Online Shift Detection and Conformal Adaptation for Deployed Safety Classifiers
Pith reviewed 2026-06-27 10:17 UTC · model grok-4.3
The pith
An online monitoring system detects distributional shifts in safety classifiers and adapts thresholds via conformal abstention to hold error at 0.1.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that an online system for shift detection using calibrated sequential statistics, followed by conformal adaptation of thresholds, maintains reliable performance for safety classifiers under various distributional shifts, as shown by 86.6% valid detection rate and 39.5 step mean latency in a factorial experiment covering synthetic, jailbreak, and adversarial scenarios.
What carries the argument
Calibrated sequential statistics for online shift detection and weighted conformal prediction with logistic density ratio estimation for importance weighting, augmented by PCA to 32 dimensions when needed.
If this is right
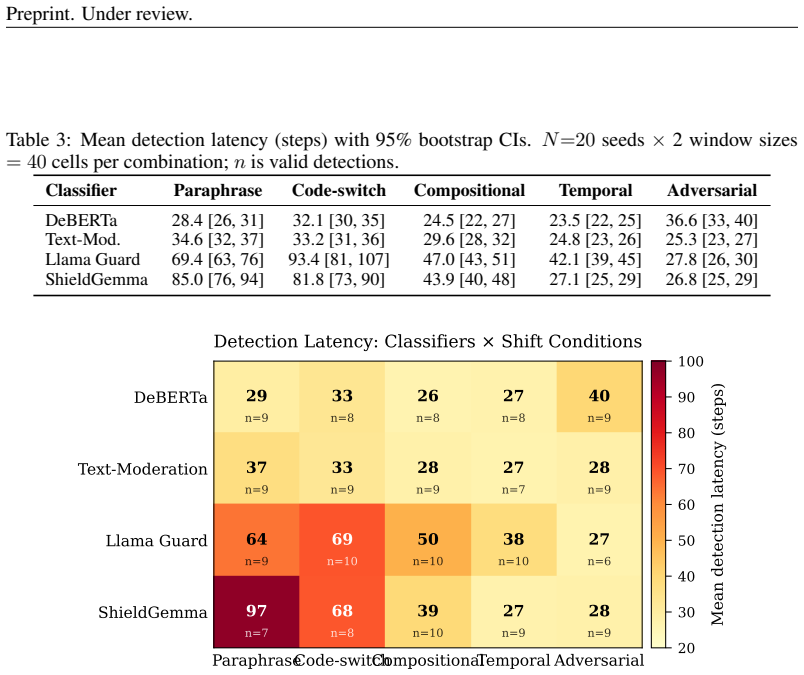
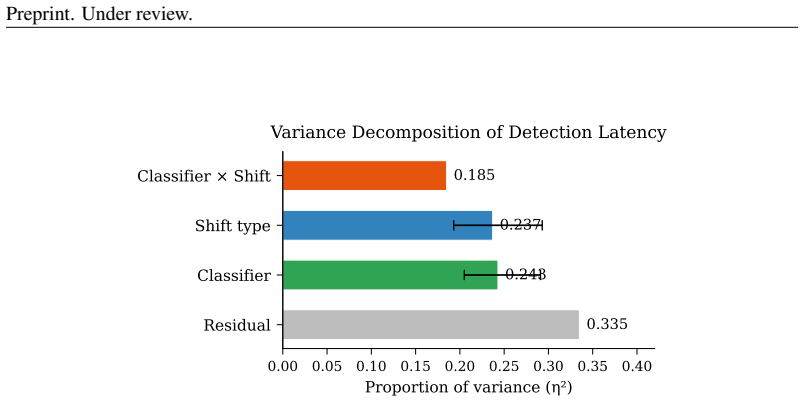
- Classifier type, shift type, and their interaction all contribute substantially to variation in detection latency, requiring tailored monitoring for each classifier.
- Weighted conformal prediction recovers up to 39 percentage points of lost coverage for DeBERTa but collapses for other classifiers unless PCA dimensionality reduction is applied.
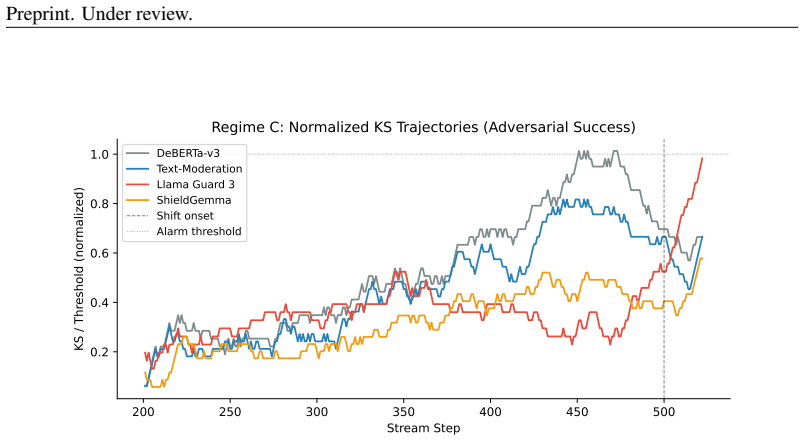
- The system detects shifts effectively across synthetic onset, real temporal jailbreaks, and GCG adversarial attacks.
- Importance weighting via logistic density ratio estimation achieves perfect separability in high-dimensional spaces but clips weights, necessitating alternatives like PCA for recovery.
Where Pith is reading between the lines
- Similar monitoring could be applied to other types of deployed machine learning models facing distributional shifts, such as in medical or autonomous systems.
- Future work might explore alternative importance weighting methods that avoid the separability issues seen in high-dimensional embeddings.
- Reducing dimensionality with PCA before applying conformal methods may be a general strategy for improving robustness in high-dimensional settings.
Load-bearing premise
Logistic density ratio estimation for importance weighting will achieve separability or PCA reduction to 32 dimensions will recover performance of weighted conformal prediction, which otherwise collapses for most classifiers.
What would settle it
A replication of the 800-cell factorial evaluation that yields valid detection below 80 percent or shows no coverage recovery after PCA reduction would indicate the claimed reliability does not hold.
Figures
read the original abstract
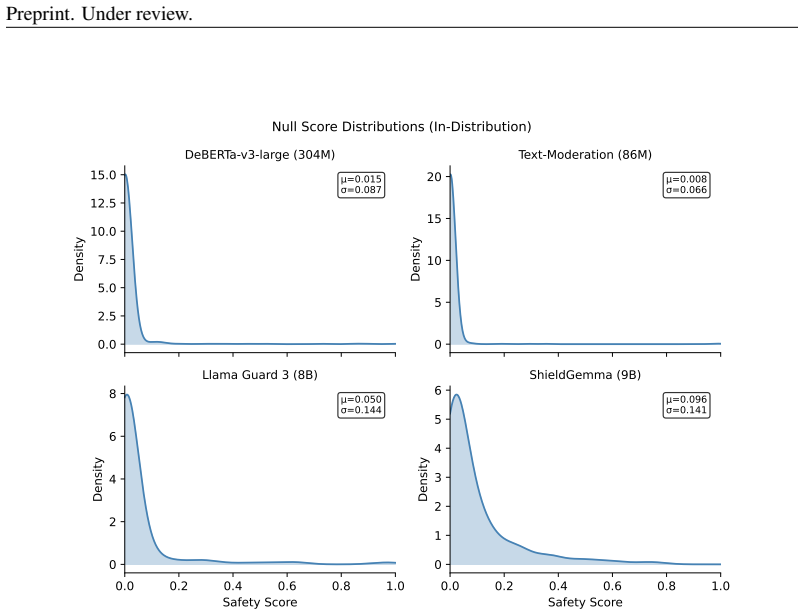
We present an online monitoring system for distributional shift in deployed safety classifiers, using calibrated sequential statistics to detect when a classifier has moved out of distribution. Upon detection, a conformal abstention layer adapts decision thresholds to recover a target error rate epsilon=0.1. In a pre-registered factorial evaluation (4 classifiers x 5 shift conditions x 20 seeds x 2 window sizes, 800 cells), the system achieves 86.6% valid detection (693/800, 95% CI [84.1%, 88.8%]) with mean latency of 39.5 steps. Detection holds across three ground-truth regimes: synthetic onset (86.6%), real temporal jailbreaks (85%, 17/20), and GCG adversarial attacks. Weighted conformal prediction recovers up to 39 pp of lost coverage for DeBERTa (ESS=46/300) but collapses for all other classifiers (ESS~300): logistic density ratio estimation achieves perfect source/target separability in high-dimensional embedding spaces, clipping all importance weights to the floor. DeBERTa shows a gradient from effective correction (paraphrase, ESS=46) to near-total collapse (adversarial suffix, ESS=206). PCA to 32 dimensions breaks the collapse, recovering 33 pp for Llama Guard and 21 pp for ShieldGemma. Variance decomposition reveals classifier (eta^2=0.243), shift type (eta^2=0.237), and their interaction (eta^2=0.185) all contribute substantially to detection latency variance (all p<0.001), indicating per-classifier monitoring profiles are necessary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an online monitoring system for distributional shift in deployed safety classifiers, using calibrated sequential statistics to detect shifts and, upon detection, a conformal abstention layer with weighted conformal prediction (via logistic density ratio estimation for importance weights) to adapt thresholds and recover a target error rate ε=0.1. In a pre-registered factorial evaluation (4 classifiers × 5 shift conditions × 20 seeds × 2 window sizes = 800 cells), it reports 86.6% valid detection (693/800, 95% CI [84.1%, 88.8%]) with mean latency 39.5 steps, holding across synthetic onset, real temporal jailbreaks, and GCG adversarial attacks. Weighted conformal prediction recovers up to 39 pp coverage for DeBERTa but collapses for other classifiers due to perfect source/target separability in high-dimensional embeddings (ESS ~300, weights clipped); PCA to 32 dimensions recovers 33 pp for Llama Guard and 21 pp for ShieldGemma. Variance decomposition shows classifier (η²=0.243), shift type (η²=0.237), and interaction (η²=0.185) effects on latency (all p<0.001).
Significance. If the results hold, the work provides a practical framework for monitoring and adapting safety classifiers in deployment, with credible empirical support from the pre-registered 800-cell design, multiple ground-truth regimes, and transparent reporting of conformal adaptation collapse cases. The variance decomposition and explicit documentation of effective sample sizes strengthen the detection claims; the pre-registered design and falsifiable performance metrics (e.g., 86.6% detection rate) are notable strengths.
major comments (2)
- [Abstract and adaptation results] Abstract and weighted conformal prediction results: the adaptation claim (recovering target ε=0.1 via importance-weighted conformal prediction) is load-bearing for the system's utility, yet the reported collapse for all classifiers except DeBERTa (due to perfect separability in logistic density ratio estimation) is only mitigated by PCA reduction to 32 dimensions, which recovers 33 pp for Llama Guard and 21 pp for ShieldGemma. No ablation or independent justification is provided for the specific choice of 32 dimensions or for the stability of the resulting weights across embedding spaces.
- [Abstract and adaptation results] Abstract, ESS values: for DeBERTa the effective sample size drops to 46/300 under paraphrase shift (and 206/300 under adversarial suffix), indicating that even when adaptation 'recovers' coverage the importance weights remain unreliable; this undermines the general claim that the conformal layer adapts decision thresholds upon detection.
minor comments (2)
- [Abstract] Notation: 'eta^2' in the variance decomposition should be rendered as η² (partial eta-squared) for standard statistical presentation.
- [Abstract] Clarity: the three ground-truth regimes (synthetic onset, real temporal jailbreaks, GCG attacks) are listed but would benefit from a brief explicit definition or reference to their implementation details in the methods.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the pre-registered 800-cell design, variance decomposition, and transparent reporting. We address the two major comments on the conformal adaptation results below.
read point-by-point responses
-
Referee: [Abstract and adaptation results] Abstract and weighted conformal prediction results: the adaptation claim (recovering target ε=0.1 via importance-weighted conformal prediction) is load-bearing for the system's utility, yet the reported collapse for all classifiers except DeBERTa (due to perfect separability in logistic density ratio estimation) is only mitigated by PCA reduction to 32 dimensions, which recovers 33 pp for Llama Guard and 21 pp for ShieldGemma. No ablation or independent justification is provided for the specific choice of 32 dimensions or for the stability of the resulting weights across embedding spaces.
Authors: We agree that the manuscript would benefit from explicit justification and an ablation for the 32-dimensional PCA choice. This value was selected in preliminary work to sufficiently decorrelate the embeddings and avoid perfect source/target separability in the logistic density-ratio model while retaining the majority of variance; however, we acknowledge the lack of systematic reporting. In the revision we will add a supplementary ablation across 16/32/64/128 components, reporting ESS, weight stability, and coverage recovery for each classifier-shift pair to justify the operating point. revision: yes
-
Referee: [Abstract and adaptation results] Abstract, ESS values: for DeBERTa the effective sample size drops to 46/300 under paraphrase shift (and 206/300 under adversarial suffix), indicating that even when adaptation 'recovers' coverage the importance weights remain unreliable; this undermines the general claim that the conformal layer adapts decision thresholds upon detection.
Authors: The manuscript already reports these ESS values transparently and documents the resulting collapse cases. We do not advance a general claim of reliable adaptation across all settings; the results are presented as conditional on the separability of the embedding spaces. In revision we will add explicit language in the discussion that adaptation is reliable only when ESS exceeds a practical threshold (e.g., >100) and that near-perfect separability requires alternative methods. This clarifies rather than overstates the scope of the conformal layer. revision: partial
Circularity Check
No circularity: results are direct empirical measurements from pre-registered experiments
full rationale
The paper reports outcomes from a pre-registered factorial experiment (4 classifiers × 5 shifts × 20 seeds × 2 windows) measuring detection rates, latency, ESS, and coverage recovery under weighted conformal prediction. No derivation chain, equations, or first-principles predictions are presented that reduce to fitted inputs, self-definitions, or self-citations by construction. Claims about PCA recovering performance and variance decomposition are post-hoc analyses of experimental data, not load-bearing derivations. The design is externally falsifiable via the stated metrics and conditions.
Axiom & Free-Parameter Ledger
free parameters (2)
- target error rate epsilon =
0.1
- window sizes
axioms (1)
- domain assumption Calibrated sequential statistics reliably detect distributional shifts in the input stream
Reference graph
Works this paper leans on
-
[1]
Annals of Mathematical Statistics , volume=
Sequential tests of statistical hypotheses , author=. Annals of Mathematical Statistics , volume=
-
[2]
Journal of the Royal Statistical Society Series B , volume=
Estimating means of bounded random variables by betting , author=. Journal of the Royal Statistical Society Series B , volume=
-
[3]
JMLR , volume=
A kernel two-sample test , author=. JMLR , volume=
-
[4]
NeurIPS , year=
B-tests: Low variance kernel two-sample tests , author=. NeurIPS , year=
-
[5]
Algorithmic Learning in a Random World , author=
-
[6]
NeurIPS , year=
Conformal prediction under covariate shift , author=. NeurIPS , year=
-
[7]
NeurIPS , year=
Adaptive conformal inference under distribution shift , author=. NeurIPS , year=
-
[8]
NeurIPS , year=
Classification with valid and adaptive coverage , author=. NeurIPS , year=
-
[9]
ICLR , year=
Leveraging unlabeled data to predict out-of-distribution performance , author=. ICLR , year=
-
[10]
NeurIPS , year=
Failing loudly: An empirical study of methods for detecting dataset shift , author=. NeurIPS , year=
-
[12]
arXiv preprint arXiv:2406.18495 , year=
WildGuard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLMs , author=. arXiv preprint arXiv:2406.18495 , year=
-
[13]
arXiv preprint arXiv:2312.06674 , year=
Llama Guard: LLM-based input-output safeguard for human-AI conversations , author=. arXiv preprint arXiv:2312.06674 , year=
-
[14]
arXiv preprint arXiv:2407.21772 , year=
ShieldGemma: Generative AI content moderation based on Gemma , author=. arXiv preprint arXiv:2407.21772 , year=
-
[15]
Neurocomputing , year=
Reactive Soft Prototype Computing for Concept Drift Streams , author=. Neurocomputing , year=
-
[16]
ICLR , year=
Tracking the risk of a deployed model and detecting harmful distribution shifts , author=. ICLR , year=
-
[17]
2025 , note=
Prinster, Drew and Han, Xing and Liu, Anqi and Saria, Suchi , booktitle=. 2025 , note=
2025
-
[19]
NeurIPS , year=
Telescoping Density-Ratio Estimation , author=. NeurIPS , year=
-
[20]
Brittlebench: Quantifying
Romanou, Angelika and Ibrahim, Mark and Ross, Candace and Shaib, Chantal and Oktar, Kerem and Bell, Samuel J and Ovalle, Anaelia and Dodge, Jesse and Bosselut, Antoine and Sinha, Koustuv and Williams, Adina , journal=. Brittlebench: Quantifying
-
[21]
AISTATS , pages=
Low-Dimensional Density Ratio Estimation for Covariate Shift Correction , author=. AISTATS , pages=. 2019 , volume=
2019
-
[22]
Neural Networks , volume=
Direct density-ratio estimation with dimensionality reduction via least-squares hetero-distributional subspace search , author=. Neural Networks , volume=
-
[24]
Leveraging unlabeled data to predict out-of-distribution performance
Saurabh Garg, Sivaraman Balakrishnan, Zachary C Lipton, Behnam Neyshabur, and Hanie Sedghi. Leveraging unlabeled data to predict out-of-distribution performance. In ICLR, 2022
2022
-
[25]
Adaptive conformal inference under distribution shift
Isaac Gibbs and Emmanuel Cand \`e s. Adaptive conformal inference under distribution shift. In NeurIPS, 2021
2021
-
[26]
A kernel two-sample test
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Sch \"o lkopf, and Alexander Smola. A kernel two-sample test. JMLR, 13: 0 723--773, 2012
2012
-
[27]
Tracking the risk of a deployed model and detecting harmful distribution shifts
Aleksandr Podkopaev and Aaditya Ramdas. Tracking the risk of a deployed model and detecting harmful distribution shifts. In ICLR, 2022. arXiv:2110.06177
arXiv 2022
-
[28]
WATCH : Adaptive monitoring for AI deployments via weighted-conformal martingales
Drew Prinster, Xing Han, Anqi Liu, and Suchi Saria. WATCH : Adaptive monitoring for AI deployments via weighted-conformal martingales. In International Conference on Machine Learning (ICML), 2025. arXiv:2505.04608
arXiv 2025
-
[29]
Reactive soft prototype computing for concept drift streams
Christoph Raab, Moritz Heusinger, and Frank-Michael Schleif. Reactive soft prototype computing for concept drift streams. Neurocomputing, 2020. arXiv:2007.05432
arXiv 2020
-
[30]
Failing loudly: An empirical study of methods for detecting dataset shift
Stephan Rabanser, Stephan G \"u nnemann, and Zachary C Lipton. Failing loudly: An empirical study of methods for detecting dataset shift. In NeurIPS, 2019
2019
-
[31]
Telescoping density-ratio estimation
Benjamin Rhodes, Kai Xu, and Michael U Gutmann. Telescoping density-ratio estimation. In NeurIPS, 2020
2020
-
[32]
Classification with valid and adaptive coverage
Yaniv Romano, Matteo Sesia, and Emmanuel Cand \`e s. Classification with valid and adaptive coverage. In NeurIPS, 2020
2020
-
[33]
Brittlebench: Quantifying LLM robustness via prompt sensitivity
Angelika Romanou, Mark Ibrahim, Candace Ross, Chantal Shaib, Kerem Oktar, Samuel J Bell, Anaelia Ovalle, Jesse Dodge, Antoine Bosselut, Koustuv Sinha, and Adina Williams. Brittlebench: Quantifying LLM robustness via prompt sensitivity. arXiv preprint arXiv:2603.13285, 2026
Pith/arXiv arXiv 2026
-
[34]
I can't believe it's not robust: Catastrophic collapse of safety classifiers under embedding drift
Subramanyam Sahoo, Vinija Jain, Divya Chaudhary, and Aman Chadha. I can't believe it's not robust: Catastrophic collapse of safety classifiers under embedding drift. arXiv preprint arXiv:2603.01297, 2026
arXiv 2026
-
[35]
Low-dimensional density ratio estimation for covariate shift correction
Petar Stojanov, Mingming Gong, Jaime Carbonell, and Kun Zhang. Low-dimensional density ratio estimation for covariate shift correction. In AISTATS, volume 89 of PMLR, pp.\ 3449--3458, 2019
2019
-
[36]
Direct density-ratio estimation with dimensionality reduction via least-squares hetero-distributional subspace search
Masashi Sugiyama, Makoto Yamada, Paul von B \"u nau, Taiji Suzuki, Takafumi Kanamori, and Motoaki Kawanabe. Direct density-ratio estimation with dimensionality reduction via least-squares hetero-distributional subspace search. Neural Networks, 24 0 (2): 0 183--198, 2011
2011
-
[37]
Conformal prediction under covariate shift
Ryan J Tibshirani, Rina Foygel Barber, Emmanuel Cand \`e s, and Aaditya Ramdas. Conformal prediction under covariate shift. In NeurIPS, 2019
2019
-
[38]
Guillermo Villate-Castillo, Javier Del Ser, and Borja Sanz. A collaborative content moderation framework for toxicity detection based on conformalized estimates of annotation disagreement. arXiv preprint arXiv:2411.04090, 2024
arXiv 2024
-
[39]
Algorithmic Learning in a Random World
Vladimir Vovk, Alex Gammerman, and Glenn Shafer. Algorithmic Learning in a Random World. Springer, 2005
2005
-
[40]
Sequential tests of statistical hypotheses
Abraham Wald. Sequential tests of statistical hypotheses. Annals of Mathematical Statistics, 16 0 (2): 0 117--186, 1945
1945
-
[41]
Estimating means of bounded random variables by betting
Ian Waudby-Smith and Aaditya Ramdas. Estimating means of bounded random variables by betting. Journal of the Royal Statistical Society Series B, 86 0 (1): 0 1--27, 2024
2024
-
[42]
B-tests: Low variance kernel two-sample tests
Wojciech Zaremba, Arthur Gretton, and Matthew Blaschko. B-tests: Low variance kernel two-sample tests. In NeurIPS, 2013
2013
-
[43]
Universal and transferable adversarial attacks on aligned language models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.