Multi-Head Recurrent Memory Agents
Pith reviewed 2026-07-03 20:49 UTC · model grok-4.3
The pith
Splitting recurrent memory into independent heads and updating only one per step raises retention from under 30 percent to 74 percent at 896K tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
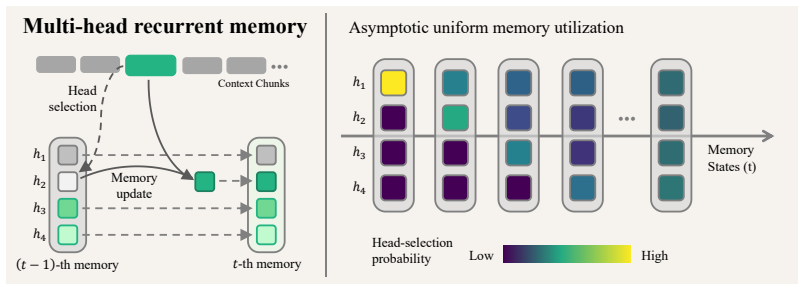
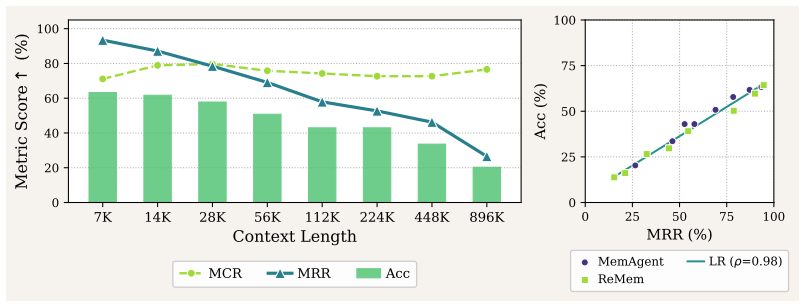
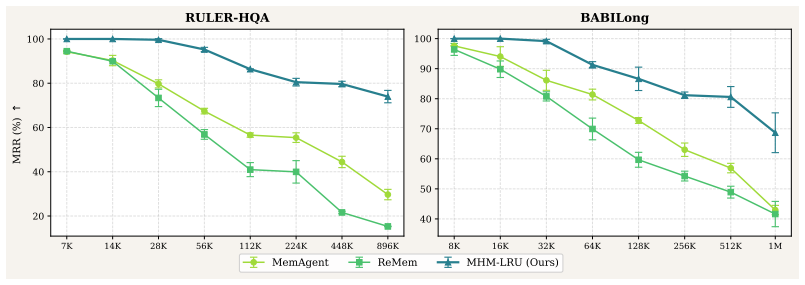
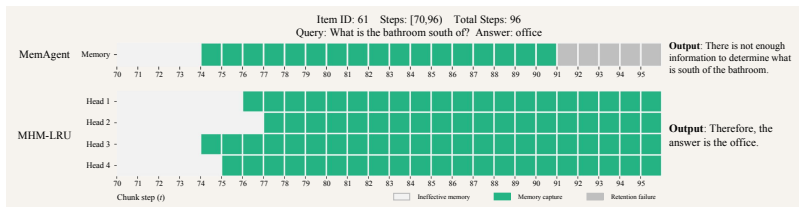
Existing recurrent memory agents treat memory as one monolithic text block, so every consolidation step risks erasing earlier content and retention collapses with growing context length. Multi-Head Recurrent Memory partitions the fixed-size memory into independent heads and applies a stage-wise select-then-update rule: exactly one head is chosen for the current update while the others stay structurally untouched. The MHM-LRU instantiation enforces uniform head rotation with zero added cost, lifting measured retention on RULER-HQA at 896K tokens from below 30 percent to 73.96 percent and delivering corresponding gains in task accuracy across model families.
What carries the argument
Multi-Head Recurrent Memory (MHM) with stage-wise select-then-update strategy that structurally shields all heads except the single chosen one during each consolidation step.
If this is right
- End-to-end accuracy on long-context tasks rises in direct proportion to the measured retention rate.
- The improvement holds across different base models and task types without any retraining.
- Retention becomes an architectural guarantee rather than an emergent model behavior.
- Uniform head rotation adds no token overhead yet prevents the degradation seen in single-block memory.
Where Pith is reading between the lines
- The same head-partition idea could be applied to other fixed-size memory structures such as key-value caches.
- Optimal head count or selection policy might vary by task and could be tuned without changing the core shielding rule.
- Uniform rotation may limit specialization of individual heads, which could be checked by tracking per-head contribution on mixed tasks.
Load-bearing premise
That keeping most heads untouched during each update will still let the system capture new information without coordination failures or missed updates across heads.
What would settle it
Measure end-to-end accuracy on a task engineered to require simultaneous updates to every memory slot; if accuracy falls below the monolithic baseline, the shielding premise is falsified.
Figures





read the original abstract
Recurrent memory agents extend LLMs to arbitrarily long contexts by iteratively consolidating input into a fixed-size memory window. Despite their scalability, these agents exhibit a well-documented reliability problem: end-to-end performance degrades systematically as context length grows. We diagnose this failure by decomposing performance into two factors--memory capture and memory retention--and quantitatively confirm that retention is the dominant bottleneck. Retention collapses because existing designs maintain memory as a monolithic text block, forcing every update to risk overwriting previously retained content. Motivated by this diagnosis, we propose Multi-Head Recurrent Memory (MHM), a general, training-free framework that partitions memory into independent heads governed by a stage-wise select-then-update strategy. At each step, exactly one head is selected for update while the remaining heads are structurally shielded from overwriting, shifting the burden of retention from model behavior to architectural design. As a lightweight instantiation, we introduce Least-Recently-Updated MHM (MHM-LRU), which guarantees uniform head utilization with zero additional token overhead. Extensive experiments on long-context benchmarks show that MHM-LRU substantially improves both retention and end-to-end accuracy across the 100K--1M token range, where baselines degrade sharply. On RULER-HQA at 896K tokens, MHM-LRU improves the memory retention rate from less than 30% to 73.96%. These gains generalize across model families, scales, and task types, positioning architectural optimization as a practical and cost-efficient path toward reliable long-context recurrent memory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper diagnoses retention as the dominant failure mode in recurrent memory agents for long contexts (due to monolithic memory updates risking overwrites) and proposes Multi-Head Recurrent Memory (MHM), a training-free framework that partitions memory into independent heads with a stage-wise select-then-update rule (exactly one head updated per step). As a concrete instantiation, MHM-LRU uses least-recently-updated selection to guarantee uniform utilization with no extra overhead. Experiments claim that MHM-LRU raises retention from <30% to 73.96% on RULER-HQA at 896K tokens and improves end-to-end accuracy across 100K-1M token regimes on multiple long-context benchmarks, generalizing across model families and scales.
Significance. If the central empirical claims hold, the work supplies a lightweight, parameter-free architectural fix that shifts retention from learned behavior to structural shielding, offering a cost-efficient route to reliable recurrent memory without retraining or added tokens. The diagnosis into capture vs. retention and the zero-overhead LRU instantiation are concrete strengths.
major comments (1)
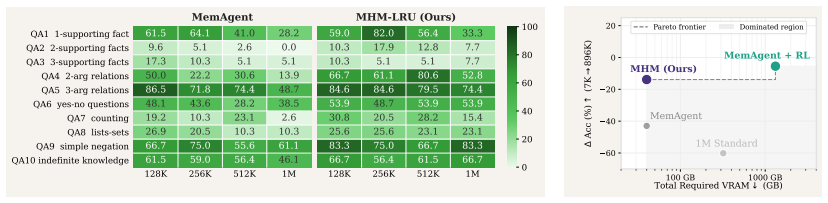
- [Abstract / Experiments] Abstract and Experiments: the claim that gains 'generalize across ... task types' rests on benchmarks whose primary stress (RULER-HQA single-fact retrieval) does not probe the weakest assumption—that the distributed select-then-update rule preserves cross-head consolidation without introducing new failure modes such as head starvation on correlated facts or degraded multi-head reasoning. No additional coordination or multi-fact benchmarks are described that would falsify this risk.
minor comments (2)
- [Abstract] Abstract: quantitative claims (73.96% retention, <30% baseline) are reported without error bars, number of runs, or variance, reducing verifiability.
- [Abstract] Abstract: full methods details (exact head count, selection implementation, memory window size) are omitted, making the 'lightweight instantiation' claim difficult to reproduce from the given text.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. We address the major comment below and agree that additional validation would strengthen the generalization claims.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments: the claim that gains 'generalize across ... task types' rests on benchmarks whose primary stress (RULER-HQA single-fact retrieval) does not probe the weakest assumption—that the distributed select-then-update rule preserves cross-head consolidation without introducing new failure modes such as head starvation on correlated facts or degraded multi-head reasoning. No additional coordination or multi-fact benchmarks are described that would falsify this risk.
Authors: We agree that RULER-HQA emphasizes single-fact retrieval and that the current set of benchmarks does not explicitly test scenarios involving correlated facts across heads or multi-fact coordination. The manuscript reports gains on multiple long-context benchmarks, but these do not include dedicated multi-fact or cross-head reasoning evaluations that would directly falsify the identified risks. In the revision we will (1) qualify the generalization statement in the abstract to reflect the task types actually evaluated and (2) add experiments on multi-fact retrieval and coordination benchmarks to probe the select-then-update rule under those conditions. revision: yes
Circularity Check
No significant circularity; design motivated by diagnosis and validated empirically
full rationale
The paper diagnoses retention failure in monolithic recurrent memory via decomposition into capture/retention factors, then introduces MHM partitioning and stage-wise shielding as an architectural intervention. MHM-LRU is presented as a lightweight instantiation with LRU selection. All performance claims (e.g., retention rate lift on RULER-HQA) rest on external benchmark experiments rather than any equation or parameter fit that reduces the output to the input by construction. No self-citations are invoked as uniqueness theorems or load-bearing premises for the central result. The derivation chain is self-contained against the stated benchmarks and does not exhibit self-definitional, fitted-prediction, or ansatz-smuggling patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Multi-Head Recurrent Memory heads
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Chain of agents: Large language models collaborating on long-context tasks.Advances in Neural Information Processing Systems, 37:132208–132237, 2024
Yusen Zhang, Ruoxi Sun, Yanfei Chen, Tomas Pfister, Rui Zhang, and Sercan Ö Arık. Chain of agents: Large language models collaborating on long-context tasks.Advances in Neural Information Processing Systems, 37:132208–132237, 2024
2024
-
[2]
Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1658–1677, 2024
2024
-
[3]
How long can context length of open-source llms truly promise? InNeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023
Dacheng Li, Rulin Shao, Anze Xie, Ying Sheng, Lianmin Zheng, Joseph Gonzalez, Ion Stoica, Xuezhe Ma, and Hao Zhang. How long can context length of open-source llms truly promise? InNeurIPS 2023 Workshop on Instruction Tuning and Instruction Following, 2023
2023
-
[4]
Jiaqi Li, Mengmeng Wang, Zilong Zheng, and Muhan Zhang. Loogle: Can long-context language models understand long contexts? InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16304–16333, 2024
2024
-
[5]
Infllm: Training-free long-context extrapolation for llms with an efficient context memory.Advances in neural information processing systems, 37:119638–119661, 2024
Chaojun Xiao, Pengle Zhang, Xu Han, Guangxuan Xiao, Yankai Lin, Zhengyan Zhang, Zhiyuan Liu, and Maosong Sun. Infllm: Training-free long-context extrapolation for llms with an efficient context memory.Advances in neural information processing systems, 37:119638–119661, 2024
2024
-
[6]
Leave no document behind: Benchmarking long-context llms with extended multi-doc qa
Minzheng Wang, Longze Chen, Fu Cheng, Shengyi Liao, Xinghua Zhang, Bingli Wu, Haiyang Yu, Nan Xu, Lei Zhang, Run Luo, et al. Leave no document behind: Benchmarking long-context llms with extended multi-doc qa. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5627–5646, 2024
2024
-
[7]
Mmlongbench-doc: Benchmarking long-context document understanding with visualizations.Advances in Neural Information Processing Systems, 37:95963–96010, 2024
Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Yan Ma, Xiaoyi Dong, et al. Mmlongbench-doc: Benchmarking long-context document understanding with visualizations.Advances in Neural Information Processing Systems, 37:95963–96010, 2024
2024
-
[8]
Long context vs
Xinze Li, Yushi Bai, Bowen Jin, Fengbin Zhu, Liangming Pan, and Yixin Cao. Long context vs. rag: Strategies for processing long documents in llms. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 4110– 4113, 2025
2025
-
[9]
Re- sum: Unlocking long-horizon search intelligence via context summarization.Arxiv:2509.13313, 2025
Xixi Wu, Kuan Li, Yida Zhao, Liwen Zhang, Litu Ou, Huifeng Yin, Zhongwang Zhang, Yong Jiang, Pengjun Xie, Fei Huang, Minhao Cheng, Shuai Wang, Hong Cheng, and Jingren Zhou. Re- sum: Unlocking long-horizon search intelligence via context summarization.Arxiv:2509.13313, 2025
-
[10]
arXiv preprint arXiv:2506.18096 , year=
Yuxuan Huang, Yihang Chen, Haozheng Zhang, Kang Li, Huichi Zhou, Meng Fang, Linyi Yang, Xiaoguang Li, Lifeng Shang, Songcen Xu, et al. Deep research agents: A systematic examination and roadmap.Arxiv:2506.18096, 2025
-
[11]
Weizhi Zhang, Yangning Li, Yuanchen Bei, Junyu Luo, Guancheng Wan, Liangwei Yang, Chenxuan Xie, Yuyao Yang, Wei-Chieh Huang, Chunyu Miao, et al. From web search towards agentic deep research: Incentivizing search with reasoning agents.Arxiv:2506.18959, 2025
-
[12]
Iterresearch: Rethinking long-horizon agents via markovian state reconstruction
Guoxin Chen, Zile Qiao, Xuanzhong Chen, Donglei Yu, Haotian Xu, Xin Zhao, Ruihua Song, Wenbiao Yin, Huifeng Yin, Liwen Zhang, Kuan Li, Minpeng Liao, Yong Jiang, Pengjun Xie, Fei Huang, and Jingren Zhou. Iterresearch: Rethinking long-horizon agents via markovian state reconstruction. InThe Fourteenth International Conference on Learning Representations, 2026. 10
2026
-
[13]
In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents
Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, et al. In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8416–8439, 2025
2025
-
[14]
Recurrentgpt: Interactive generation of (arbitrarily) long text,
Wangchunshu Zhou, Yuchen Eleanor Jiang, Peng Cui, Tiannan Wang, Zhenxin Xiao, Yifan Hou, Ryan Cotterell, and Mrinmaya Sachan. Recurrentgpt: Interactive generation of (arbitrarily) long text.Arxiv:2305.13304, 2023
-
[15]
MemSearcher: Training LLMs to Reason, Search and Manage Memory via End-to-End Reinforcement Learning
Qianhao Yuan, Jie Lou, Zichao Li, Jiawei Chen, Yaojie Lu, Hongyu Lin, Le Sun, Debing Zhang, and Xianpei Han. Memsearcher: Training llms to reason, search and manage memory via end-to-end reinforcement learning.Arxiv:2511.02805, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
MEM1: Learning to synergize memory and reasoning for efficient long-horizon agents
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Bryan Kian Hsiang Low, and Paul Pu Liang. MEM1: Learning to synergize memory and reasoning for efficient long-horizon agents. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[17]
Memagent: Reshaping long-context LLM with multi-conv RL-based memory agent
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, and Hao Zhou. Memagent: Reshaping long-context LLM with multi-conv RL-based memory agent. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[18]
Huerta, and Hao Peng
Yufeng Du, Minyang Tian, Srikanth Ronanki, Subendhu Rongali, Sravan Babu Bodapati, Aram Galstyan, Azton Wells, Roy Schwartz, Eliu A. Huerta, and Hao Peng. Context length alone hurts LLM performance despite perfect retrieval. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 23281–23298, 2025
2025
-
[19]
The impact of positional encoding on length generalization in transformers
Amirhossein Kazemnejad, Inkit Padhi, Karthikeyan Natesan, Payel Das, and Siva Reddy. The impact of positional encoding on length generalization in transformers. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[20]
Two stones hit one bird: Bilevel positional encoding for better length extrapolation
Zhenyu He, Guhao Feng, Shengjie Luo, Kai Yang, Liwei Wang, Jingjing Xu, Zhi Zhang, Hongxia Yang, and Di He. Two stones hit one bird: Bilevel positional encoding for better length extrapolation. InForty-first International Conference on Machine Learning, 2024
2024
-
[21]
An efficient recipe for long context extension via middle-focused positional encoding
Tong Wu, Yanpeng Zhao, and Zilong Zheng. An efficient recipe for long context extension via middle-focused positional encoding. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[22]
Flexprefill: A context- aware sparse attention mechanism for efficient long-sequence inference
Xunhao Lai, Jianqiao Lu, Yao Luo, Yiyuan Ma, and Xun Zhou. Flexprefill: A context- aware sparse attention mechanism for efficient long-sequence inference. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[23]
LServe: Efficient long-sequence LLM serving with unified sparse attention
Shang Yang, Junxian Guo, Haotian Tang, Qinghao Hu, Guangxuan Xiao, Jiaming Tang, Yujun Lin, Zhijian Liu, Yao Lu, and Song Han. LServe: Efficient long-sequence LLM serving with unified sparse attention. InEighth Conference on Machine Learning and Systems, 2025
2025
-
[24]
Efficient content-based sparse attention with routing transformers.Transactions of the Association for Computational Linguistics, 9:53–68, 2021
Aurko Roy, Mohammad Saffar, Ashish Vaswani, and David Grangier. Efficient content-based sparse attention with routing transformers.Transactions of the Association for Computational Linguistics, 9:53–68, 2021
2021
-
[25]
An Yang, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoyan Huang, Jiandong Jiang, Jianhong Tu, Jianwei Zhang, Jingren Zhou, Junyang Lin, Kai Dang, Kexin Yang, Le Yu, Mei Li, Minmin Sun, Qin Zhu, Rui Men, Tao He, Weijia Xu, Wenbiao Yin, Wenyuan Yu, Xiafei Qiu, Xingzhang Ren, Xinlong Yang, Yong Li, Zhiying Xu, and Zipeng Zhang. Qwen2.5-1m technical re...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Introducing claude sonnet 4.6, 2024
Anthropic. Introducing claude sonnet 4.6, 2024
2024
-
[27]
Gemini 3.1 pro: A smarter model for your most complex tasks, 2026
Google. Gemini 3.1 pro: A smarter model for your most complex tasks, 2026
2026
-
[28]
Recurrent memory transformer.Advances in Neural Information Processing Systems, 35:11079–11091, 2022
Aydar Bulatov, Yury Kuratov, and Mikhail Burtsev. Recurrent memory transformer.Advances in Neural Information Processing Systems, 35:11079–11091, 2022. 11
2022
-
[29]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. Arxiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Rwkv: Reinventing rnns for the transformer era
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Stella Biderman, Huanqi Cao, Xin Cheng, Michael Chung, Leon Derczynski, et al. Rwkv: Reinventing rnns for the transformer era. InFindings of the association for computational linguistics: EMNLP 2023, pages 14048–14077, 2023
2023
-
[31]
Titans: Learning to Memorize at Test Time
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. Arxiv:2501.00663, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Leheng Sheng, Yongtao Zhang, Wenchang Ma, Yaorui Shi, Ting Huang, Xiang Wang, An Zhang, Ke Shen, and Tat-Seng Chua. When to memorize and when to stop: Gated recurrent memory for long-context reasoning.Arxiv:2602.10560, 2026
-
[33]
Look back to reason forward: Revisitable memory for long-context LLM agents
Yaorui Shi, Yuxin Chen, Siyuan Wang, Sihang Li, Hengxing Cai, Qi GU, Xiang Wang, and An Zhang. Look back to reason forward: Revisitable memory for long-context LLM agents. In The Fourteenth International Conference on Learning Representations, 2026
2026
-
[34]
Working memory: Theories, models, and controversies.Annual review of psychology, 63(1):1–29, 2012
Alan Baddeley. Working memory: Theories, models, and controversies.Annual review of psychology, 63(1):1–29, 2012
2012
-
[35]
Forgetting as retrieval failure.Animal memory, pages 45–109, 1971
Norman E Spear. Forgetting as retrieval failure.Animal memory, pages 45–109, 1971
1971
-
[36]
A dissociation of encoding and retrieval processes in the human hippocampus
Laura L Eldridge, Stephen A Engel, Michael M Zeineh, Susan Y Bookheimer, and Barbara J Knowlton. A dissociation of encoding and retrieval processes in the human hippocampus. Journal of Neuroscience, 25(13):3280–3286, 2005
2005
-
[37]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tian- hao Li, Tingyu...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
RULER: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling, 2024
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling, 2024
2024
-
[39]
Cohen, Ruslan Salakhut- dinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhut- dinov, and Christopher D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, 2018
2018
-
[40]
On the existence of a spectrum of policies that subsumes the least recently used (lru) and least frequently used (lfu) policies
Donghee Lee, Jongmoo Choi, Jong-Hun Kim, Sam H Noh, Sang Lyul Min, Yookun Cho, and Chong Sang Kim. On the existence of a spectrum of policies that subsumes the least recently used (lru) and least frequently used (lfu) policies. InProceedings of the 1999 ACM SIGMETRICS international conference on Measurement and modeling of computer systems, pages 134–143, 1999
1999
-
[41]
Least-recently-used caching with dependent requests.Theoretical computer science, 326(1-3):293–327, 2004
Predrag R Jelenkovi ´c and Ana Radovanovi ´c. Least-recently-used caching with dependent requests.Theoretical computer science, 326(1-3):293–327, 2004
2004
-
[42]
Outperforming lru with an adaptive replacement cache algorithm.Computer, 37(4):58–65, 2004
Nimrod Megiddo and Dharmendra S Modha. Outperforming lru with an adaptive replacement cache algorithm.Computer, 37(4):58–65, 2004
2004
-
[43]
There- fore, the answer is (insert answer here)
Yuri Kuratov, Aydar Bulatov, Petr Anokhin, Ivan Rodkin, Dmitry Igorevich Sorokin, Artyom Sorokin, and Mikhail Burtsev. BABILong: Testing the limits of LLMs with long context reasoning-in-a-haystack. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. 12 Appendix Table of Contents A Multi-Head Recurre...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.