Global Convergence and Error Propagation in Neural Gradient Flows: A Riemannian Optimization Framework
Pith reviewed 2026-06-29 15:12 UTC · model grok-4.3
The pith
Neural MMS iterates converge to an O(δ) neighborhood of the global minimum by propagating inner-solver and approximation errors through Riemannian gradient flows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
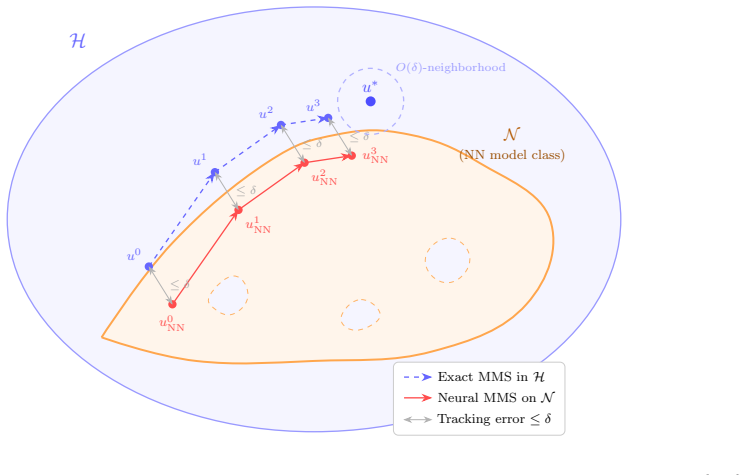
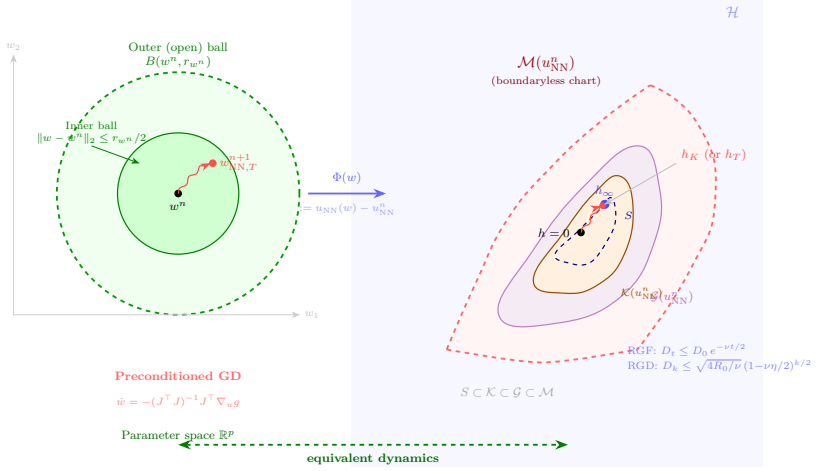
Under a C² network with locally non-degenerate Jacobian, each neural MMS step induces a Riemannian gradient flow on a boundaryless smooth embedded submanifold of increments; when the reached sublevel set is geodesically convex and the subproblem objective is geodesically strongly convex, both the continuous flow and its discrete exponential-map version converge linearly to the unique minimizer, and propagating inner-solver inexactness together with neural approximation error through the MMS iterations yields a uniform function-space tracking bound and explicit trajectory budget that forces the inexact neural sequence to converge to an O(δ)-neighborhood of the global minimum.
What carries the argument
Minimizing movement scheme (MMS) steps reformulated as Riemannian gradient flow on the increment submanifold, with error propagation through iterations producing function-space tracking bounds.
If this is right
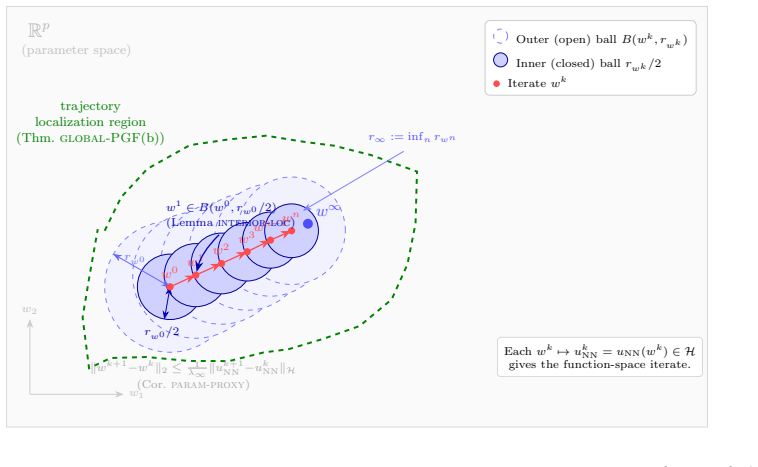
- Both the continuous Riemannian gradient flow and its discrete exponential-map version converge linearly to the unique subproblem minimizer.
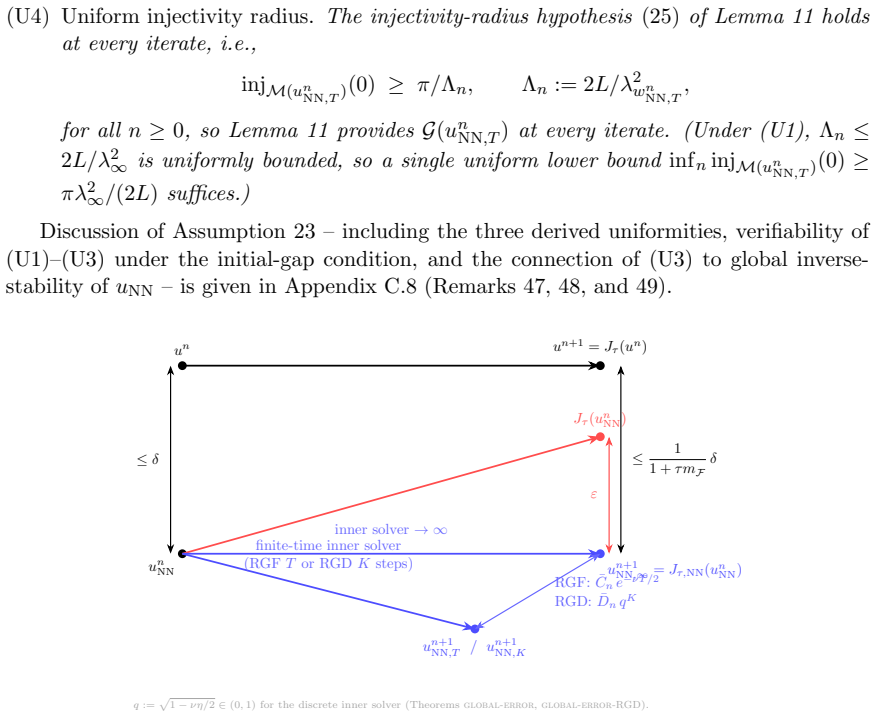
- A uniform function-space tracking bound holds after propagating finite-time inner-solver inexactness and neural-approximation error.
- An explicit trajectory budget controls the total deviation of inexact neural iterates from the exact MMS path.
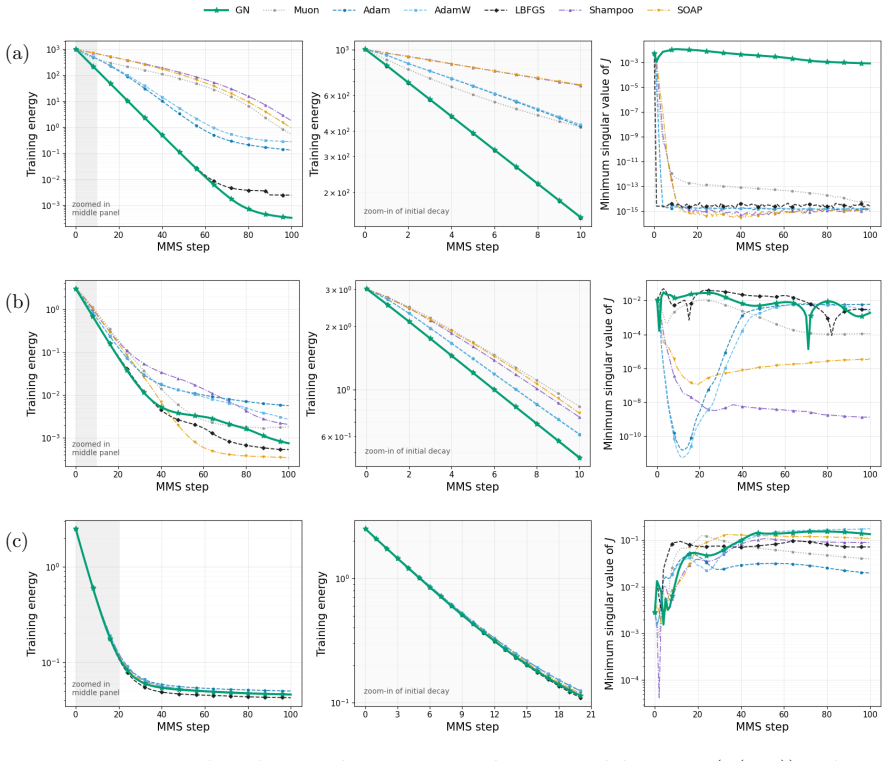
- The Gauss-Newton-type inner solver produces smaller trajectory errors with substantially fewer inner iterations than first-order baselines.
Where Pith is reading between the lines
- The same error-propagation argument could be tested on other first-order optimization schemes that admit a similar Riemannian reformulation.
- Numerical verification on larger latent-diffusion models would check whether the O(δ) neighborhood remains useful when the network width and depth increase.
- Relaxing the geodesic strong-convexity assumption while retaining only local convexity might still yield convergence to stationary points rather than global minima.
Load-bearing premise
The reached sublevel set must be geodesically convex and the subproblem objective must be geodesically strongly convex on it, which requires the strict interior-localization condition and the explicit data condition.
What would settle it
Run the Gauss-Newton inner solver on a nonlinear regression problem where the sublevel set loses geodesic convexity; if the observed trajectory error exceeds the predicted O(δ) bound even as inner iterations increase and network approximation error decreases, the global convergence claim fails.
Figures





read the original abstract
We develop a geometric convergence theory for neural-network optimization within the minimizing movement scheme (MMS) framework. Reformulating each neural MMS step as a minimization over the set of increments in a Hilbert space, we show that under a $C^2$ network with locally non-degenerate Jacobian this increment set is a boundaryless smooth embedded submanifold, on which a natural preconditioned (Gauss--Newton-type) gradient flow in parameter space induces exactly the Riemannian gradient flow. Under a strict interior-localization condition and an explicit data condition, the reached sublevel set is geodesically convex and the subproblem objective is geodesically strongly convex on it; both the continuous Riemannian gradient flow and its discrete companion via the exponential map converge linearly to the unique subproblem minimizer. Propagating finite-time inner-solver inexactness and neural-approximation error through the MMS iterations yields a uniform function-space tracking bound and an explicit trajectory budget, so the inexact neural iterates converge to an $O(\delta)$-neighborhood of the global minimum. Numerical experiments on nonlinear regression and a small-scale latent-diffusion testbed indicate that the Gauss--Newton-type inner solver achieves smaller trajectory errors with substantially fewer inner iterations than first-order baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a geometric convergence theory for neural-network optimization inside the minimizing movement scheme (MMS). Each MMS step is recast as a minimization over increments in a Hilbert space; under C² regularity and locally non-degenerate Jacobian the increment set is shown to be a boundaryless smooth embedded submanifold on which a Gauss–Newton-type parameter-space flow coincides with the Riemannian gradient flow. Under an interior-localization condition together with an explicit data condition the reached sublevel set is geodesically convex and the subproblem is geodesically strongly convex, yielding linear convergence of both the continuous flow and its exponential-map discretization. Finite-time inexactness and neural approximation errors are propagated to obtain a uniform function-space tracking bound and an explicit trajectory budget, so that the inexact neural iterates converge to an O(δ) neighborhood of the global minimum. Small-scale numerical tests on nonlinear regression and latent diffusion are reported.
Significance. If the stated hypotheses hold, the work supplies an explicit, non-asymptotic error-propagation result that links neural approximation error directly to distance from the global minimizer in function space. The reduction of the neural MMS step to a Riemannian gradient flow on a manifold induced by the network Jacobian is a clean technical contribution, and the derivation of a uniform tracking bound together with a trajectory budget is stronger than typical qualitative convergence statements in the neural-optimization literature.
minor comments (3)
- The abstract states that the increment set is a 'boundaryless smooth embedded submanifold' under C² regularity and local non-degeneracy of the Jacobian; the corresponding theorem statement and the precise non-degeneracy hypothesis should be displayed early in §3 so that readers can immediately verify the manifold dimension and the absence of boundary.
- The interior-localization condition and the explicit data condition are invoked to obtain geodesic strong convexity, yet no quantitative illustration (e.g., a low-dimensional network and data set for which both conditions are verified by direct computation) appears in the numerical section; adding such an example would make the restrictiveness of the hypotheses concrete.
- Notation for the exponential map and the retraction used in the discrete scheme should be unified; the manuscript alternates between 'exponential map' and 'retraction' without an explicit statement that they coincide on the manifold in question.
Simulated Author's Rebuttal
We thank the referee for the detailed and accurate summary of our manuscript as well as the positive significance assessment. The recommendation of minor revision is noted. No specific major comments were raised in the report.
Circularity Check
No significant circularity; derivation self-contained under explicit assumptions
full rationale
The paper's chain begins from C² smoothness plus locally non-degenerate Jacobian to establish the increment set as a smooth embedded submanifold, then invokes an interior-localization condition plus explicit data condition to obtain geodesic convexity and strong convexity; linear convergence of the Riemannian flow and its exponential-map discretization follows from standard Riemannian optimization theory, after which error propagation to an O(δ) neighborhood is a routine inexact-iteration estimate. None of these steps reduces by definition, by fitted-parameter renaming, or by load-bearing self-citation; all load-bearing hypotheses are stated externally to the target conclusion and the argument remains conditional on them. No self-citation chains, ansatz smuggling, or renaming of known empirical patterns appear in the derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Network is C² with locally non-degenerate Jacobian
- domain assumption Strict interior-localization condition and explicit data condition hold
Reference graph
Works this paper leans on
-
[1]
Boumal.An Introduction to Optimization on Smooth Manifolds
doi: 10.1017/9781009166164. URLhttps://www.nicolasboumal.net/ book. Martin R Bridson and Andr´ e Haefliger.Metric spaces of non-positive curvature, volume
-
[2]
Tianle Cai, Ruiqi Gao, Jikai Hou, Siyu Chen, Dong Wang, Di He, Zhihua Zhang, and Liwei Wang. A gram–Gauss–Newton method learning overparameterized deep neural networks for regression problems.arXiv preprint arXiv:1905.11675,
-
[3]
URLhttps://arxiv.org/abs/2412.14031. Jeff Cheeger and David G. Ebin.Comparison Theorems in Riemannian Geometry. AMS Chelsea Publishing, revised reprint of the 1975 original edition,
-
[4]
Expansive natural neural gradient flows for energy minimization.arXiv preprint arXiv:2507.13475,
Wolfgang Dahmen, Wuchen Li, Yuankai Teng, and Zhu Wang. Expansive natural neural gradient flows for energy minimization.arXiv preprint arXiv:2507.13475,
-
[5]
Finite depth and width corrections to the neural tangent kernel.arXiv preprint arXiv:1909.05989,
Boris Hanin and Mihai Nica. Finite depth and width corrections to the neural tangent kernel.arXiv preprint arXiv:1909.05989,
-
[6]
URLhttps://doi.org/10.1137/22M1529427
doi: 10.1137/22M1529427. URLhttps://doi.org/10.1137/22M1529427. Arthur Jacot, Franck Gabriel, and Cl´ ement Hongler. Neural tangent kernel: Convergence and generalization in neural networks. InAdvances in Neural Information Processing Systems, volume 31,
-
[7]
Muon: An optimizer for hidden layers in neural networks, 2024.URL https://kellerjordan
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024.URL https://kellerjordan. github. io/posts/muon, 6(3):4,
2024
-
[8]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
doi: 10.1007/978-0-387-21752-9
-
[11]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Ayan Maiti, Michelle Michelle, and Haizhao Yang. Optimal neural network approximation for high-dimensional continuous functions.arXiv preprint arXiv:2409.02363,
-
[13]
An introduction to the analysis of gradients systems.arXiv preprint arXiv:2306.05026,
Alexander Mielke. An introduction to the analysis of gradients systems.arXiv preprint arXiv:2306.05026,
-
[14]
Phan-Minh Nguyen and Huy Tuan Pham. A rigorous framework for the mean field limit of multilayer neural networks.arXiv preprint arXiv:2001.11443,
-
[15]
SOAP: Improving and Stabilizing Shampoo using Adam
Nikhil Vyas, Depen Morwani, Rosie Zhao, Mujin Kwun, Itai Shapira, David Brandfon- brener, Lucas Janson, and Sham Kakade. Soap: Improving and stabilizing shampoo using adam.arXiv preprint arXiv:2409.11321,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.