GPTQ-intrinsic LoRA: A Near-optimal Algorithm for Low-precision Quantization with Low-rank Adaptation
Pith reviewed 2026-06-28 17:26 UTC · model grok-4.3
The pith
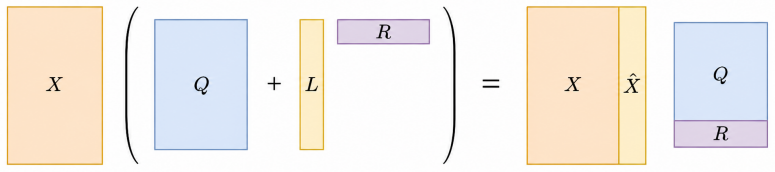
GPTQ-intrinsic LoRA folds low-rank corrections into the quantization pass to replace full-norm error dependence with a rank-r residual norm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
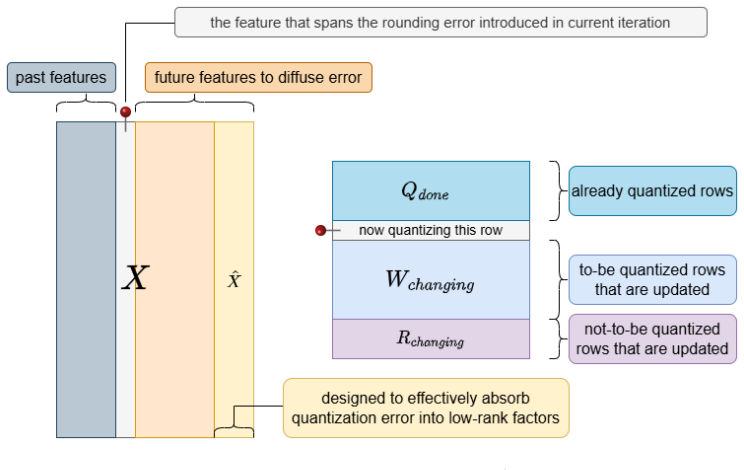
By choosing L equal to the top right singular vectors V_r of the calibration matrix X and incorporating the low-rank compensation directly through Hessian augmentation, the layer-wise reconstruction error admits provable bounds in which the usual GPTQ term proportional to ||X||_F^2 is replaced by a term proportional to the rank-r residual ||X - X_r||_F^2 (up to regularization). Under the paper's natural structural assumptions these bounds match the information-theoretic lower bounds in their leading scaling, up to constants and mild factors. The algorithm remains training-free and is accompanied by the Bid-Up refinement procedure that alternates optimal low-rank compensation with fixed-grid
What carries the argument
GPTQ-intrinsic LoRA, the procedure that augments the calibration Hessian to embed the low-rank correction L = V_r inside the quantization pass itself.
If this is right
- The combined quantization-plus-low-rank representation can be realized in one training-free pass rather than sequential quantization followed by separate low-rank compensation.
- Layer-wise error becomes controlled by the rank-r residual of the calibration matrix instead of its full Frobenius norm.
- Alternating Bid-Up refinement with low-rank compensation produces a sequence of approximations with strictly non-increasing reconstruction error.
- Empirical gains appear on both language models (Qwen3) and vision transformers (DeiT) relative to plain GPTQ and to GPTQ followed by post-hoc low-rank correction.
Where Pith is reading between the lines
- The Hessian-augmentation technique could be ported to other quantization routines that rely on second-order statistics, potentially extending the residual-norm scaling benefit beyond the GPTQ family.
- If the structural assumptions hold across typical pretrained weights, then low-bit representations with modest-rank corrections are information-theoretically near-optimal for many network layers.
- The explicit dependence on the top singular vectors of X suggests that pre-computing a low-rank basis from calibration data may be sufficient for near-optimal performance without further adaptation.
- Testing the tightness of the bounds on out-of-distribution calibration sets would reveal whether the residual-norm advantage persists when the structural assumptions are only approximately satisfied.
Load-bearing premise
Calibration data or weight matrices possess natural structural properties that let the derived error bounds scale with the residual norm rather than the full norm and thereby approach the information-theoretic limits.
What would settle it
On standard calibration sets, compute the observed layer-wise reconstruction error after applying GPTQ-intrinsic LoRA and check whether it exceeds the predicted residual-norm bound by more than the allowed constant and mild factors.
Figures
read the original abstract
Post-training quantization is widely used for compressing large neural networks, but aggressive low-bit quantization can significantly degrade model quality. A common remedy is to augment the quantized weights with a low-rank correction, leading to approximations of the form $W\approx Q+LR$. In this paper, we study this low-precision plus low-rank representation through the layer-wise reconstruction objective $\|XW-X(Q+LR)\|_F^2$, where $X$ is a calibration matrix. We establish, to our knowledge, the first information-theoretic lower bounds for this problem under finite-alphabet and bounded low-rank compensation constraints. We then propose GPTQ-intrinsic LoRA, a training-free algorithm that incorporates the low-rank correction directly into a GPTQ-style quantization pass by appropriately augmenting the calibration Hessian. For the choice $L=V_r$, where $V_r$ contains the top right singular vectors of $X$, we prove layer-wise reconstruction error bounds in which the usual GPTQ dependence on $\|X\|_F^2$ is replaced by the rank-$r$ residual $\|X-X_r\|_F^2$, up to regularization terms. Under natural structural assumptions, these bounds match the information-theoretic lower bounds in their dominant scaling, up to constants and mild factors. We also introduce Bid-Up, a fixed-grid quantization refinement step that can be alternated with optimal low-rank compensation with guaranteed non-increasing layer-wise reconstruction error. Experiments on Qwen3 language models and DeiT vision transformers show that GPTQ-intrinsic LoRA improves over GPTQ and GPTQ followed by low-rank compensation, with additional gains from refinement loops.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to establish the first information-theoretic lower bounds for the layer-wise reconstruction objective in low-precision quantization augmented with bounded low-rank compensation. It proposes the GPTQ-intrinsic LoRA algorithm, which augments the GPTQ Hessian to incorporate the low-rank term directly in a training-free manner. For the specific choice L = V_r (top right singular vectors of the calibration matrix X), it proves reconstruction error bounds in which the standard GPTQ ||X||_F^2 dependence is replaced by the rank-r residual ||X - X_r||_F^2 (up to regularization). Under unspecified natural structural assumptions, these upper bounds are claimed to match the lower bounds in dominant scaling. The paper also introduces the Bid-Up fixed-grid refinement procedure with non-increasing error guarantees and reports empirical gains over GPTQ and post-hoc low-rank compensation on Qwen3 and DeiT models.
Significance. If the stated bounds and their matching hold, the work would be a notable contribution to post-training quantization by supplying the first matching lower/upper bounds for the combined low-precision plus low-rank setting and a practical algorithm that achieves the improved residual-norm scaling without additional training. The explicit integration of the low-rank correction into the quantization pass via Hessian augmentation and the guaranteed monotonicity of the Bid-Up refinement are concrete strengths that could influence follow-on algorithm design.
major comments (1)
- [Abstract] Abstract: the claim that the derived upper bounds match the information-theoretic lower bounds 'in their dominant scaling, up to constants and mild factors' under 'natural structural assumptions' is the load-bearing statement for the 'near-optimal' characterization, yet the abstract (and therefore the central theoretical contribution) provides no explicit definition or statement of those assumptions (e.g., incoherence, RIP, or spectral conditions on X or W). Without them the matching cannot be verified and the experimental calibration matrices cannot be checked against the proof hypotheses.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting the need for greater clarity in the abstract. We address the single major comment below and will incorporate the suggested revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the derived upper bounds match the information-theoretic lower bounds 'in their dominant scaling, up to constants and mild factors' under 'natural structural assumptions' is the load-bearing statement for the 'near-optimal' characterization, yet the abstract (and therefore the central theoretical contribution) provides no explicit definition or statement of those assumptions (e.g., incoherence, RIP, or spectral conditions on X or W). Without them the matching cannot be verified and the experimental calibration matrices cannot be checked against the proof hypotheses.
Authors: We agree that the abstract should explicitly reference the structural assumptions to make the matching claim verifiable. In the body of the manuscript (Section 3.2 and Theorem 3), the assumptions are stated as: (i) the calibration matrix X satisfies a bounded incoherence condition with parameter μ, and (ii) the weight matrix admits a spectral decay such that the residual after rank-r projection is controlled by the singular values. These are the 'natural structural assumptions' referenced. We will revise the abstract to include a concise parenthetical statement of these conditions (e.g., 'under bounded incoherence of X and spectral decay of W'). This change will allow readers to check the hypotheses against both the proofs and the experimental calibration matrices without altering any theorems or empirical results. revision: yes
Circularity Check
Derivation chain is self-contained; no circular reductions identified
full rationale
The paper derives information-theoretic lower bounds independently for the layer-wise reconstruction objective under finite-alphabet and bounded low-rank constraints. It then proposes the GPTQ-intrinsic LoRA algorithm that augments the Hessian and proves upper bounds for the specific choice L = V_r (top right singular vectors of X), replacing the usual ||X||_F^2 term with the residual ||X - X_r||_F^2. The claim that these bounds match in dominant scaling occurs only under separately stated 'natural structural assumptions' on the data or weights; these assumptions are not shown to be defined in terms of the target result or to reduce the upper bounds to a fitted quantity by construction. No self-citations, ansatzes smuggled via prior work, or renaming of known results appear as load-bearing steps in the abstract or described chain. The overall derivation therefore retains independent mathematical content.
Axiom & Free-Parameter Ledger
free parameters (1)
- rank r
axioms (1)
- domain assumption Natural structural assumptions on calibration data or weights
Reference graph
Works this paper leans on
-
[1]
Ashkboos, A
S. Ashkboos, A. Mohtashami, M. L. Croci, B. Li, P. Cameron, M. Jaggi, D. Alistarh, T. Hoefler, and J. Hensman. Quarot: Outlier-free 4-bit inference in rotated llms.Advances in Neural Information Processing Systems, 37:100213–100240, 2024
2024
-
[2]
Bailleul
A. Bailleul. Explicit kronecker–weyl theorems and applications to prime number races.Research in Number Theory, 8(3):43, 2022
2022
-
[3]
Bertsimas, R
D. Bertsimas, R. Cory-Wright, and N. A. Johnson. Sparse plus low rank matrix decomposition: A discrete optimization approach.Journal of Machine Learning Research, 24(267):1–51, 2023
2023
-
[4]
E. J. Candes and Y. Plan. Tight oracle inequalities for low-rank matrix recovery from a minimal number of noisy random measurements.IEEE Transactions on Information Theory, 57(4):2342–2359, 2011
2011
-
[5]
E. J. Cand` es, X. Li, Y. Ma, and J. Wright. Robust principal component analysis?Journal of the ACM (JACM), 58(3):1–37, 2011
2011
-
[6]
J. Chee, Y. Cai, V. Kuleshov, and C. M. De Sa. Quip: 2-bit quantization of large language models with guarantees.Advances in Neural Information Processing Systems, 36:4396–4429, 2023
2023
- [7]
-
[8]
Chen, H.-F
P. Chen, H.-F. Yu, I. Dhillon, and C.-J. Hsieh. Drone: Data-aware low-rank compression for large nlp models.Advances in neural information processing systems, 34:29321–29334, 2021
2021
- [9]
- [10]
-
[11]
R. Child. Generating long sequences with sparse transformers.arXiv preprint arXiv:1904.10509, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[12]
Y. Cho, D. Jeon, S. Kim, M. Jeon, and A. No. Preserve-then-quantize: Balancing rank budgets for quantization error reconstruction in llms.arXiv preprint arXiv:2602.02001, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
J. Cook, J. Guo, G. Xiao, Y. Lin, and S. Han. Four over six: More accurate nvfp4 quantization with adaptive block scaling.arXiv preprint arXiv:2512.02010, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[15]
L. Deng, G. Li, S. Han, L. Shi, and Y. Xie. Model compression and hardware acceleration for neural networks: A comprehensive survey.Proceedings of the IEEE, 108(4):485–532, 2020
2020
- [16]
-
[17]
T. Dettmers, R. Svirschevski, V. Egiazarian, D. Kuznedelev, E. Frantar, S. Ashkboos, A. Borzunov, T. Hoefler, and D. Alistarh. Spqr: A sparse-quantized representation for near-lossless llm weight compression.arXiv preprint arXiv:2306.03078, 2023
-
[18]
Dettmers, A
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer. Qlora: Efficient finetuning of quantized llms.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[19]
Eckart and G
C. Eckart and G. Young. The approximation of one matrix by another of lower rank.Psychometrika, 1 (3):211–218, 1936. 23
1936
-
[20]
V. Egiazarian, R. L. Castro, D. Kuznedelev, A. Panferov, E. Kurtic, S. Pandit, A. Marques, M. Kurtz, S. Ashkboos, T. Hoefler, et al. Bridging the gap between promise and performance for microscaling fp4 quantization.arXiv preprint arXiv:2509.23202, 2025
-
[21]
Frantar and D
E. Frantar and D. Alistarh. Optimal brain compression: A framework for accurate post-training quantization and pruning.Advances in Neural Information Processing Systems, 35:4475–4488, 2022
2022
-
[22]
Frantar and D
E. Frantar and D. Alistarh. Sparsegpt: Massive language models can be accurately pruned in one-shot. InInternational conference on machine learning, pages 10323–10337. PMLR, 2023
2023
-
[23]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
E. Frantar, U. Evci, W. Park, N. Houlsby, and D. Alistarh. Compression scaling laws: Unifying sparsity and quantization.arXiv preprint arXiv:2502.16440, 2025
-
[25]
Gholami, S
A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer. A survey of quantization methods for efficient neural network inference. InLow-power computer vision, pages 291–326. Chapman and Hall/CRC, 2022
2022
- [26]
-
[27]
Halko, P.-G
N. Halko, P.-G. Martinsson, and J. A. Tropp. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions.SIAM review, 53(2):217–288, 2011
2011
-
[28]
Hassibi and D
B. Hassibi and D. Stork. Second order derivatives for network pruning: Optimal brain surgeon.Advances in neural information processing systems, 5, 1992
1992
-
[29]
Hassibi, D
B. Hassibi, D. G. Stork, and G. J. Wolff. Optimal brain surgeon and general network pruning. InIEEE international conference on neural networks, pages 293–299. IEEE, 1993
1993
-
[30]
Hoefler, D
T. Hoefler, D. Alistarh, T. Ben-Nun, N. Dryden, and A. Peste. Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks.Journal of Machine Learning Research, 22 (241):1–124, 2021
2021
-
[31]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
Hubara, Y
I. Hubara, Y. Nahshan, Y. Hanani, R. Banner, and D. Soudry. Accurate post training quantization with small calibration sets. InInternational conference on machine learning, pages 4466–4475. PMLR, 2021
2021
- [33]
-
[34]
Ikebe, T
Y. Ikebe, T. Inagaki, and S. Miyamoto. The monotonicity theorem, cauchy’s interlace theorem, and the courant-fischer theorem.The American Mathematical Monthly, 94(4):352–354, 1987
1987
-
[35]
gptq.https://github.com/ist-daslab/gptq, 2022
IST-DASLab. gptq.https://github.com/ist-daslab/gptq, 2022
2022
- [36]
-
[37]
Kuzmin, M
A. Kuzmin, M. Nagel, M. Van Baalen, A. Behboodi, and T. Blankevoort. Pruning vs quantization: Which is better?Advances in neural information processing systems, 36:62414–62427, 2023
2023
-
[38]
LeCun, J
Y. LeCun, J. Denker, and S. Solla. Optimal brain damage.Advances in neural information processing systems, 2, 1989. 24
1989
- [39]
- [40]
- [41]
- [42]
-
[43]
Liang, J
T. Liang, J. Glossner, L. Wang, S. Shi, and X. Zhang. Pruning and quantization for deep neural network acceleration: A survey.Neurocomputing, 461:370–403, 2021
2021
- [44]
- [45]
-
[46]
Z. Liu, J. Yuan, H. Jin, S. Zhong, Z. Xu, V. Braverman, B. Chen, and X. Hu. Kivi: A tuning-free asymmetric 2bit quantization for kv cache.arXiv preprint arXiv:2402.02750, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Z. Liu, C. Zhao, I. Fedorov, B. Soran, D. Choudhary, R. Krishnamoorthi, V. Chandra, Y. Tian, and T. Blankevoort. Spinquant–llm quantization with learned rotations.arXiv preprint arXiv:2405.16406, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Lybrand and R
E. Lybrand and R. Saab. A greedy algorithm for quantizing neural networks.Journal of Machine Learning Research, 22(156):1–38, 2021
2021
-
[49]
Maalouf, I
A. Maalouf, I. Jubran, and D. Feldman. Fast and accurate least-mean-squares solvers.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[50]
Maalouf, I
A. Maalouf, I. Jubran, and D. Feldman. Fast and accurate least-mean-squares solvers for high dimensional data.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(12):9977–9994, 2022
2022
-
[51]
Pointer Sentinel Mixture Models
S. Merity, C. Xiong, J. Bradbury, and R. Socher. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [52]
-
[53]
Panferov, A
A. Panferov, A. Volkova, I.-V. Modoranu, V. Egiazarian, M. Safaryan, and D. Alistarh. Unified scaling laws for compressed representations.Advances in Neural Information Processing Systems, 38: 151086–151112, 2026
2026
-
[54]
Paszke, S
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, et al. PyTorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[55]
R. Saha, N. Sagan, V. Srivastava, A. Goldsmith, and M. Pilanci. Compressing large language models using low rank and low precision decomposition.Advances in Neural Information Processing Systems, 37:88981–89018, 2024
2024
-
[56]
I. G. Shevtsova. Sharpening of the upper bound of the absolute constant in the berry–esseen inequality. Theory of Probability & Its Applications, 51(3):549–553, 2007
2007
-
[57]
Takane and M
Y. Takane and M. A. Hunter. Constrained principal component analysis: a comprehensive theory. Applicable Algebra in Engineering, Communication and Computing, 12:391–419, 2001. 25
2001
-
[58]
Takane and H
Y. Takane and H. Hwang. Regularized linear and kernel redundancy analysis.Computational Statistics & Data Analysis, 52(1):394–405, 2007
2007
-
[59]
Takane and S
Y. Takane and S. Jung. Regularized partial and/or constrained redundancy analysis.Psychometrika, 73: 671–690, 2008
2008
-
[60]
Tanner and S
J. Tanner and S. Vary. Compressed sensing of low-rank plus sparse matrices.Applied and Computational Harmonic Analysis, 64:254–293, 2023
2023
-
[61]
J. M. Ten Berge.Least squares optimization in multivariate analysis. DSWO Press, Leiden University Leiden, 1993
1993
-
[62]
Touvron, M
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. J´ egou. Training data-efficient image transformers & distillation through attention. InInternational conference on machine learning, pages 10347–10357. PMLR, 2021
2021
-
[63]
Touvron, M
H. Touvron, M. Cord, and H. J´ egou. Deit iii: Revenge of the vit. InEuropean conference on computer vision, pages 516–533. Springer, 2022
2022
- [64]
-
[65]
Vershynin
R. Vershynin. High-dimensional probability.University of California, Irvine, 10:11, 2020
2020
-
[66]
Y. Wang, H. Wang, and S. Q. Zhang. Qsvd: Efficient low-rank approximation for unified query-key-value weight compression in low-precision vision-language models.Advances in Neural Information Processing Systems, 38:1789–1820, 2026
2026
-
[67]
L. Wei, Z. Ma, C. Yang, and Q. Yao. Advances in the neural network quantization: A comprehensive review.Applied Sciences, 14(17):7445, 2024
2024
-
[68]
ResNet strikes back: An improved training procedure in timm
R. Wightman, H. Touvron, and M. Cordts. Resnet strikes back: An improved training procedure in timm.arXiv preprint arXiv:2110.00476, 2021
-
[69]
T. Wolf, L. Debut, V. Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, et al. Transformers: State-of-the-art natural language processing. InProceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations, pages 38–45, 2020
2020
-
[70]
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning, pages 38087–38099. PMLR, 2023
2023
- [71]
-
[72]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
G. Yang, C. He, J. Guo, J. Wu, Y. Ding, A. Liu, H. Qin, P. Ji, and X. Liu. Llmcbench: Benchmarking large language model compression for efficient deployment.Advances in Neural Information Processing Systems, 37:87532–87544, 2024
2024
- [74]
-
[75]
Yu and J
H. Yu and J. Wu. Compressing transformers: features are low-rank, but weights are not! InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 11007–11015, 2023. 26
2023
-
[76]
X. Yu, T. Liu, X. Wang, and D. Tao. On compressing deep models by low rank and sparse decomposition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7370–7379, 2017
2017
- [77]
- [78]
- [79]
-
[80]
Provable Post-Training Quantization: Theoretical Analysis of OPTQ and Qronos
H. Zhang, S. Zhang, I. Colbert, and R. Saab. Provable post-training quantization: Theoretical analysis of optq and qronos.arXiv preprint arXiv:2508.04853, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.