Better Literary Translation: A Multi-Aspect Data Generation and LLM Training Approach
Pith reviewed 2026-06-28 02:11 UTC · model grok-4.3
The pith
A multi-aspect iterative refinement framework generates literary translation references that outperform original ground truth by 8.65 CEA100 points for supervised fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
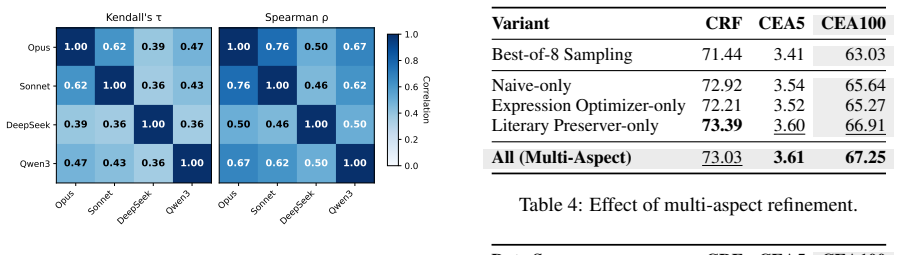
The multi-aspect iterative refinement framework generates translation references that outperform the original ground truth for supervised fine-tuning by 8.65 CEA100 points. For reinforcement learning, DPO leads to degradation while an explicit reward model with GRPO yields an additional 1.51 point gain. The resulting LitMT-8B and LitMT-14B models score 67.25 and 69.07 on the MetaphorTrans English-to-Chinese literary translation benchmark, competitive with Claude Sonnet 4.5 at 68.43, and demonstrate strong generalization to out-of-domain literary work such as O. Henry.
What carries the argument
Multi-aspect iterative refinement framework that deploys specialized LLM translators, each targeting a distinct quality dimension, to produce high-quality translation references and preference data.
If this is right
- Generated references improve SFT performance by 8.65 CEA100 points over the original ground truth.
- GRPO with an explicit reward model adds 1.51 points while DPO causes degradation.
- The trained models reach 67.25 and 69.07 on the MetaphorTrans benchmark and generalize to out-of-domain literary texts.
- Two-stage training with online exploration supports stable preference optimization for literary tasks.
Where Pith is reading between the lines
- Separating quality dimensions may allow more precise control than single-model refinement for creative text.
- The stability advantage of GRPO over DPO could apply to other preference-tuning settings that involve subjective or stylistic judgments.
- The same data-generation pipeline could be tested on additional language pairs or non-metaphor literary genres to check transfer.
Load-bearing premise
The framework assumes that distinct quality dimensions in literary translation can be effectively isolated and targeted by separate specialized LLM translators during iterative refinement without introducing systematic biases or inconsistencies that affect downstream training.
What would settle it
Retraining the models on the MetaphorTrans benchmark with the generated references and observing an improvement of less than 8.65 CEA100 points over the original ground truth would falsify the central performance claim.
Figures

read the original abstract
Literary translation poses unique challenges due to the scarcity of high-quality annotated data and the need to balance expression fluency with literary effect. We present a multi-aspect iterative refinement framework that generates high-quality translation references and preference data through specialized LLM translators, each targeting a distinct quality dimension. We leverage the generated data for supervised fine-tuning and reinforcement learning. Experiments show that our generated references outperform the original ground truth for SFT by 8.65 CEA100 points. For reinforcement learning, we find that DPO leads to performance degradation in this setting, while leveraging an explicit reward model for GRPO yields an additional 1.51 point improvement. We attribute this to the stability of two-stage training and GRPO's online exploration capability. Our resulting models, LitMT-8B and LitMT-14B, achieve 67.25 and 69.07 CEA100 respectively on the MetaphorTrans English-to-Chinese literary translation benchmark, competitive with Claude Sonnet 4.5 at 68.43, and demonstrate strong generalization to out-of-domain literary work (i.e., O. Henry).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a multi-aspect iterative refinement framework that employs specialized LLM translators, each targeting a distinct quality dimension, to generate high-quality literary translation references and preference data. These data are used for supervised fine-tuning (SFT) and reinforcement learning via GRPO (with DPO shown to degrade performance). The resulting LitMT-8B and LitMT-14B models achieve 67.25 and 69.07 CEA100 on the MetaphorTrans English-to-Chinese benchmark, outperforming SFT on original human ground truth by 8.65 points and remaining competitive with Claude Sonnet 4.5 at 68.43, with reported generalization to out-of-domain literary texts such as O. Henry.
Significance. If the generated references demonstrably improve literary quality without metric artifacts or biases, the framework would offer a scalable solution to data scarcity in literary machine translation and highlight advantages of explicit reward models in GRPO over DPO for this domain. The reported gains and out-of-domain generalization would be of interest to the MT community, but the absence of validation for the core data-quality assumption limits the immediate impact.
major comments (3)
- [Abstract] Abstract: The central empirical claim that SFT on the generated references outperforms SFT on the original human ground truth by 8.65 CEA100 points is presented without any reported human preference study, ablation isolating each specialized translator, or check for systematic biases introduced by the iterative refinement loop.
- [Abstract] Abstract: No evidence is supplied that CEA100 on MetaphorTrans correlates with human literary judgments, leaving open the possibility that the reported gains reflect metric optimization rather than genuine improvements in fluency and literary effect.
- [Abstract] Abstract: The experimental description supplies no details on data splits, statistical significance testing, baseline comparisons, or controls that would allow assessment of whether the 8.65-point and 1.51-point gains are robust.
minor comments (1)
- Define all acronyms (CEA100, SFT, GRPO, DPO) at first use in the main text and provide a brief description of the CEA100 metric.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim that SFT on the generated references outperforms SFT on the original human ground truth by 8.65 CEA100 points is presented without any reported human preference study, ablation isolating each specialized translator, or check for systematic biases introduced by the iterative refinement loop.
Authors: We acknowledge that the abstract and current experimental presentation do not include these specific validations. In the revised manuscript we will add ablations that isolate the contribution of each specialized translator, an analysis of potential systematic biases from the iterative loop, and a human preference study on a subset of outputs to support the reported 8.65-point gain over human ground truth. revision: yes
-
Referee: [Abstract] Abstract: No evidence is supplied that CEA100 on MetaphorTrans correlates with human literary judgments, leaving open the possibility that the reported gains reflect metric optimization rather than genuine improvements in fluency and literary effect.
Authors: We agree that an explicit correlation study between CEA100 and human literary judgments is absent from the manuscript. CEA100 was chosen because it targets literary aspects on this benchmark, and the key result is that models trained on our generated references outperform those trained on the original human references; however, we will add a discussion of this limitation and any available supporting references for the metric in the revision. revision: partial
-
Referee: [Abstract] Abstract: The experimental description supplies no details on data splits, statistical significance testing, baseline comparisons, or controls that would allow assessment of whether the 8.65-point and 1.51-point gains are robust.
Authors: We will expand the experimental section in the revised manuscript to report data splits, statistical significance tests for the 8.65-point and 1.51-point gains, additional baseline comparisons, and controls that demonstrate robustness. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmark comparisons
full rationale
The paper's central claims are experimental: generated references improve SFT performance by 8.65 CEA100 points over human ground truth on the MetaphorTrans benchmark, with further gains from GRPO. These are direct comparisons of model outputs against an external metric and held-out data, not reductions of predictions to fitted parameters, self-definitions, or self-citation chains. No equations, uniqueness theorems, or ansatzes are invoked that collapse to the inputs by construction. The framework's data-generation loop is presented as a method whose quality is validated externally rather than assumed by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Drt: Deep reasoning translation via long chain-of-thought , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[2]
Transactions of the Association for Computational Linguistics , volume=
Deeptrans: Deep reasoning translation via reinforcement learning , author=. Transactions of the Association for Computational Linguistics , volume=. 2026 , publisher=
2026
-
[3]
arXiv preprint arXiv:2505.12996 , year=
ExTrans: Multilingual Deep Reasoning Translation via Exemplar-Enhanced Reinforcement Learning , author=. arXiv preprint arXiv:2505.12996 , year=
-
[4]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[5]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Xu, Haoran and Sharaf, Amr and Chen, Yunmo and Tan, Weiting and Shen, Lingfeng and Van Durme, Benjamin and Murray, Kenton and Kim, Young Jin , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[6]
Advances in Neural Information Processing Systems , volume=
Simpo: Simple preference optimization with a reference-free reward , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[8]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Self-instruct: Aligning language models with self-generated instructions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[9]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[10]
The Twelfth International Conference on Learning Representations , year=
Statistical Rejection Sampling Improves Preference Optimization , author=. The Twelfth International Conference on Learning Representations , year=
-
[11]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[12]
arXiv preprint arXiv:2204.05862 , year=
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
-
[13]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Synthesizing post-training data for llms through multi-agent simulation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[14]
Proceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM ^2 ) , pages=
The fellowship of the LLMs: Multi-model workflows for synthetic preference optimization dataset generation , author=. Proceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM ^2 ) , pages=
-
[15]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[16]
Haoran Xu and Kenton Murray and Philipp Koehn and Hieu Hoang and Akiko Eriguchi and Huda Khayrallah , booktitle=. X-. 2025 , url=
2025
-
[17]
the method of paired comparisons , author=
Rank analysis of incomplete block designs: I. the method of paired comparisons , author=. Biometrika , volume=. 1952 , publisher=
1952
-
[18]
Post, Matt. A Call for Clarity in Reporting BLEU Scores. Proceedings of the Third Conference on Machine Translation: Research Papers. 2018. doi:10.18653/v1/W18-6319
-
[19]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[20]
Large Language Models Are State-of-the-Art Evaluators of Translation Quality
Kocmi, Tom and Federmann, Christian. Large Language Models Are State-of-the-Art Evaluators of Translation Quality. Proceedings of the 24th Annual Conference of the European Association for Machine Translation. 2023
2023
-
[21]
arXiv preprint arXiv:1503.02531 , year=
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
-
[22]
Proceedings of the qualities of literary machine translation , pages=
The challenges of using neural machine translation for literature , author=. Proceedings of the qualities of literary machine translation , pages=
-
[23]
Translation Spaces , volume=
Creativity in translation: Machine translation as a constraint for literary texts , author=. Translation Spaces , volume=. 2022 , publisher=
2022
-
[24]
Kocmi, Tom and Artemova, Ekaterina and Avramidis, Eleftherios and Bawden, Rachel and Bojar, Ond r ej and Dranch, Konstantin and Dvorkovich, Anton and Dukanov, Sergey and Fishel, Mark and Freitag, Markus and Gowda, Thamme and Grundkiewicz, Roman and Haddow, Barry and Karpinska, Marzena and Koehn, Philipp and Lakougna, Howard and Lundin, Jessica and Monz, C...
-
[25]
Proceedings of the Ninth Conference on Machine Translation , pages=
Findings of the WMT24 general machine translation shared task: The LLM era is here but MT is not solved yet , author=. Proceedings of the Ninth Conference on Machine Translation , pages=
-
[26]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[27]
First Conference on Language Modeling , year=
Helping or Herding? Reward Model Ensembles Mitigate but do not Eliminate Reward Hacking , author=. First Conference on Language Modeling , year=
-
[28]
Proceedings of the Seventh Conference on Machine Translation (WMT) , pages=
CometKiwi: IST-unbabel 2022 submission for the quality estimation shared task , author=. Proceedings of the Seventh Conference on Machine Translation (WMT) , pages=
2022
-
[29]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Xu, Shusheng and Fu, Wei and Gao, Jiaxuan and Ye, Wenjie and Liu, Weilin and Mei, Zhiyu and Wang, Guangju and Yu, Chao and Wu, Yi , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[30]
Advances in neural information processing systems , volume=
Unpacking dpo and ppo: Disentangling best practices for learning from preference feedback , author=. Advances in neural information processing systems , volume=
-
[31]
arXiv preprint arXiv:2412.19437 , year=
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
-
[32]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[33]
arXiv preprint arXiv:2507.20534 , year=
Kimi k2: Open agentic intelligence , author=. arXiv preprint arXiv:2507.20534 , year=
-
[34]
arXiv preprint arXiv:2511.07003 , year=
Beyond English: Toward Inclusive and Scalable Multilingual Machine Translation with LLMs , author=. arXiv preprint arXiv:2511.07003 , year=
-
[35]
2025 , howpublished=
Claude Sonnet 4.5 , author=. 2025 , howpublished=
2025
-
[36]
2025 , howpublished=
Claude Opus 4.5 , author=. 2025 , howpublished=
2025
-
[37]
2025 , howpublished=
Introducing GPT-5.2 , author=. 2025 , howpublished=
2025
-
[38]
arXiv preprint arXiv:2508.10925 , year=
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
-
[39]
2025 , howpublished=
Qwen3-235B-A22B-Instruct-2507 , author=. 2025 , howpublished=
2025
-
[40]
2025 , howpublished=
Amazon Bedrock Pricing , author=. 2025 , howpublished=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.