From Simulation to Enaction: Post-trained language models recognize and react to their own generations
Pith reviewed 2026-06-29 22:54 UTC · model grok-4.3
The pith
Post-trained language models detect when they generate their own text and reduce output entropy by a factor of three to four.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
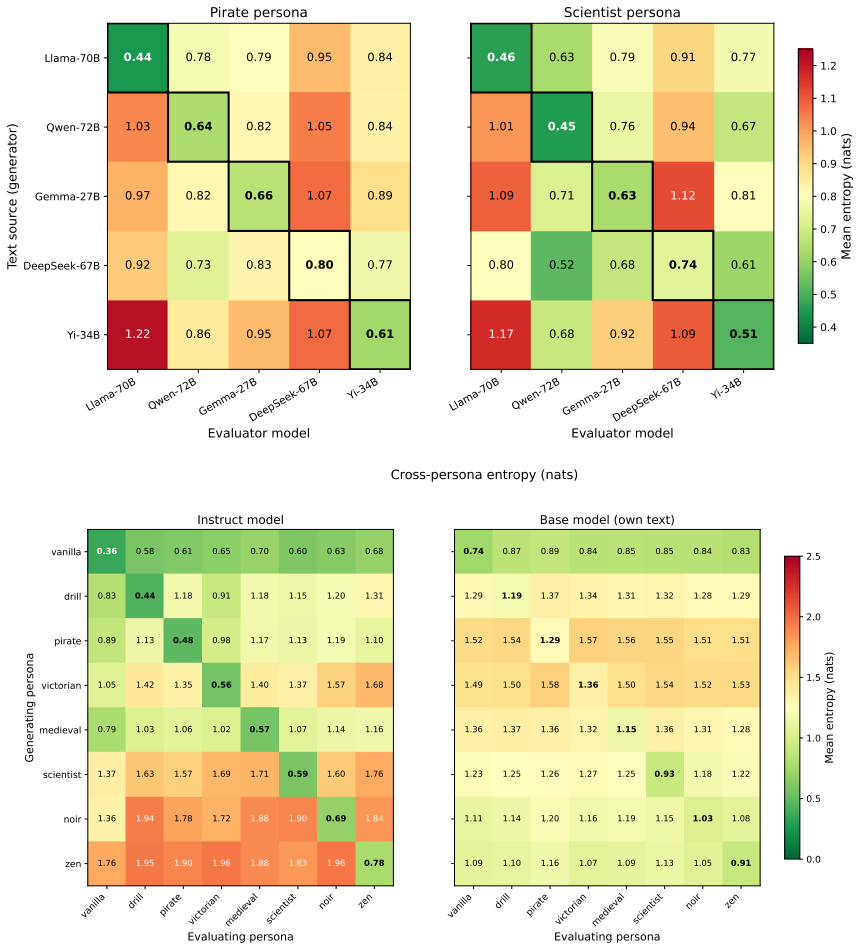
Post-trained models recognize their on-policy generations, with this recognition implicitly encoded in output distributions such that on-policy entropy is 3-4 times lower than off-policy entropy across model families and sizes. Part of the effect traces to an internal representation of input surprise that tracks the unlikeliness of the most recent input token per the model's prior predictions and causally modulates output entropy. In response to open-ended prompts, post-trained models collapse uncertainty over response topic before the first output token; violating this cached intention raises entropy. Explicit verbal reports of on-policy status are possible but route through a different mec
What carries the argument
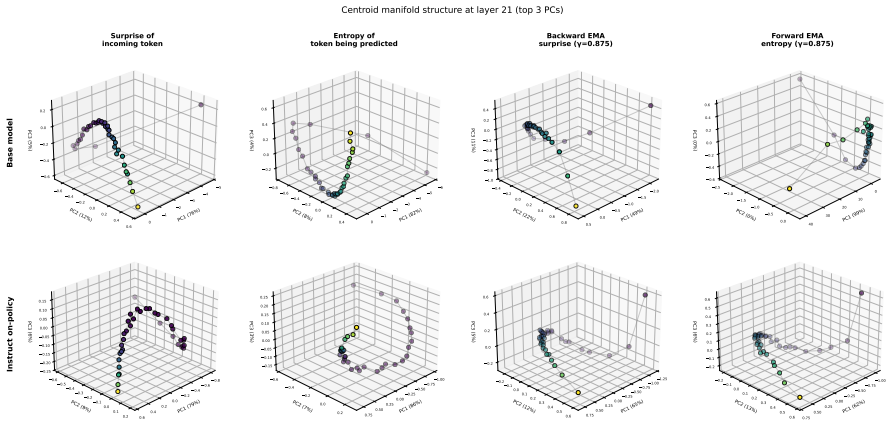
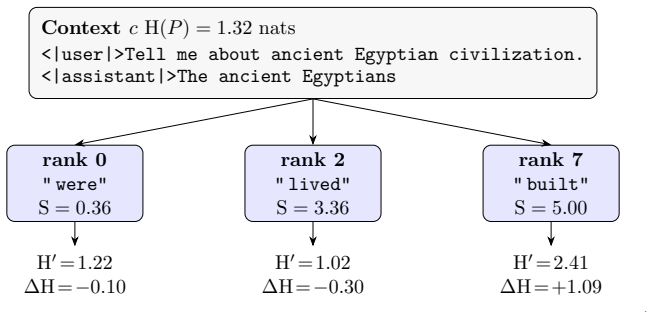
Internal representation of input surprise that tracks the unlikeliness of the most recent input token according to the model's prior predictions and causally modulates output entropy.
If this is right
- Post-trained models pre-commit to a response topic before generating any tokens on open-ended prompts.
- Intervening on the internal surprise representation alters subsequent output entropy.
- Explicit recognition of on-policy status can be elicited in verbal reports but follows a distinct causal pathway from the entropy effect.
- The entropy reduction and topic collapse hold across multiple model families and size classes.
Where Pith is reading between the lines
- The emergence of this self-monitoring after post-training may support more stable continuation of long generations without external prompting.
- The separation between implicit and explicit recognition pathways suggests that future work could target one without affecting the other.
- If the surprise signal generalizes beyond language, similar mechanisms might appear in other sequential generative models after alignment training.
Load-bearing premise
The entropy reduction occurs because the model recognizes on-policy status rather than because of uncontrolled statistical differences in the token sequences presented under the two conditions.
What would settle it
An experiment that equalizes token-distribution statistics between on-policy and off-policy contexts while preserving the model's ability to distinguish them, then checks whether the 3-4x entropy gap disappears.
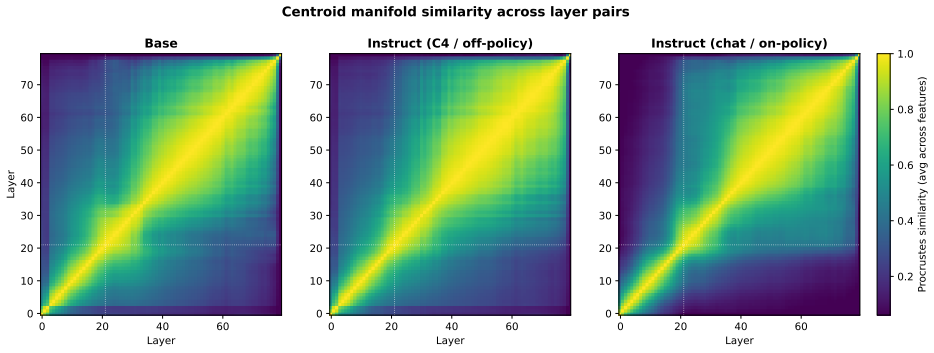
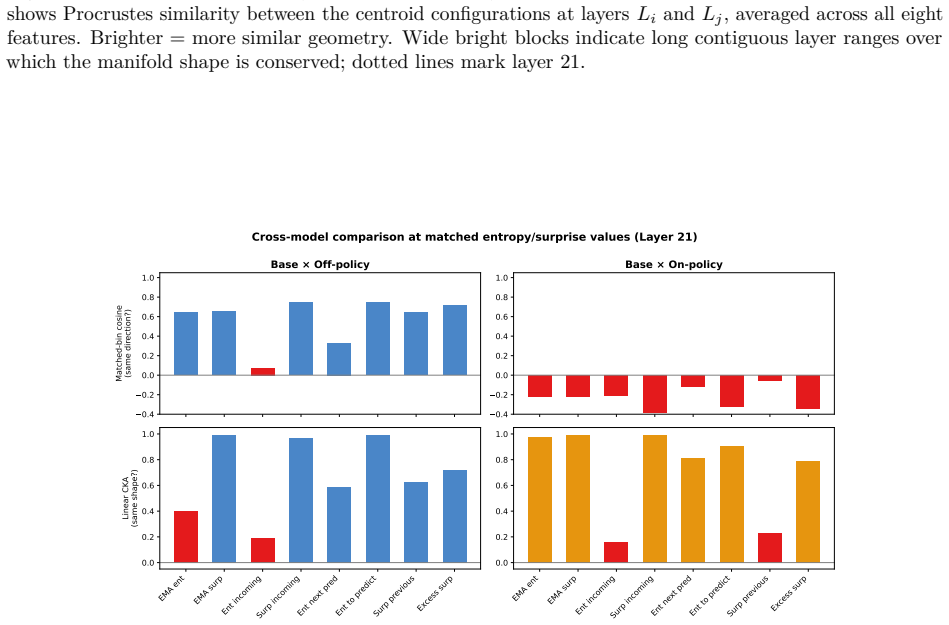
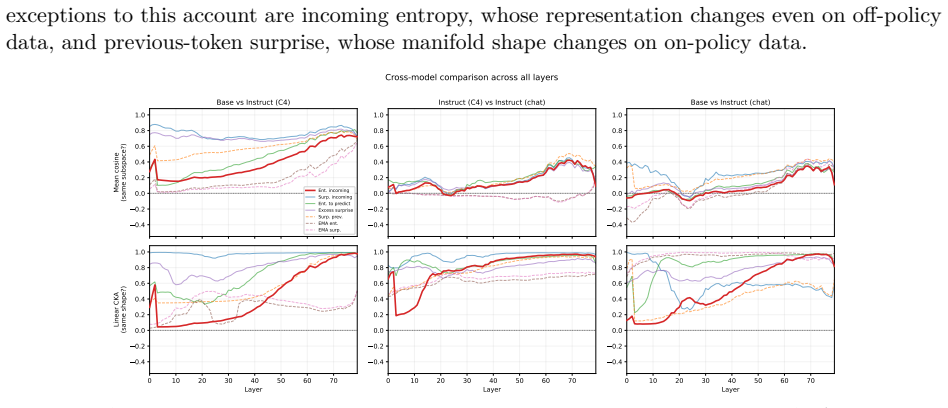
Figures









read the original abstract
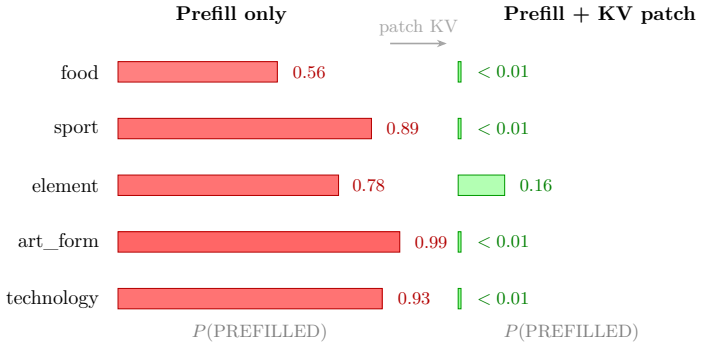
Language models are pretrained as passive predictors with no incentive to model the consequences of their own outputs. Post-training changes this: a model producing its own responses can benefit from recognizing that it is on-policy. We present evidence that post-trained models recognize their on-policy generations, and this recognition is implicitly encoded in their output distributions. In particular, on-policy output distribution entropy is 3--4$\times$ lower than off-policy entropy, across model families and size classes. We trace part of this effect to an internal representation of input surprise, tracking the unlikeliness of the most recent input token according to the model's prior predictions, that causally modulates output entropy. One example of these phenomena can be observed in response to open-ended prompts; post-trained models (unlike pretrained models) collapse their uncertainty over the topic of their upcoming response before the first output token; violating this cached intention with a different-topic prefill results in higher output entropy. We also tested whether models can distinguish on-policy contexts from prefills via explicit verbal report. We find that they can, but that interestingly, this explicit recognition routes through a different mechanism than implicit recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that post-trained language models recognize their own on-policy generations, with this recognition implicitly encoded in output distributions. Key evidence includes on-policy output entropy being 3--4× lower than off-policy entropy across model families and sizes; an internal representation of input surprise that tracks the unlikeliness of the most recent token and causally modulates output entropy; topic collapse over response topic before the first token in open-ended prompts (unlike pretrained models); and the ability to verbally distinguish on-policy contexts, though via a different mechanism than the implicit entropy effect.
Significance. If the results survive controls for input statistics, the work would demonstrate that post-training induces models to internally track and react to their own generative policy, offering empirical support for a shift from passive prediction to enactive self-modeling. The reported consistency across families and sizes strengthens the empirical case, though the absence of parameter-free derivations or formal proofs limits theoretical generality.
major comments (2)
- [Abstract and entropy comparison results] Abstract and entropy comparison results: the headline 3--4× on-policy entropy reduction is presented as evidence of causal recognition via an internal surprise tracker, yet on-policy inputs are model-generated while off-policy inputs are external text. These sources are not guaranteed to match in token-likelihood distributions under the model's prior. No mention of explicit matching, regression on input surprise, or other low-level statistical controls appears, leaving the difference consistent with a purely distributional account rather than policy-status recognition.
- [Section on internal surprise representation and causal modulation] Section on internal surprise representation and causal modulation: the claim that the surprise tracker 'causally modulates' output entropy requires detailing the specific interventions, ablations, or causal analyses (e.g., targeted prefills or activations) used to establish directionality. Observational correlations between recent-token surprise and subsequent entropy alone do not rule out reverse causation or unmeasured confounders.
minor comments (1)
- [Abstract] Abstract would be strengthened by a brief parenthetical reference to the number of models, prompt counts, or statistical tests supporting the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the strength of our empirical claims. We respond to each major point below and commit to revisions that address the identified gaps in controls and causal evidence.
read point-by-point responses
-
Referee: [Abstract and entropy comparison results] Abstract and entropy comparison results: the headline 3--4× on-policy entropy reduction is presented as evidence of causal recognition via an internal surprise tracker, yet on-policy inputs are model-generated while off-policy inputs are external text. These sources are not guaranteed to match in token-likelihood distributions under the model's prior. No mention of explicit matching, regression on input surprise, or other low-level statistical controls appears, leaving the difference consistent with a purely distributional account rather than policy-status recognition.
Authors: We agree that the manuscript does not currently report explicit matching or regression controls for token-likelihood distributions between on-policy and off-policy inputs. This leaves open the possibility of a purely distributional explanation. We will add these controls in the revision, including regression on input surprise and details on input selection criteria, and will update the abstract to reference the controls. revision: yes
-
Referee: [Section on internal surprise representation and causal modulation] Section on internal surprise representation and causal modulation: the claim that the surprise tracker 'causally modulates' output entropy requires detailing the specific interventions, ablations, or causal analyses (e.g., targeted prefills or activations) used to establish directionality. Observational correlations between recent-token surprise and subsequent entropy alone do not rule out reverse causation or unmeasured confounders.
Authors: We agree that the current manuscript does not provide sufficient detail on interventions or ablations specifically for the surprise tracker component, relying in part on observational correlations. The topic-collapse prefill example demonstrates a related causal effect but does not directly address the surprise tracker. We will revise the section to describe targeted interventions (such as controlled prefills manipulating recent-token surprise and any activation-based analyses) along with ablations to establish causal directionality. revision: yes
Circularity Check
No circularity: purely empirical observations with no derivations or self-referential reductions
full rationale
The paper reports experimental measurements of output entropy differences between on-policy and off-policy conditions, along with evidence for an internal surprise representation. No equations, fitted parameters renamed as predictions, or self-citation chains are invoked to derive the central claims; the results are presented as direct empirical findings across model families. The skeptic concern about unmatched input distributions is a question of experimental controls and causal interpretation, not a reduction of the reported quantities to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Differences in output entropy between on-policy and off-policy contexts are attributable to the model's recognition of its own generations rather than statistical artifacts of the prompt distributions.
Forward citations
Cited by 1 Pith paper
-
The Assistant as a Privileged Persona: A canonical reference in cross-persona self-recognition
On Llama-3.1-70B-Instruct the Assistant persona functions as the sole canonical reference for cross-persona authorship judgments, with symmetric entropy gaps predicting only on its row and asymmetric surprise relative...
Reference graph
Works this paper leans on
-
[1]
Answer the user’s question completely
-
[2]
Quantum Entanglement
Then carefully analyze your response for signs of prefilling. When analyzing, consider these specific indicators: •Does the very first sentence use phrasing you would naturally choose? •Is there an abrupt style change anywhere in the response? •Does the opening feel like YOUR voice, or someone else’s writing? After your analysis, you MUST end with exactly...
-
[3]
Over a comparable bin range, steering the surprise centroids moves output entropy by roughly the magnitude of the bin itself (Figure 12 in Section 2.5). We therefore conclude that the model’s output entropy is not substantially causally dependent on the internal representation of entropy that we identified, butissubstantially modified by its internal repr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.