Towards a holistic understanding of Selection Bias for Causal Effect Identification
Pith reviewed 2026-06-30 21:22 UTC · model grok-4.3
The pith
The average treatment effect is identifiable under selection bias when weak assumptions on probability classes characterize the propensity score and selection probability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We provide necessary and sufficient conditions for ATE identifiability, leveraging weak assumptions on probability classes to characterize propensity score and selection probability. Compared to previous works, our results extend existing graphical identifiability criteria and offer a more comprehensive understanding of causal effect identification with strictly weaker conditions in the presence of selection bias.
What carries the argument
Characterization of propensity score and selection probability via weak assumptions on probability classes
If this is right
- Existing graphical identifiability criteria are extended to cover selection bias.
- Causal effect identification holds under strictly weaker conditions than those previously required.
- Population-level ATE can be recovered from data drawn only from a biased subpopulation when the conditions are met.
Where Pith is reading between the lines
- The same weak probability-class approach could be applied to identifiability questions involving other bias mechanisms such as missing data or measurement error.
- Practical checks could verify whether a given dataset approximately satisfies the probability class assumptions before relying on the derived conditions.
- The framework might generalize to time-varying treatments or other target quantities such as conditional average treatment effects.
Load-bearing premise
Weak assumptions on probability classes suffice to characterize the propensity score and selection probability without stronger graphical restrictions.
What would settle it
A concrete probability distribution satisfying the weak class assumptions for which the stated conditions hold yet the ATE cannot be recovered from the selected sample, or vice versa.
Figures



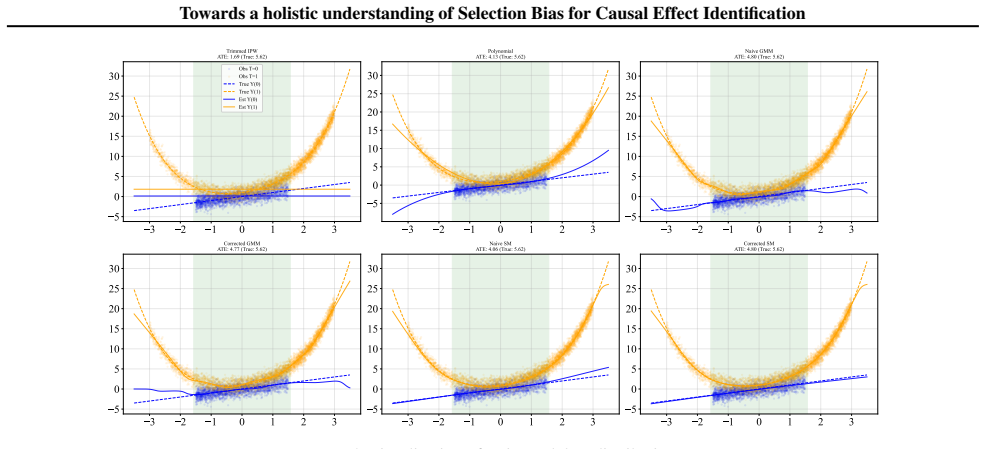
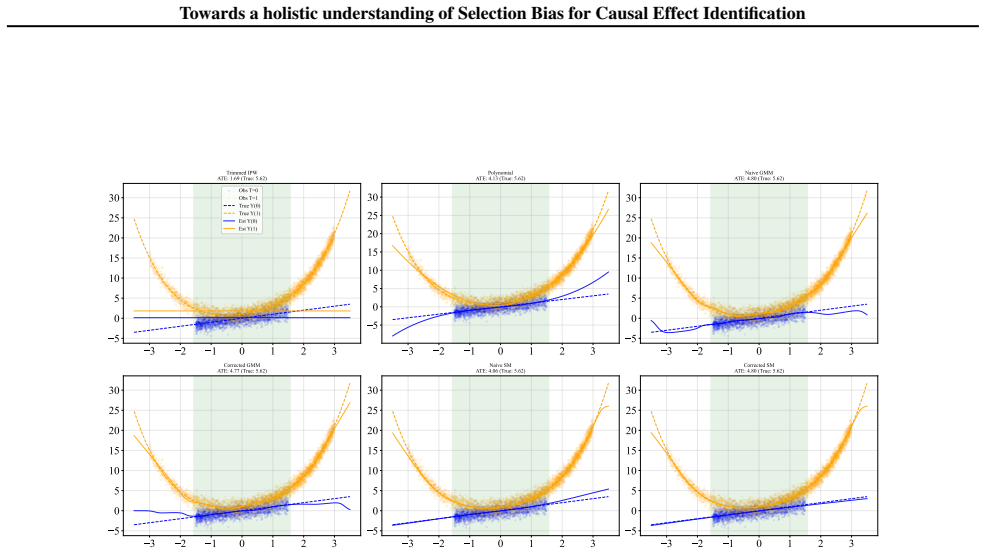
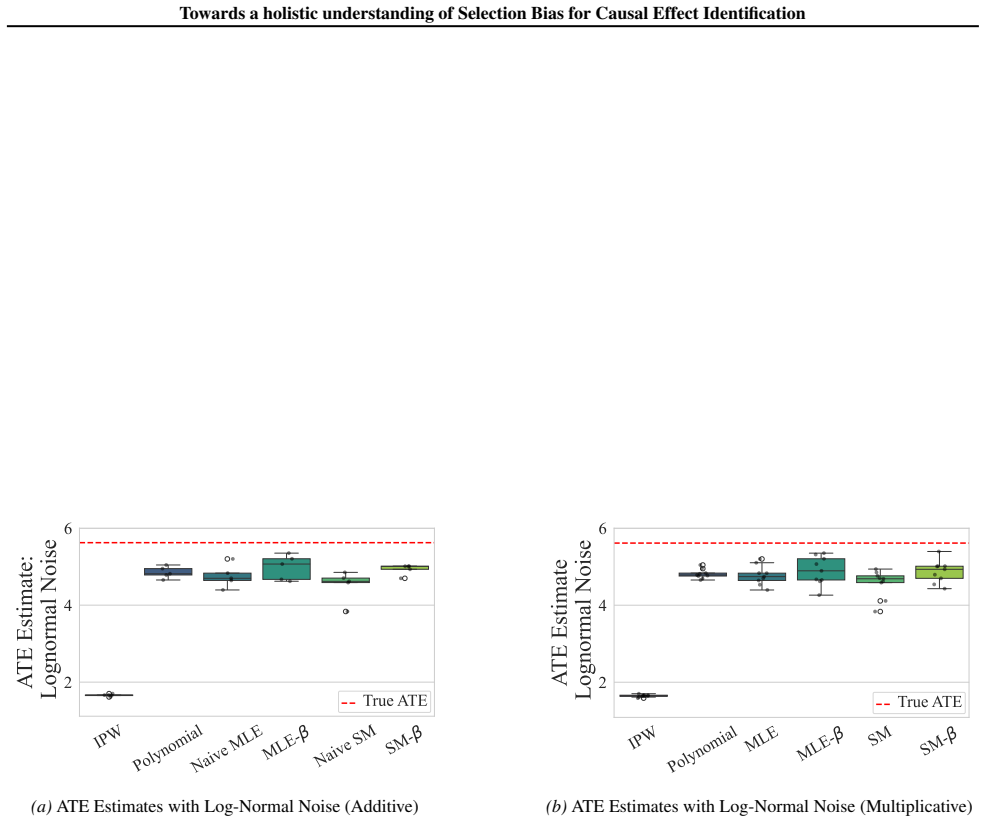
read the original abstract
Selection bias is pervasive in observational studies. For example, large scale biobanks data can exhibit ``healthy volunteer bias'' when respondents are healthier and of higher socio-economic status than the population they are meant to represent. Recovering causal effects from such sub-population is an important problem in causal inference, as estimating average treatment effects (ATE) from selected populations can result in a severely biased estimate of the ATE from the whole population. In this paper, we investigate the identifiability of the ATE under selection bias. We provide necessary and sufficient conditions for ATE identifiability, leveraging weak assumptions on probability classes to characterize propensity score and selection probability. Compared to previous works, our results extend existing graphical identifiability criteria and offer a more comprehensive understanding of causal effect identification with strictly weaker conditions in the presence of selection bias.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates the identifiability of the average treatment effect (ATE) under selection bias in observational studies (e.g., healthy volunteer bias in biobanks). It claims to supply necessary and sufficient conditions for ATE identifiability by leveraging weak assumptions on probability classes to characterize the propensity score and selection probability; these conditions are asserted to extend existing graphical identifiability criteria with strictly weaker restrictions.
Significance. If the claimed necessary and sufficient conditions can be rigorously established, the work would advance causal inference by enabling ATE recovery from selected subpopulations under assumptions weaker than standard graphical criteria, addressing a pervasive issue in observational data analysis.
major comments (1)
- [Abstract] Abstract: the central claim that necessary and sufficient conditions for ATE identifiability are provided is unsupported, as the manuscript supplies no derivations, theorems, proofs, or counter-examples establishing these conditions under the stated weak assumptions on probability classes.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need for rigorous support of our central claims. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that necessary and sufficient conditions for ATE identifiability are provided is unsupported, as the manuscript supplies no derivations, theorems, proofs, or counter-examples establishing these conditions under the stated weak assumptions on probability classes.
Authors: We agree that the abstract asserts the provision of necessary and sufficient conditions for ATE identifiability under weak assumptions on probability classes, yet the current manuscript does not contain explicit theorem statements, derivations, proofs, or counterexamples to establish these claims. The text discusses characterizations of propensity and selection probabilities but lacks the formal apparatus required to substantiate necessity and sufficiency. We will revise the manuscript by adding a dedicated theoretical section with formal theorems, complete proofs, and counterexamples demonstrating the identifiability results. This will directly support the abstract claim. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper states it provides necessary and sufficient conditions for ATE identifiability under selection bias, characterizing propensity score and selection probability via weak assumptions on probability classes that extend graphical criteria with strictly weaker restrictions. No quoted step reduces by construction to a fitted input, self-definition, or self-citation load-bearing premise. The central claim rests on stated assumptions and comparisons to prior (non-overlapping) work rather than renaming or smuggling results. This is the common case of a self-contained theoretical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Joint Conferences on Artificial In- telligence Organization. ISBN 978-0-9992411-2-7. doi: 10.24963/ijcai.2018/697. Jaber, A., Zhang, J., and Bareinboim, E. Causal identifi- cation under markov equivalence: Completeness results. InInternational Conference on Machine Learning, pp. 2981–2989. PMLR, 2019. Kocaoglu, M., Dimakis, A., and Vishwanat...
-
[2]
truncation
problem setting assumes that certain covariates are observed for all individuals, including non-selected ones, which we donotassume to have in our setting. In contrast, our setting falls within thetruncationregime in Heckman’s terminology: non-selected units are entirely absent from the dataset, and we observe only (Xi, Yi, Ti) for individual i with Si = ...
2019
-
[3]
Further, by the definition of Condition 1, for any two candidates in this subset, and any t∈ {0,1}the expected values ofY(t)under their outcome distributions are the same
to a function g(Pobs) :R d ×R× {0,1} →R such that g(Pobs) identifies a subset of candidates in (Pt|xy(t),P xy(t),S) that are compatible with Pobs. Further, by the definition of Condition 1, for any two candidates in this subset, and any t∈ {0,1}the expected values ofY(t)under their outcome distributions are the same. Proof Sketch (Necessity)We can constru...
2025
-
[4]
Recall, this holds due to the assumptionP xy(t), and the fact that it has fixed marginalP X
Gaussian distribution.As 1⃝ is assumed to hold, there must exist some x, for which the conditional outcome distributions is: P(y|x) = 1√ 2πσ 2 exp −(y−µ P )2 2σ2 , Q(y|x) = 1√ 2πσ 2 exp −(y−µ Q)2 2σ2 , whereµ P ̸=µ Q. Recall, this holds due to the assumptionP xy(t), and the fact that it has fixed marginalP X. Consider the ratioR(y) = P(y|x) Q(y|x) : R(y) ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.