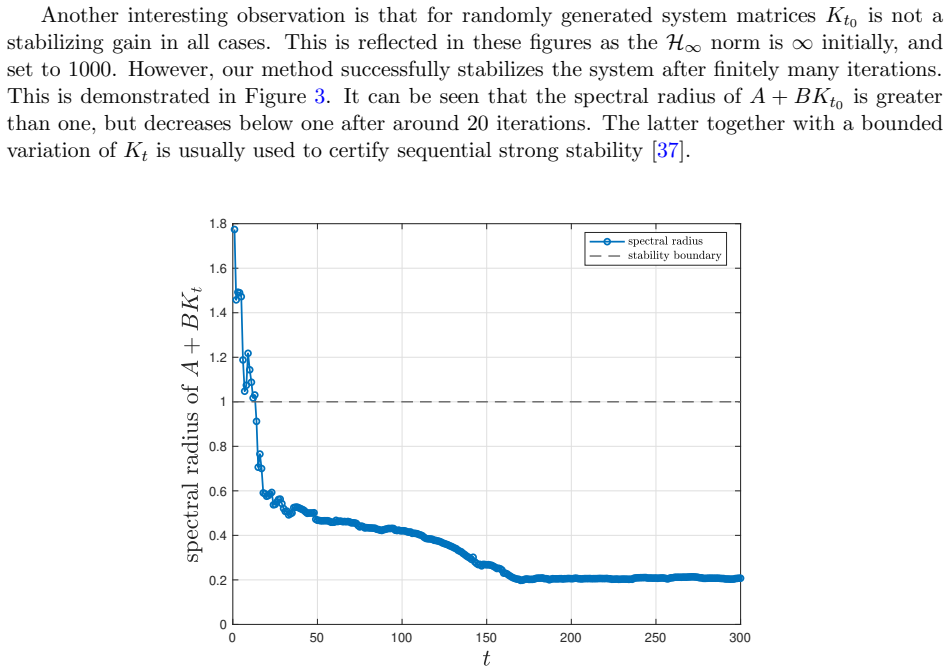
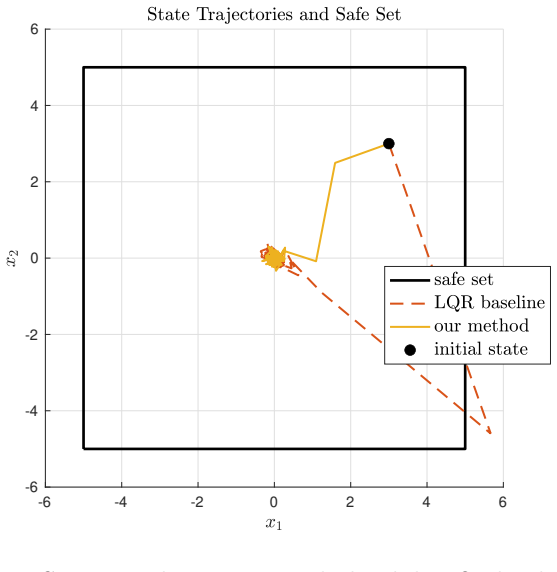
read the original abstract
This paper develops a data-enabled primal-dual framework for learning optimal control policies for unknown linear discrete-time systems from online data. The proposed approach views the data-dependent control synthesis problem as a time-varying semidefinite program (SDP) whose coefficients are recursively updated from online closed-loop measurements. Instead of repeatedly solving a full SDP as new data arrive, the policy is updated online through lightweight primal-dual iterations, each consisting of a linear equation solve and a projection onto the positive semidefinite cone. The framework applies to both direct and indirect data-driven formulations and covers a broad class of control objectives, including LQR, $H_\infty$ control, and safety-critical control. To characterize the coupling between online optimization and closed-loop data generation, we introduce two data-dependent quantities: the Sim-to-Real Gap, which measures the mismatch between noisy and noiseless data-induced SDPs, and the Difference-of-Signal, which measures the temporal variation of the SDP coefficients. Under persistency of excitation, suitable SDP regularity conditions, and sufficiently slow data variation, we establish a local linear tracking result up to residual terms governed by the latter two quantities. A global ergodic convergence bound is also derived for arbitrary initialization. Numerical examples on LQR, $H_\infty$ control, and safe exploration demonstrate that the proposed method can efficiently improve control performance from online data while accommodating SDP constraints beyond the well-explored LQR policy-gradient formulations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a data-enabled primal-dual framework for online policy learning in unknown linear discrete-time systems. Control synthesis is cast as a time-varying SDP whose coefficients are updated recursively from closed-loop measurements; policy updates are performed via lightweight primal-dual iterations (linear solve plus PSD projection) rather than repeated full SDP solves. The framework covers direct and indirect data-driven formulations and a range of objectives (LQR, H∞, safety-critical). Two data-dependent quantities—the Sim-to-Real Gap and the Difference-of-Signal—are introduced to quantify the coupling between optimization and data generation. Under persistency of excitation, SDP regularity conditions, and sufficiently slow data variation, the paper claims a local linear tracking result (with residuals governed by the two quantities) and a global ergodic convergence bound for arbitrary initialization. Numerical examples on LQR, H∞ control, and safe exploration are presented.
Significance. If the stated tracking and ergodic bounds hold, the work supplies a computationally efficient online algorithm with explicit convergence guarantees for a broader class of SDP-based data-driven control problems than existing policy-gradient approaches. The introduction of the Sim-to-Real Gap and Difference-of-Signal as analysis tools offers a concrete way to separate measurement mismatch from temporal variation, which could be useful for other online data-driven methods. The numerical examples provide initial evidence of practical performance.
major comments (2)
- [§4] §4 (Analysis): The local linear tracking result is stated to hold up to residual terms governed by the Sim-to-Real Gap and Difference-of-Signal, yet the manuscript provides no explicit quantitative bound on these residuals in terms of noise level, excitation parameters, or the rate of data variation. Without such an explicit expression (e.g., an inequality relating the tracking error to the two quantities and the persistency-of-excitation constant), it is impossible to verify that the residuals remain small under the stated assumptions.
- [§4.2, Theorem 1] §4.2, Theorem 1: The global ergodic convergence bound is claimed for arbitrary initialization, but the text does not clarify whether this bound continues to hold when the slow-variation assumption required for the local tracking result is relaxed, or whether the two results share the same SDP regularity conditions. This leaves open whether the ergodic bound is truly independent of the local-tracking hypotheses.
minor comments (2)
- [Numerical examples] The numerical examples section would benefit from reporting the observed Sim-to-Real Gap and Difference-of-Signal values alongside the performance metrics, to allow readers to correlate the empirical behavior with the theoretical residuals.
- [§3] Notation for the primal-dual variables and the projection operator onto the PSD cone should be introduced once and used consistently; several equations reuse symbols without redefinition.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive evaluation of the work's significance. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and bounds.
read point-by-point responses
-
Referee: [§4] §4 (Analysis): The local linear tracking result is stated to hold up to residual terms governed by the Sim-to-Real Gap and Difference-of-Signal, yet the manuscript provides no explicit quantitative bound on these residuals in terms of noise level, excitation parameters, or the rate of data variation. Without such an explicit expression (e.g., an inequality relating the tracking error to the two quantities and the persistency-of-excitation constant), it is impossible to verify that the residuals remain small under the stated assumptions.
Authors: We agree that an explicit quantitative bound relating the tracking error to the Sim-to-Real Gap, Difference-of-Signal, noise level, persistency-of-excitation constant, and data variation rate would make the result easier to verify. The current analysis establishes that the residuals are governed by these two quantities (which implicitly depend on noise and excitation via the data generation process), but does not expand this into a fully explicit inequality. In the revision we will derive and insert such a bound in Section 4. revision: yes
-
Referee: [§4.2, Theorem 1] §4.2, Theorem 1: The global ergodic convergence bound is claimed for arbitrary initialization, but the text does not clarify whether this bound continues to hold when the slow-variation assumption required for the local tracking result is relaxed, or whether the two results share the same SDP regularity conditions. This leaves open whether the ergodic bound is truly independent of the local-tracking hypotheses.
Authors: The global ergodic convergence bound of Theorem 1 is derived under persistency of excitation and the SDP regularity conditions only; it does not invoke the slow-variation assumption used exclusively for the local linear tracking result. The ergodic bound follows from averaging arguments that hold for arbitrary initialization and is therefore independent of the local-tracking hypotheses. The SDP regularity conditions are identical for both results. We will revise the text to state these distinctions explicitly. revision: yes
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Persistency of excitation of the online closed-loop data
- domain assumption Suitable SDP regularity conditions on the data-induced problems
- domain assumption Sufficiently slow temporal variation of the SDP coefficients
invented entities (2)
-
Sim-to-Real Gap
no independent evidence
-
Difference-of-Signal
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A note on persistency of excitation,
J. C. Willems, P. Rapisarda, I. Markovsky, and B. L. De Moo r, “A note on persistency of excitation,” Systems & Control Letters , vol. 54, no. 4, pp. 325–329, 2005
2005
-
[2]
Data-enabled pr edictive control: In the shallows of the deepc,
J. Coulson, J. Lygeros, and F. D¨ orfler, “Data-enabled pr edictive control: In the shallows of the deepc,” in 2019 18th European control conference (ECC) , pp. 307–312, IEEE, 2019
2019
-
[3]
Regularized and distributionally robust data-enabled predictive control,
J. Coulson, J. Lygeros, and F. D¨ orfler, “Regularized and distributionally robust data-enabled predictive control,” in 2019 IEEE 58th Conference on Decision and Control (CDC) , pp. 2696– 2701, IEEE, 2019
2019
-
[4]
Data-driven model predictive control with stability and robustness guarantees,
J. Berberich, J. K¨ ohler, M. A. M¨ uller, and F. Allg¨ ower, “Data-driven model predictive control with stability and robustness guarantees,” IEEE transactions on automatic control , vol. 66, no. 4, pp. 1702–1717, 2020
2020
-
[5]
Formulas for data-driven contr ol: Stabilization, optimality, and robustness,
C. De Persis and P. Tesi, “Formulas for data-driven contr ol: Stabilization, optimality, and robustness,” IEEE Transactions on Automatic Control , vol. 65, no. 3, pp. 909–924, 2019
2019
-
[6]
R obust data-driven state-feedback design,
J. Berberich, A. Koch, C. W. Scherer, and F. Allg¨ ower, “R obust data-driven state-feedback design,” in Proceedings of the 2020 American Control Conference , pp. 1532–1538, 2020
2020
-
[7]
On the certainty-e quivalence approach to direct data- driven lqr design,
F. D¨ orfler, P. Tesi, and C. De Persis, “On the certainty-e quivalence approach to direct data- driven lqr design,” IEEE Transactions on Automatic Control , vol. 68, no. 12, pp. 7989–7996, 2023
2023
-
[8]
Data informativity: A new perspective on data-driven analysis and control,
H. J. Van Waarde, J. Eising, H. L. Trentelman, and M. K. Cam libel, “Data informativity: A new perspective on data-driven analysis and control,” IEEE Transactions on Automatic Control, vol. 65, no. 11, pp. 4753–4768, 2020
2020
-
[9]
Regret bo unds for robust adaptive control of the linear quadratic regulator,
S. Dean, H. Mania, N. Matni, B. Recht, and S. Tu, “Regret bo unds for robust adaptive control of the linear quadratic regulator,” Advances in Neural Information Processing Systems , vol. 31, 2018
2018
-
[10]
Minimax adaptive control for a finite set of linear systems,
A. Rantzer, “Minimax adaptive control for a finite set of linear systems,” in Learning for Dynamics and Control , pp. 893–904, PMLR, 2021
2021
-
[11]
Data-enable d policy optimization for direct adap- tive learning of the lqr,
F. Zhao, F. D¨ orfler, A. Chiuso, and K. You, “Data-enable d policy optimization for direct adap- tive learning of the lqr,” IEEE Transactions on Automatic Control , vol. 70, no. 11, pp. 7217– 7232, 2025. 33
2025
-
[12]
Policy gradient ada ptive control for the lqr: Indirect and direct approaches,
F. Zhao, A. Chiuso, and F. D¨ orfler, “Policy gradient ada ptive control for the lqr: Indirect and direct approaches,” arXiv preprint arXiv:2505.03706 , 2025
-
[13]
An adaptive data- enabled policy optimization approach for autonomous bicyc le control,
N. Persson, F. Zhao, M. Kaheni, F. D¨ orfler, and A. V. Papa dopoulos, “An adaptive data- enabled policy optimization approach for autonomous bicyc le control,” IEEE Transactions on Control Systems Technology, 2026
2026
-
[14]
Benign nonconvex la ndscapes in optimal and robust control, part i: Global optimality,
Y. Zheng, C.-F. R. Pai, and Y. Tang, “Benign nonconvex la ndscapes in optimal and robust control, part i: Global optimality,” IEEE Transactions on Automatic Control , 2026
2026
-
[15]
Online convex programming and generali zed infinitesimal gradient ascent,
M. Zinkevich, “Online convex programming and generali zed infinitesimal gradient ascent,” in Proceedings of the Twentieth International Conference on Mach ine Learning, pp. 928–936, 2003
2003
-
[16]
Online convex optimizatio n in dynamic environments,
E. C. Hall and R. M. Willett, “Online convex optimizatio n in dynamic environments,” IEEE Journal of Selected Topics in Signal Processing , vol. 9, no. 4, pp. 647–662, 2015
2015
-
[17]
Adaptive online learni ng in dynamic environments,
L. Zhang, S. Lu, and Z.-H. Zhou, “Adaptive online learni ng in dynamic environments,” in Advances in Neural Information Processing Systems , vol. 31, pp. 1330–1340, 2018
2018
-
[18]
Dynamic regret of convex and smooth functions,
P. Zhao, Y.-J. Zhang, L. Zhang, and Z.-H. Zhou, “Dynamic regret of convex and smooth functions,” in Advances in Neural Information Processing Systems , vol. 33, pp. 12510–12520, 2020
2020
-
[19]
Online alternating direction method,
H. Wang and A. Banerjee, “Online alternating direction method,” in Proceedings of the 29th International Conference on Machine Learning , vol. 2, pp. 1119–1126, 2012
2012
-
[20]
Online proximal- ADMM for time-varying constrained optimization,
Y. Zhang, E. Dall’Anese, and M. Hong, “Online proximal- ADMM for time-varying constrained optimization,” IEEE Transactions on Signal and Information Processing over N etworks, vol. 7, pp. 144–155, 2021
2021
-
[21]
Time-varying convex optimization: Time-structured algorithms and appl ications,
A. Simonetto, E. Dall’Anese, S. Paternain, G. Leus, and G. B. Giannakis, “Time-varying convex optimization: Time-structured algorithms and appl ications,” Proceedings of the IEEE , vol. 108, no. 11, pp. 2032–2048, 2020
2032
-
[22]
Semidefinite programming,
C. Helmberg, “Semidefinite programming,” in Handbook of Combinatorial Optimization (D.-Z. Du and P. M. Pardalos, eds.), pp. 289–319, Springer, 2000
2000
-
[23]
Warmstarting the homogeneous and s elf-dual interior point method for linear and conic quadratic problems,
A. Skajaa and Y. Ye, “Warmstarting the homogeneous and s elf-dual interior point method for linear and conic quadratic problems,” Mathematical Programming Computation, vol. 7, no. 1, pp. 25–48, 2015
2015
-
[24]
S. Boyd, L. El Ghaoui, E. Feron, and V. Balakrishnan, Linear matrix inequalities in system and control theory . SIAM, 1994
1994
-
[25]
Inp ut perturbations for adaptive control and learning,
M. K. S. Faradonbeh, A. Tewari, and G. Michailidis, “Inp ut perturbations for adaptive control and learning,” Automatica, vol. 117, p. 108950, 2020
2020
-
[26]
Alternating direction augmented Lagrangian methods for semidefinite programming,
Z. Wen, D. Goldfarb, and W. Yin, “Alternating direction augmented Lagrangian methods for semidefinite programming,” Mathematical Programming Computation , vol. 2, no. 3, pp. 203– 230, 2010
2010
-
[27]
Comp lementarity and nondegeneracy in semidefinite programming,
F. Alizadeh, J.-P. A. Haeberly, and M. L. Overton, “Comp lementarity and nondegeneracy in semidefinite programming,” Mathematical programming, vol. 77, no. 1, pp. 111–128, 1997. 34
1997
-
[28]
Constraint nondegeneracy, stron g regularity, and nonsingularity in semidefinite programming,
Z. X. Chan and D. Sun, “Constraint nondegeneracy, stron g regularity, and nonsingularity in semidefinite programming,” SIAM Journal on optimization , vol. 19, no. 1, pp. 370–396, 2008
2008
-
[29]
Prim al-dual interior-point methods for semidefinite programming: convergence rates, stability an d numerical results,
F. Alizadeh, J.-P. A. Haeberly, and M. L. Overton, “Prim al-dual interior-point methods for semidefinite programming: convergence rates, stability an d numerical results,” SIAM journal on optimization , vol. 8, no. 3, pp. 746–768, 1998
1998
-
[30]
Onlin e learning with inexact proximal online gradient descent algorithms,
R. Dixit, A. S. Bedi, R. Tripathi, and K. Rajawat, “Onlin e learning with inexact proximal online gradient descent algorithms,” IEEE Transactions on Signal Processing , vol. 67, no. 5, pp. 1338–1352, 2019
2019
-
[31]
Online optimization: Com- peting with dynamic comparators,
A. Jadbabaie, A. Rakhlin, S. Shahrampour, and K. Sridha ran, “Online optimization: Com- peting with dynamic comparators,” in Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics , vol. 38 of Proceedings of Machine Learning Research , pp. 398–406, PMLR, 2015
2015
-
[32]
Global con vergence of policy gradient methods for the linear quadratic regulator,
M. Fazel, R. Ge, S. M. Kakade, and M. Mesbahi, “Global con vergence of policy gradient methods for the linear quadratic regulator,” in Proceedings of the 35th International Conference on Machine Learning , vol. 80 of Proceedings of Machine Learning Research , pp. 1467–1476, PMLR, 2018
2018
-
[33]
Derivative-free methods for policy optimization: Guaran tees for linear quadratic systems,
D. Malik, A. Pananjady, K. Bhatia, K. Khamaru, P. L. Bart lett, and M. J. Wainwright, “Derivative-free methods for policy optimization: Guaran tees for linear quadratic systems,” Journal of Machine Learning Research , vol. 21, no. 21, pp. 1–51, 2020
2020
-
[34]
A model-free first-order method for linear quadratic regulator with ˜O(1/ε ) sampling complexity,
C. Ju, G. Kotsalis, and G. Lan, “A model-free first-order method for linear quadratic regulator with ˜O(1/ε ) sampling complexity,” SIAM Journal on Optimization , vol. 35, no. 2, pp. 1232– 1259, 2025
2025
-
[35]
On the o(1/n) convergence rate of the d ouglas–rachford alternating direction method,
B. He and X. Yuan, “On the o(1/n) convergence rate of the d ouglas–rachford alternating direction method,” SIAM Journal on Numerical Analysis , vol. 50, no. 2, pp. 700–709, 2012
2012
-
[36]
A linear matrix inequality approach to H∞ control,
P. Gahinet and P. Apkarian, “A linear matrix inequality approach to H∞ control,” Interna- tional Journal of Robust and Nonlinear Control , vol. 4, no. 4, pp. 421–448, 1994
1994
-
[37]
Online linear quadratic control,
A. Cohen, A. Hasidim, T. Koren, N. Lazic, Y. Mansour, and K. Talwar, “Online linear quadratic control,” in International Conference on Machine Learning , pp. 1029–1038, PMLR, 2018
2018
-
[38]
Synthesis of safety certificates for discrete-time uncertain systems via convex optimizati on,
M. Fochesato, H. Wang, A. Papachristodoulou, and P. Gou lart, “Synthesis of safety certificates for discrete-time uncertain systems via convex optimizati on,” arXiv preprint arXiv:2505.08559, 2025
-
[39]
S. Kang, X. Jiang, and H. Yang, “Local linear convergenc e of the alternating direction method of multipliers for semidefinite programming under strict co mplementarity,” arXiv preprint arXiv:2503.20142, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Proximal algorithms,
N. Parikh and S. Boyd, “Proximal algorithms,” Foundations and Trends in optimization, vol. 1, no. 3, pp. 127–239, 2014. 35
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.