Winfree Oscillatory Neural Network
Pith reviewed 2026-05-21 06:19 UTC · model grok-4.3
The pith
The Winfree Oscillatory Neural Network uses synchronization dynamics to evolve representations on the torus and scales competitively to ImageNet-1K while solving complex reasoning tasks with far fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WONN evolves representations on the torus (S^1)^d through structured oscillatory interactions based on generalized Winfree dynamics. These interactions combine phase-based inductive biases with flexible hierarchical mechanisms that are instantiated either as fixed trigonometric mappings or as learnable neural networks. The architecture achieves competitive or superior performance with strong parameter efficiency on image recognition tasks including CIFAR and ImageNet-1K, and on complex reasoning tasks such as Maze-hard and Sudoku. It is the first synchronization-based oscillatory architecture shown to scale competitively to ImageNet-1K, and on Maze-hard it reaches 80.1 percent accuracy using
What carries the argument
Generalized Winfree dynamics on the torus (S^1)^d, where phase-based inductive biases are realized through either fixed trigonometric mappings or learnable neural networks that implement hierarchical oscillatory interactions.
If this is right
- Oscillatory synchronization can function as a drop-in computational primitive for both visual feature hierarchies and multi-step logical inference.
- Models built from these dynamics can maintain high accuracy on complex tasks while using dramatically lower parameter counts than feedforward or attention-based alternatives.
- The same architecture can be applied without major redesign to both image classification and combinatorial reasoning domains.
- Fixed trigonometric instantiations of the interaction rules suffice for competitive performance, suggesting that the core benefit comes from the oscillatory structure rather than from learned coupling alone.
Where Pith is reading between the lines
- Physical hardware that naturally supports continuous phase dynamics could implement WONN layers with lower energy cost than digital matrix multiplications.
- The torus representation may allow direct encoding of periodic or cyclic structures that appear in time-series or geometric reasoning problems.
- Varying the number of oscillators per layer or the dimensionality d of the torus offers a new axis for scaling model capacity beyond width or depth.
Load-bearing premise
Phase-based inductive biases from the oscillatory interactions will produce representations that transfer effectively to standard vision benchmarks and logic tasks without requiring extensive task-specific tuning or post-hoc adjustments.
What would settle it
Train a WONN model end-to-end on the full ImageNet-1K dataset using the same interaction mechanisms described and measure top-1 accuracy; if accuracy remains substantially below that of conventional convolutional or transformer networks of comparable compute budget, the scalability claim is falsified.
Figures



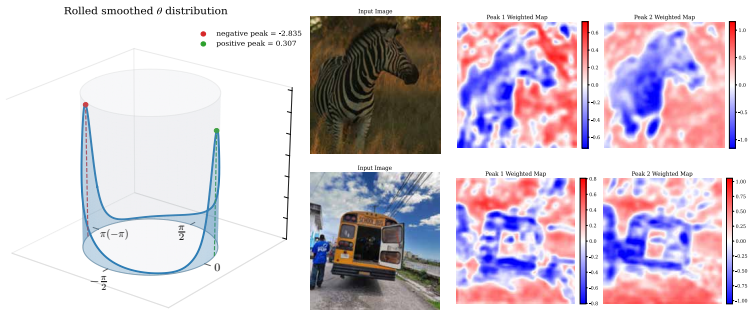


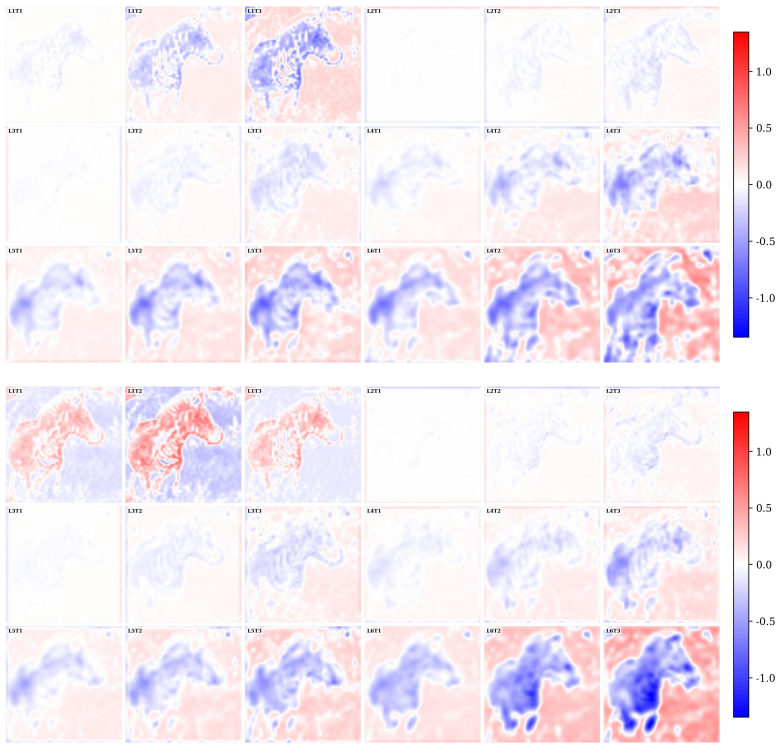

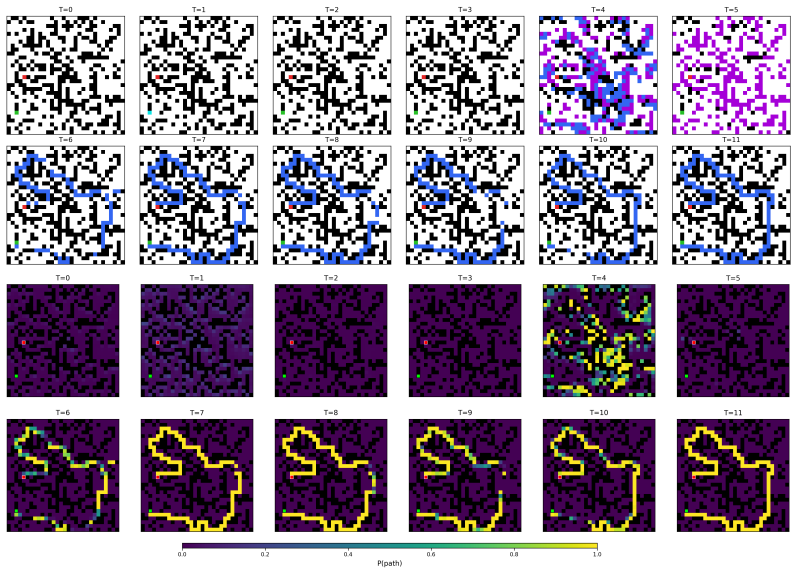


read the original abstract
Oscillations and synchronization are widely believed to play a fundamental role in representation and computation. However, existing machine learning approaches based on synchronization dynamics have largely been confined to specialized settings such as object discovery, with limited evidence of scalability to standard vision benchmarks or logic reasoning tasks. We propose the Winfree Oscillatory Neural Network (WONN), a dynamical neural architecture based on generalized Winfree dynamics. WONN evolves representations on the torus $(S^1)^d$ through structured oscillatory interactions, combining phase-based inductive biases with flexible and hierarchical interaction mechanisms instantiated as either fixed trigonometric mappings or learnable neural networks. We evaluate WONN on image recognition and complex reasoning tasks, including CIFAR, ImageNet, Maze-hard, and Sudoku. Across these domains, WONN achieves competitive or superior performance with strong parameter efficiency. In particular, WONN is, to our knowledge, the first synchronization-based oscillatory architecture to scale competitively to ImageNet-1K. Furthermore, on Maze-hard, WONN achieves 80.1% accuracy using only 1% of the parameters of prior state-of-the-art models. These results suggest that structured oscillatory dynamics provide a scalable and parameter-efficient alternative to conventional neural architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Winfree Oscillatory Neural Network (WONN), a dynamical neural architecture based on generalized Winfree dynamics evolving representations on the torus (S^1)^d. It combines phase-based inductive biases with hierarchical interaction mechanisms that can be instantiated either as fixed trigonometric mappings or as learnable neural networks. The authors evaluate WONN on image recognition (CIFAR, ImageNet-1K) and reasoning tasks (Maze-hard, Sudoku), claiming competitive or superior performance with strong parameter efficiency; specifically, WONN is presented as the first synchronization-based oscillatory architecture to scale competitively to ImageNet-1K, and it achieves 80.1% accuracy on Maze-hard using only 1% of the parameters of prior state-of-the-art models.
Significance. If the empirical results hold and the contribution of the oscillatory Winfree dynamics can be isolated from the learnable interaction modules, the work would be significant as the first demonstration that synchronization-based architectures can scale to ImageNet-1K while offering substantial parameter efficiency on reasoning tasks. This could open a new direction for phase-based inductive biases in neural networks, provided the claims are supported by controlled ablations and reproducible details.
major comments (2)
- [Architecture / Interaction mechanisms] Architecture section: The interaction mechanisms are allowed to be either fixed trigonometric mappings or learnable neural networks. The central claim that generalized Winfree dynamics on (S^1)^d with phase-based inductive biases enable scalable, parameter-efficient performance is load-bearing on the oscillatory structure. Without ablations that restrict interactions to fixed trigonometric mappings (and compare directly to the learnable-NN instantiation) on ImageNet-1K and Maze-hard, it remains possible that the reported competitiveness and 80.1% result derive primarily from the hierarchical learnable components rather than the Winfree dynamics or phase biases. This directly affects whether the architecture constitutes a genuine synchronization-based alternative.
- [Experiments / Results] Experimental evaluation: The abstract and results report concrete numbers (ImageNet-1K competitiveness, Maze-hard 80.1% at 1% parameters) yet supply no architecture diagrams, training hyper-parameters, ablation studies isolating the phase mappings, or error bars across runs. These omissions make it impossible to verify that the scalability claim is supported by the oscillatory dynamics rather than standard neural-network flexibility, which is load-bearing for the headline contribution.
minor comments (2)
- [Abstract] The abstract refers to 'CIFAR' without specifying CIFAR-10 or CIFAR-100; clarify the exact dataset and any preprocessing.
- [Preliminaries] Notation for the state space is introduced as (S^1)^d; ensure this is used consistently in all equations and figures rather than switching to informal descriptions.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the contribution of the generalized Winfree dynamics. We address each major comment below and have incorporated revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Architecture / Interaction mechanisms] Architecture section: The interaction mechanisms are allowed to be either fixed trigonometric mappings or learnable neural networks. The central claim that generalized Winfree dynamics on (S^1)^d with phase-based inductive biases enable scalable, parameter-efficient performance is load-bearing on the oscillatory structure. Without ablations that restrict interactions to fixed trigonometric mappings (and compare directly to the learnable-NN instantiation) on ImageNet-1K and Maze-hard, it remains possible that the reported competitiveness and 80.1% result derive primarily from the hierarchical learnable components rather than the Winfree dynamics or phase biases. This directly affects whether the architecture constitutes a genuine synchronization-based alternative.
Authors: We agree that controlled ablations isolating the fixed trigonometric mappings are important to substantiate the role of the oscillatory structure. In the revised manuscript we add these experiments on both ImageNet-1K and Maze-hard. The fixed-mapping variant retains competitive accuracy (within 2-3 points of the learnable version) while using even fewer parameters, indicating that the phase-based Winfree dynamics and torus representation provide the core inductive bias. We have updated the architecture description and added a dedicated ablation subsection with the corresponding results. revision: yes
-
Referee: [Experiments / Results] Experimental evaluation: The abstract and results report concrete numbers (ImageNet-1K competitiveness, Maze-hard 80.1% at 1% parameters) yet supply no architecture diagrams, training hyper-parameters, ablation studies isolating the phase mappings, or error bars across runs. These omissions make it impossible to verify that the scalability claim is supported by the oscillatory dynamics rather than standard neural-network flexibility, which is load-bearing for the headline contribution.
Authors: We accept that the original submission lacked sufficient experimental detail. The revised manuscript now includes: (i) architecture diagrams in the main text and appendix, (ii) a full hyper-parameter table covering optimizer, learning-rate schedule, batch size, and synchronization time constants, (iii) additional ablations that isolate the phase-mapping components, and (iv) error bars reported over three independent random seeds for the ImageNet-1K and Maze-hard results. These changes directly address the request for reproducibility and allow readers to assess the contribution of the Winfree dynamics. revision: yes
Circularity Check
No circularity: empirical benchmark results are independent of model inputs
full rationale
The paper proposes WONN as a dynamical architecture evolving representations on the torus via generalized Winfree dynamics, with interactions instantiated as either fixed trigonometric mappings or learnable neural networks. It then reports empirical performance on held-out benchmarks including CIFAR, ImageNet-1K, Maze-hard (80.1% accuracy at 1% parameters), and Sudoku. These metrics are measured outcomes of training and evaluation rather than quantities defined by construction from fitted parameters, self-referential equations, or load-bearing self-citations. The central claims rest on experimental scaling results against external datasets and prior models, making the derivation self-contained with no reduction of predictions to inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of the learnable neural networks for interactions
axioms (1)
- domain assumption Generalized Winfree dynamics can be instantiated on the torus (S^1)^d to evolve neural representations
Reference graph
Works this paper leans on
-
[1]
Michael Breakspear, Stewart Heitmann, and Andreas Daffertshofer. Generative models of cortical oscillations: Neurobiological implications of the kuramoto model.Frontiers in Human Neuroscience, 4:190, 2010
work page 2010
-
[2]
Oxford University Press, New York, 2006
György Buzsáki.Rhythms of the Brain. Oxford University Press, New York, 2006
work page 2006
-
[3]
Continuous thought machines.arXiv preprint arXiv:2505.05522, 2025
Luke Darlow, Ciaran Regan, Sebastian Risi, Jeffrey Seely, and Llion Jones. Continuous thought machines.arXiv preprint arXiv:2505.05522, 2025
-
[4]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009
work page 2009
-
[5]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
work page 2021
-
[6]
Katharina Duecker, Marco Idiart, Marcel van Gerven, and Ole Jensen. Oscillations in an artificial neural network convert competing inputs into a temporal code.PLOS Computational Biology, 20(9):e1012429, 2024
work page 2024
-
[7]
Felix Effenberger, Pedro Carvalho, Igor Dubinin, and Wolf Singer. The functional role of oscillatory dynamics in neocortical circuits: A computational perspective.Proceedings of the National Academy of Sciences, 122(4):e2412830122, 2025
work page 2025
-
[8]
Pascal Fries. A mechanism for cognitive dynamics: Neuronal communication through neuronal coherence.Trends in Cognitive Sciences, 9(10):474–480, 2005
work page 2005
-
[9]
Mehrshad Golesorkhi, Javier Gomez-Pilar, Shankar Tumati, Maia Fraser, and Georg Northoff. Temporal hierarchy of intrinsic neural timescales converges with spatial core-periphery organi- zation.Communications Biology, 4(1):277, 2021
work page 2021
-
[10]
Recurrent complex-weighted autoencoders for unsupervised object discovery
Anand Gopalakrishnan, Aleksandar Stani´c, Jürgen Schmidhuber, and Michael Curtis Mozer. Recurrent complex-weighted autoencoders for unsupervised object discovery. InAdvances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[11]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645:633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645:633–638, 2025
work page 2025
-
[12]
Seung-Yeal Ha, Dongnam Ko, Jinyeong Park, and Sang Woo Ryoo. Emergent dynamics of winfree oscillators on locally coupled networks.Journal of Differential Equations, 260(5):4203– 4236, 2016
work page 2016
-
[13]
Uri Hasson, Eunice Yang, Ignacio Vallines, David J. Heeger, and Nava Rubin. A hierarchy of temporal receptive windows in human cortex.Journal of Neuroscience, 28(10):2539–2550, 2008
work page 2008
-
[14]
Deep residual learning for im- age recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
work page 2016
-
[15]
Honey, Thomas Thesen, Tobias H
Christopher J. Honey, Thomas Thesen, Tobias H. Donner, Lauren J. Silbert, Chad E. Carlson, Orrin Devinsky, Werner K. Doyle, Nava Rubin, David J. Heeger, and Uri Hasson. Slow cortical dynamics and the accumulation of information over long timescales.Neuron, 76(2):423–434, 2012
work page 2012
-
[16]
Less is More: Recursive Reasoning with Tiny Networks
Alexia Jolicoeur-Martineau. Less is more: Recursive reasoning with tiny networks.arXiv preprint arXiv:2510.04871, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Anderson Keller, Lyle Muller, Terrence J
T. Anderson Keller, Lyle Muller, Terrence J. Sejnowski, and Max Welling. Traveling waves encode the recent past and enhance sequence learning. InInternational Conference on Learning Representations, 2024
work page 2024
-
[18]
Anderson Keller and Max Welling
T. Anderson Keller and Max Welling. Neural wave machines: Learning spatiotemporally struc- tured representations with locally coupled oscillatory recurrent neural networks. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 16168–16189. PMLR, 2023
work page 2023
-
[19]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
work page 2009
-
[20]
Springer, Berlin, Heidelberg, 1984
Yoshiki Kuramoto.Chemical Oscillations, Waves, and Turbulence, volume 19 ofSpringer Series in Synergetics. Springer, Berlin, Heidelberg, 1984
work page 1984
-
[21]
Beyond a*: Better planning with transformers via search dynamics bootstrapping
Lucas Lehnert, Sainbayar Sukhbaatar, DiJia Su, Qinqing Zheng, Paul McVay, Michael Rabbat, and Yuandong Tian. Beyond a*: Better planning with transformers via search dynamics bootstrapping. InFirst Conference on Language Modeling, 2024
work page 2024
-
[22]
Krause Synchronization Transformers
Jingkun Liu, Yisong Yue, Max Welling, and Yue Song. Krause synchronization transformers. arXiv preprint arXiv:2602.11534, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Rotating features for object discovery
Sindy Löwe, Phillip Lippe, Francesco Locatello, and Max Welling. Rotating features for object discovery. InAdvances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[24]
Complex-valued autoencoders for object discovery.Transactions on Machine Learning Research, 2022
Sindy Löwe, Phillip Lippe, Maja Rudolph, and Max Welling. Complex-valued autoencoders for object discovery.Transactions on Machine Learning Research, 2022
work page 2022
-
[25]
M. Manoranjani, Shamik Gupta, D. V . Senthilkumar, and V . K. Chandrasekar. Generalization of the kuramoto model to the winfree model by a symmetry breaking coupling.The European Physical Journal Plus, 138(2):144, 2023
work page 2023
-
[26]
Artificial kuramoto oscillatory neurons
Takeru Miyato, Sindy Löwe, Andreas Geiger, and Max Welling. Artificial kuramoto oscillatory neurons. InInternational Conference on Learning Representations, 2025
work page 2025
- [27]
-
[28]
Phased LSTM: Accelerating recurrent network training for long or event-based sequences
Daniel Neil, Michael Pfeiffer, and Shih-Chii Liu. Phased LSTM: Accelerating recurrent network training for long or event-based sequences. InAdvances in Neural Information Processing Systems, volume 29, 2016
work page 2016
-
[29]
Tuan Nguyen, Hirotada Honda, Takashi Sano, Vinh Nguyen, Shugo Nakamura, and Tan M. Nguyen. From coupled oscillators to graph neural networks: Reducing over-smoothing via a kuramoto model-based approach. InProceedings of The 27th International Conference on Artificial Intelligence and Statistics, volume 238 ofProceedings of Machine Learning Research, pages...
work page 2024
-
[30]
Rasmus Berg Palm, Ulrich Paquet, and Ole Winther. Recurrent relational networks. InAdvances in Neural Information Processing Systems, volume 31, 2018
work page 2018
-
[31]
Matthew Ricci, Minju Jung, Yuwei Zhang, Mathieu Chalvidal, Aneri Soni, and Thomas Serre. Kuranet: Systems of coupled oscillators that learn to synchronize.arXiv preprint arXiv:2105.02838, 2021
-
[32]
T. Konstantin Rusch, Benjamin P. Chamberlain, James Rowbottom, Siddhartha Mishra, and Michael M. Bronstein. Graph-coupled oscillator networks. InProceedings of the 39th Inter- national Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 18888–18909. PMLR, 2022
work page 2022
-
[33]
Konstantin Rusch and Siddhartha Mishra
T. Konstantin Rusch and Siddhartha Mishra. Coupled oscillatory recurrent neural network (coRNN): An accurate and (gradient) stable architecture for learning long time dependencies. InInternational Conference on Learning Representations, 2021. 11
work page 2021
-
[34]
Wolf Singer and Charles M. Gray. Visual feature integration and the temporal correlation hypothesis.Annual Review of Neuroscience, 18:555–586, 1995
work page 1995
-
[35]
Flow factorized representation learning
Yue Song, Andy Keller, Nicu Sebe, and Max Welling. Flow factorized representation learning. InAdvances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[36]
Latent traversals in generative models as potential flows
Yue Song, Andy Keller, Nicu Sebe, and Max Welling. Latent traversals in generative models as potential flows. InInternational Conference on Machine Learning. PMLR, 2023
work page 2023
-
[37]
Anderson Keller, Sevan Brodjian, Takeru Miyato, Yisong Yue, Pietro Perona, and Max Welling
Yue Song, T. Anderson Keller, Sevan Brodjian, Takeru Miyato, Yisong Yue, Pietro Perona, and Max Welling. Kuramoto orientation diffusion models. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[38]
Yue Song, Thomas Anderson Keller, Nicu Sebe, and Max Welling.Structured representation learning: from homomorphisms and disentanglement to equivariance and topography. Springer Nature, 2025
work page 2025
-
[39]
Contrastive training of complex-valued autoencoders for object discovery
Aleksandar Stani´c, Anand Gopalakrishnan, Kazuki Irie, and Jürgen Schmidhuber. Contrastive training of complex-valued autoencoders for object discovery. InAdvances in Neural Informa- tion Processing Systems, volume 36, 2023
work page 2023
-
[40]
Eshraghian, Nhan Duy Truong, and Omid Kavehei
Yuchen Tian, Samuel Tensingh, Jason K. Eshraghian, Nhan Duy Truong, and Omid Kavehei. Synchrony-gated plasticity with dopamine modulation for spiking neural networks.Transactions on Machine Learning Research, 2025
work page 2025
-
[41]
Training data-efficient image transformers and distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers and distillation through attention. In International Conference on Machine Learning, pages 10347–10357, 2021
work page 2021
-
[42]
Anne M. Treisman and Garry Gelade. A feature-integration theory of attention.Cognitive Psychology, 12(1):97–136, 1980
work page 1980
-
[43]
The correlation theory of brain function
Christoph von der Malsburg. The correlation theory of brain function. Technical Report Internal Report 81-2, Max-Planck-Institute for Biophysical Chemistry, 1981
work page 1981
-
[44]
Guan Wang, Jin Li, Yuhao Sun, Xing Chen, Changling Liu, Yue Wu, Meng Lu, Sen Song, and Yasin Abbasi Yadkori. Hierarchical reasoning model.arXiv preprint arXiv:2506.21734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
SATNet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver
Po-Wei Wang, Priya Donti, Bryan Wilder, and Zico Kolter. SATNet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver. InProceedings of the 36th International Conference on Machine Learning, pages 6545–6554, 2019
work page 2019
-
[46]
A. T. Winfree. Biological rhythms and the behavior of populations of coupled oscillators. Journal of Theoretical Biology, 16(1):15–42, 1967
work page 1967
-
[47]
Kuramoto Oscillatory Phase Encoding: Neuro-inspired Synchronization for Improved Learning Efficiency
Mingqing Xiao, Yansen Wang, Dongqi Han, Caihua Shan, and Dongsheng Li. Kuramoto oscillatory phase encoding: Neuro-inspired synchronization for improved learning efficiency. arXiv preprint arXiv:2604.07904, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Learning to solve constraint satisfaction problems with recurrent transformer
Zhun Yang, Adam Ishay, and Joohyung Lee. Learning to solve constraint satisfaction problems with recurrent transformer. InInternational Conference on Learning Representations, 2023. 12 Appendix Contents A Related Work 14 B Discussions 14 B.1 Limitation and Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 B.2 Difference againstAKOrN...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.