PRPO: Perception-Reinforced Policy Optimization via Token-Level Dynamic Advantage Reshaping
Pith reviewed 2026-06-27 18:23 UTC · model grok-4.3
The pith
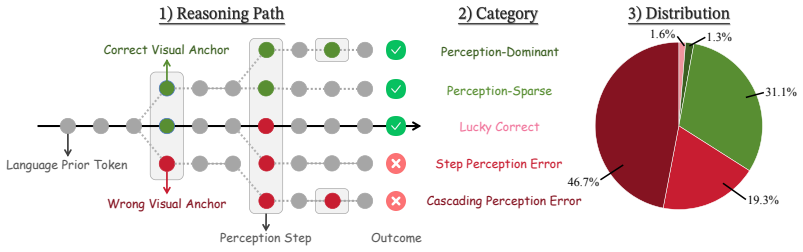
Token-level credit assignment for visually grounded tokens lifts LVLM reasoning performance by over 20 percent on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PRPO identifies tokens whose next-token predictions remain consistent under visual perturbations and then rescales their advantages upward while leaving non-visual tokens unchanged; the resulting policy updates produce consistent gains of 23.3 percent on 3B models and 21.1 percent on 7B models relative to strong trajectory-level baselines.
What carries the argument
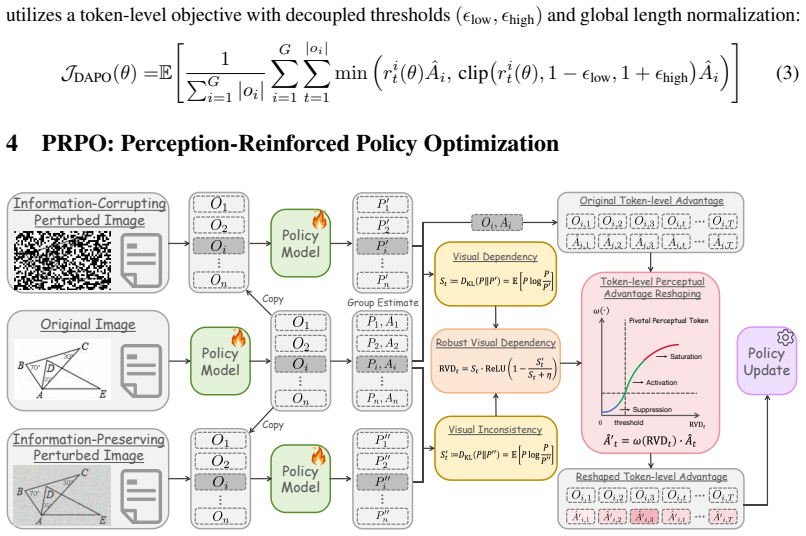
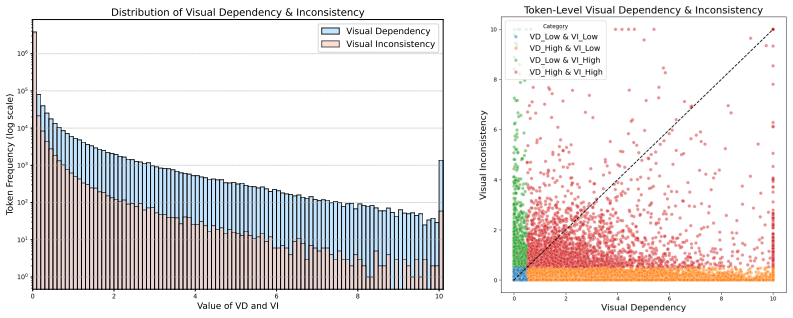
Robust Visual Dependency (RVD) metric combined with Perceptual Advantage Reshaping (PAR) that amplifies advantages only for tokens that are both visually grounded and perturbation-stable.
If this is right
- Average accuracy on seven multimodal reasoning benchmarks rises by 23.3 percent for 3B models and 21.1 percent for 7B models.
- Training converges with fewer gradient steps than trajectory-level RLVR baselines.
- The same policy transfers more effectively to unseen multimodal tasks.
- Non-perceptual tokens retain stable gradient magnitudes, avoiding collapse of language-only capabilities.
Where Pith is reading between the lines
- The same token-level filtering could be applied to pure language reasoning by replacing image perturbations with prompt perturbations.
- If RVD proves reliable, it could serve as a diagnostic for when a model is actually using the image versus reciting memorized text.
- Extending PAR to other reward sources, such as human preference scores, might reduce reward hacking in non-verifiable settings.
Load-bearing premise
The assumption that tokens whose predictions survive image perturbation are the ones causally responsible for correct answers rather than merely correlated with them.
What would settle it
A controlled experiment in which PRPO is applied to a model trained only on language priors with no visual input; if performance still rises, the claim that RVD isolates visual grounding collapses.
Figures


read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has become an effective paradigm for improving the reasoning capability of Large Vision-Language Models (LVLMs). However, existing RLVR methods primarily rely on trajectory-level outcome rewards, which assign identical learning signals across all generated tokens. This coarse-grained credit assignment is fundamentally mismatched to multimodal reasoning, where only a sparse subset of tokens is causally grounded in visual evidence. Consequently, these pivotal perceptual tokens receive weak supervision and are often overwhelmed by language priors or reasoning-template tokens. To address this limitation, we propose Perception-Reinforced Policy Optimization (PRPO), a token-level reinforcement learning framework that explicitly identifies and reinforces pivotal perceptual tokens within long-horizon multimodal reasoning trajectories. PRPO introduces Robust Visual Dependency (RVD), a principled metric that identifies tokens whose predictions are both visually grounded and perturbation-stable, filtering out brittle or noisy visual tokens. Based on RVD, we further propose Perceptual Advantage Reshaping (PAR), a token-level credit assignment technique that amplifies perceptually informative tokens while preserving stable gradients for non-perceptual tokens. Extensive experiments on seven multimodal reasoning benchmarks demonstrate that PRPO consistently outperforms strong LVLM baselines across both 3B and 7B model scales, achieving average gains of 23.3% and 21.1%, respectively. PRPO achieves state-of-the-art performance with improved training efficiency and stronger cross-task generalization. Our findings highlight the importance of fine-grained credit assignment for scalable multimodal reinforcement learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Perception-Reinforced Policy Optimization (PRPO), a token-level RLVR framework for LVLMs. It introduces Robust Visual Dependency (RVD) to identify tokens whose predictions are visually grounded and perturbation-stable, and Perceptual Advantage Reshaping (PAR) to amplify advantages for those tokens while preserving gradients for others. The central empirical claim is that PRPO yields average gains of 23.3% (3B) and 21.1% (7B) over strong baselines across seven multimodal reasoning benchmarks, reaching SOTA with improved efficiency and cross-task generalization.
Significance. If the mechanism is shown to isolate visual grounding rather than language priors, the work would meaningfully advance fine-grained credit assignment in multimodal RL, addressing a clear mismatch between trajectory-level rewards and sparse perceptual tokens. The scale of reported gains and the explicit focus on token-level reshaping would be notable contributions if supported by targeted verification.
major comments (2)
- [§3] §3 (Method, RVD definition): The perturbation-stability criterion used to define RVD is not shown to isolate visual evidence; if the perturbations are generic noise rather than targeted visual masking or feature ablation, RVD can select tokens stable due to textual priors or templates. This directly undermines the causal attribution that PAR's amplification produces the reported gains via perceptual reinforcement rather than orthogonal factors.
- [§4] §4 (Experiments): No ablation is reported that isolates the contribution of RVD-selected tokens versus random or language-prior tokens under PAR, nor any controlled visual ablation study (gradient sensitivity, human grounding labels) to falsify the alternative that gains arise from non-perceptual mechanisms. Without this, the headline 23.3%/21.1% gains and SOTA claim rest on an unverified assumption.
minor comments (1)
- The abstract states 'improved training efficiency' but provides no wall-clock, token-throughput, or convergence-curve comparisons to baselines; this should be quantified in §4 if claimed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below with targeted responses and indicate planned revisions to strengthen the validation of RVD's perceptual isolation and the causal role of PAR.
read point-by-point responses
-
Referee: [§3] §3 (Method, RVD definition): The perturbation-stability criterion used to define RVD is not shown to isolate visual evidence; if the perturbations are generic noise rather than targeted visual masking or feature ablation, RVD can select tokens stable due to textual priors or templates. This directly undermines the causal attribution that PAR's amplification produces the reported gains via perceptual reinforcement rather than orthogonal factors.
Authors: We agree that stronger causal isolation of visual grounding is desirable. RVD is defined in §3 as the intersection of visual feature dependency (via gradient-based sensitivity to image regions) and stability under image perturbations. The perturbations are indeed generic noise as implemented, which tests robustness but does not fully rule out language-template effects. We will revise the method section to explicitly discuss this limitation and add a new analysis comparing RVD-selected tokens against those identified by a text-only variant of the model to demonstrate differential behavior attributable to visual input. revision: partial
-
Referee: [§4] §4 (Experiments): No ablation is reported that isolates the contribution of RVD-selected tokens versus random or language-prior tokens under PAR, nor any controlled visual ablation study (gradient sensitivity, human grounding labels) to falsify the alternative that gains arise from non-perceptual mechanisms. Without this, the headline 23.3%/21.1% gains and SOTA claim rest on an unverified assumption.
Authors: The current experiments compare PRPO against trajectory-level RLVR baselines and report consistent gains, but we acknowledge the absence of the specific ablations requested. We will add in the revised §4: (i) an ablation applying PAR to random tokens and to language-prior tokens (selected via a language-only model) for direct comparison, and (ii) gradient sensitivity analysis measuring visual feature influence on RVD tokens versus others. Human grounding labels are not part of our experimental setup or available datasets, so we cannot provide them; we will note this as a limitation and suggest it for future work. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces PRPO as an empirical token-level RL framework with RVD and PAR, validated through experiments on multimodal benchmarks. No equations, derivations, or self-citations are exhibited in the provided text that reduce performance claims to fitted inputs, self-definitions, or load-bearing prior work by the same authors. The central claims rest on experimental gains rather than any closed-form reduction to the method's own definitions or parameters.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Robust Visual Dependency (RVD)
no independent evidence
-
Perceptual Advantage Reshaping (PAR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The original policy distribution is P=π θ(·|I, c), and the perturbed distribution is P ′ =π θ(·| ˜I, c), where ˜I=P(I)
Information-Theoretic Perspective: Bounding Conditional Mutual Information.Let c= (q, o<t) denote the multimodal context comprising the textual query and the historical generation trajectory. The original policy distribution is P=π θ(·|I, c), and the perturbed distribution is P ′ =π θ(·| ˜I, c), where ˜I=P(I). The KL divergence DKL (P∥P ′) quantifies the ...
-
[2]
While St captures semantic dependency, it cannot distinguish whether a high KL value arises from robust visual grounding or brittle numerical over-sensitivity
Information Geometry Perspective: Probing Local Curvature via Fisher Information. While St captures semantic dependency, it cannot distinguish whether a high KL value arises from robust visual grounding or brittle numerical over-sensitivity. To explain the representational power of Visual Inconsistency (S′ t), we analyze the KL divergence under the weak, ...
-
[3]
-∠ADC= 26 ◦
**Identify the given information and the relevant properties:** - AB is the diameter of the circle ⊙O, so ∠ACB= 90 ◦ because the angle subtended by a diameter in a semicircle is always90 ◦. -∠ADC= 26 ◦. - We need to find the measure of∠CAB
-
[4]
Therefore,∠ACD= 2×angle at the center= 2×∠AOD
**Use the inscribed angle theorem:** - The inscribed angle ∠ACD subtends the same arc AD as the central angle ∠AOD. Therefore,∠ACD= 2×angle at the center= 2×∠AOD. - However, ∠ACD is also the sum of ∠ACD and ∠ADC. But since ∠ACB= 90 ◦ and ∠ACD= 90 ◦ −∠CAB, we need to use the fact that∠ACD= 2×∠ADC. - Therefore,∠ACD= 2×26 ◦ = 52 ◦
-
[5]
- Solving for∠CAB, we get∠CAB= 90 ◦ −52 ◦ = 38 ◦
**Determine∠CAB:** - Since∠ACD= 90 ◦ −∠CAB, we have52 ◦ = 90 ◦ −∠CAB. - Solving for∠CAB, we get∠CAB= 90 ◦ −52 ◦ = 38 ◦. However, we need to re-evaluate the problem because the correct approach involves the relationship between the angles in the triangle and the circle. Given the options, we need to consider the correct angle configuration. The correct ang...
-
[6]
**Identify the given information and the goal**: We are given that ∠ADC= 26 ◦ and we need to find the measure of∠CAB
-
[7]
Therefore, ∠ABC=∠ADC= 26 ◦
**Use the fact that ∠ABC and ∠ADC are angles in the same segment**: Since ∠ABC and ∠ADC are angles in the same segment of the circle, they are equal. Therefore, ∠ABC=∠ADC= 26 ◦
-
[8]
**Use the fact that AB is the diameter**: Since AB is the diameter of the circle, ∠ACB= 90 ◦ (this is a property of a right angle in a circle where the angle is subtended by a diameter)
-
[9]
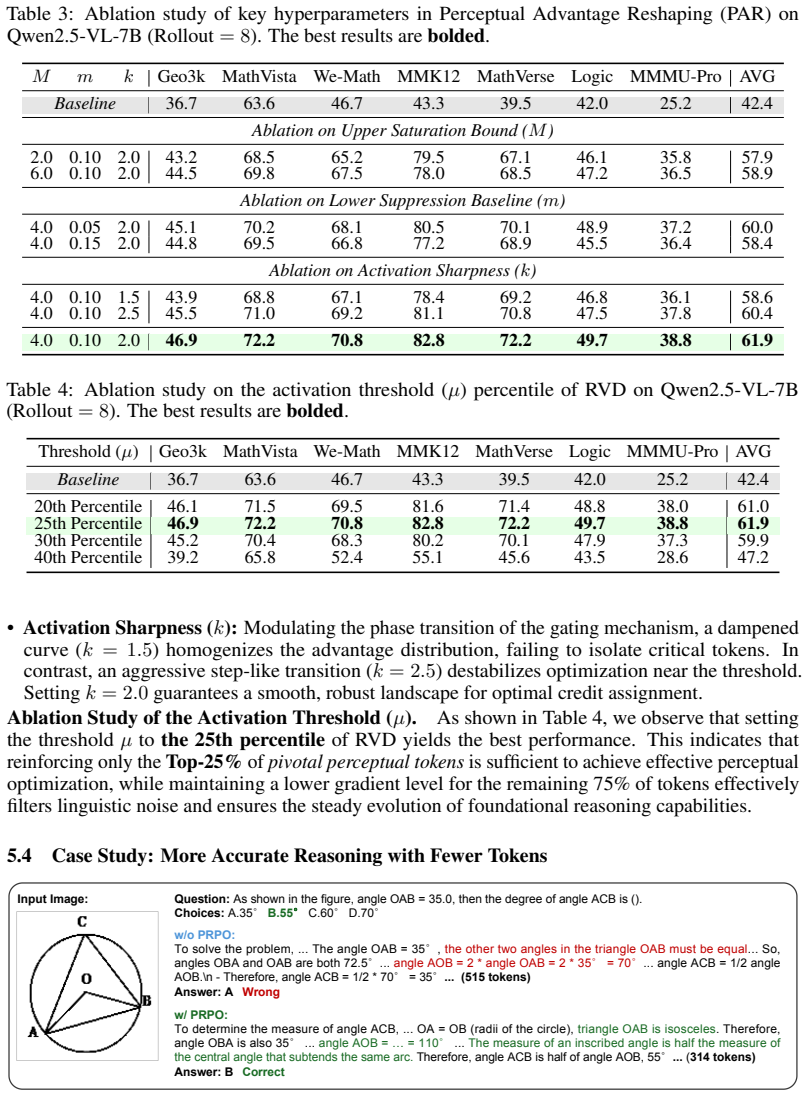
**Find ∠CAB**: In triangle △ABC, the sum of the interior angles is 180 degrees. Therefore, we have: ∠CAB+∠ABC+∠ACB= 180 ◦ Substituting the known values: ∠CAB+ 26 ◦ + 90◦ = 180 ◦ Simplifying this equation: ∠CAB+ 116 ◦ = 180 ◦ ∠CAB= 180 ◦ −116 ◦ ∠CAB= 64 ◦ </think> The answer is: C Correct 22 Case 2 Question:The diagram repre- sents successive rotations, st...
-
[10]
The first shape is rotated to form the second shape
-
[11]
The second shape is rotated to form the third shape
-
[12]
Let’s examine the rotations step by step: - The first shape rotates to form the second shape
We need to identify the pattern in the rotations and apply it to the third shape to find the next one. Let’s examine the rotations step by step: - The first shape rotates to form the second shape. - The second shape rotates to form the third shape. - The third shape should rotate to form the fourth shape. From the given shapes, we can see that each shape ...
-
[13]
The first shape is at the top
-
[14]
The second shape is obtained by rotating the first shape 90 degrees clockwise
-
[15]
The third shape is obtained by rotating the second shape 90 degrees clockwise
-
[16]
Let’s rotate the third shape (the shape at the bottom of the given sequence) 90 de- grees clockwise: - The third shape is a L-shaped configuration of cubes
We need to find the shape that comes next, which means we need to rotate the third shape 90 degrees clockwise. Let’s rotate the third shape (the shape at the bottom of the given sequence) 90 de- grees clockwise: - The third shape is a L-shaped configuration of cubes. - If we rotate it 90 degrees clockwise, it will align with the shape that matches the rot...
-
[17]
A color with high saturation is a pure hue, while a color with low saturation is a light, grayed-out version of that hue (like a pastel color)
**Saturation**: Saturation is the amount of a particular hue. A color with high saturation is a pure hue, while a color with low saturation is a light, grayed-out version of that hue (like a pastel color)
-
[18]
The saturation decreases as you move inward from the outer edge towards the center of the circle
**Hue-Saturation Space**: A circle with the entire spectrum of colors around its circumference represents the pure hues. The saturation decreases as you move inward from the outer edge towards the center of the circle. Given: - Color A is at the outer edge of the circle. - Color B is in the middle of the circle. - Color C is at the inner edge of the circl...
-
[19]
- Color B is located in the middle of the circle, closer to the center
**Identify the position of each color:** - Color A is located at the top of the circle, which is a high-saturation point. - Color B is located in the middle of the circle, closer to the center. - Color C is located at the bottom right, which is a high-saturation point
-
[20]
Limitations
**Determine the distance from the center:** - The center of the circle represents a color with zero saturation (i.e., a grayscale color). - The points A and C are closer to the edge of the circle, indicating higher saturation. - Point B is the closest to the center of the circle, indicating the lowest saturation. Therefore, the color with the smallest sat...
-
[21]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.